Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel lernen Sie, wie Sie ein Projekt zur benutzerdefinierten Textklassifizierung erstellen, in dem Sie benutzerdefinierte Modelle für die Textklassifizierung trainieren können. Ein Modell ist KI-Software, die trainiert wird, um eine bestimmte Aufgabe zu erledigen. Für dieses System klassifizieren die Modelle Text und werden durch Lernen aus bezeichneten Daten trainiert.
Benutzerdefinierte Textklassifizierung unterstützt zwei Arten von Projekten:
- Klassifizierung mit einzelner Bezeichnung: Sie können jeder Datei In Ihrem Dataset eine einzelne Klasse zuweisen. Beispielsweise könnte ein Filmskript nur als "Romanze" oder "Komödie" klassifiziert werden.
- Klassifizierung mit mehreren Bezeichnungen: Sie können jedem Dokument in Ihrem Dataset mehrere Klassen zuweisen. Beispielsweise könnte ein Filmskript als "Comedy" oder "Romanze" und "Comedy" klassifiziert werden.
In dieser Schnellstartanleitung können Sie die Beispieldatensätze verwenden, die bereitgestellt werden, um eine Mehrbezeichnungsklassifizierung zu erstellen, um Filmskripts in einer oder mehreren Kategorien zu klassifizieren. Alternativ können Sie das Dataset für die Klassifizierung einzelner Bezeichnungen verwenden, um Abstracts von wissenschaftlichen Arbeiten in einer der definierten Domänen zu klassifizieren.
Voraussetzungen
- Azure-Abonnement – Erstellen eines kostenlosen Kontos
Erstellen Sie eine neue Ressource für Azure Language Services in Foundry Tools und ein Azure Storage-Konto.
Bevor Sie eine benutzerdefinierte Textklassifizierung verwenden können, müssen Sie eine Sprachressource erstellen, die Ihnen die Anmeldeinformationen gibt, die Sie zum Erstellen eines Projekts benötigen, und mit dem Training eines Modells beginnen. Sie benötigen auch ein Azure-Speicherkonto, in dem Sie Ihr Dataset hochladen können, das beim Erstellen Ihres Modells verwendet wird.
Wichtig
Um schnell zu beginnen, empfehlen wir das Erstellen einer neuen Sprachressource mithilfe der in diesem Artikel beschriebenen Schritte, mit denen Sie Azure Language-Ressource erstellen und/oder gleichzeitig ein Speicherkonto erstellen und/oder verbinden können, was einfacher ist als später.
Wenn Sie über eine bereits vorhandene Ressource verfügen, die Sie verwenden möchten, müssen Sie sie mit einem Speicherkonto verbinden.
Erstellen einer neuen Ressource im Azure-Portal
Wechseln Sie zum Azure-Portal , um eine neue Azure Language in Foundry Tools-Ressource zu erstellen.
Wählen Sie im angezeigten Fenster in den benutzerdefinierten Features Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten aus. Wählen Sie Fahren Sie fort mit dem Erstellen einer Ressource am unteren Rand des Bildschirms aus.
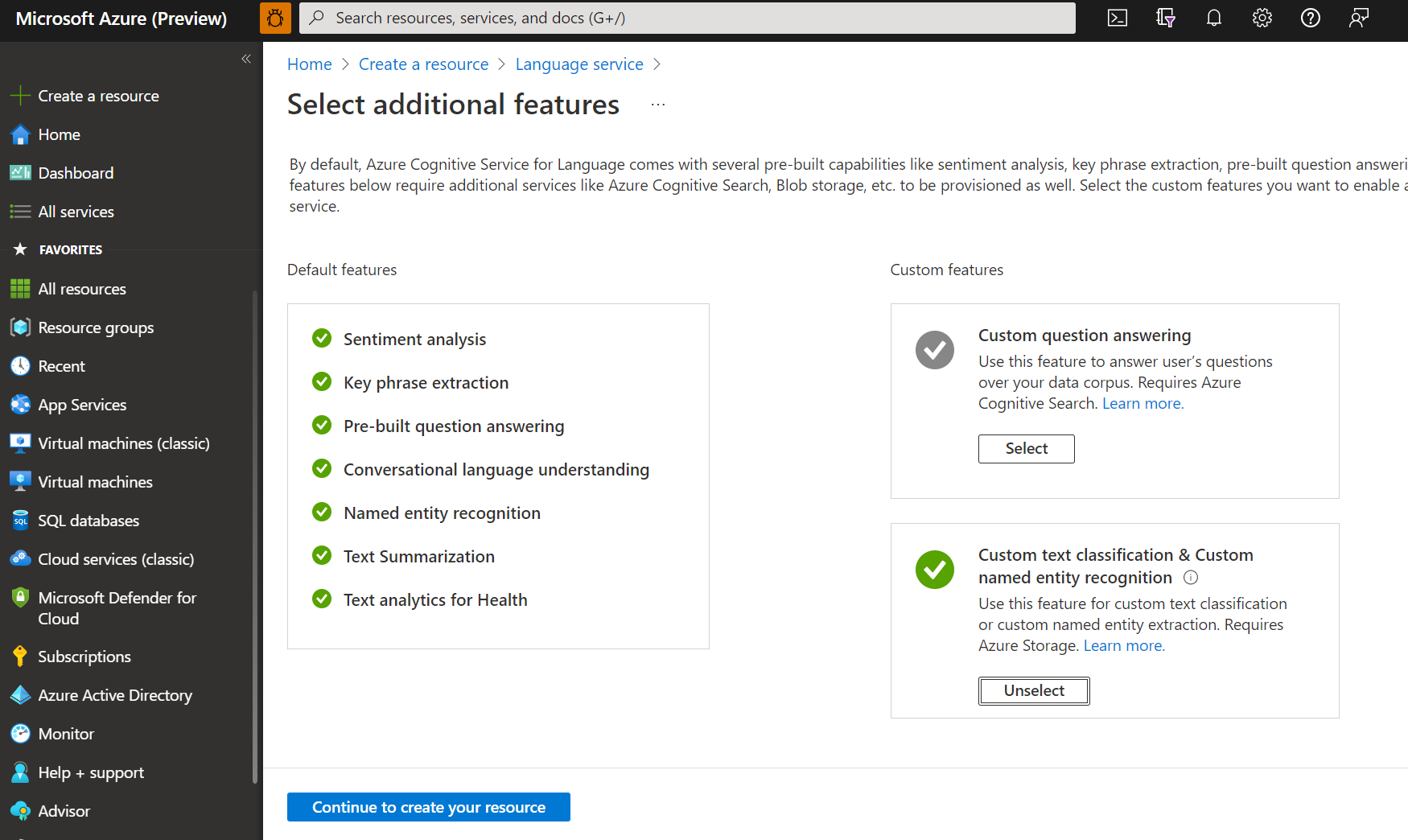
Erstellen Sie eine Sprachressource mit den folgenden Details:
Name Erforderlicher Wert Abonnement Ihr Azure-Abonnement. Ressourcengruppe Eine Ressourcengruppe, die Ihre Ressource enthält. Sie können eine vorhandene verwenden oder eine neue erstellen. Region Eine der unterstützten Regionen. Beispiel: „USA, Westen 2“. Name Ein Name für Ihre Ressource. Tarif Einer der unterstützten Preistarife. Sie können den kostenlosen Tarif (F0) verwenden, um den Dienst auszuprobieren. Wenn Sie in einer Meldung darauf hingewiesen werden, dass Ihr Anmeldekonto kein Besitzer der Ressourcengruppe des ausgewählten Speicherkontos ist, muss Ihrem Konto eine Besitzerrolle für die Ressourcengruppe zugewiesen werden, bevor Sie eine Sprachressource erstellen können. Wenden Sie sich an den Besitzer des Azure-Abonnements, um Unterstützung zu erhalten.
Sie können den Besitzer Ihres Azure-Abonnements ermitteln, indem Sie Ihre Ressourcengruppe durchsuchen und dem Link zum zugehörigen Abonnement folgen. Führen Sie dann folgende Schritte aus:
- Wählen Sie die Registerkarte Zugriffssteuerung (IAM) aus
- Wählen Sie Rollenzuweisungen aus
- Filtern Sie nach Rolle:Besitzer.
Wählen Sie im Abschnitt Benutzerdefinierte Textklassifizierung und benutzerdefinierte Erkennung benannter Entitäten ein vorhandenes Speicherkonto aus, oder wählen Sie Neues Speicherkonto aus. Beachten Sie, dass Ihnen diese Werte den Einstieg erleichtern sollen und nicht unbedingt die Speicherkontowerte darstellen, die in Produktionsumgebungen verwendet werden sollten. Um Wartezeit beim Erstellen Ihres Projekts zu vermeiden, sollten Sie eine Verbindung mit Speicherkonten in derselben Region herstellen, in der sich auch Ihre Sprachressource befindet.
Speicherkontowert Empfohlener Wert Speicherkontoname Beliebiger Name Speicherkontotyp Standardmäßiger LRS Vergewissern Sie sich, dass der Hinweis Verantwortungsvolle KI markiert ist. Wählen Sie am unteren Rand der Seite die Option Bewerten + erstellen aus.

Hochladen von Beispieldaten in den Blobcontainer
Nachdem Sie ein Azure-Speicherkonto erstellt und mit Ihrer Sprachressource verbunden haben, müssen Sie die Dokumente aus dem Beispieldatensatz in das Stammverzeichnis Ihres Containers hochladen. Diese Dokumente werden verwendet, um Ihr Modell zu trainieren.
Öffnen Sie die ZIP-Datei, und extrahieren Sie den Ordner mit den darin enthaltenen Dokumenten.
Das bereitgestellte Beispieldataset enthält ungefähr 200 Dokumente, die alle die Zusammenfassung eines Films darstellen. Jedes Dokumentation gehört mindestens einer der folgenden Klassen an:
- „Mystery“
- „Drama“
- „Thriller“
- „Komödie“
- „Action“
Azure-Portal
Navigieren Sie im Azure-Portal zu dem von Ihnen erstellten Speicherkonto, und wählen Sie es aus, indem Sie "Speicherkonten " auswählen und den Namen Ihres Speicherkontos in "Filter" für ein beliebiges Feld eingeben.
Wenn Ihre Ressourcengruppe nicht angezeigt wird, stellen Sie sicher, dass der Filter "Abonnement gleich " auf "Alle" festgelegt ist.
Klicken Sie in Ihrem Speicherkonto im Menü auf der linken Seite unter Datenspeicher auf Container. Klicken Sie im angezeigten Bildschirm auf + Container. Geben Sie dem Container den Namen example-data, und übernehmen Sie den Standardwert für Öffentliche Zugriffsebene.
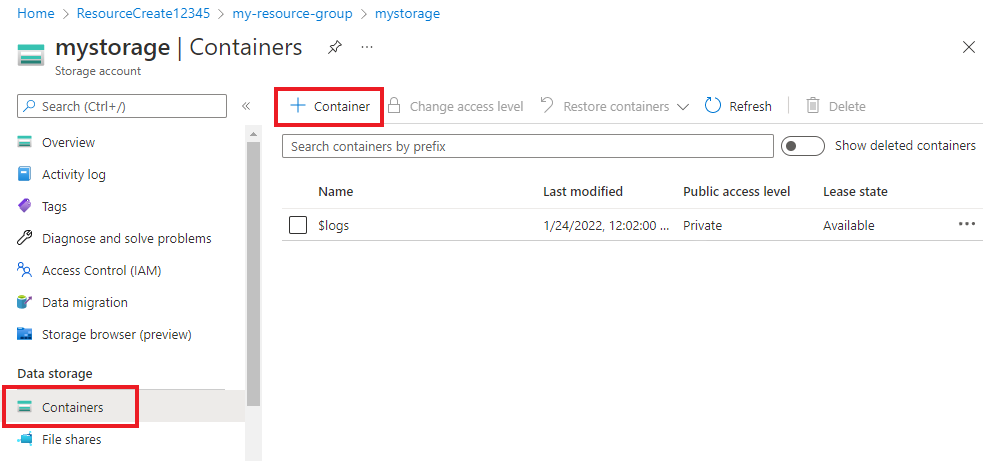
Nachdem Ihr Container erstellt wurde, wählen Sie ihn aus. Wählen Sie dann die Schaltfläche Hochladen aus, um die Dateien
.txtund.jsonauszuwählen, die Sie zuvor heruntergeladen haben.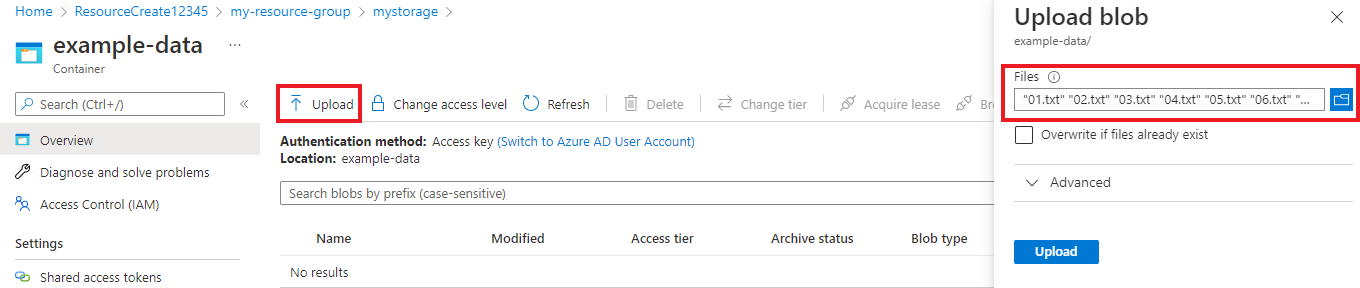


Abrufen Ihrer Ressourcenschlüssel und Endpunkte
Navigieren Sie im Azure-Portal zur Übersichtsseite Ihrer Ressource.
Wählen Sie im Menü auf der linken Seite Schlüssel und Endpunkte aus. Der Endpunkt und der Schlüssel werden für API-Anforderungen verwendet.

Erstellen eines Projekts zur benutzerdefinierten Textklassifizierung
Nachdem Ihre Ressource und der Speichercontainer konfiguriert wurden, erstellen Sie ein neues benutzerdefiniertes Textklassifizierungsprojekt. Ein Projekt ist ein Arbeitsbereich, in dem Sie Ihre benutzerdefinierten ML-Modelle auf Grundlage Ihrer Daten erstellen können. Auf Ihr Projekt kann nur von Ihnen und anderen Personen zugegriffen werden, die Zugriff auf die verwendete Azure-Sprachressource haben.
Auslösen des Importprojektauftrags
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um Ihre Bezeichnungsdatei zu importieren. Stellen Sie sicher, dass die Bezeichnungsdatei dem akzeptierten Format entspricht.
Wenn bereits ein Projekt mit demselben Namen existiert, werden die Daten dieses Projekts ersetzt.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Körper
Verwenden Sie den folgenden JSON-Code in Ihrer Anforderung. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| API-Version | {API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Die hier verwendete Version muss mit der API-Version in der URL identisch sein. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
| projectKind | customMultiLabelClassification |
Die Art Ihres Projekts | customMultiLabelClassification |
| Sprache | {LANGUAGE-CODE} |
Hierbei handelt es sich um eine Zeichenfolge, die den Sprachcode für die in Ihrem Projekt verwendeten Dokumente angibt. Wenn Ihr Projekt ein mehrsprachiges Projekt ist, wählen Sie den Sprachcode für die meisten Dokumente aus. Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung. | en-us |
| mehrsprachig | true |
Dies ist ein boolescher Wert, der es ermöglicht, dass Ihr Dataset Dokumente in mehreren Sprachen enthält. Wenn Ihr Modell bereitgestellt wird, können Sie das Modell in jeder unterstützten Sprache abfragen (die nicht zwangsläufig in Ihren Trainingsdokumenten enthalten ist). Informationen zur Unterstützung mehrerer Sprachen finden Sie unter Sprachunterstützung. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Der Name Ihres Azure-Speichercontainers für Ihre hochgeladenen Dokumente. | myContainer |
| Klassen | [] | Hierbei handelt es sich um ein Array mit allen Klassen, die im Projekt enthalten sind. | [] |
| documents | [] | Dies ist ein Array, das alle Dokumente in Ihrem Projekt und die für dieses Dokument beschrifteten Klassen enthält. | [] |
| Standort | {DOCUMENT-NAME} |
Dies ist der Speicherort der Dokumente im Speichercontainer. Da sich alle Dokumente im Stammverzeichnis des Containers befinden, sollte dies der Dokumentname sein. | doc1.txt |
| Datensatz | {DATASET} |
Der Testsatz, in den dieses Dokument bei der Aufteilung vor dem Training aufgenommen wird. Erfahren Sie , wie Sie ein Modell trainieren. Mögliche Werte für dieses Feld sind Train und Test. |
Train |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202 Antwort, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location wie folgt formatierten Wert:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie verwenden diese URL, um den Status des Importauftrags abzurufen.
Mögliche Fehlerszenarios für diese Anforderung:
- Die ausgewählte Ressource verfügt nicht über die richtigen Berechtigungen für das Speicherkonto.
- Das angegebene
storageInputContainerName-Element ist nicht vorhanden. - Ein ungültiger Sprachcode wird verwendet, oder der Sprachcodetyp ist keine Zeichenfolge.
-
Der Wert
multilingualist eine Zeichenfolge und kein boolescher Wert.
Abrufen des Importauftragsstatus
Verwenden Sie die folgende GET-Anforderung, um den Status Ihres Importprojekts abzurufen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Trainieren Ihres Modells
Nachdem Sie ein Projekt erstellt haben, beginnen Sie in der Regel damit, die Dokumente zu markieren, die im mit Ihrem Projekt verknüpften Container vorhanden sind. Für diesen Schnellstart haben Sie ein markiertes Beispieldataset importiert und Ihr Projekt mit der JSON-Beispieltagsdatei initialisiert.
Beginnen mit dem Trainieren Ihres Modells
Nachdem das Projekt importiert wurde, können Sie mit dem Trainieren Ihres Modells beginnen.
Übermitteln Sie eine POST-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Trainingsauftrag zu übermitteln. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie den folgenden JSON-Code im Anforderungstext. Das Modell wird als {MODEL-NAME} bezeichnet, nachdem das Training abgeschlossen ist. Nur erfolgreiche Trainingsaufträge generieren Modelle.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Der Modellname, der Ihrem Modell zugewiesen ist, nachdem es erfolgreich trainiert wurde. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Dies ist die Modellversion , die zum Trainieren des Modells verwendet wird. | 2022-05-01 |
| Bewertungsoptionen | Dies ist die Option zum Aufteilen Ihrer Daten zwischen Trainings- und Testdatensätzen. | {} |
|
| freundlich | percentage |
Aufteilungsmethoden Mögliche Werte sind percentage oder manual. Weitere Informationen finden Sie unter Trainieren eines Modells. |
percentage |
| trainingSplitPercentage | 80 |
Dies ist der Prozentsatz der markierten Daten, die in den Trainingsdatensatz einbezogen werden sollen. Der empfohlene Wert lautet 80. |
80 |
| testingSplitPercentage | 20 |
Dies ist der Prozentsatz der markierten Daten, die in den Testdatensatz einbezogen werden sollen. Der empfohlene Wert lautet 20. |
20 |
Hinweis
trainingSplitPercentage und testingSplitPercentage sind nur erforderlich, wenn Kind auf percentage festgelegt ist, und die Summe beider Prozentsätze sollte 100 ergeben.
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202 Antwort, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den location wie folgt formatierten Wert:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können diese URL zum Abrufen des Trainingsstatus verwenden.
Abrufen des Trainingsauftragsstatus
Das Training kann zwischen 10 und 30 Minuten dauern. Sie können die folgende Anforderung verwenden, um den Status des Trainingsauftrags bis zum erfolgreichen Abschluss abzufragen.
Verwenden Sie die folgende GET-Anforderung, um den Trainingsstatus Ihres Modells abzufragen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
Anfrage-URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Dieser Wert befindet sich im location-Headerwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen finden Sie unterModelllebenszyklus. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Sobald Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Bereitstellen Ihres Modells
Im Allgemeinen überprüfen Sie nach dem Trainieren eines Modells seine Auswertungsdetails und nehmen bei Bedarf Verbesserungen vor. In diesem Schnellstart stellen Sie einfach Ihr Modell bereit und stellen es zur Verfügung, um es in Language Studio auszuprobieren. Alternativ können Sie die Vorhersage-API aufrufen.
Übermitteln des Bereitstellungsauftrags
Übermitteln Sie eine PUT-Anforderung mithilfe der folgenden URL, der Header und des JSON-Texts, um einen Bereitstellungsauftrag zu übermitteln. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Anforderungstext
Verwenden Sie die folgende JSON-Datei im Textkörper Ihrer Anforderung. Verwenden Sie den Namen des Modells, das Sie der Bereitstellung zuweisen.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Der Modellname, der Ihrer Bereitstellung zugewiesen wird. Sie können nur Modelle zuweisen, für die das Training erfolgreich war. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myModel |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202 Antwort, die angibt, dass der Auftrag ordnungsgemäß übermittelt wurde. Extrahieren Sie in den Antwortheadern den operation-location wie folgt formatierten Wert:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} wird verwendet, um Ihre Anforderung zu identifizieren, da es sich um einen asynchronen Vorgang handelt. Sie können den Bereitstellungsstatus über diese URL abrufen.
Abrufen des Auftragsstatus der Bereitstellung
Verwenden Sie die folgende GET-Anforderung, um den Status des Bereitstellungsauftrags abzurufen. Sie können die URL verwenden, die Sie im vorherigen Schritt erhalten haben, oder die Platzhalterwerte durch Ihre eigenen Werte ersetzen.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name des Projekts. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | staging |
{JOB-ID} |
Die ID zum Ermitteln des Trainingsstatus Ihres Modells. Er befindet sich im location Kopfzeilenwert, den Sie im vorherigen Schritt erhalten haben. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
Ocp-Apim-Subscription-Key |
Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Antworttext
Sobald Sie die Anforderung gesendet haben, erhalten Sie die folgende Antwort. Setzen Sie den Abruf dieses Endpunkts fort, bis der Parameter status zu „succeeded“ (erfolgreich) wechselt. Sie sollten einen 200-Code erhalten, der den Erfolg der Anforderung angibt.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Klassifizieren von Text
Nachdem Ihr Modell erfolgreich bereitgestellt wurde, können Sie es verwenden, um Ihren Text über die Vorhersage-API zu klassifizieren. Im zuvor heruntergeladenen Beispieldataset finden Sie einige Testdokumente, die Sie in diesem Schritt verwenden können.
Übermitteln einer Aufgabe für die benutzerdefinierte Textklassifizierung
Verwenden Sie diese POST-Anforderung, um eine Textklassifizierungsaufgabe zu starten.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen finden Sie unterModelllebenszyklus. | 2022-05-01 |
Header
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Ihr Schlüssel, der den Zugriff auf diese API ermöglicht. |
Körper
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Schlüssel | Platzhalter | Wert | Beispiel |
|---|---|---|---|
displayName |
{JOB-NAME} |
Dies ist der Name Ihres Auftrags. | MyJobName |
documents |
[{},{}] | Dies ist die Liste der Dokumente, für die Aufgaben ausgeführt werden sollen. | [{},{}] |
id |
{DOC-ID} |
Hierbei handelt es sich um den Namen oder die ID des Dokuments. | doc1 |
language |
{LANGUAGE-CODE} |
Dies ist eine Zeichenfolge, die den Sprachcode des Dokuments angibt. Wenn dieser Schlüssel nicht angegeben ist, nimmt der Dienst die Standardsprache des Projekts an, die bei der Projekterstellung ausgewählt wurde. Unter Sprachunterstützung finden sie eine Liste der unterstützten Sprachcodes. | en-us |
text |
{DOC-TEXT} |
Dies ist die Dokumentaufgabe, für die die Aufgaben ausgeführt werden sollen. | Lorem ipsum dolor sit amet |
tasks |
Liste der Aufgaben, die ausgeführt werden sollen. | [] |
|
taskName |
CustomMultiLabelClassification | Aufgabenname | CustomMultiLabelClassification |
parameters |
Dies ist die Liste der Parameter, die an die Aufgabe übergeben werden. | ||
project-name |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Der Name Ihrer Bereitstellung. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | prod |
Antwort
Sie erhalten eine Antwort mit dem Statuscode 202, die auf Erfolg hinweist. Extrahieren Sie in den operation-location.
operation-location weist dieses Format auf:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
Sie können diese URL verwenden, um den Abschlussstatus der Aufgabe abzufragen und die Ergebnisse abzurufen, wenn die Aufgabe abgeschlossen ist.
Abrufen der Ergebnisse der Aufgabe
Verwenden Sie die folgende GET-Anforderung, um den Status bzw. die Ergebnisse der Textklassifizierungsaufgabe abzufragen.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Modellversion. | 2022-05-01 |
Header
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Ihr Schlüssel, der den Zugriff auf diese API ermöglicht. |
Antworttext
Die Antwort ist ein JSON-Dokument mit den folgenden Parametern.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Bereinigen von Ressourcen
Wenn Sie Ihr Projekt nicht mehr benötigen, können Sie es mit der folgenden DELETE-Anforderung löschen. Ersetzen Sie die Platzhalterwerte durch eigene Werte.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Platzhalter | Wert | Beispiel |
|---|---|---|
{ENDPOINT} |
Der Endpunkt für die Authentifizierung Ihrer API-Anforderung. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Der Name für Ihr Projekt. Bei diesem Wert wird die Groß-/Kleinschreibung beachtet. | myProject |
{API-VERSION} |
Die Version der von Ihnen aufgerufenen API. Der Wert, auf den verwiesen wird, bezieht sich auf die neueste Version, die veröffentlicht wurde. Weitere Informationen zu anderen verfügbaren API-Versionen finden Sie hier. | 2022-05-01 |
Header
Verwenden Sie den folgenden Header, um Ihre Anforderung zu authentifizieren.
| Schlüssel | Wert |
|---|---|
| Ocp-Apim-Subscription-Key | Der Schlüssel für Ihre Ressource. Wird für die Authentifizierung Ihrer API-Anforderungen verwendet. |
Nachdem Sie Ihre API-Anforderung gesendet haben, erhalten Sie eine 202 Antwort, die den Erfolg angibt, was bedeutet, dass Ihr Projekt gelöscht wird. Ein erfolgreicher Aufruf enthält einen Operation-Location-Header, mit dem der Auftragsstatus überprüft wird.
Nächste Schritte
Nachdem Sie ein benutzerdefiniertes Textklassifizierungsmodell erstellt haben, können Sie:
Wenn Sie beginnen, eigene Projekte für die benutzerdefinierte Textklassifizierung zu erstellen, verwenden Sie die Anleitungsartikel, um ausführlichere Informationen zur Entwicklung Ihres Modells zu erhalten: