Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel erfahren Sie, wie Sie die Genauigkeit des Basismodells für die Spracherkennung oder Ihrer eigenen benutzerdefinierten Modelle quantitativ messen und verbessern können. Audio- und Humantranskriptions-Daten sind erforderlich, um die Genauigkeit zu testen. Sie sollten 30 Minuten bis 5 Stunden repräsentativer Audiodaten bereitstellen.
Wichtig
Beim Testen führt das System eine Transkription durch. Dies sollten Sie nicht vergessen, da die Preise pro Serviceangebot und Abonnementebene variieren. Aktuelle Informationen finden Sie immer auf der offiziellen Seite „Azure KI Services-Preise“.
Erstellen eines Tests
Sie können die Genauigkeit Ihres benutzerdefinierten Modells testen, indem Sie einen Test erstellen. Ein Test erfordert eine Sammlung von Audiodateien und deren entsprechenden Transkriptionen. Sie können die Genauigkeit eines benutzerdefinierten Modells mit einem Basismodell für die Spracherkennung oder einem anderen benutzerdefinierten Modell vergleichen. Nachdem Sie die Testergebnisse abgerufen haben, bewerten Sie die Wortfehlerrate (WER) im Vergleich zu Spracherkennungsergebnissen.
Nachdem Sie Schulungs- und Testdatensätze hochgeladen haben, können Sie einen Test erstellen.
Führen Sie die folgenden Schritte aus, um Ihr fein abgestimmtes benutzerdefiniertes Sprachmodell zu testen:
Melden Sie sich beim Azure AI Foundry-Portal an.
Wählen Sie Feinabstimmung im linken Bereich und dann KI Service Feinabstimmung aus.
Wählen Sie die benutzerdefinierte Sprachoptimierungsaufgabe (nach Modellname) aus, die Sie gestartet haben, wie im Artikel zum Starten der benutzerdefinierten Sprachoptimierung beschrieben.
Wählen Sie "Testmodelle>+ Test erstellen" aus.
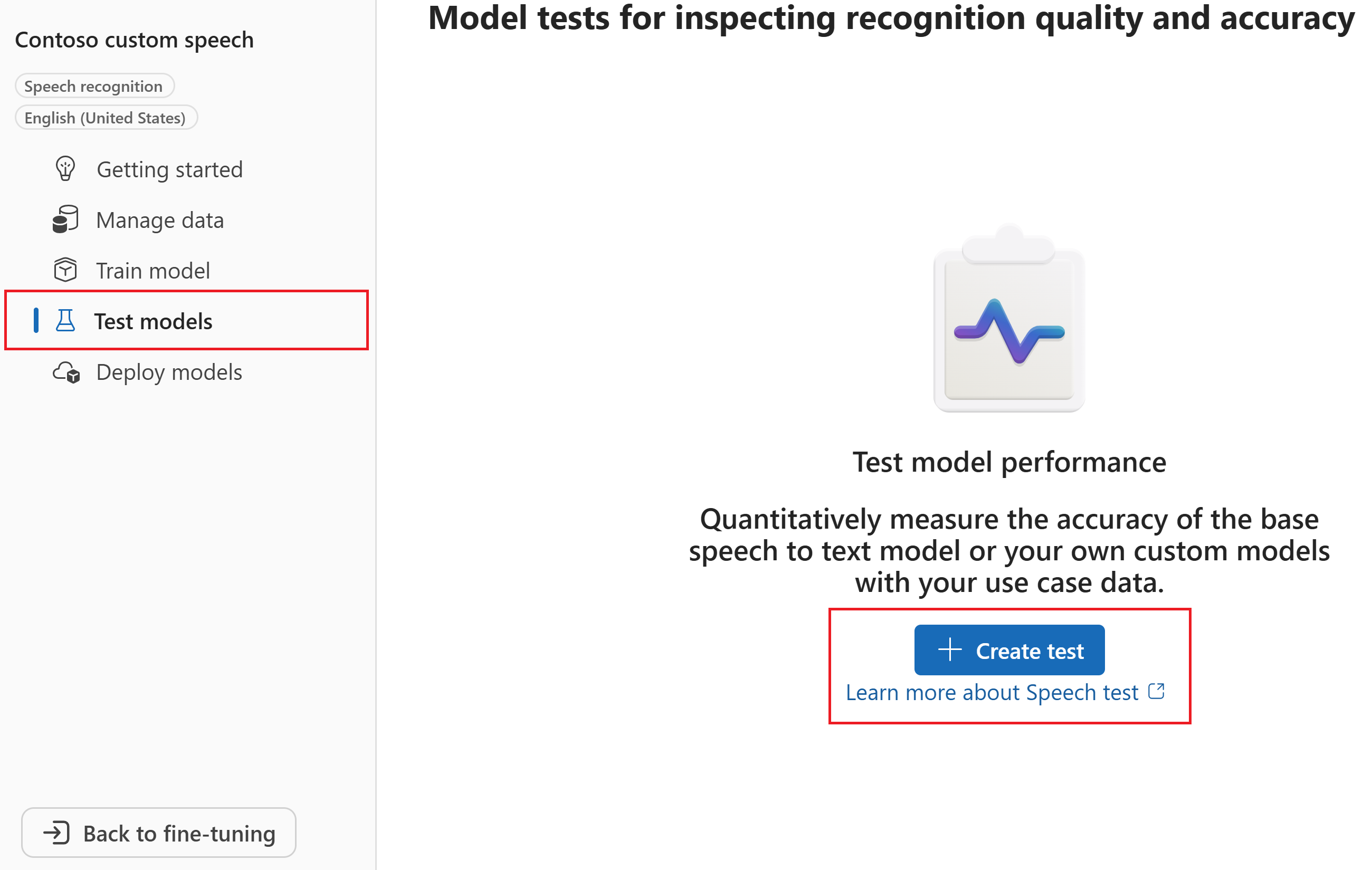
Wählen Sie im Assistenten Neuen Test erstellen den Testtyp aus. Wählen Sie für einen Genauigkeitstest (quantitativ) die Option " Genauigkeit auswerten" (Audio + Transkriptdaten) aus. Wählen Sie dann Weiter aus.
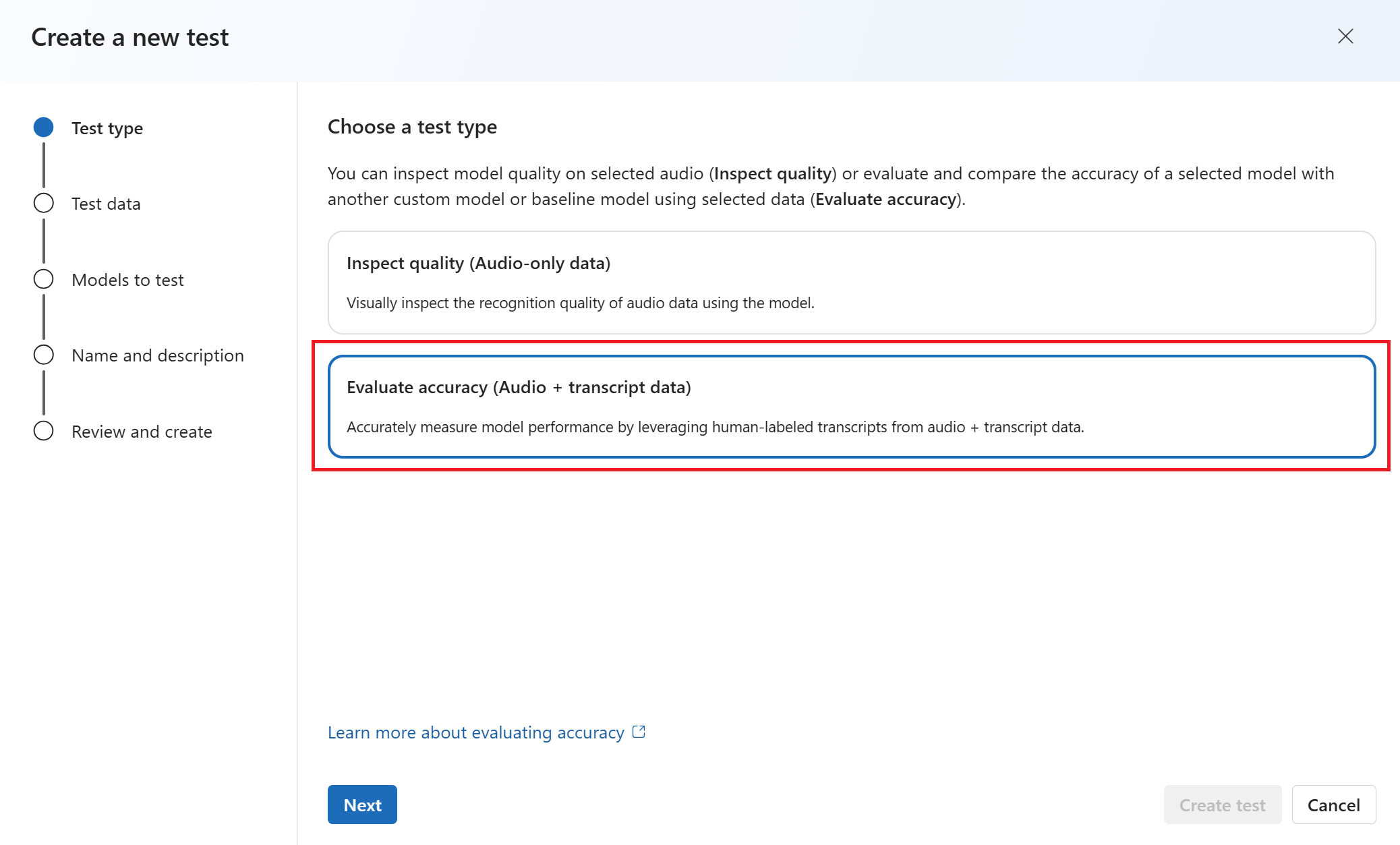
Wählen Sie die Daten aus, die Sie für das Testen verwenden möchten. Wählen Sie dann Weiter aus.
Wählen Sie bis zu zwei Modelle aus, um die Genauigkeit auszuwerten und zu vergleichen. In diesem Beispiel wählen wir das Modell aus, das wir trainiert haben, und das Basismodell. Wählen Sie dann Weiter aus.
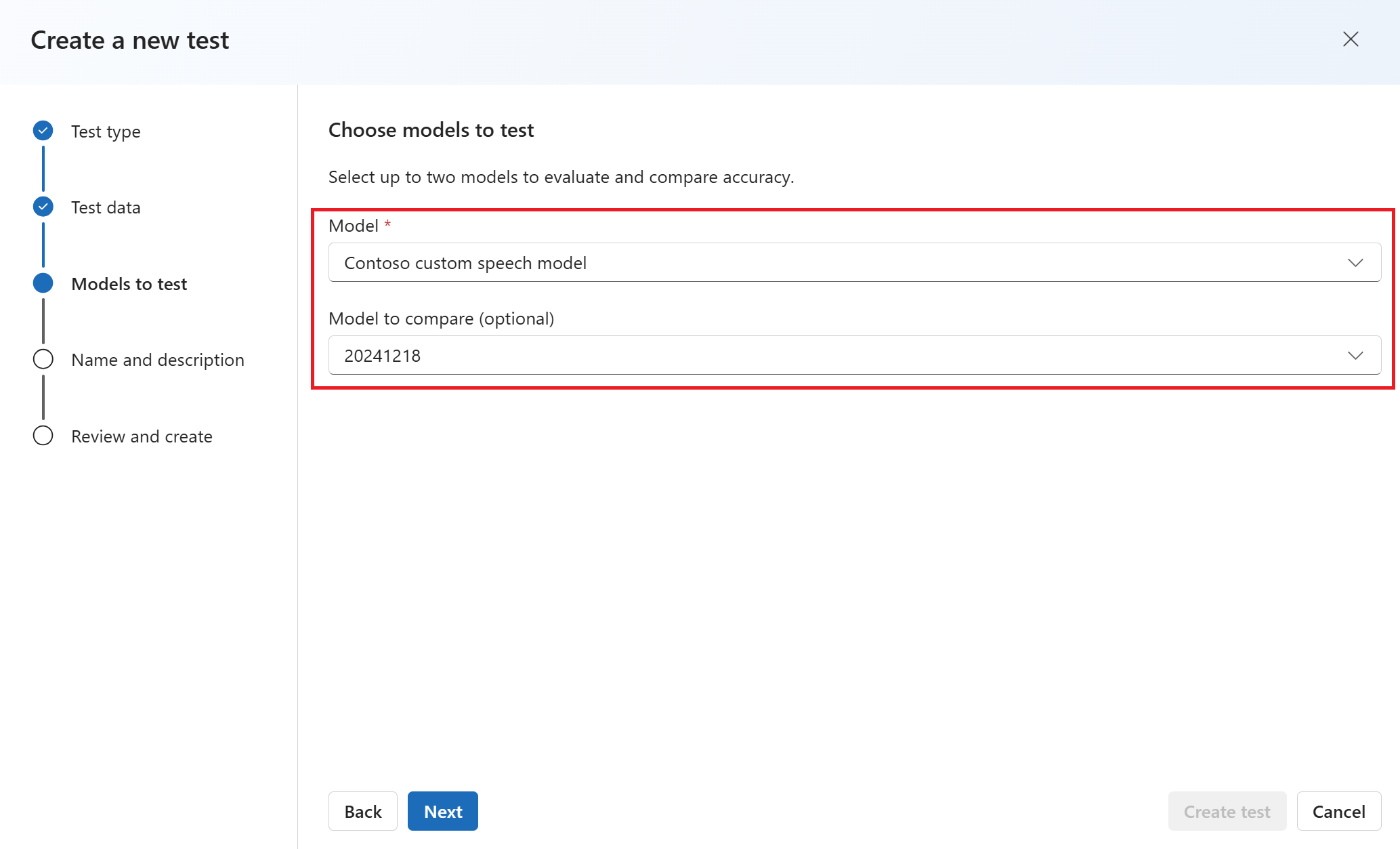
Geben Sie einen Namen und eine Beschreibung für den Test ein. Wählen Sie dann Weiter aus.
Überprüfen Sie die Einstellungen, und wählen Sie Test erstellen aus. Sie gelangen zurück zur Seite Testmodelle. Der Status der Daten ist Wird verarbeitet.




Führen Sie die folgenden Schritte aus, um einen Genauigkeitstest zu erstellen:
Melden Sie sich in Speech Studio an.
Wählen Sie Custom Speech> Ihr Projektname >Modelle testen aus.
Wählen Sie Neuen Test erstellen aus.
Wählen Sie Bewerten der Genauigkeit>Weiter aus.
Wählen Sie ein Audio- und Humantranskriptions-Dataset aus, und klicken Sie dann auf Weiter. Wenn keine Datasets verfügbar sind, brechen Sie das Setup ab, und wechseln Sie dann zum Menü Speech-Datasets, um Datasets hochzuladen.
Hinweis
Es ist wichtig, einen akustischen Dataset zu wählen, der sich von dem unterscheidet, den Sie für Ihr Modell verwendet haben. So erhalten Sie ein realistisches Bild von der Leistung des Modells.
Wählen Sie bis zu zwei Modelle aus, die bewertet werden sollen, und klicken Sie dann auf Weiter.
Geben Sie den Testnamen und eine Beschreibung ein, und klicken Sie dann auf Weiter.
Überprüfen Sie die Testdetails, und klicken Sie dann auf Speichern und Schließen.
Zum Erstellen eines Tests verwenden Sie den Befehl spx csr evaluation create. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie die
projectEigenschaft auf die ID eines vorhandenen Projekts fest. Diese Eigenschaft wird empfohlen, damit Sie den Test auch im Azure AI Foundry-Portal anzeigen können. Mit dem Befehlspx csr project listkönnen Sie verfügbare Projekte abrufen. - Legen Sie die erforderliche
model1Eigenschaft auf die ID eines Modells fest, das Sie testen möchten. - Legen Sie die erforderliche
model2Eigenschaft auf die ID eines anderen Modells fest, das Sie testen möchten. Wenn Sie nicht zwei Modelle vergleichen möchten, verwenden Sie das gleiche Modell sowohl fürmodel1als auch fürmodel2. - Legen Sie die erforderliche
datasetEigenschaft auf die ID eines Datasets fest, das Sie für den Test verwenden möchten. - Legen Sie die
languageEigenschaft fest, andernfalls legt die Speech CLI standardmäßig "en-US" fest. Dieser Parameter sollte das Gebietsschema des Datasetinhalts sein. Das Gebietsschema können Sie später nicht mehr ändern. Die Speech CLI-Eigenschaftlanguageentspricht derlocaleEigenschaft in der JSON-Anforderung und -Antwort. - Legen Sie die erforderliche
name-Eigenschaft fest. Dieser Parameter ist der Name, der im Azure AI Foundry-Portal angezeigt wird. Die Speech CLI-Eigenschaftnameentspricht derdisplayNameEigenschaft in der JSON-Anforderung und -Antwort.
Hier ist ein beispielhafter Befehl der Speech-Befehlszeilenschnittstelle, der einen Test erstellt:
spx csr evaluation create --api-version v3.2 --project 0198f569-cc11-4099-a0e8-9d55bc3d0c52 --dataset 23b6554d-21f9-4df1-89cb-f84510ac8d23 --model1 ff43e922-e3e6-4bf0-8473-55c08fd68048 --model2 13fb305e-09ad-4bce-b3a1-938c9124dda3 --name "My Evaluation" --description "My Evaluation Description"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Die oberste self-Eigenschaft im Antworttext ist der URI der Auswertung. Verwenden Sie diesen URI, um Details zum Projekt und Testergebnisse abzurufen. Sie verwenden diesen URI auch, um die Auswertung zu aktualisieren oder zu löschen.
Führen Sie den folgenden Befehl aus, um Hilfe für die Speech-Befehlszeilenschnittstelle mit Auswertungen zu erhalten:
spx help csr evaluation
Verwenden Sie zum Erstellen eines Tests den Vorgang Evaluations_Create der Spracherkennung-REST-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die
project-Eigenschaft auf den URI eines vorhandenen Projekts fest. Diese Eigenschaft wird empfohlen, damit Sie den Test auch im Azure AI Foundry-Portal anzeigen können. Sie können eine Projects_List-Anforderung zum Abrufen verfügbarer Projekte ausführen. - Legen Sie die
testingKind-Eigenschaft innerhalb vonEvaluationaufcustomPropertiesfest. Wenn SieEvaluationnicht angeben, wird der Test wie eine Qualitätsprüfung behandelt. Unabhängig davon, ob dietestingKindEigenschaft aufEvaluationoderInspectionoder nicht festgelegt ist, können Sie über die API auf die Genauigkeitsbewertungen zugreifen, aber nicht im Azure AI Foundry-Portal. - Legen Sie die erforderliche
model1-Eigenschaft auf den URI eines Modells fest, das Sie testen möchten. - Legen Sie die erforderliche
model2-Eigenschaft auf den URI eines anderen Modells fest, das Sie testen möchten. Wenn Sie nicht zwei Modelle vergleichen möchten, verwenden Sie das gleiche Modell sowohl fürmodel1als auch fürmodel2. - Legen Sie den erforderlichen
dataset-Parameter auf die ID eines Datasets fest, das Sie für den Test verwenden möchten. - Legen Sie die erforderliche
locale-Eigenschaft fest. Diese Eigenschaft sollte das Gebietsschema des Datasetinhalts sein. Das Gebietsschema können Sie später nicht mehr ändern. - Legen Sie die erforderliche
displayName-Eigenschaft fest. Diese Eigenschaft ist der Name, der im Azure AI Foundry-Portal angezeigt wird.
Erstellen Sie eine HTTP POST-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Ersetzen Sie YourSpeechResoureKey durch Ihren Speech-Ressourcenschlüssel, ersetzen Sie YourServiceRegion durch die Region der Speech-Ressource, und legen Sie die Anforderungstexteigenschaften wie zuvor beschrieben fest.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey" -H "Content-Type: application/json" -d '{
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
},
"locale": "en-US"
}' "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": -1.0,
"sentenceErrorRate1": -1.0,
"sentenceCount1": -1,
"wordCount1": -1,
"correctWordCount1": -1,
"wordSubstitutionCount1": -1,
"wordDeletionCount1": -1,
"wordInsertionCount1": -1,
"wordErrorRate2": -1.0,
"sentenceErrorRate2": -1.0,
"sentenceCount2": -1,
"wordCount2": -1,
"correctWordCount2": -1,
"wordSubstitutionCount2": -1,
"wordDeletionCount2": -1,
"wordInsertionCount2": -1
},
"lastActionDateTime": "2024-07-14T21:31:14Z",
"status": "NotStarted",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Die oberste self-Eigenschaft im Antworttext ist der URI der Auswertung. Verwenden Sie diesen URI, um Details über das Projekt und die Testergebnisse der Auswertung abzurufen. Sie verwenden diesen URI auch, um die Auswertung zu aktualisieren oder zu löschen.
Abrufen von Testergebnissen
Sie sollten die Testergebnisse erhalten und die Wortfehlerrate (WER) im Vergleich zu den Ergebnissen der Spracherkennung auswerten.
Wenn der Teststatus Erfolgreich ist, können Sie die Ergebnisse anzeigen. Wählen Sie den Test aus, um die Ergebnisse anzuzeigen.
Führen Sie die folgenden Schritte aus, um Testergebnisse abzurufen:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Speech> Ihr Projektname >Modelle testen aus.
- Wählen Sie den Link anhand des Testnamens aus.
- Nachdem der Test abgeschlossen ist, wie durch den auf Erfolgreich festgelegten Status angegeben, sollten Sie Ergebnisse sehen, die die WER-Zahl für jedes getestete Modell enthalten.
Auf dieser Seite sind alle Äußerungen in Ihrem Dataset und die Erkennungsergebnisse neben der Transkription aus dem übermittelten Dataset aufgelistet. Sie können zwischen verschiedenen Fehlertypen umschalten, darunter Einfügung, Löschung und Ersetzung. Durch Anhören der Audiodaten und Vergleich mit den Erkennungsergebnissen in den einzelnen Spalten können Sie entscheiden, welches Modell Ihre Anforderungen erfüllt und ermitteln, wo weiteres Training und Verbesserungen erforderlich sind.
Verwenden Sie den Befehl spx csr evaluation status, um Testergebnisse abzurufen. Erstellen Sie die Anforderungsparameter gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
evaluationEigenschaft auf die ID der Auswertung fest, für die Sie Testergebnisse abrufen möchten.
Hier ist ein beispielhafter Befehl der Speech-Befehlszeilenschnittstelle, der Testergebnisse abruft:
spx csr evaluation status --api-version v3.2 --evaluation 8bfe6b05-f093-4ab4-be7d-180374b751ca
Die Wortfehlerraten und weitere Details werden im Antworttext zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Führen Sie den folgenden Befehl aus, um Hilfe für die Speech-Befehlszeilenschnittstelle mit Auswertungen zu erhalten:
spx help csr evaluation
Zum Abrufen von Testergebnissen beginnen Sie mit dem Vorgang Evaluations_Get der Spracherkennung-REST-API.
Erstellen Sie eine HTTP GET-Anforderung mithilfe des URI, wie im folgenden Beispiel gezeigt. Ersetzen Sie YourEvaluationId durch die ID Ihrer Auswertung, YourSpeechResoureKey durch den Schlüssel Ihrer Speech-Ressource und YourServiceRegion durch die Region Ihrer Speech-Ressource.
curl -v -X GET "https://YourServiceRegion.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/YourEvaluationId" -H "Ocp-Apim-Subscription-Key: YourSpeechResoureKey"
Die Wortfehlerraten und weitere Details werden im Antworttext zurückgegeben.
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38",
"model1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"model2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/models/base/13fb305e-09ad-4bce-b3a1-938c9124dda3"
},
"dataset": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/datasets/23b6554d-21f9-4df1-89cb-f84510ac8d23"
},
"transcription2": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"transcription1": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/transcriptions/b50642a8-febf-43e1-b9d3-e0c90b82a62a"
},
"project": {
"self": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/projects/0198f569-cc11-4099-a0e8-9d55bc3d0c52"
},
"links": {
"files": "https://eastus.api.cognitive.microsoft.com/speechtotext/v3.2/evaluations/dda6e880-6ccd-49dc-b277-137565cbaa38/files"
},
"properties": {
"wordErrorRate1": 0.028900000000000002,
"sentenceErrorRate1": 0.667,
"tokenErrorRate1": 0.12119999999999999,
"sentenceCount1": 3,
"wordCount1": 173,
"correctWordCount1": 170,
"wordSubstitutionCount1": 2,
"wordDeletionCount1": 1,
"wordInsertionCount1": 2,
"tokenCount1": 165,
"correctTokenCount1": 145,
"tokenSubstitutionCount1": 10,
"tokenDeletionCount1": 1,
"tokenInsertionCount1": 9,
"tokenErrors1": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
},
"wordErrorRate2": 0.028900000000000002,
"sentenceErrorRate2": 0.667,
"tokenErrorRate2": 0.12119999999999999,
"sentenceCount2": 3,
"wordCount2": 173,
"correctWordCount2": 170,
"wordSubstitutionCount2": 2,
"wordDeletionCount2": 1,
"wordInsertionCount2": 2,
"tokenCount2": 165,
"correctTokenCount2": 145,
"tokenSubstitutionCount2": 10,
"tokenDeletionCount2": 1,
"tokenInsertionCount2": 9,
"tokenErrors2": {
"punctuation": {
"numberOfEdits": 4,
"percentageOfAllEdits": 20.0
},
"capitalization": {
"numberOfEdits": 2,
"percentageOfAllEdits": 10.0
},
"inverseTextNormalization": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
},
"lexical": {
"numberOfEdits": 12,
"percentageOfAllEdits": 12.0
},
"others": {
"numberOfEdits": 1,
"percentageOfAllEdits": 5.0
}
}
},
"lastActionDateTime": "2024-07-14T21:31:22Z",
"status": "Succeeded",
"createdDateTime": "2024-07-14T21:31:14Z",
"locale": "en-US",
"displayName": "My Evaluation",
"description": "My Evaluation Description",
"customProperties": {
"testingKind": "Evaluation"
}
}
Bewertung der Wortfehlerrate (WER)
Der Branchenstandard zur Messung der Modellgenauigkeit ist die Wortfehlerrate (WER). WER ermittelt die Anzahl der bei der Erkennung falsch identifizierten Wörter und dividiert sie durch die Gesamtzahl der Wörter, die in der Humantranskription angegeben sind.
Falsch identifizierte Wörter fallen in drei Kategorien:
- Einfügung (I): Wörter, die fälschlicherweise im Hypothesentranskript hinzugefügt werden
- Löschung (D): Wörter, die im Hypothesentranskript nicht erkannt werden
- Ersetzung (S): Wörter, die zwischen Verweis und Hypothese ersetzt wurden
Im Azure AI Foundry-Portal und Speech Studio wird der Quotient mit 100 multipliziert und als Prozentsatz angezeigt. Die Ergebnisse der Speech-Befehlszeilenschnittstelle und der REST-API werden nicht mit 100 multipliziert.
$$ WER = {{I+D+S} N}\over\times 100 $$
Im Folgenden finden Sie ein Beispiel, in dem falsch identifizierte Wörter im Vergleich zur Humantranskription dargestellt werden:

Das Ergebnis der Spracherkennung ist wie folgt fehlerhaft:
- Einfügung (I): das Wort „ein“ wurde hinzugefügt
- Löschung (D): Das Wort „sind“ wurde gelöscht
- Ersetzung (S): Das Wort „Jones“ wurde durch „John“ ersetzt
Die Wortfehlerrate aus dem vorherigen Beispiel beträgt 60 %.
Wenn Sie WER-Messungen lokal replizieren möchten, können Sie das sclite-Tool aus dem NIST Scoring Toolkit (SCTK) verwenden.
Beheben von Fehlern und Verbessern der WER
Sie können die WER-Berechnung aus den Ergebnissen der maschinellen Erkennung verwenden, um die Qualität des mit Ihrer App, Ihrem Tool oder Ihrem Produkt verwendeten Modells zu bewerten. Eine WER von 5 bis 10 % gilt als gute Qualität und ist sofort verwendbar. Eine WER von 20 % ist akzeptabel, Sie sollten aber zusätzliches Training in Betracht ziehen. Eine WER von 30 % oder mehr weist auf schlechte Qualität hin und erfordert Anpassung und Training.
Die Verteilung der Fehler spielt eine wichtige Rolle. Wenn viele Löschfehler auftreten, liegt es in der Regel an einem schwachen Audiosignal. Um dieses Problem zu beheben, müssen Sie Audiodaten näher an der Quelle erfassen. Einfügefehler bedeuten, dass der Ton in einer lauten Umgebung aufgenommen wurde und Übersprechen vorhanden sein kann, was zu Erkennungsproblemen führt. Ersetzungsfehler treten häufig auf, wenn eine unzureichende Stichprobe domänenspezifischer Begriffe entweder als menschenmarkierte Transkriptionen oder zugehöriger Text bereitgestellt wird.
Durch die Analyse einzelner Dateien können Sie feststellen, welche Art von Fehlern vorliegen und welche Fehler nur in einer bestimmten Datei auftreten. Das Verständnis von Problemen auf Dateiebene hilft Ihnen bei gezielten Verbesserungen.
Bewertung der Tokenfehlerrate (TER)
Neben der Wortfehlerrate können Sie auch das erweiterte Measure Tokenfehlerrate (TER, Token Error Rate) verwenden, um die Qualität im endgültigen End-to-End-Anzeigeformat auszuwerten. Neben dem lexikalischen Format (That will cost $900. anstelle von that will cost nine hundred dollars) werden bei der TER die Aspekte des Anzeigeformats wie Interpunktion, Großschreibung und ITN berücksichtigt. Hier finden Sie weitere Informationen zum Anzeigen der Ausgabeformatierung mit Spracherkennung.
WER ermittelt die Anzahl der bei der Erkennung falsch identifizierten Wörter und dividiert sie durch die Gesamtzahl der Wörter, die im von Menschen beschrifteten Transkript angegeben sind.
$$ TER = {{I+D+S} N}\over\times 100 $$
Die Formel der TER-Berechnung ähnelt auch der WER-Formel. Der einzige Unterschied besteht darin, dass TER auf der Tokenebene und nicht auf der Wortebene berechnet wird.
- Einfügung (I): Token, die fälschlicherweise im Hypothesentranskript hinzugefügt werden
- Löschung (D): Token, die im Hypothesentranskript nicht erkannt werden
- Ersetzung (S): Token, die zwischen Verweis und Hypothese ersetzt wurden
In einem realen Fall können Sie sowohl die WER- als auch die TER-Ergebnisse analysieren, um die gewünschten Verbesserungen zu erzielen.
Hinweis
Um TER messen zu können, müssen Sie sicherstellen, dass die Audio- und Transkripttestdaten Transkriptionen mit Anzeigeformatierungen wie Interpunktion, Großschreibung und ITN enthalten.
Beispielhafte Szenarioergebnisse
Spracherkennungsszenarien unterscheiden sich in Bezug auf die Audioqualität und die Sprache (Vokabular und Sprechweise). Die folgende Tabelle enthält Informationen zu vier gängigen Szenarien:
| Szenario | Audioqualität | Vokabular | Sprechweise |
|---|---|---|---|
| Callcenter | Niedrig, 8 kHz, zwei Personen auf einem Audiokanal sind möglich, könnte komprimiert werden | Eingeschränkt, auf jeweiliges Thema und Produkte bezogen | Interaktiv, locker strukturiert |
| Sprachassistent, z. B. Cortana oder ein Drive-Through-Fenster | Hoch, 16 kHz | Viele Entitäten (Songtitel, Produkte, Orte) | Klar gesprochene Wörter und Ausdrücke |
| Diktat (Sofortnachricht, Notizen, Suche) | Hoch, 16 kHz | Verschiedene | Festhalten von Notizen |
| Untertitelung für Videos | Variabel, z. B. vielfältige Mikrofonnutzung, hinzugefügte Musik | Variabel, aus Besprechungen, Rezitationen, Songtexten | Vorgelesen, vorbereitet oder locker strukturiert |
Unterschiedliche Szenarien führen zu Ergebnissen unterschiedlicher Qualität. Die folgende Tabelle enthält Informationen dazu, wie die Inhalte dieser vier Szenarien in Bezug auf die Wortfehlerrate (Word Error Rate, WER) abschneiden. In der Tabelle ist angegeben, welche Fehlertypen in den einzelnen Szenarien am häufigsten vorkommen. Die Einfüge-, Ersatz- und Löschungsfehlerraten helfen Ihnen, zu ermitteln, welche Art von Daten hinzugefügt werden soll, um das Modell zu verbessern.
| Szenario | Spracherkennungsqualität | Fehler beim Einfügen | Fehler beim Löschen | Fehler beim Ersetzen |
|---|---|---|---|---|
| Callcenter | Mittelstufe (WER ist < 30 %) |
Niedrig, sofern keine anderen Personen im Hintergrund sprechen | Ggf. hoch. In Callcentern kann es laut sein, und für das Modell kommt es durch sich überlappende Sprecher ggf. zu Verwirrung | Mittel. Namen von Produkten und Personen können diese Fehler verursachen |
| Sprachassistent | Hoch (WER kann < 10 % sein) |
Niedrig | Niedrig | Mittel, aufgrund von Songtiteln, Produktnamen oder Orten |
| Diktieren | Hoch (WER kann < 10 % sein) |
Niedrig | Niedrig | Hoch |
| Untertitelung für Videos | Je nach Videotyp (WER kann < 50 % sein) | Niedrig | Kann aufgrund von Musik, Nebengeräuschen, Mikrofonqualität hoch sein | Fachsprache kann diese Fehler verursachen. |