Überwachen der Metriken des NGINX-Eingangsdatencontrollers im Anwendungsrouting-Add-On mit Prometheus in Grafana (Vorschau)
Der NGINX-Eingangsdatencontroller im Anwendungsrouting-Add-On macht viele Metriken für Anforderungen, den NGINX-Prozess und den Controller verfügbar, die bei der Analyse der Leistung und Nutzung Ihrer Anwendung hilfreich sein können.
Das Anwendungsrouting-Add-On macht den Prometheus-Metrikendpunkt unter /metrics an Port 10254 verfügbar.
Wichtig
AKS-Previewfunktionen stehen gemäß dem Self-Service- und Aktivierungsprinzip zur Verfügung. Vorschauversionen werden „wie besehen“ und „wie verfügbar“ bereitgestellt und sind von den Vereinbarungen zum Service Level und der eingeschränkten Garantie ausgeschlossen. AKS-Vorschauversionen werden teilweise vom Kundensupport auf Grundlage der bestmöglichen Leistung abgedeckt. Daher sind diese Funktionen nicht für die Verwendung in der Produktion vorgesehen. Weitere Informationen finden Sie in den folgenden Supportartikeln:
Voraussetzungen
- AKS-Cluster (Azure Kubernetes Service) mit aktiviertem Anwendungsrouting-Add-On
- Prometheus-Instanz, z. B. verwalteter Azure Monitor-Dienst für Prometheus
- Grafana-Instanz, z. B. Azure Managed Grafana
Überprüfen des Metrikendpunkts
Um zu überprüfen, ob die Metriken erfasst werden, können Sie eine Portweiterleitung für einen der Pods des NGINX-Eingangsdatencontrollers einrichten.
kubectl get pods -n app-routing-system
NAME READY STATUS RESTARTS AGE
external-dns-667d54c44b-jmsxm 1/1 Running 0 4d6h
nginx-657bb8cdcf-qllmx 1/1 Running 0 4d6h
nginx-657bb8cdcf-wgcr7 1/1 Running 0 4d6h
Leiten Sie nun einen lokalen Port an Port 10254 auf einem der NGINX-Pods weiter.
kubectl port-forward nginx-657bb8cdcf-qllmx -n app-routing-system :10254
Forwarding from 127.0.0.1:43307 -> 10254
Forwarding from [::1]:43307 -> 10254
Notieren Sie sich den lokalen Port (in diesem Fall 43307), und öffnen Sie http://localhost:43307/metrics in Ihrem Browser. Die Metriken des NGINX-Eingangsdatencontrollers sollten jetzt geladen werden.
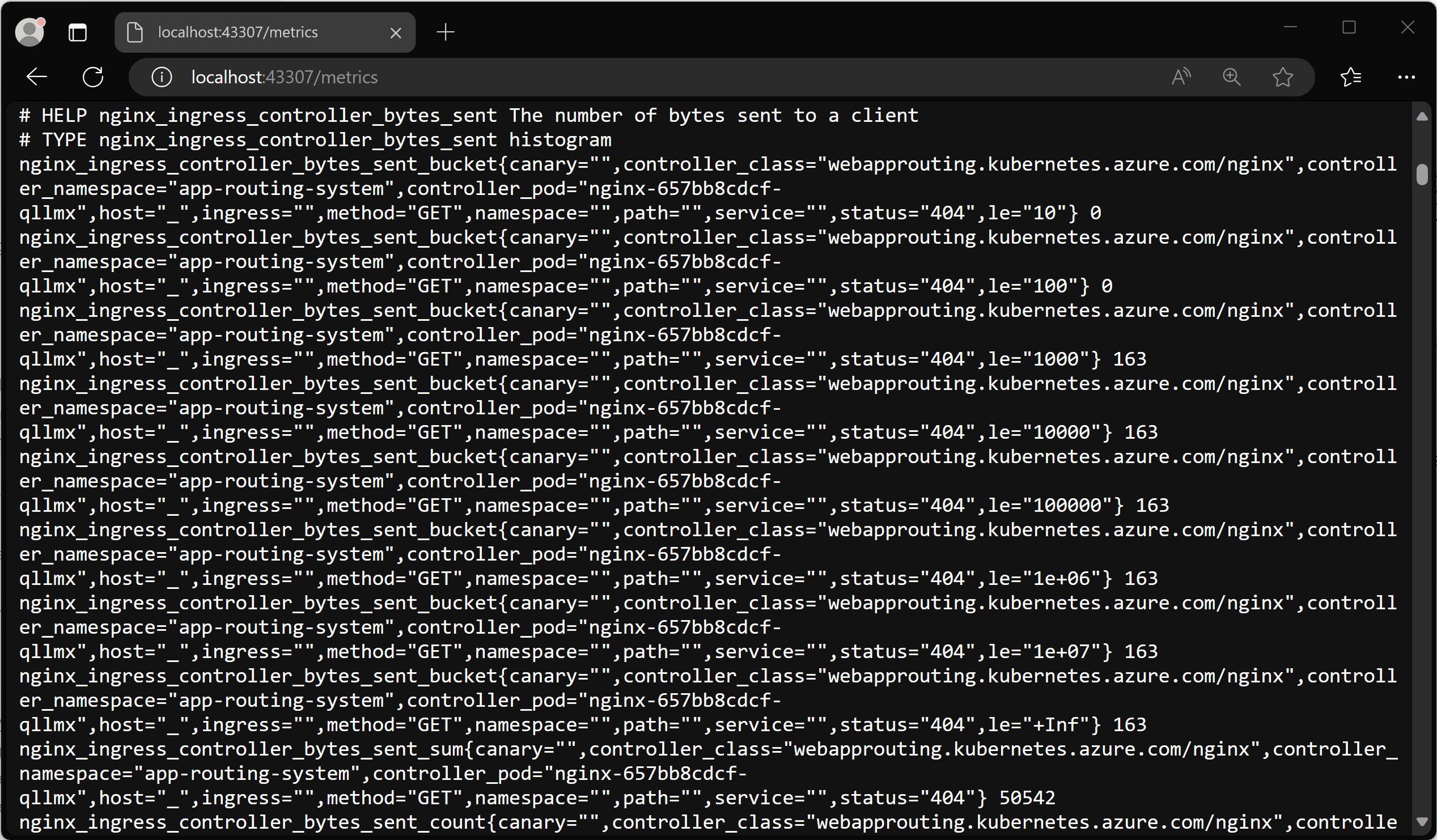
Sie können nun den port-forward-Prozess beenden, um die Weiterleitung zu schließen.
Konfigurieren des verwalteten Azure Monitor-Diensts für Prometheus und von Azure Managed Grafana mithilfe von Container Insights
Der verwaltete Azure Monitor-Dienst für Prometheus ist ein vollständig verwalteter Prometheus-kompatibler Dienst, der branchenübliche Features wie PromQL, Grafana-Dashboards und Prometheus-Warnungen unterstützt. Dieser Dienst erfordert, dass das Metrik-Add-On für den Azure Monitor-Agent, der Daten an Prometheus sendet, konfiguriert wird. Wenn Ihr Cluster nicht mit dem Add-On konfiguriert ist, können Sie diesen Artikel befolgen, um Ihren AKS-Cluster (Azure Kubernetes Service) so zu konfigurieren, dass Daten an den verwalteten Azure Monitor-Dienst für Prometheus gesendet und die gesammelten Metriken an eine Azure Managed Grafana-Instanz gesendet werden.
Aktivieren von auf Podanmerkungen basierendem Scraping
Nachdem Ihr Cluster mit dem Azure Monitor-Agent aktualisiert wurde, müssen Sie den Agent so konfigurieren, dass Scraping basierend auf Podanmerkungen aktiviert wird, die den NGINX-Eingangspods hinzugefügt werden. Eine Möglichkeit, diese Einstellung festzulegen, ist die ConfigMap ama-metrics-settings-configmap im Namespace kube-system.
Achtung
Dadurch wird Ihre vorhandene ConfigMap ama-metrics-settings-configmap in kube-system ersetzt. Wenn Sie bereits über eine Konfiguration verfügen, können Sie eine Sicherung erstellen oder sie mit dieser Konfiguration zusammenführen.
Sie können die vorhandene ConfigMap ama-metrics-settings-config sichern, indem Sie kubectl get configmap ama-metrics-settings-configmap -n kube-system -o yaml > ama-metrics-settings-configmap-backup.yaml ausführen.
Die folgende Konfiguration legt den Parameter podannotationnamespaceregex auf .* fest, um alle Namespaces auszulesen:
kubectl apply -f - <<EOF
kind: ConfigMap
apiVersion: v1
metadata:
name: ama-metrics-settings-configmap
namespace: kube-system
data:
schema-version:
#string.used by agent to parse config. supported versions are {v1}. Configs with other schema versions will be rejected by the agent.
v1
config-version:
#string.used by customer to keep track of this config file's version in their source control/repository (max allowed 10 chars, other chars will be truncated)
ver1
prometheus-collector-settings: |-
cluster_alias = ""
default-scrape-settings-enabled: |-
kubelet = true
coredns = false
cadvisor = true
kubeproxy = false
apiserver = false
kubestate = true
nodeexporter = true
windowsexporter = false
windowskubeproxy = false
kappiebasic = true
prometheuscollectorhealth = false
# Regex for which namespaces to scrape through pod annotation based scraping.
# This is none by default. Use '.*' to scrape all namespaces of annotated pods.
pod-annotation-based-scraping: |-
podannotationnamespaceregex = ".*"
default-targets-metrics-keep-list: |-
kubelet = ""
coredns = ""
cadvisor = ""
kubeproxy = ""
apiserver = ""
kubestate = ""
nodeexporter = ""
windowsexporter = ""
windowskubeproxy = ""
podannotations = ""
kappiebasic = ""
minimalingestionprofile = true
default-targets-scrape-interval-settings: |-
kubelet = "30s"
coredns = "30s"
cadvisor = "30s"
kubeproxy = "30s"
apiserver = "30s"
kubestate = "30s"
nodeexporter = "30s"
windowsexporter = "30s"
windowskubeproxy = "30s"
kappiebasic = "30s"
prometheuscollectorhealth = "30s"
podannotations = "30s"
debug-mode: |-
enabled = false
EOF
Die ama-metrics-Pods im kube-system-Namespace sollten in wenigen Minuten neu gestartet werden und die neue Konfiguration übernehmen.
Überprüfen der Visualisierung von Metriken in Azure Managed Grafana
Sie haben den verwalteten Azure Monitor-Dienst für Prometheus und Azure Managed Grafana konfiguriert und sollten nun auf Ihre Managed Grafana-Instanz zugreifen.
Es gibt zwei offizielle ingress-nginx-Dashboards, die Sie herunterladen und in Ihre Grafana-Instanz importieren können:
- Dashboard für den NGINX-Eingangsdatencontroller
- Dashboard für die Anforderungsverarbeitungsleistung
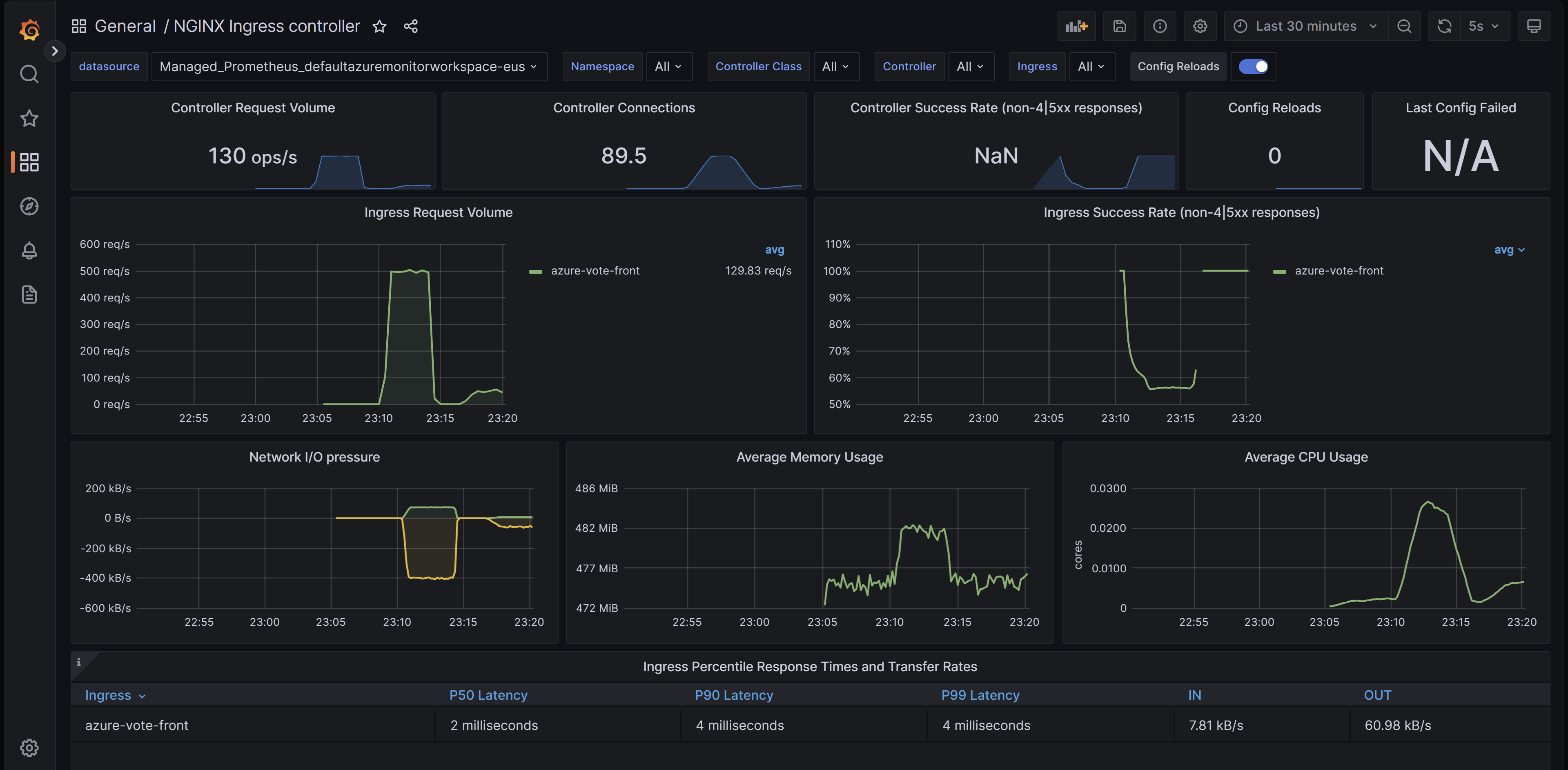
Dashboard für den NGINX-Eingangsdatencontroller
Mit diesem Dashboard erhalten Sie Einblick in Anforderungsvolumen, Verbindungen, Erfolgsraten, neu geladene Konfigurationen und nicht synchronisierte Konfigurationen. Sie können darüber auch die Netzwerk-E/A-Auslastung sowie die Arbeitsspeicher- und CPU-Auslastung des Eingangsdatencontrollers anzeigen. Schließlich werden auch die Antwortzeiten der Perzentile P50, P95 und P99 Ihrer Eingangsdaten und der Durchsatz angezeigt.
Sie können dieses Dashboard von GitHub herunterladen.
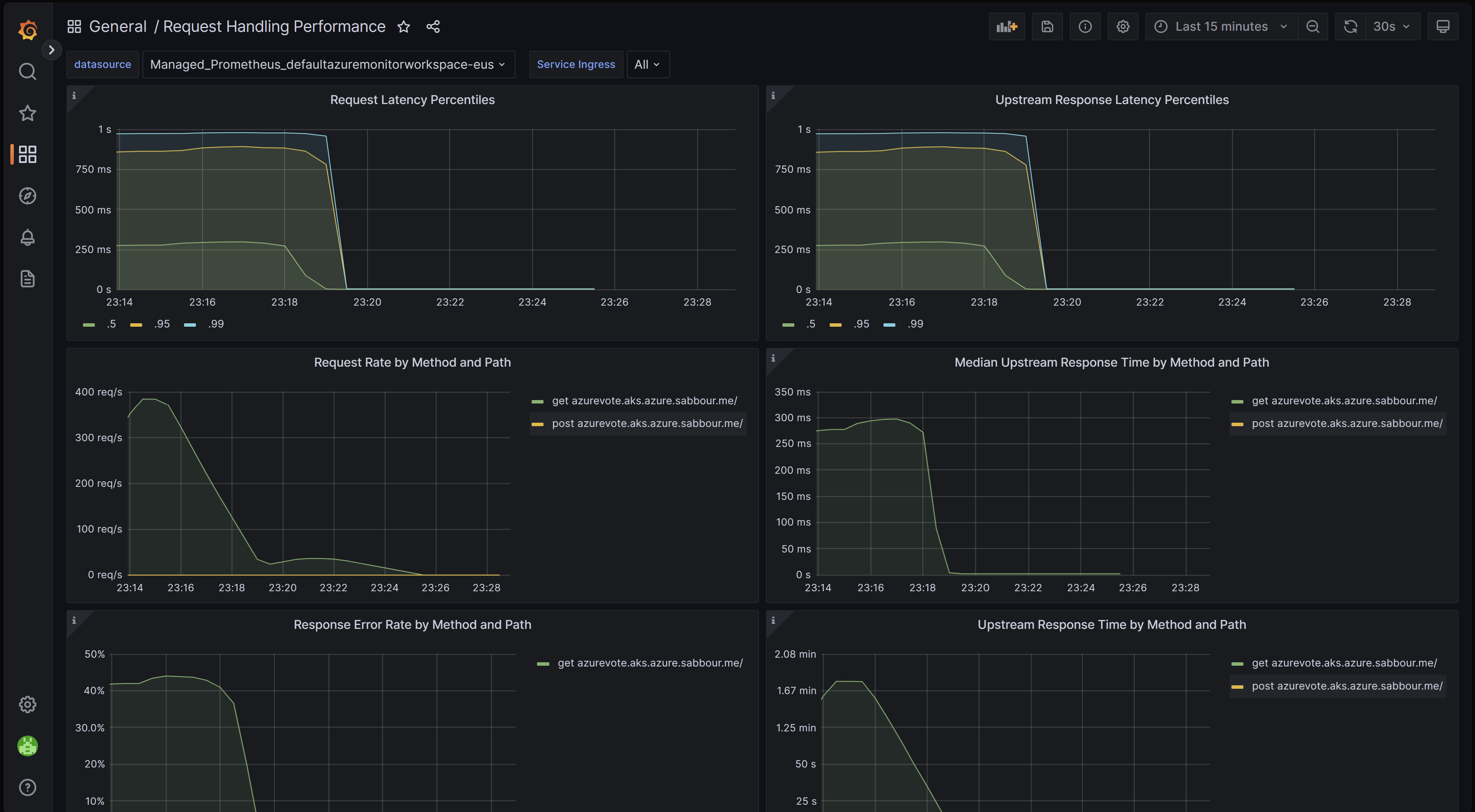
Dashboard für die Anforderungsverarbeitungsleistung
Mit diesem Dashboard erhalten Sie Einblick in die Leistung der Anforderungsverarbeitung der verschiedenen Eingangsupstreamziele, bei denen es sich um die Anwendungsendpunkte handelt, an die der Eingangscontroller Datenverkehr weiterleitet. Es zeigt das Perzentil P50, P95 und P99 der gesamten Anforderungs- und Upstreamantwortzeiten an. Sie können auch Aggregate von Anforderungsfehlern und Wartezeiten anzeigen. Verwenden Sie diese Dashboard, um die Leistung und Skalierbarkeit Ihrer Anwendungen zu überprüfen und zu verbessern.
Sie können dieses Dashboard von GitHub herunterladen.
Importieren eines Dashboards
Erweitern Sie zum Importieren eines Grafana-Dashboards das Menü auf der linken Seite, und klicken Sie unter „Dashboards“ auf Importieren.
Laden Sie dann die gewünschte Dashboarddatei hoch, und klicken Sie auf Laden.
Nächste Schritte
- Sie können die Skalierung Ihrer Workloads mithilfe von Eingangsmetriken konfigurieren, die mit Prometheus über Kubernetes Event-Driven Autoscaler (KEDA) ausgelesen werden. Erfahren Sie mehr über die Integration von KEDA in AKS.
- Mit Azure Load Testing können Sie einen Auslastungstest erstellen und ausführen, um die Workloadleistung zu testen und die Skalierbarkeit Ihrer Anwendungen zu optimieren.