Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Front Door
Azure API Management
Azure Kubernetes Service (AKS)
Azure Application Gateway
Dynamics 365
Der Erfolg Ihrer Cloudlösung hängt von ihrer Zuverlässigkeit ab. Zuverlässigkeit kann grob als die Wahrscheinlichkeit definiert werden, dass das System unter den gegebenen Umgebungsbedingungen und unter Einhaltung der Zeitvorgaben wie erwartet funktioniert. Das Site Reliability Engineering (SRE) umfasst eine Reihe von Prinzipien und Methoden für die Erstellung skalierbarer und äußerst zuverlässiger Softwaresysteme. SRE wird beim Entwerfen von digitalen Diensten immer öfter eingesetzt, um für eine höhere Zuverlässigkeit zu sorgen.
Weitere Informationen zu SRE-Strategien finden Sie unter AZ-400: Entwickeln einer Site Reliability Engineering-Strategie (SRE).
Mögliche Anwendungsfälle
Die Konzepte in diesem Artikel gelten für:
- API-basierte Clouddienste
- Öffentlich zugängliche Webanwendungen
- IoT- oder ereignisbasierte Workloads
Architektur

Laden Sie eine PowerPoint-Datei zu dieser Architektur herunter.
Die hier dargestellte Architektur entspricht der Architektur einer skalierbaren API-Plattform. Die Lösung besteht aus mehreren Microservices, die verschiedene Datenbanken und Speicherdienste verwenden, einschließlich SaaS-Lösungen (Software as a Service) wie Dynamics 365 und Microsoft 365.
In diesem Artikel wird eine Lösung behandelt, die allgemeine Marketplace- und E-Commerce-Anwendungsfälle behandelt, um die im Diagramm dargestellten Blöcke zu veranschaulichen. Die Anwendungsfälle sind:
- Produktsuche
- Registrierung und Anmeldung
- Anzeige von Inhalten, z. B. Nachrichtenartikel
- Bestellungs- und Abonnementverwaltung
Clientanwendungen wie Web-Apps, mobile Apps und sogar Dienstanwendungen nutzen die API-Plattformdienste über einen einheitlichen Zugriffspfad: https://api.contoso.com.
Komponenten
- Azure Front Door dient als sicherer, einheitlicher Einstiegspunkt für alle Anforderungen, die an die Lösung gesendet werden. Weitere Informationen finden Sie unter Übersicht über die Routingarchitektur.
- Mit Azure API Management wird eine Governanceebene oberhalb von allen veröffentlichten APIs bereitgestellt. Sie können Azure API Management-Richtlinien verwenden, um auf der API-Ebene zusätzliche Funktionen anzuwenden, z. B. Zugriffsbeschränkungen, Zwischenspeicherung und Datentransformation. API Management unterstützt die automatische Skalierung für die Standard- und Premium-Ebene.
- Azure Kubernetes Service (AKS) ist die Azure-Implementierung von Kubernetes-Open-Source-Clustern. Azure übernimmt als gehosteter Kubernetes-Dienst wichtige Aufgaben, z. B. Systemüberwachung und -wartung. Da Azure den Kubernetes-API-Server verwaltet, steuern und warten Sie nur die Agentknoten. Bei dieser Architektur werden alle Microservices in AKS bereitgestellt.
- Azure Application Gateway ist ein Controllerdienst für die Anwendungsbereitstellung. Er arbeitet auf der Anwendungsschicht (Layer 7) und verfügt über verschiedene Lastenausgleichsfunktionen. Der Application Gateway-Eingangsdatencontroller (Application Gateway Ingress Controller, AGIC) ist eine Kubernetes-Anwendung, mit der Kunden von Azure Kubernetes Service (AKS) den nativen L7-Lastenausgleich von Application Gateway in Azure nutzen können, um Cloudsoftware im Internet verfügbar zu machen. Die automatische Skalierung und die Zonenredundanz werden für die v2-SKU unterstützt.
- Mit Azure Storage, Azure Data Lake Storage, Azure Cosmos DB und Azure SQL kann sowohl strukturierter als auch nicht strukturierter Inhalt gespeichert werden. Azure Cosmos DB-Container und -Datenbanken können mit Durchsatz mit automatischer Skalierung erstellt werden.
- Microsoft Dynamics 365 ist ein SaaS-Angebot (Software as a Service) von Microsoft, das mehrere Geschäftsanwendungen für Kundendienst, Vertrieb, Marketing und Finanzen bereitstellt. In dieser Architektur wird Dynamics 365 in erster Linie für die Verwaltung von Produktkatalogen und für die Verwaltung von Kundendienst verwendet. Skalierungseinheiten sorgen bei Dynamics 365-Anwendungen für Resilienz.
- Microsoft 365 (vormals Office 365) wird als Content-Management-System für Unternehmen verwendet und basiert auf Microsoft 365 SharePoint in Microsoft 365. Es wird genutzt, um Inhalte, z. B. Medienobjekte und Dokumente, zu erstellen, zu verwalten und zu veröffentlichen.
Alternativen
Da für diese Lösung eine hochgradig skalierbare Architektur auf Basis von Microservices verwendet wird, sollten Sie für die Computeebene die folgenden Alternativen in Betracht ziehen:
- Azure Functions für serverlose API-Dienste
- Azure Spring Apps für Java-basierte Microservices
Angemessene Zuverlässigkeit
Der Zuverlässigkeitsgrad, der für eine Lösung erforderlich ist, richtet sich nach dem Geschäftskontext. Für ein Einzelhandelsgeschäft, das 14 Stunden lang geöffnet ist und bei dem es innerhalb dieses Zeitraums zu Spitzenauslastungen des Systems kommt, gelten andere Anforderungen als für einen Onlineshop, der jederzeit Bestellungen annehmen kann. SRE-Methoden können so angepasst werden, dass ein angemessener Zuverlässigkeitsgrad erreicht wird.
Die Zuverlässigkeit wird anhand von Servicelevelzielen (Service Level Objectives, SLOs), mit denen für einen Dienst der Ziellevel in Bezug auf die Zuverlässigkeit festgelegt wird, definiert und gemessen. Mit der Erreichung des Ziellevels wird sichergestellt, dass die Kunden zufrieden sind. Die SLO-Ziele können sich je nach den Anforderungen des Unternehmens weiterentwickeln bzw. ändern. Die Besitzer der Dienste sollten die Zuverlässigkeit aber regelmäßig anhand der SLOs messen, um Probleme erkennen und Korrekturmaßnahmen ergreifen zu können. SLOs werden normalerweise als der erzielte Erfolgswert (in Prozent) in einem bestimmten Zeitraum definiert.
Ein weiterer wichtiger Begriff ist der Servicelevelindikator (SLI). Dies ist die Metrik, die zum Berechnen des SLO-Werts verwendet wird. SLIs basieren auf Erkenntnissen aus Daten, die erfasst werden, während der Kunde den Dienst nutzt. SLIs werden immer aus Sicht eines Kunden gemessen.
SLOs und SLIs gehen immer Hand in Hand und werden normalerweise iterativ definiert. SLOs basieren auf wichtigen Geschäftszielen, während SLIs davon abhängig sind, welche Messungen beim Implementieren des Diensts durchgeführt werden können.
Die folgende Abbildung zeigt die Beziehung zwischen der überwachten Metrik, dem SLI und dem SLO:
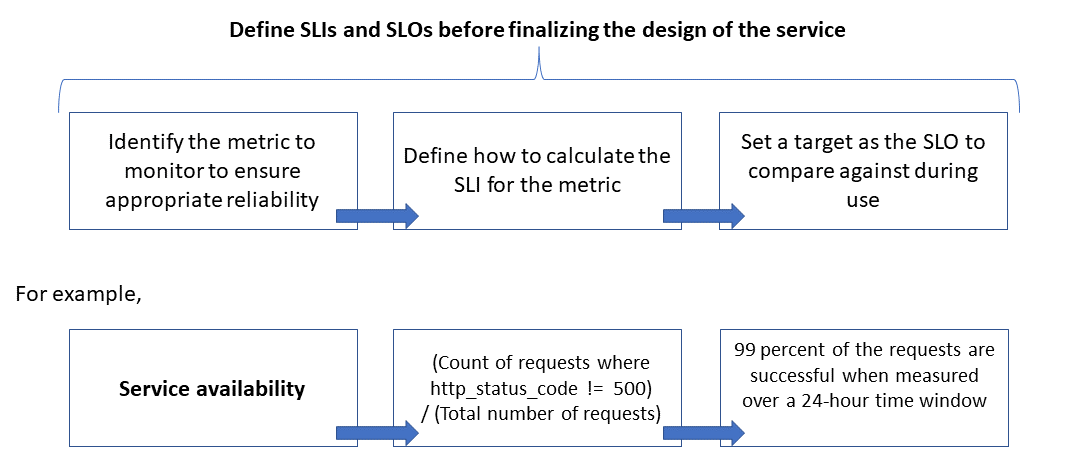
Weitere Informationen zu diesem Prozess finden Sie unter Define SLI metrics to calculate SLOs.
Modellieren der Erwartungen in Bezug auf die Skalierung und Leistung
Bei einem Softwaresystem ist mit der Leistung normalerweise die allgemeine Reaktionsfähigkeit des Systems gemeint, wenn eine Aktion innerhalb eines bestimmten Zeitraums ausgeführt werden soll. Bei der Skalierbarkeit geht es um die Fähigkeit des Systems, erhöhte Auslastungen durch Benutzer zu bewältigen, ohne dass die Leistung beeinträchtigt wird.
Ein System wird als skalierbar angesehen, wenn die zugrunde liegenden Ressourcen dynamisch verfügbar gemacht werden können, um eine gestiegene Auslastung zu unterstützen. Cloudanwendungen müssen auf Skalierbarkeit ausgelegt sein, und das Datenverkehrsvolumen ist manchmal nicht leicht vorherzusagen. Die Skalierungsanforderungen können sich durch saisonale Spitzenlasten erhöhen, z. B. wenn ein Dienst Anforderungen für mehrere Mandanten verarbeitet.
Es hat sich bewährt, Anwendungen so zu entwerfen, dass die Cloudressourcen bei Bedarf automatisch hoch- und herunterskaliert werden, um die Auslastungsanforderungen zu erfüllen. Das System sollte sich an die Zunahme der Workloads anpassen, indem Ressourcen inkrementell zugeordnet oder bereitgestellt werden, um den Bedarf zu erfüllen. Skalierbarkeit bezieht sich nicht nur auf Compute-Instanzen, sondern auch auf andere Elemente wie Datenspeicherung und Messaginginfrastruktur.
In diesem Artikel wird veranschaulicht, wie Sie die angemessene Zuverlässigkeit für eine Cloudanwendung sicherstellen können, indem Sie eine Skalierungs- und Leistungsmodellierung für die Workloadszenarien durchführen und die Ergebnisse zum Definieren der Überwachungen, SLIs und SLOs verwenden.
Überlegungen
Anleitungen zur Entwicklung von skalierbaren und zuverlässigen Anwendungen finden Sie unter den Säulen Zuverlässigkeit und Leistungseffizienz des Azure Well-Architected Framework.
In diesem Artikel wird beschrieben, wie Sie Verfahren zur Skalierbarkeits- und Leistungsmodellierung anwenden, um die Architektur und den Entwurf der Lösung zu optimieren. Mit diesen Verfahren werden Änderungen an den Transaktionsdatenflüssen ermittelt, die erforderlich sind, um eine optimale Benutzerfreundlichkeit zu erzielen. Treffen Sie Ihre technischen Entscheidungen basierend auf den nicht funktionsbezogenen Anforderungen der Lösung. Der Vorgang umfasst folgende Schritte:
- Ermitteln der Skalierbarkeitsanforderungen
- Modellieren der erwarteten Last
- Definieren der SLIs und SLOs für die Benutzerszenarien
Hinweis
Azure Application Insights ist Teil von Azure Monitor und ein leistungsstarkes Tool für die Steuerung der Anwendungsleistung (Application Performance Management, APM), das Sie leicht in Ihre Anwendungen integrieren können, um Telemetriedaten zu senden und anwendungsspezifische Metriken zu analysieren. Darüber hinaus verfügt das Tool über sofort einsatzbereite Dashboards und ein Metrik-Explorer zum Analysieren der Daten für Ihre geschäftlichen Anforderungen.
Erfassen von Skalierbarkeitsanforderungen
Gehen Sie von den folgenden Spitzenlastmetriken aus:
- Anzahl von Verbrauchern, die die API-Plattform nutzen: 1,5 Millionen
- Aktive Verbraucher pro Stunde (30 Prozent von 1,5 Millionen): 450.000
- Auslastung in Prozent pro Aktivität:
- Produktsuche: 75 Prozent
- Registrierung, einschließlich Profilerstellung und Anmeldung: 10 Prozent
- Verwaltung von Bestellungen und Abonnements: 10 Prozent
- Inhaltsanzeige: 5 Prozent
Die Last (normale Spitzenlast) führt für die APIs, die von der Plattform gehostet werden, zu den folgenden Skalierungsanforderungen:
- Microservice für Produkt: ca. 500 Anforderungen pro Sekunde (Requests Per Second, RPS)
- Microservice für Profil: ca. 100 RPS
- Microservice für Bestellungen und Zahlung: ca. 100 RPS
- Microservice für Inhalt: ca. 50 RPS
Bei diesen Skalierungsanforderungen werden saisonale und zufällige Spitzenlasten sowie Spitzenlasten bei speziellen Ereignissen, z. B. Marketingaktionen, nicht berücksichtigt. Während der Spitzenzeiten sind die Skalierungsanforderungen für einige Benutzeraktivitäten gegenüber der normalen Spitzenlast bis zu zehnmal höher. Berücksichtigen Sie diese Einschränkungen und zu erwartenden Lasten, wenn Sie die Entwurfsentscheidungen für die Microservices treffen.
Definieren von SLI-Metriken für die Berechnung von SLOs
Mit SLI-Metriken wird angegeben, wie hoch die Benutzerfreundlichkeit eines Diensts ist. Dies kann als das Verhältnis der guten Ereignisse zu den Gesamtereignissen ausgedrückt werden.
Bei einem API-Dienst beziehen sich die Ereignisse auf die anwendungsspezifischen Metriken, die während der Ausführung in Form von Telemetriedaten oder verarbeiteten Daten erfasst werden. Dieses Beispiel verfügt über die folgenden SLI-Metriken:
| Metrik | Beschreibung des Dataflows |
|---|---|
| Verfügbarkeit | Anforderung wurde von der API verarbeitet: Ja/Nein |
| Latenz | Zeitraum für die Verarbeitung der Anforderung durch die API und die Rückgabe einer Antwort |
| Durchsatz | Anzahl von Anforderungen, die von der API verarbeitet wurden |
| Erfolgsrate | Anzahl von Anforderungen, die von der API erfolgreich verarbeitet wurden |
| Fehlerrate | Anzahl von Fehlern für die Anforderungen, die von der API verarbeitet wurden |
| Aktualität | Häufigkeit, mit der der Benutzer die neuesten Daten für die Lesevorgänge der API erhalten hat, obwohl der zugrunde liegende Datenspeicher mit einer bestimmten Schreiblatenz aktualisiert wurde |
Hinweis
Achten Sie darauf, dass Sie auch alle weiteren SLIs ermitteln, die für Ihre Lösung wichtig sind.
Hier sind Beispiele für SLIs angegeben:
- (Anzahl von Anforderungen, die in weniger als 1.000 ms erfolgreich abgeschlossen wurden)/(Anzahl von Anforderungen)
- (Anzahl von Suchergebnissen, in denen innerhalb von drei Sekunden alle im Katalog veröffentlichten Produkte zurückgegeben werden)/(Anzahl von Suchvorgängen)
Nachdem Sie die SLIs definiert haben, bestimmen Sie, welche Ereignisse oder Telemetriedaten für die Messung erfasst werden sollen. Zum Messen der Verfügbarkeit erfassen Sie beispielsweise Ereignisse, um anzugeben, ob der API-Dienst eine Anforderung erfolgreich verarbeitet hat. Bei HTTP-basierten Diensten wird „Erfolg“ oder „Fehler“ mit HTTP-Statuscodes angegeben. Beim Entwerfen und Implementieren der API müssen die richtigen Codes angegeben werden. Im Allgemeinen sind SLI-Metriken eine wichtige Voraussetzung für die API-Implementierung.
Bei cloudbasierten Systemen können Sie einige Metriken abrufen, indem Sie die Diagnose- und Überwachungsfunktionen verwenden, die für die Ressourcen verfügbar sind. Azure Monitor ist eine umfassende Lösung, mit der Sie Telemetriedaten aus Ihren Clouddiensten erfassen und analysieren und entsprechende Maßnahmen ergreifen können. Je nach Ihren SLI-Anforderungen können noch weitere Überwachungsdaten erfasst werden, um die Metriken zu berechnen.
Verwenden von Quantilverteilungen
Einige SLIs werden mithilfe eines Verfahrens zur Quantilverteilung berechnet. Dies ermöglicht eine Verbesserung der Ergebnisse, wenn Ausreißer vorhanden sind, die bei anderen Verfahren, z. B. Mittelwert- oder Medianverteilungen, zu Verzerrungen führen können.
Beachten Sie beispielsweise, dass die Metrik die Latenz der API-Anforderungen ist und dass der Schwellenwert für die optimale Leistung drei Sekunden beträgt. Die sortierten Antwortzeiten für API-Anforderungen im Zeitraum einer Stunde zeigen, dass nur wenige Anforderungen länger als drei Sekunden dauern und für die meisten Antworten der Schwellenwert nicht überschritten wird. Dies ist das erwartete Verhalten des Systems.
Bei der Quantilverteilung sollen Ausreißer ausgeschlossen werden, die durch zeitweilige Probleme verursacht werden. Wenn sich die richtigen Dienstantworten beispielsweise innerhalb des 90. oder 95. Quantils bewegen, wird das Servicelevelziel (SLO) als erreicht angesehen.
Auswählen der richtigen Messzeiträume
Der Messzeitraum ist beim Festlegen eines SLO-Werts sehr wichtig. Damit die Ergebnisse in Bezug auf die Benutzerfreundlichkeit aussagekräftig sind, muss nicht der Leerlauf, sondern die Aktivität erfasst werden. Je nachdem, wie Sie die SLI-Metrik überwachen und berechnen möchten, kann dieses Zeitfenster zwischen 5 Minuten und 24 Stunden lang sein.
Einrichten eines Governanceprozesses für die Leistung
Die Leistung einer API muss von ihrer Inbetriebnahme bis zur Einstufung als „veraltet“ bzw. bis zur Aussonderung gesteuert werden. Ein robuster Governanceprozess muss eingerichtet sein, um sicherzustellen, dass Leistungsprobleme frühzeitig erkannt und behoben werden, bevor sie einen großen Ausfall verursachen, der sich auf das Unternehmen auswirkt.
Hier sind die Elemente eines Governanceprozesses für die Leistung angegeben:
Diagramm, das die sieben Elemente der Leistungssteuerung zeigt, wie im folgenden Abschnitt beschrieben.
- Leistungsziele: Definieren Sie gewünschten SLOs in Bezug auf die Leistung für die Geschäftsszenarien.
- Leistungsmodellierung: Identifizieren Sie unternehmenskritische Workflows und Transaktionen, und führen Sie die Modellierung durch, um die leistungsbezogenen Auswirkungen zu verstehen. Führen Sie eine präzisere Erfassung dieser Informationen durch, um genauere Vorhersagen zu erhalten.
- Entwurfsrichtlinien: Legen Sie Entwurfsrichtlinien in Bezug auf die Leistung fest, und empfehlen Sie die Durchführung der entsprechenden Änderungen am Geschäftsworkflow. Stellen Sie sicher, dass die Teams diese Richtlinien verstehen.
- Implementierung von Richtlinien: Implementieren Sie Entwurfsrichtlinien in Bezug auf die Leistung für die Lösungskomponenten, einschließlich der Instrumentierung für die Erfassung von Metriken. Führen Sie Überprüfungen des Leistungsentwurfs durch. Es ist sehr wichtig, alle diese Daten für die einzelnen Teams mithilfe von Architektur-Backlog Items nachzuverfolgen.
- Leistungstests: Führen Sie Auslastungs- und Belastungstests in Übereinstimmung mit der Auslastungsprofilverteilung durch, um die Metriken zur Plattformintegrität zu erfassen. Sie können diese Tests auch für eine begrenzte Auslastung durchführen, um einen Benchmarkwert für die Anforderungen der Lösungsinfrastruktur zu erhalten.
- Engpassanalyse: Nutzen Sie Codeuntersuchungen und Code Reviews, um Leistungsengpässe verschiedener Komponenten zu identifizieren, zu analysieren und zu beseitigen. Identifizieren Sie Erweiterungen in Bezug auf die horizontale oder vertikale Skalierung, die zur Unterstützung der Spitzenlasten erforderlich sind.
- Kontinuierliche Überwachung: Richten Sie im Rahmen der DevOps-Prozesse eine Infrastruktur für die fortlaufende Überwachung und Benachrichtigung ein. Stellen Sie sicher, dass die betroffenen Teams benachrichtigt werden, wenn sich die Antwortzeiten im Vergleich zu den Benchmarkwerten erheblich verschlechtern.
- Governanceprozess für die Leistung: Legen Sie einen Governanceprozess für die Leistung mit eindeutig definierten Prozessen und Teams fest, der als Grundlage für die Leistungs-SLOs dient. Verfolgen Sie die Konformität nach jedem Release nach, um Einbußen aufgrund von Buildupgrades zu vermeiden. Führen Sie regelmäßig Überprüfungen durch, um gestiegene Lasten zu erkennen, die Lösungsupgrades erforderlich machen.
Wiederholen Sie diese Schritte während der gesamten Lösungsentwicklung, um für einen ständigen Verbesserungsprozess zu sorgen.
Nachverfolgen von Leistungszielen und Erwartungen in Ihrem Backlog
Verfolgen Sie Ihre Leistungsziele nach, um sicherzustellen, dass sie erreicht werden. Erfassen Sie präzise und detaillierte Benutzerberichte für die Nachverfolgung. Hierdurch wird sichergestellt, dass Entwicklungsteams den Aktivitäten des Governanceprozesses für die Leistung eine hohe Priorität zuordnen.
Festlegen von gewünschten SLOs für die Ziellösung
Hier sind Beispiele für gewünschte SLOs für die vorliegende API-Plattformlösung aufgeführt:
- Antwortet innerhalb von einer Sekunde auf 95 Prozent aller READ-Anforderungen eines Tags.
- Antwortet innerhalb von drei Sekunden auf 95 Prozent aller CREATE- und UPDATE-Anforderungen eines Tags.
- Antwortet innerhalb von fünf Sekunden ohne Fehler auf 99 Prozent aller Anforderungen eines Tags.
- Antwortet innerhalb von fünf Sekunden erfolgreich auf 99,9 Prozent aller Anforderungen eines Tags.
- Für weniger als 1 Prozent der Anforderungen während des einstündigen Spitzenlast-Zeitfensters tritt ein Fehler auf.
Die SLOs können an bestimmte Anwendungsanforderungen angepasst werden. Es ist aber sehr wichtig, hierbei präzise und eindeutig genug vorzugehen, damit die Zuverlässigkeit sichergestellt ist.
Messen der anfänglichen SLOs, die auf Daten aus den Protokollen basieren
Überwachungsprotokolle werden automatisch erstellt, wenn der API-Dienst verwendet wird. Gehen Sie davon aus, dass eine Woche von Daten die folgenden Ergebnisse zeigt:
- Anforderungen: 123.456
- Erfolgreiche Anforderungen: 123.204
- Latenz 90. Quantil: 497 ms
- Latenz 95. Quantil: 870 ms
- Latenz 99. Quantil: 1.024 ms
Aus diesen Daten ergeben sich die folgenden anfänglichen SLIs:
- Verfügbarkeit = (123.204/123.456) = 99,8 Prozent
- Latenz = mindestens 90 Prozent der Anforderungen wurden innerhalb von 500 ms verarbeitet
- Latenz = ca. 98 Prozent der Anforderungen wurden innerhalb von 1.000 ms verarbeitet
Angenommen, während der Planung wird als gewünschtes SLO-Ziel für die Latenz festgelegt, dass im Zeitraum einer Woche 90 Prozent der Anforderungen innerhalb von 500 ms mit einer Erfolgsrate von 99 Prozent verarbeitet werden sollen. Anhand der Protokolldaten können Sie leicht ermitteln, ob das SLO-Ziel erreicht wurde. Wenn Sie diese Art von Analyse einige Wochen lang durchführen, können Sie die Trends in Bezug auf die SLO-Konformität erkennen.
Anleitung zur technischen Risikominderung
Verwenden Sie die folgende Checkliste mit den empfohlenen Methoden, um Skalierbarkeits- und Leistungsrisiken zu minimieren:
- Achten Sie beim Entwerfen auf die Skalierung und die Leistung.
- Stellen Sie sicher, dass Sie die Skalierungsanforderungen für jedes Benutzerszenario und jede Workload erfassen, einschließlich Saisonalität und Spitzen.
- Führen Sie die Leistungsmodellierung durch, um für das System Einschränkungen und Engpässe zu ermitteln.
- Managen Sie die technischen Schulden.
- Führen Sie eine umfassende Ablaufverfolgung der Leistungsmetriken durch.
- Erwägen Sie die Verwendung von Skripts zum Ausführen von Tools wie K6.io, Karate und JMeter in Ihrer Stagingumgebung für die Entwicklung mit unterschiedlichen Benutzerlasten, z. B. 50 bis 100 RPS. Hierdurch enthalten die Protokolle dann Informationen, die für die Erkennung von Entwurfs- und Implementierungsproblemen hilfreich sind.
- Integrieren Sie die Skripts für automatisierte Tests in Ihre Continuous Deployment-Prozesse (CD), um Buildunterbrechungen zu erkennen.
- Achten Sie auf eine Produktionsmentalität.
- Passen Sie die Schwellenwerte für die automatische Skalierung gemäß den Integritätsstatistiken an.
- Bevorzugen Sie horizontale gegenüber vertikalen Skalierungsverfahren.
- Gehen Sie bei der Skalierung proaktiv vor, um saisonale Spitzen abzudecken.
- Bevorzugen Sie Bereitstellungen auf Ringbasis.
- Verwenden Sie Fehlerbudgets für Experimente.
Preise
Zuverlässigkeit, Leistungseffizienz und Kostenoptimierung gehen Hand in Hand. Die in der Architektur verwendeten Azure-Dienste tragen zur Kostensenkung bei, da sie automatisch skaliert werden, um sich ändernde Benutzerlasten abzudecken.
Bei AKS können Sie zu Beginn VMs mit Standardgrößen für den Knotenpool nutzen. Anschließend können Sie die Ressourcenanforderungen während der Entwicklung oder der Nutzung in der Produktion überwachen und entsprechende Anpassungen vornehmen.
Die Kostenoptimierung ist eine Säule des Microsoft Azure Well-Architected Framework. Weitere Informationen finden Sie unter Übersicht über die Säule „Kostenoptimierung“. Nutzen Sie den Preisrechner, falls Sie eine Kostenschätzung für Azure-Produkte und -Konfigurationen benötigen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Subhajit Chatterjee | Leitender Softwareentwickler
Nächste Schritte
- Azure-Dokumentation
- Microsoft Azure Well-Architected Framework
- Architekturstil für Microservices
- Ausrichtung des Entwurfs auf Aufskalierung
- Auswählen eines Azure-Computediensts für Ihre Anwendung
- Microservicearchitektur in Azure Kubernetes Service
- Was ist Azure Front Door?
- Informationen zu API Management
- Was ist der Application Gateway-Eingangscontroller?
- Azure Kubernetes-Dienst
- Automatische Skalierung und zonenredundantes Application Gateway v2
- Automatisches Skalieren eines Clusters, um Anwendungsanforderungen für Azure Kubernetes Service (AKS) zu erfüllen
- Erstellen von Azure Cosmos DB-Containern und -Datenbanken mit automatisch skaliertem Durchsatz
- Microsoft Dynamics 365: Dokumentation
- Dokumentation zu Microsoft 365
- Dokumentation zum Websitezuverlässigkeits-Engineering (Site Reliability Engineering, SRE)
- AZ-400: Entwickeln einer Site Reliability Engineering-Strategie (SRE)
- Baselinewebanwendung mit Zonenredundanz