In einem typischen Fall von Onlinebetrug führt der Dieb mehrere Transaktionen durch, was zu einem Verlust von Tausenden von Dollar führt. Aus diesem Grund muss die Betrugserkennung in Quasi-Echtzeit erfolgen. Mehr als 800 Millionen Menschen verwenden mobile Apps. Wenn diese Zahl steigt, nimmt auch der Betrug beim mobilen Banking zu. Die Finanzbranche verzeichnet im Vergleich zum Vorjahr einen 100-prozentigen Anstieg der Verluste, die durch den Zugriff über mobile Plattformen verursacht werden. Aber es gibt eine Risikominderung. In diesem Artikel wird eine Lösung vorgestellt, die Azure-Technologie verwendet, um eine betrügerische Transaktion beim mobilen Banking innerhalb von zwei Sekunden zu erkennen. Die hier vorgestellte Architektur basiert auf einer realen Lösung.
Herausforderungen: Seltene Fälle von Betrug und starre Regeln
Die meisten Betrugsfälle mit Mobiltelefonen treten auf, wenn ein SIM-Swap-Angriff verwendet wird, um eine Mobiltelefonnummer zu kompromittieren. Die Telefonnummer wird geklont und der Kriminelle erhält die SMS-Benachrichtigungen und Anrufe, die an das mobile Gerät des Opfers gesendet werden. Der Kriminelle verschafft sich dann Anmeldeinformationen mithilfe von Social Engineering, Phishing, Vishing (Phishing über ein Telefon) oder einer infizierten heruntergeladenen App. Mit diesen Informationen kann sich der Kriminelle als Kunde einer Bank ausgeben, sich für den mobilen Zugriff registrieren und sofort Geldüberweisungen und Abhebungen generieren.
Betrug beim mobilen Banking ist schwer zu erkennen und teuer für Verbraucher und Banken. Die erste Herausforderung ist, dass es selten ist. Weniger als 1 Prozent aller Transaktionen sind betrügerisch, sodass es einige Zeit dauern kann, bis ein Betrugs- oder Fallverwaltungsteam die potenziell betrügerischen Transaktionen durchgesehen hat, um die betrügerischen Transaktionen zu identifizieren. Eine zweite Herausforderung besteht darin, dass viele Lösungen zur Betrugsüberwachung auf regelbasierten Engines basieren. Traditionell sind regelbasierte Engines effektiv bei der Erkennung etablierter Muster betrugsähnlicher Transaktionen, die von riskanten IP-Adressen generiert werden, oder mehreren Transaktionen, die innerhalb eines kurzen Zeitraums auf einem neuen Konto generiert werden. Aber regelbasierte Engines haben eine wesentliche Einschränkung: Regeln passen sich nicht schnell an neue oder sich entwickelnde Arten von Angriffen an. Sie sind auf folgende Weise eingeschränkt:
- Die Erkennung erfolgt nicht in Echtzeit, sodass der Betrug erst nach einem finanziellen Verlust entdeckt wird.
- Regeln sind binär und begrenzt. Sie werden der Komplexität und den Kombinationen von Eingabevariablen, die ausgewertet werden können, nicht gerecht. Diese Einschränkung führt zu einer hohen Anzahl von False Positive-Ergebnissen.
- Regeln sind in Geschäftslogik hartcodiert. Das Anpassen der Regeln, das Einbeziehen neuer Datenquellen oder das Hinzufügen neuer Betrugsmuster erfordert in der Regel Änderungen in der Anwendung, die sich auf einen Geschäftsprozess auswirken. Die Weitergabe von Änderungen in einem Geschäftsprozess kann mühsam und teuer sein.
KI-Modelle können die Betrugserkennungsraten und die Erkennungszeiten drastisch verbessern. Die Banken verwenden diese Modelle zusammen mit anderen Ansätzen, um Verluste zu reduzieren. Der hier beschriebene Prozess basiert auf drei Elementen:
- Ein KI-Modell, das auf eine festgelegte Anzahl von Verhaltensmerkmalen reagiert
- Eine Methodik für maschinelles Lernen
- Ein Modellauswertungsprozess, der dem ähnelt, den ein Betrugsmanager zur Auswertung eines Portfolios verwendet
Operativer Kontext
Bei der Bank, auf der diese Lösung basiert, kam es zu einem sprunghaften Anstieg der Betrugsfälle über den mobilen Kanal, als die Kunden verstärkt digitale Dienste verwendeten. Es war an der Zeit, dass die Bank ihren Ansatz zur Betrugserkennung und -prävention überdachte. Diese Lösung begann mit Fragen, die ihren Betrugsprozess und ihre Entscheidungen betrafen:
- Welche Aktivitäten oder Transaktionen sind wahrscheinlich betrügerisch?
- Welche Konten sind gefährdet?
- Welche Aktivitäten erfordern weitere Untersuchungen und Fallverwaltung?
Damit die Lösung einen Nutzen bringt, muss klar sein, wie sich der Betrug beim mobilen Banking in der betrieblichen Umgebung bemerkbar macht:
- Welche Arten von Betrug werden auf der Plattform begangen?
- Wie wird er begangen?
- Welche Muster gibt es bei betrügerischen Aktivitäten und Transaktionen?
Die Antworten auf diese Fragen führten zu einem Verständnis der Verhaltensweisen, die auf Betrug hindeuten können. Die Datenattribute wurden den von den Anwendungsgateways gesammelten Nachrichten zugeordnet, die mit den identifizierten Verhaltensweisen korrelierten. Das für die Feststellung von Betrug relevante Kontoverhalten wurde dann profiliert.
Die folgende Tabelle zeigt die Arten der Kompromittierung, Datenattribute, die auf Betrug hindeuten könnten, und Verhaltensweisen, die für die Bank relevant waren:
| Kompromittierung von Anmeldeinformationen* | Gerätekompromittierungen | Finanzielle Kompromittierungen | Nicht auf Transaktionen ausgelegte Kompromittierungen | |
|---|---|---|---|---|
| Verwendete Methoden | Phishing, Vishing. | SIM-Swap, Vishing, Schadsoftware, Jailbreaking, Geräteemulatoren. | Verwendung von Kontoanmeldeinformationen und digitale Bezeichner von Geräten oder Benutzern (z. B. E-Mail-Adressen und physische Adressen). | Hinzufügen neuer Benutzer zum Konto, Erhöhen von Karten- oder Kontolimits, Ändern von Kontodetails und Kundenprofilinformationen oder Kennwort. |
| Daten | E-Mail-Adresse oder Kennwort, Kredit- oder Debitkartennummern, vom Kunden gewählte oder einmalige PINs. | Geräte-ID, SIM-Kartennummer, Geolocation und IP-Adresse. | Transaktionsbeträge, Überweisungen, Abhebungen oder Zahlungsempfänger. | Kontodetails. |
| Muster | Neuer digitaler Kunde (nicht zuvor registriert) mit einer vorhandenen Karte und PIN. Fehlgeschlagene Anmeldungen für Benutzer, die nicht vorhanden oder unbekannt sind. Anmeldungen in Zeiträumen, die für das Konto ungewöhnlich sind. Mehrere Versuche, Kennwörter für die Anmeldung zu ändern. |
Geografische Unregelmäßigkeiten (Zugriff von einem ungewöhnlichen Ort aus). Zugriff von mehreren Geräten aus in kürzester Zeit. |
Muster bei Transaktionen. Beispielsweise viele kleine Transaktionen für dasselbe Konto in kurzer Zeit, manchmal gefolgt von einer großen Abhebung. Oder Zahlungen, Auszahlungen oder Überweisungen für die maximal zulässigen Beträge. Ungewöhnliche Häufigkeit von Transaktionen. |
Muster bei den Anmeldungen und der Abfolge der Aktivitäten. Beispielsweise mehrere Anmeldungen innerhalb eines kurzen Zeitraums, mehrere Versuche, Kontaktinformationen zu ändern oder das Hinzufügen von Geräten in einem ungewöhnlichen Zeitrahmen. |
* Der häufigste Indikator für Kompromittierungen. Er geht finanziellen und nicht-finanziellen Kompromittierungen voraus.
Die Verhaltensdimension ist entscheidend für die Aufdeckung von Betrug beim mobilen Banking. Verhaltensbasierte Profile können helfen, typische Verhaltensmuster für ein Konto zu ermitteln. Analysen können auf Aktivitäten hinweisen, die von der Norm abzuweichen scheinen. Dies sind einige Beispiele für Verhaltensweisen, für die ein Profil erstellt werden kann:
- Wie viele Konten sind dem Gerät zugeordnet?
- Wie viele Geräte sind dem Konto zugeordnet? Wie häufig werden sie gelöscht oder hinzugefügt?
- Wie häufig melden sich das Gerät oder der Kunde an?
- Wie oft ändert der Kunde Kennwörter?
- Wie hoch ist der durchschnittliche Überweisungs- oder Abhebungsbetrag von dem Konto?
- Wie oft werden Abhebungen von dem Konto getätigt?
Die Lösung verwendet einen Ansatz, der auf Folgendem basiert:
- Feature Engineering zum Erstellen von Verhaltensprofilen für Kunden und Konten.
- Azure Machine Learning, um ein Betrugsklassifizierungsmodell für verdächtiges oder inkonsistentes Kontoverhalten zu erstellen.
- Azure-Dienste für Echtzeitereignisverarbeitung und End-to-End-Workflow.
Grundlegende Architektur

Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
In dieser Architektur gibt es drei Arbeitsstreams:
Eine ereignisgesteuerte Pipeline erfasst und verarbeitet Protokolldaten, erstellt und pflegt Verhaltensprofile von Konten, integriert ein Betrugsklassifizierungsmodell und erstellt einen prädiktiven Score. Die meisten Schritte in dieser Pipeline beginnen mit einer Azure-Funktion. Azure-Funktionen werden verwendet, weil sie serverlos, leicht aufskalierbar und planbar sind. Diese Workload erfordert die Verarbeitung von Millionen eingehender Transaktionen von mobilen Geräten und deren Prüfung auf Betrug in Quasi-Echtzeit.
Ein Arbeitsstream für das Modelltraining kombiniert lokale betrugsbezogene Verlaufsdaten und erfasste Protokolldaten. Diese Workload ist batchorientiert und wird für das Trainieren bzw. das erneute Trainieren von Modellen verwendet. Azure Data Factory orchestriert die Verarbeitungsschritte, einschließlich:
- Hochladen von beschrifteten betrugsbezogenen Verlaufsdaten aus lokalen Quellen.
- Archivieren von Datenfeaturesätzen und Scoreverlauf für alle Transaktionen.
- Extrahieren von Ereignissen und Nachrichten in ein strukturiertes Format für das Feature Engineering und das erneute Trainieren und Auswerten von Modellen.
- Trainieren und erneutes Trainieren eines Betrugsmodells mit Azure Machine Learning.
Der dritte Arbeitsstream ist die Integration mit Back-End-Geschäftsprozessen. Sie können Azure Logic Apps verwenden, um sich mit einem lokalen System zu verbinden und zu synchronisieren, um einen Betrugsverwaltungsfall zu erstellen, den Zugriff auf ein Konto zu sperren oder einen Telefonkontakt zu generieren.
Im Mittelpunkt dieser Architektur stehen die Datenpipeline und das KI-Modell, auf die wir später in diesem Artikel näher eingehen.
Die Lösung lässt sich mithilfe eines Enterprise Service Bus (ESB) und einer leistungsstarken Netzwerkverbindung in die lokale Umgebung der Bank integrieren.
Datenpipeline und Automatisierung
Wenn ein Krimineller über eine mobile App Zugriff auf ein Bankkonto hat, kann der finanzielle Verlust innerhalb von Minuten eintreten. Eine wirksame Erkennung von Betrugsaktivitäten muss erfolgen, während der Kriminelle mit der mobilen Anwendung interagiert und bevor eine Geldtransaktion erfolgt. Die Zeit, die benötigt wird, um auf eine betrügerische Transaktion zu reagieren, hat direkten Einfluss darauf, in welcher Höhe ein finanzieller Verlust verhindert werden kann. Je früher die Entdeckung erfolgt, desto geringer ist der finanzielle Schaden.
Weniger als zwei Sekunden, idealerweise viel weniger, ist die maximale Zeitspanne, die nach der Weiterleitung einer Mobile Banking-Aktivität zur Bearbeitung vergehen darf, um sie auf Betrug zu prüfen. Folgendes muss in diesen zwei Sekunden geschehen:
- Erfassen eines komplexen JSON-Ereignisses.
- Überprüfen, Authentifizieren, Analysieren und Transformieren des JSON-Ereignisses.
- Erstellen von Kontofeatures aus den Datenattributen.
- Übermitteln der Transaktion für das Rückschließen.
- Abrufen der Betrugsbewertung.
- Synchronisieren mit einem Back-End-Fallverwaltungssystem.
Warte- und Reaktionszeiten sind bei einer Lösung zur Betrugserkennung von entscheidender Bedeutung. Die unterstützende Infrastruktur muss schnell und skalierbar sein.
Ereignisverarbeitung
Telemetrieereignisse von den mobilen und Internet-Anwendungsgateways der Bank werden als JSON-Dateien mit einem lose definierten Schema formatiert. Diese Ereignisse werden als Anwendungstelemetrie zu Azure Event Hubs gestreamt, wo eine Azure-Funktion in einer dedizierten App Service-Umgebung die Verarbeitung orchestriert.
Das folgende Diagramm veranschaulicht die grundlegenden Interaktionen für eine Azure-Funktion innerhalb dieser Infrastruktur:
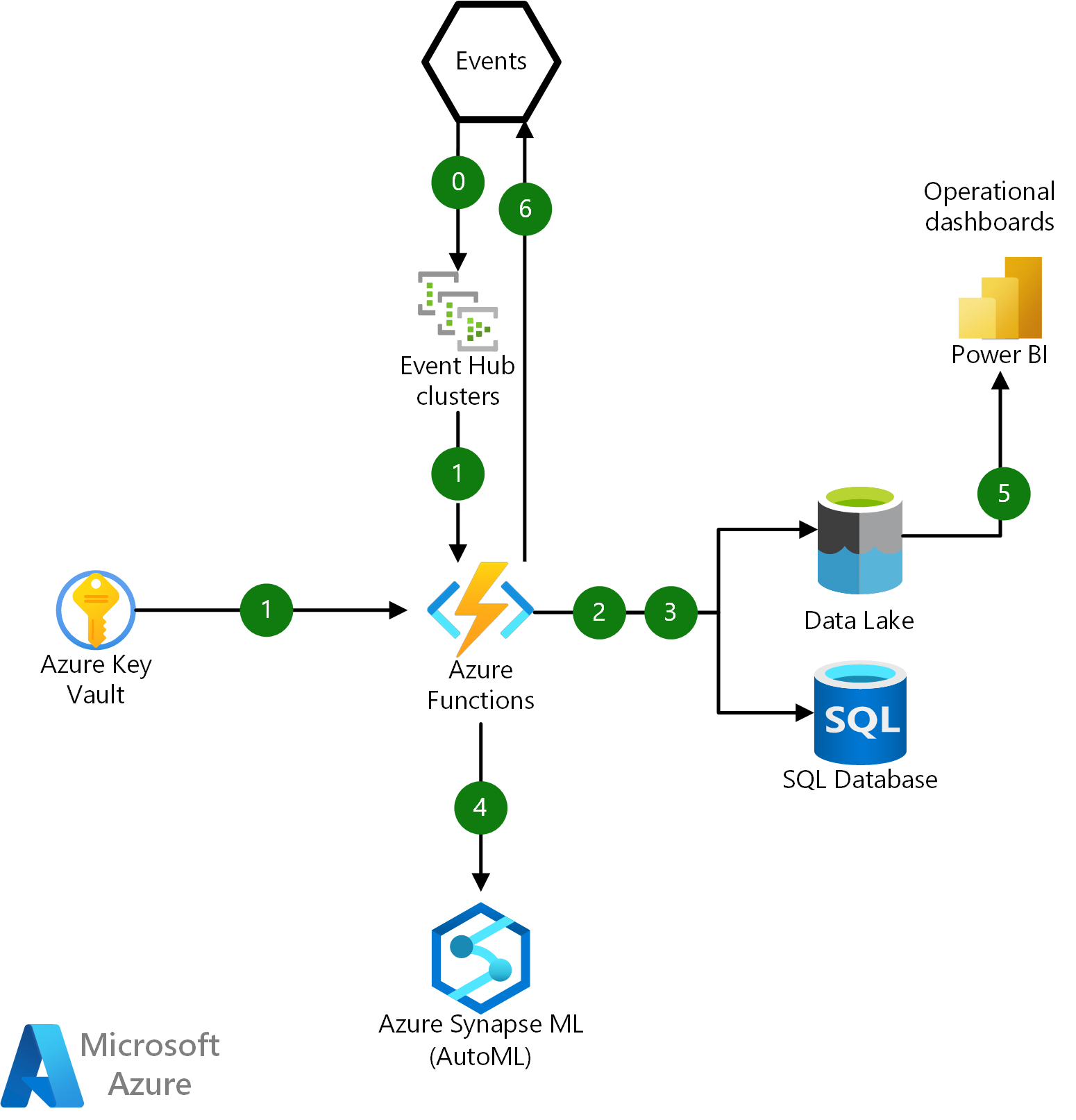
Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
- Erfassen Sie die unformatierte JSON-Ereignisnutzdaten von Event Hubs, und authentifizieren Sie sie mithilfe eines SSL-Zertifikats, das von Azure Key Vault abgerufen wird.
- Koordinieren Sie die Deserialisierung, Analyse, Speicherung und Protokollierung von unformatierten JSON-Nachrichten in Azure Data Lake und den Verlauf von Finanztransaktionen der Benutzer in Azure SQL-Datenbank.
- Aktualisieren Sie Benutzerkonto- und Geräteprofile aus SQL-Datenbank und Data Lake und rufen Sie sie ab.
- Rufen Sie einen Azure Machine Learning-Endpunkt auf, um ein Vorhersagemodell auszuführen und eine Betrugsbewertung zu erhalten. Bewahren Sie das Rückschlussergebnis in einen Data Lake für operative Analysen auf.
- Verbinden Sie Power BI über Azure Synapse Analytics mit Data Lake, um ein Dashboard für operative Analysen in Echtzeit zu erhalten.
- Veröffentlichen Sie die ausgewerteten Ergebnisse als Ereignis in einem lokalen System für weitere Betrugsuntersuchungen und Verwaltungsaktivitäten.
Datenvorverarbeitung und JSON-Transformation
In dem realen Szenario, auf dem diese Lösung basiert, war die Vorverarbeitung der Daten ein wesentlicher Schritt bei der Formatierung der Daten für die Entwicklung und das Training der Machine Learning-Modelle. Es gab Verlaufsereignissen zum mobilen und Onlinebanking über Jahre hinweg, einschließlich Transaktionsdaten aus der Telemetrie des Anwendungsgateways im JSON-Format. Es gab Hunderttausende von Dateien, die mehrere Ereignisse enthielten, die für das Training des Machine Learning-Modells deserialisiert, vereinfacht und bereinigt werden mussten.
Jedes Anwendungsgateway erzeugt Telemetriedaten aus der Interaktion eines Benutzers und erfasst Informationen wie das Betriebssystem, Metadaten des mobilen Geräts, Kontodaten sowie Anforderungen und Antworten auf Transaktionen. Die JSON-Dateien und -Attribute variierten, und die Datentypen waren uneinheitlich und inkonsistent. Eine weitere Schwierigkeit bei den JSON-Dateien bestand darin, dass sich Attribute und Datentypen unerwartet ändern konnten, wenn Anwendungsupdates an die Gateways weitergegeben und Features entfernt, geändert oder hinzugefügt wurden. Zu den Herausforderungen bei der Datentransformation mit den Schemata gehören die folgenden:
- Eine JSON-Datei kann eine oder mehrere Mobiltelefoninteraktionen enthalten. Jede Interaktion muss als separate Nachricht extrahiert werden.
- Die Felder können unterschiedlich benannt oder dargestellt werden.
- Zeichen wie Zeilenvorschübe oder Zeilenumbrüche werden inkonsistent in Nachrichten eingebettet.
- Attribute wie E-Mail-Adressen können fehlen oder nur teilweise formatiert sein.
- Es kann komplexe, geschachtelte Eigenschaften und Werte geben.
Ein Spark-Pool wird als Teil des kalten Pfads verwendet, um JSON-Verlaufsdateien zu verarbeiten und Geräte- und Transaktionsattribute zu deserialisieren, zu vereinfachen und zu extrahieren. Jede JSON-Datei wird überprüft und analysiert, und die Transaktionsattribute werden extrahiert und in einem Data Lake gespeichert und nach dem Datum der Transaktion partitioniert.
Diese Attribute werden später verwendet, um Features für die Betrugsklassifizierung zu erstellen. Die Leistungsfähigkeit dieser Lösung beruht auf der Fähigkeit, JSON-Daten zu standardisieren, zu verknüpfen und mit Verlaufsdaten zu aggregieren, um Verhaltensprofile zu erstellen.
Datenverarbeitung in Quasi-Echtzeit und Featurisierung mit SQL-Datenbank
Bei dieser Lösung werden Ereignisse aus mehreren Quellen erzeugt, darunter Authentifizierungsdatensätze, Kundeninformationen und demografische Daten, Transaktionsdatensätze sowie Protokoll- und Aktivitätsdaten von mobilen Geräten. Die SQL-Datenbank wird für die Analyse von Daten in Echtzeit, die Vorverarbeitung und Featurisierung verwendet, da SQL vielen Entwicklern vertraut ist.
Die HTAP-Funktionalität ist notwendig, um den Verlauf des Verhaltens eines Benutzerkontos für ein bestimmtes Gerät in den letzten sieben Tagen abzurufen, um Features in Quasi-Echtzeit und mit geringer Wartezeit zu berechnen. In SQL-Datenbank werden diese HTAP-Funktionen (Hybrid Transaction/Analytical Processing) verwendet:
- Speicheroptimierte Tabellen speichern Kontoprofile. Speicheroptimierte Tabellen haben Vorteile gegenüber herkömmlichen SQL-Tabellen, da sie im Hauptspeicher erstellt werden und darin der Zugriff auf sie erfolgt. Die Wartezeit und der Mehraufwand des Zugriffs auf Datenträger werden vermieden. Die Anforderung an diese Lösung ist die Verarbeitung von 300 JSON-Nachrichten/Sekunde. Speicheroptimierte Tabellen bieten dieses Maß an Durchsatz.
- Auf speicheroptimierte Tabellen wird am effizientesten über nativ kompilierte gespeicherte Prozeduren zugegriffen. Im Gegensatz zu interpretierten gespeicherten Prozeduren werden nativ kompilierte gespeicherte Prozeduren kompiliert, wenn sie zum ersten Mal erstellt werden.
- Eine temporale Tabelle ist eine Tabelle, die automatisch einen Verlauf der Änderungen verwaltet. Wenn eine Zeile hinzugefügt oder aktualisiert wird, erhält sie eine Versionsangabe und wird in die Verlaufstabelle geschrieben. Bei dieser Lösung werden die Kontoprofile in einer temporalen Tabelle gespeichert, für die eine Richtlinie zur Aufbewahrung von sieben Tagen gilt, sodass die Zeilen nach Ablauf der Aufbewahrungsfrist automatisch entfernt werden.
Dieser Ansatz bietet auch die folgenden Vorteile:
- Zugriff auf archivierte Daten für operative Analysen, erneutes Training von Machine Learning-Modellen und Betrugsüberprüfung
- Vereinfachte Datenarchivierung in langfristigen Speicher
- Skalierbarkeit über die horizontale Partitionierung (Sharding) von Daten und die Verwendung einer elastischen Datenbank
Ereignisschemaverwaltung
Die Automatisierung der Schemaverwaltung ist eine weitere Herausforderung, die für diese Lösung gemeistert werden musste. JSON ist ein flexibles und portables Dateiformat, auch da kein Schema mit den Daten gespeichert wird. Wenn JSON-Dateien analysiert, deserialisiert und verarbeitet werden müssen, muss irgendwo ein Schema codiert werden, das die Struktur der JSON-Datei darstellt, um die Dateneigenschaften und Datentypen zu überprüfen. Wenn das Schema nicht mit der eingehenden JSON-Nachricht synchronisiert ist, schlägt die JSON-Überprüfung fehl und die Daten werden nicht extrahiert.
Die Herausforderung besteht darin, dass sich die Struktur der JSON-Nachrichten aufgrund neuer Anwendungsfunktionen ändert. In ihrer ursprünglichen Lösung stellte die Bank, für die diese Lösung erstellt wurde, mehrere Anwendungsgateways bereit, die jeweils ihre eigene Benutzeroberfläche, Funktionalität, Telemetrie und JSON-Nachrichtenstruktur aufwiesen. Wenn das Schema nicht mit den eingehenden JSON-Daten synchronisiert war, führten die Inkonsistenzen zu Datenverlusten und Verarbeitungsverzögerungen bei der Betrugserkennung.
Die Bank hatte kein formales Schema für diese Ereignisse definiert, und die ständigen Schwankungen in der Struktur der JSON-Dateien erzeugten bei jeder Iteration der Lösung technische Schulden. Diese Lösung behebt dieses Problem, indem sie ein Schema für diese Ereignisse erstellt und die Azure-Schemaregistrierung verwendet. Die Azure-Schemaregistrierung bietet eine zentrale Registrierung von Schemata für Ereignisse und Flexibilität für Producer- und Consumeranwendungen, um Daten auszutauschen, ohne das Schema verwalten und freigeben zu müssen. Das einfache Governance-Framework, das es für wiederverwendbare Schemas einführt, und die Beziehungen, die es durch die Gruppierungskonstrukte (Schemagruppen) zwischen Schemas definiert, können erhebliche technische Schulden beseitigen, Konformität erzwingen und Rückwärtskompatibilität bei wechselnden Schemas bieten.
Feature Engineering für maschinelles Lernen
Features bieten eine Möglichkeit, ein Profil des Kontoverhaltens zu erstellen, indem die Aktivitäten über verschiedene Zeiträume hinweg aggregiert werden. Sie werden aus Daten in den Anwendungsprotokollen erstellt, die das auf Transaktionen ausgelegte, das nicht auf Transaktionen ausgelegte und das Geräteverhalten darstellen. Das auf Transaktionen ausgelegte Verhalten umfasst Geldtransaktionsaktivitäten wie Zahlungen und Abhebungen. Das nicht auf Transaktionen ausgelegte Verhalten umfasst Benutzeraktionen wie Anmeldeversuche und Kennwortänderungen. Das Geräteverhalten umfasst Aktivitäten, die ein mobiles Gerät betreffen, wie das Hinzufügen oder Entfernen eines Geräts. Features werden verwendet, um das aktuelle und vergangene Kontoverhalten darzustellen, einschließlich:
- Registrierungsversuche eines neuen Benutzers von einem bestimmten Gerät aus.
- Erfolgreiche und fehlerhafte Anmeldeversuche.
- Anforderungen zum Hinzufügen von dritten Zahlungsempfängern oder Begünstigten.
- Anforderungen zur Erhöhung von Konto- oder Kreditkartenlimits.
- Änderungen des Kennworts.
Eine Kontoprofiltabelle enthält Attribute aus den JSON-Transaktionen, wie die Nachrichten-ID, den Transaktionstyp, den Zahlungsbetrag, den Wochentag und die Uhrzeit. Die Aktivitäten werden über mehrere Zeiträume hinweg zusammengefasst, z. B. eine Stunde, einen Tag und sieben Tage, und als Verhaltensverlauf für jedes Konto gespeichert. Jede Zeile in der Tabelle steht für ein einzelnes Konto. Dies sind nur einige der Features:
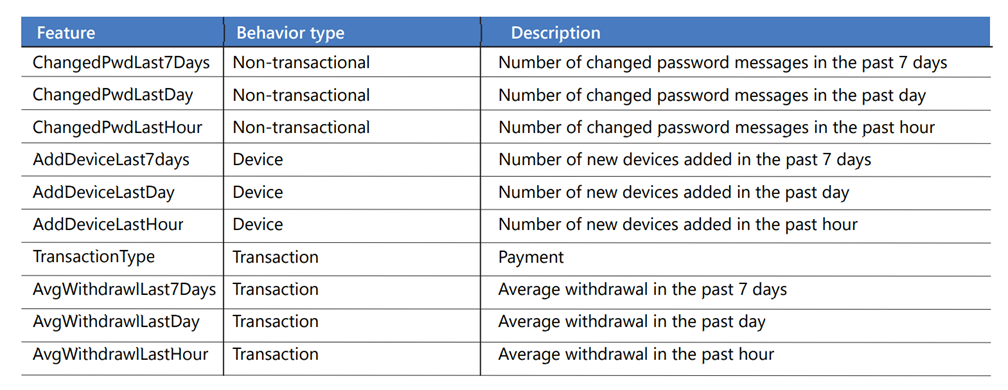
Nachdem die Kontofeatures berechnet und das Profil aktualisiert wurde, ruft eine Azure-Funktion das Machine Learning-Modell für die Bewertung über eine REST-API auf, um diese Frage zu beantworten: Wie hoch ist die Wahrscheinlichkeit, dass es sich bei diesem Konto um einen Betrug handelt, basierend auf dem beobachteten Verhalten?
AutoML
AutoML wird in der Lösung verwendet, da es schnell und einfach zu verwenden ist. AutoML kann ein nützlicher Ausgangspunkt sein, um schnell etwas zu entdecken und zu lernen, da es keine speziellen Kenntnisse oder Einstellungen erfordert. Es automatisiert die zeitaufwändigen, iterativen Aufgaben der Entwicklung von Machine Learning-Modellen. Wissenschaftliche Fachkräfte für Daten, Analysten und Entwickler können es verwenden, um Machine Learning-Modelle mit hoher Skalierbarkeit, Effizienz und Produktivität zu erstellen und dabei die Modellqualität zu erhalten.
AutoML kann die folgenden Aufgaben in einem Machine Learning-Prozess ausführen:
- Teilen von Daten in Datasets für Training und Überprüfung
- Optimieren des Trainings basierend auf einer ausgewählten Metrik
- Durchführen einer Kreuzvalidierung
- Generieren von Features
- Imputieren von fehlenden Werten
- Durchführen einer One-Hot-Codierung und verschiedener Skalierer
Unausgeglichene Daten
Die Klassifizierung von Betrugsversuchen ist aufgrund des starken Klassenungleichgewichts eine Herausforderung. In einem Betrugsdataset gibt es viel mehr nicht betrügerische als betrügerische Transaktionen. Normalerweise enthält weniger als 1 Prozent eines Datasets betrügerische Transaktionen. Wenn dieses Ungleichgewicht nicht behoben wird, kann es zu einem Glaubwürdigkeitsproblem in dem Modell führen, da alle Transaktionen als nicht betrügerisch eingestuft werden könnten. Das Modell könnte alle betrügerischen Transaktionen komplett übersehen und trotzdem eine Genauigkeitsrate von 99 Prozent erreichen.
AutoML kann dabei helfen, die Daten neu zu verteilen und ein besseres Gleichgewicht zwischen betrügerischen und nicht betrügerischen Transaktionen zu erstellen:
- AutoML unterstützt das Hinzufügen einer Gewichtungsspalte als Eingabe, wodurch die Zeilen in den Daten nach oben oder unten gewichtet werden, wodurch eine Klasse weniger wichtig werden kann. Die von AutoML verwendeten Algorithmen erkennen ein Ungleichgewicht, wenn die Anzahl der Stichproben in der Minderheitsklasse gleich oder weniger als 20 Prozent der Anzahl der Stichproben in der Mehrheitsklasse ist. Anschließend führt AutoML das Experiment mit Daten aus einem Teilsatz der Stichprobe aus, um zu prüfen, ob die Verwendung von Klassengewichten dieses Problem behebt und die Leistung verbessert. Wenn festgestellt wird, dass die Leistung aufgrund des Experiments besser ist, wird die Problemlösung angewendet.
- Sie können eine Metrik zur Leistungsmessung verwenden, die mit unausgeglichenen Daten besser umgehen kann. Wenn Ihr Modell z. B. sensibel auf False Negative-Ergebnisse reagieren soll, verwenden Sie
recall. Wenn das Modell sensibel auf False Positive-Ergebnisse reagieren soll, verwenden Sieprecision. Sie können auch einen F1-Score verwenden. Dieser Score ist das harmonische Mittel zwischenprecisionundrecall, sodass er nicht durch eine hohe Anzahl von True Positive- oder True Negative-Ergebnisse beeinflusst wird. Möglicherweise müssen Sie einige Metriken während Ihrer Testphase manuell berechnen.
Um die Anzahl der als betrügerisch eingestuften Transaktionen zu erhöhen, können Sie alternativ manuell eine Technik namens „Methode zur synthetischen Minderheitsüberquotierung“ (Synthetic Minority Oversampling Technique, SMOTE) verwenden. SMOTE ist eine statistische Technik, die Bootstrapping und k-Nearest Neighbor (KNN) verwendet, um Instanzen der Minderheitsklasse zu erzeugen.
Modelltraining
Für das Modelltraining erwartet das Python SDK Daten entweder im Pandas-Dataframeformat oder ein Azure Machine Learning-Tabellendataset. Der Wert, den Sie vorhersagen möchten, muss im Dataset enthalten sein. Sie übergeben die Spalte y als Parameter, wenn Sie den Trainingsauftrag erstellen.
Hier folgt ein Codebeispiel mit Kommentaren:
data = https://automlsamplenotebookdata.blob.core.windows.net/automl-sample-notebook-data/creditcard.csv
dataset = Dataset.Tabular.from_delimited_files(data)
training_data, validation_data = dataset.random_split(percentage=0.7)
label_column_name = "Class"
automl_settings = {
"n_cross_validations": 3, # Number of cross validation splits.
"primary_metric": "average_precision_score_weighted", # This is the metric that you want to optimize.
"experiment_timeout_hours": 0.25, # Percentage of an hour you want this to run.
"verbosity": logging.INFO, # Logging info level, debug, info, warning, error, critical.
"enable_stack_ensemble": False, # VotingEnsembled is enabled by default.
}
automl_config = AutoMLConfig(
task="classification",
debug_log="automl_errors.log",
training_data=training_data,
label_column_name=label_column_name,
**automl_settings,
)
local_run = experiment.submit(automl_config, show_output=True)
Im Code:
- Laden Sie das Dataset in ein Azure Machine Learning-Tabellendataset oder einen Pandas-Dataframe.
- Teilen Sie das Dataset in 70 Prozent für das Training und 30 Prozent für die Überprüfung auf.
- Erstellen Sie eine Variable für die Spalte, die Sie vorhersagen möchten.
- Beginnen Sie mit der Erstellung der AutoML-Parameter.
- Konfigurieren Sie die
AutoMLConfig.taskist die Art des maschinellen Lernens, die Sie durchführen möchten:classificationoderregression. Verwenden Sie in diesem Fallclassification.debug_logist der Speicherort, an den die Debuginformationen geschrieben werden.training_dataist der Dataframe oder das Tabellenobjekt, in den/das die Trainingsdaten geladen werden.label_column_nameist die Spalte, die Sie vorhersagen möchten.
- Führen Sie den Machine Learning-Auftrag aus.
Modellauswertung
Ein gutes Modell liefert realistische und umsetzbare Ergebnisse. Das ist eine der Herausforderungen bei einem Modell zur Betrugserkennung. Die meisten Betrugserkennungsmodelle treffen eine binäre Entscheidung, um festzustellen, ob eine Transaktion betrügerisch ist. Die Entscheidung basiert auf zwei Faktoren:
- Ein Wahrscheinlichkeitsergebnis zwischen 0 und 100, das vom Klassifizierungsalgorithmus zurückgegeben wird.
- Ein Wahrscheinlichkeitsschwellenwert, der vom Unternehmen festgelegt wird. Ein Wert über dem Schwellenwert gilt als betrügerisch, ein Wert unter dem Schwellenwert gilt als nicht betrügerisch.
Die Wahrscheinlichkeit ist eine Standardmetrik für jedes Klassifizierungsmodell. Aber in einem Betrugsszenario reicht dies in der Regel nicht aus, um zu entscheiden, ob ein Konto gesperrt werden soll, um weitere Verluste zu verhindern.
Bei dieser Lösung werden Metriken auf Kontoebene erstellt und bei der Entscheidung berücksichtigt, ob das Unternehmen ein Konto sperren sollte. Die Metriken auf Kontoebene werden auf der Grundlage der folgenden Branchenstandardmetriken definiert:
| Bedenken des Betrugs-Managers | Metrik | Beschreibung |
|---|---|---|
| Erkenne ich einen Betrug? | Betrugskontoerkennungsrate (Fraud Account Detection Rate, ADR) | Der prozentuale Anteil der erkannten Betrugskonten unter allen Betrugskonten. |
| Wie viel Geld spare ich ein (Verlustvermeidung)? Wie viel kostet eine Verzögerung bei der Reaktion auf eine Warnung? | Werterkennungsrate (Value Detection Rate, VDR) | Der Prozentsatz der monetären Einsparungen im Vergleich zu allen Betrugsverlusten, unter der Annahme, dass die aktuelle Betrugstransaktion eine Sperrung für nachfolgende Transaktionen auslöst. |
| Wie viele gute Kunden belästige ich damit? | False Positive-Kontorate (Account False Positive Ratio, AFPR) | Die Anzahl der nicht betrügerischen Konten, die für jeden erkannten echten Betrug markiert werden (pro Tag). Das Verhältnis von erkannten False Positive-Konten zu erkannten betrügerischen Konten. |
Diese Metriken sind wertvolle Datenpunkte für einen Betrugs-Manager. Der Manager verwendet sie, um sich ein vollständigeres Bild des Kontorisikos zu machen und über Abhilfemaßnahmen zu entscheiden.
Operationalisierung und erneutes Training des Modells
Vorhersagemodelle müssen in regelmäßigen Abständen aktualisiert werden. Im Laufe der Zeit und wenn neue und andere Daten verfügbar werden, muss ein Vorhersagemodell neu trainiert werden. Dies gilt insbesondere für Modelle zur Betrugserkennung, bei denen häufig neue Muster krimineller Aktivitäten auftreten. Dies ist auch dann erforderlich, wenn sich die Telemetriedaten aus den Protokollen mobiler Anwendungen aufgrund von Änderungen ändern, die an das Anwendungsgateway weitergeleitet werden. Um bei dieser Lösung ein erneutes Training zu ermöglichen, wird jede zur Analyse übermittelte Transaktion und die entsprechende Metrik für die Modellauswertung protokolliert. Die Leistung des Modells wird im Verlauf der Zeit überwacht. Wenn sie sich zu verschlechtern scheint, wird ein Workflow zum erneuten Training ausgelöst. Im Workflow zum erneuten Training werden mehrere Azure-Dienste verwendet:
Sie können Azure Synapse Analytics oder Azure Data Lake verwenden, um Verlaufsdaten von Kunden zu speichern. Sie können diese Dienste verwenden, um bekannte betrügerische Transaktionen zu speichern, die von lokalen Quellen hochgeladen wurden, sowie Daten, die vom Azure Machine Learning-Webdienst archiviert wurden, einschließlich Transaktionen, Vorhersagen und Auswertungsmetriken für das Modell. Die für das erneute Training benötigten Daten werden in diesem Datenspeicher gespeichert.
Sie können Data Factory oder Azure Synapse-Pipelines verwenden, um den Datenfluss und den Prozess für erneutes Training zu orchestrieren, einschließlich:
- Die Extraktion von Verlaufsdaten und Protokolldateien aus lokalen Systemen.
- Der Prozess der JSON-Deserialisierung.
- Die Logik zur Datenvorverarbeitung.
Weitere Informationen finden Sie unter Erneutes Trainieren und Aktualisieren von Azure Machine Learning-Modellen mit Azure Data Factory.
Sie können Blau-Grün-Bereitstellungen in Azure Machine Learning verwenden. Informationen zur Bereitstellung eines neuen Modells mit minimaler Downtime finden Sie unter Sicherer Rollout für Onlineendpunkte.
Komponenten
- Azure Functions bietet ereignisgesteuerte, serverlose Codefunktionen und eine End-to-End-Entwicklungsumgebung.
- Event Hubs ist ein vollständig verwalteter Dienst für die Datenerfassung in Echtzeit. Sie können ihn verwenden, um Millionen von Ereignissen pro Sekunde aus einer beliebigen Quelle zu streamen.
- Key Vault verschlüsselt kryptografische Schlüssel und andere Geheimnisse mithilfe von Cloud-Apps und -diensten.
- Azure Machine Learning ist ein Dienst für den End-to-End-Lebenszyklus für maschinelles Lernen auf Unternehmensniveau.
- AutoML ist ein Verfahren zur Automatisierung der zeitaufwändigen, iterativen Aufgaben der Entwicklung von Machine Learning-Modellen.
- Azure SQL-Datenbank ist ein stets aktueller und vollständig verwalteter relationaler Datenbankdienst für die Cloud.
- Azure Synapse Analytics ist ein unbegrenzter Analysedienst, der Datenintegration, Data Warehousing für Unternehmen und Big Data-Analysen vereint.
Technische Überlegungen
Um die richtigen Technologiekomponenten für eine kontinuierlich arbeitende cloudbasierte Infrastruktur zur Betrugserkennung auszuwählen, müssen Sie die aktuellen und manchmal vagen Anforderungen verstehen. Die Technologieauswahl für diese Lösung basiert auf Überlegungen, die Ihnen helfen könnten, ähnliche Entscheidungen zu treffen.
Skillsets
Berücksichtigen Sie die aktuellen technologischen Skillsets der Teams, die die Lösung entwerfen, implementieren und warten. Cloud- und KI-Technologien erweitern die Möglichkeiten, eine Lösung zu implementieren. Wenn Ihr Team z. B. über grundlegende Data Science-Skills verfügt, ist Azure Machine Learning eine gute Wahl für die Modellerstellung und den Endpunkt. Die Entscheidung, Event Hubs zu verwenden, ist ein weiteres Beispiel. Event Hubs ist ein verwalteter Dienst, der einfach einzurichten und zu pflegen ist. Es hat technische Vorteile, eine Alternative wie Kafka zu verwenden, aber dafür ist möglicherweise ein Training erforderlich.
Hybridbetriebsumgebung
Die Bereitstellung dieser Lösung umfasst eine lokale Umgebung und die Azure-Umgebung. Dienste, Netzwerke, Anwendungen und Kommunikation müssen in beiden Infrastrukturen effektiv funktionieren, um die Workload zu unterstützen. Die Technologieentscheidungen umfassen:
- Wie werden die Umgebungen integriert?
- Welche Anforderungen gibt es an die Netzwerkkonnektivität zwischen dem Azure-Rechenzentrum und der lokalen Infrastruktur? Azure ExpressRoute wird verwendet, da es Doppelleitungen, Redundanz und Failover bietet. Ein Site-to-Site-VPN bietet nicht die Sicherheit oder Quality of Service (QoS), die für die Workload erforderlich ist.
- Wie lassen sich Betrugserkennungsergebnisse mit Back-End-Systemen integrieren? Bewertungsantworten sollten mit Back-End-Workflows für Betrugsfälle integriert werden, um die Überprüfung von Transaktionen mit Kunden oder andere Aktivitäten zur Fallverwaltung zu automatisieren. Sie können entweder Azure Functions oder Logic Apps verwenden, um Azure-Dienste mit lokalen Systemen zu integrieren.
Sicherheit
Das Hosten einer Lösung in der Cloud erzeugt neue Sicherheitsverantwortlichkeiten. In der Cloud ist die Sicherheit eine gemeinsame Verantwortung zwischen einem Cloudanbieter und einem Kundenmandanten. Die Verantwortlichkeiten für eine Workload variieren, je nachdem, ob es sich bei der Workload um einen SaaS-, PaaS- oder IaaS-Dienst handelt. Weitere Informationen dazu finden Sie unter Gemeinsame Verantwortung in der Cloud.
Unabhängig davon, ob Sie einen Zero Trust-Ansatz verfolgen oder an der Einhaltung gesetzlicher Bestimmungen arbeiten, erfordert die End-to-End-Sicherung einer Lösung sorgfältige Planung und Überlegung. Für den Entwurf und die Bereitstellung empfehlen wir Ihnen, Sicherheitsprinzipien zu übernehmen, die mit einem Zero Trust-Ansatz vereinbar sind. Die Anwendung von Prinzipien wie explizite Überprüfung, Verwendung der geringstmöglichen Zugriffsrechte und Annahme einer Sicherheitsverletzung stärkt die Sicherheit der Workload.
Explizite Überprüfung beschreibt den Prozess der Überprüfung und Bewertung verschiedener Aspekte einer Zugriffsanforderung. Hier sind einige der Prinzipien:
- Verwenden Sie eine starke Identitätsplattform wie Microsoft Entra ID.
- Machen Sie sich mit dem Sicherheitsmodell für jeden Clouddienst und mit der Vorgehensweise beim Sichern von Daten und des Zugriffs vertraut.
- Verwenden Sie nach Möglichkeit verwaltete Identitäten und Dienstprinzipale, um den Zugriff auf Clouddienste zu steuern.
- Speichern Sie Schlüssel, Geheimnisse, Zertifikate und Anwendungsartefakte wie Datenbankzeichenfolgen, REST-Endpunkt-URLs und API-Schlüssel in Key Vault.
Verwendung der geringstmöglichen Zugriffsrechte: Dies hilft beim Sicherstellen, dass Berechtigungen nur zur Entsprechung bestimmter Geschäftsanforderungen von einer geeigneten Umgebung an einen geeigneten Client vergeben werden. Hier sind einige der Prinzipien:
- Unterteilen Sie Workloads, indem Sie den Zugriff auf eine Komponente oder Ressource über Rollenzuweisungen oder Netzwerkzugriff einschränken.
- Lassen Sie den öffentlichen Zugriff auf Endpunkte und Dienste nicht zu. Verwenden Sie private Endpunkte, um Ihre Dienste zu schützen, sofern Ihr Dienst keinen öffentlichen Zugriff erfordert.
- Verwenden Sie Firewallregeln, um Dienstendpunkte zu sichern oder Workloads mithilfe virtueller Netzwerke zu isolieren.
Annahme einer Sicherheitsverletzung: Dies ist eine Strategie zur Steuerung von Entwurfs- und Bereitstellungsentscheidungen. Die Strategie besteht darin, davon auszugehen, dass eine Lösung kompromittiert wurde. Es handelt sich um einen Ansatz zum Entwickeln von Resilienz in einer Workload durch die Planung der Erkennung einer Sicherheitsbedrohung, der Reaktion darauf und der Behebung dieser Bedrohung. Für Entwurfs- und Bereitstellungsentscheidungen bedeutet dies:
- Workloadkomponenten sind isoliert und segmentiert, sodass eine Beeinträchtigung einer Komponente die Auswirkungen auf Upstream- oder Downstreamkomponenten minimiert.
- Die Telemetrie wird erfasst und proaktiv analysiert, um Anomalien und potenzielle Bedrohungen zu erkennen.
- Die Automatisierung ist vorhanden, um eine Bedrohung zu erkennen, darauf zu reagieren und sie zu beseitigen.
Im Folgenden werden einige Anleitungen aufgeführt, die Sie berücksichtigen sollten:
- Verschlüsseln Sie ruhende Daten und Daten während der Übertragung.
- Aktivieren Sie die Überwachung von Diensten.
- Erfassen und zentralisieren Sie Überwachungsprotokolle und Telemetrie in einem einzelnen Arbeitsbereich, um die Analyse und Korrelation zu vereinfachen.
- Aktivieren Sie Microsoft Defender für Cloud, um auf potenziell gefährdete Konfigurationen zu prüfen und frühzeitig vor möglichen Sicherheitsproblemen zu warnen.
Der Netzwerkbetrieb ist einer der wichtigsten Sicherheitsfaktoren. Standardmäßig sind die Endpunkte des Azure Synapse-Arbeitsbereichs öffentliche Endpunkte. Das bedeutet, dass auf sie von jedem öffentlichen Netzwerk aus zugegriffen werden kann. Wir empfehlen Ihnen daher dringend, den öffentlichen Zugriff auf den Arbeitsbereich zu deaktivieren. Erwägen Sie die Bereitstellung von Azure Synapse mit aktiviertem Feature „Verwaltetes virtuelles Netzwerk“, um eine Isolationsebene zwischen Ihrem Arbeitsbereich und anderen Azure-Diensten hinzuzufügen. Weitere Informationen über verwaltete virtuelle Netzwerke und andere Sicherheitsfaktoren finden Sie im Whitepaper zur Azure Synapse Analytics-Sicherheit: Netzwerksicherheit.

Laden Sie eine Visio-Datei dieser Architektur herunter.
Die folgende Tabelle enthält einen Sicherheitsleitfaden, der sich auf die einzelnen Lösungskomponenten der Banklösung bezieht. Einen guten Ausgangspunkt finden Sie in Azure Security Benchmark, das Sicherheitsbaselines für jeden einzelnen Azure-Dienst enthält. Die Empfehlungen für die Sicherheitsbaseline können Ihnen helfen, die Einstellungen für die Sicherheitskonfiguration für jeden Dienst festzulegen.
Weitere Informationen finden Sie im Zero Trust Guidance Center.
Skalierbarkeit
Die Lösung muss in Spitzenzeiten durchgängig funktionieren. Ein Streamingworkflow für die Verarbeitung von Millionen von kontinuierlich eintreffenden Ereignissen erfordert einen hohen Durchsatz. Planen Sie, ein Testsystem zu erstellen, das das Volumen und die Parallelität simuliert, um sicherzustellen, dass die Technologiekomponenten so konfiguriert und abgestimmt sind, dass die erforderlichen Wartezeiten eingehalten werden. Skalierbarkeitstests sind insbesondere für die folgenden Komponenten wichtig:
- Datenerfassung zur Verarbeitung gleichzeitiger Datenströme. In dieser Architektur wird Event Hubs verwendet, da mehrere Instanzen davon bereitgestellt und verschiedenen Consumergruppen zugewiesen werden können. Ein horizontaler Skalierungsansatz ist die bessere Option, da das Hochskalierung zu Sperren führen kann. Ein horizontaler Skalierungsansatz ist auch besser geeignet, wenn Sie planen, die Betrugserkennung für mobiles Banking auf einen Kanal für Onlinebanking auszuweiten.
- Ein Framework zum Verwalten und Planen des Prozessflusses. Azure Functions wird verwendet, um den Workflow zu orchestrieren. Um den Durchsatz zu verbessern, werden die Nachrichten in Mikrobatches zusammengefasst und über eine einzelne Azure-Funktion verarbeitet, anstatt eine Nachricht pro Funktionsaufruf zu verarbeiten.
- Ein latenzarmer Datenprozess zum Analysieren, Vorverarbeiten, Aggregieren und Speichern. In der realen Lösung, auf der dieser Artikel basiert, erfüllen die Funktionen der In-Memory-optimierten SQL-Funktionen die Anforderungen an Skalierbarkeit und Parallelität.
- Modellbewertung zur Behandlung gleichzeitiger Anforderungen. Mit Azure Machine Learning-Webdiensten haben Sie zwei Optionen für die Skalierung:
- Wählen Sie eine Produktionswebebene aus, um die API-Parallelitätsworkload zu unterstützen.
- Fügen Sie mehrere Endpunkte zu einem Webdienst hinzu, wenn Sie mehr als 200 gleichzeitige Anforderungen unterstützen müssen.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautoren:
- Kate Baroni | Principal Customer Engineer
- Michael Hlobil | Principal Customer Engineering Manager
- Cedric Labuschagne | Technical Program Manager
- Frank Garofalo | Principal Customer Engineer
- Shep Sheppard | Senior Service Engineer
Andere Mitwirkende:
- Mick Alberts | Technical Writer
Nächste Schritte
- Eine schnelle, serverlose Big Data-Pipeline, die von einer einzelnen Azure-Funktion gesteuert wird
- Berücksichtigen von Azure Functions für ein serverloses Datenstreamingszenario
- Überlegungen zum Netzwerkbetrieb in einer App Service-Umgebung
- Event Hubs
- Schlüsseltresor
- Azure Machine Learning