Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR:  Python-SDK azure-ai-ml v2 (aktuell)
Python-SDK azure-ai-ml v2 (aktuell)
Automatisiertes maschinelles Lernen, auch als automatisierte ML oder AutoML bezeichnet, automatisiert die zeitaufwendigen, iterativen Aufgaben der Machine Learning-Modellentwicklung. Mit automatisiertem ML können Data Scientists, Analysten und Entwickler machine Learning-Modelle im Maßstab mit Effizienz und Produktivität erstellen und gleichzeitig die Modellqualität beibehalten. Automatisiertes maschinelles Lernen in Azure Machine Learning basiert auf einem Durchbruch der Microsoft Research-Abteilung.
- Installieren Sie für Kunden mit Programmiererfahrung das Azure Machine Learning Python SDK. Unter Tutorial: Trainieren eines Objekterkennungsmodells (Vorschauversion) mit AutoML und Python finden Sie Informationen zu den ersten Schritten.
Wie funktioniert automatisiertes maschinelles Lernen?
Während des Trainings erstellt Azure Machine Learning parallel viele Pipelines, die unterschiedliche Algorithmen und Parameter für Sie ausprobieren. Der Dienst durchläuft Machine Learning-Algorithmen, die mit Merkmalauswahlen gekoppelt sind. Jede Iteration erzeugt ein Modell mit einer Schulungsbewertung. Je besser die Bewertung für die Metrik, die Sie optimieren möchten, desto besser passt das Modell zu Ihren Daten. Der Prozess wird beendet, sobald er die im Experiment definierten Beendigungskriterien erfüllt.
Mithilfe von Azure Machine Learning können Sie automatisierte ML-Trainingsexperimente mit den folgenden Schritten entwerfen und ausführen:
Identifizieren Sie das zu lösende ML-Problem : Klassifizierung, Prognose, Regression, Computervision oder NLP.
Wählen Sie eine Code-first-Erfahrung oder eine Weboberfläche ohne Code-Studio aus: Benutzer, die eine Code-first-Erfahrung bevorzugen, können die Azure Machine Learning SDKv2 oder die Azure Machine Learning CLIv2 verwenden. Unter Tutorial: Trainieren eines Objekterkennungsmodells mit AutoML und Python finden Sie Informationen zu den ersten Schritten. Benutzer, die eine Umgebung mit wenig oder gar keinem Code bevorzugen, können die Webschnittstelle in Azure Machine Learning Studio unter https://ml.azure.com verwenden. Unter Tutorial: Erstellen eines Klassifizierungsmodells mit automatisiertem maschinellem Lernen in Azure Machine Learning finden Sie Informationen zu den ersten Schritten.
Geben Sie die Quelle der bezeichneten Schulungsdaten an: Bringen Sie Ihre Daten auf vielfältige Weise in Azure Machine Learning.
Konfigurieren Sie die parameter für das automatisierte maschinelle Lernen: Legen Sie die Anzahl der Iterationen über verschiedene Modelle, Hyperparametereinstellungen, erweiterte Vorverarbeitungs- und Featurisierungsoptionen sowie die Metriken fest, die beim Bestimmen des besten Modells ausgewertet werden sollen.
Übermitteln des Trainingsauftrags
Überprüfen der Ergebnisse
Dieser Prozess wird anhand des folgenden Diagramms veranschaulicht.
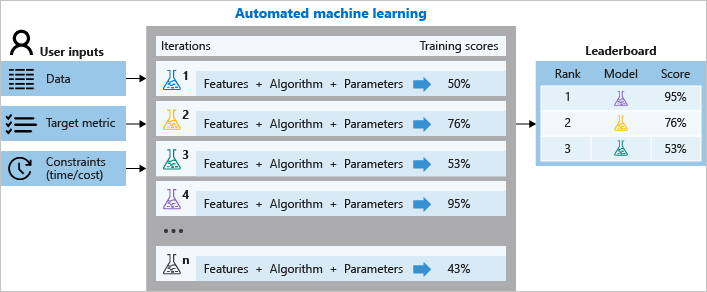
Sie können die protokollierten Auftragsinformationen auch untersuchen. Sie enthalten die während des Auftrags erfassten Metriken. Bei dem Trainingsauftrag wird ein serialisiertes Python-Objekt (.pkl-Datei) generiert, das die Vorabverarbeitung des Modells und der Daten enthält.
Obwohl die Modellerstellung automatisiert ist, können Sie auch ermitteln, wie wichtig oder relevant Features für die generierten Modelle sind.
Verwendung von AutoML: Klassifizierung, Regression, Prognose, Computervision und NLP
Verwenden Sie automatisierte ML, wenn Azure Machine Learning ein Modell für Sie trainieren und optimieren soll, indem Sie die angegebene Zielmetrik verwenden. Automatisierte ML demokratisiert den Entwicklungsprozess des Machine Learning-Modells und ermöglicht es seinen Benutzern, unabhängig von ihrer Data Science-Expertise, eine End-to-End-Machine Learning-Pipeline für jedes Problem zu identifizieren.
Spezialisten für maschinelles Lernen und Entwickler aus den verschiedensten Branchen können automatisiertes maschinelles Lernen für Folgendes verwenden:
- Implementieren von ML-Lösungen ohne umfangreiche Programmierkenntnisse
- Sparen von Zeit und Ressourcen
- Anwenden bewährter Methoden für Data Science
- Bereitstellen flexibler Problemlösungen
Klassifizierung
Klassifizierung ist eine Art des überwachten Lernens, bei der Modelle anhand von Trainingsdaten lernen und diese Erkenntnisse auf neue Daten anwenden. Azure Machine Learning bietet Featurebereitstellungen speziell für diese Aufgaben, z. B. Textfeaturizer für Deep Neural Network zur Klassifizierung. Weitere Informationen zu Optionen zur Featurisierung finden Sie unter Merkmalerstellung für Daten. Unter Unterstützte Algorithmen finden Sie auch die Liste der Algorithmen, die von automatisiertem ML unterstützt werden.
Das Hauptziel von Klassifizierungsmodellen besteht darin, auf der Grundlage der Erkenntnisse aus den Trainingsdaten vorherzusagen, in welche Kategorien neue Daten fallen. Zu den gängigen Klassifizierungsbeispielen gehören Betrugserkennung, Handschrifterkennung und Objekterkennung.
Ein Beispiel für Klassifizierung und automatisiertes maschinelles Lernen finden Sie in diesem Python-Notebook: Bank Marketing.
Rückentwicklung
Ähnlich der Klassifizierung sind Regressionsaufgaben auch ein gängiger überwachter Lerntask. Azure Machine Learning bietet ein Feature Engineering speziell für Regressionsprobleme. Erfahren Sie mehr über die Optionen für die Featurebereitstellung. Unter Unterstützte Algorithmen finden Sie auch die Liste der Algorithmen, die von automatisiertem ML unterstützt werden.
Anders als bei der Klassifizierung, bei der die vorhergesagten Ausgabewerte kategorisch sind, sagen Regressionsmodelle numerische Ausgabewerte auf der Grundlage unabhängiger Vorhersagefaktoren voraus. Bei der Regression besteht das Ziel darin, die Beziehung zwischen diesen unabhängigen Vorhersagevariablen herzustellen, indem geschätzt wird, wie eine Variable die anderen beeinflusst. Beispiel: Das Modell sagt den Fahrzeugpreis möglicherweise basierend auf Merkmalen wie Kraftstoffverbrauch und Sicherheitseinstufung vorher.
Ein Beispiel für Regression und automatisiertes maschinelles Lernen für Vorhersagen finden Sie in den folgenden Python-Notebooks: Hardwareleistung.
Zeitreihenvorhersagen
Die Erstellung von Vorhersagen ist ein integraler Bestandteil jedes Unternehmens, unabhängig davon, ob es sich um Einnahmen, Lagerbestände, Umsätze oder Kundennachfrage handelt. Verwenden Sie automatisierte ML, um Techniken und Ansätze zu kombinieren und eine empfohlene, qualitativ hochwertige Zeitreihenprognose zu erhalten. Eine Liste der algorithmen, die von AutoML unterstützt werden, finden Sie unter "Unterstützte Algorithmen".
Ein automatisiertes Zeitreihenexperiment behandelt das Problem als multivariate Regressionsproblem. Zeitreihenwerte aus der Vergangenheit werden „pivotiert“ und dienen so zusammen mit anderen Vorhersageelementen als weitere Dimensionen für den Regressor. Dieser Ansatz hat im Gegensatz zu klassischen Zeitreihenmethoden den Vorteil, dass mehrere kontextbezogene Variablen und deren Beziehungen zueinander beim Training auf natürliche Weise integriert werden. Beim automatisierten maschinellen Lernen wird ein zwar einfaches, aber häufig in interne Verzweigungen unterteiltes Modell für alle Elemente im Dataset und in den Vorhersagehorizonten erlernt. Dadurch sind mehr Daten verfügbar, um Modellparameter zu schätzen, und die Generalisierung von unbekannten Reihen wird möglich.
Die erweiterte Vorhersagekonfiguration umfasst Folgendes:
- Feiertagserkennung und Erstellen zusätzlicher Merkmale (Featurization)
- Zeitreihen und DNN-Lernmodule (Auto-ARIMA, Prophet, ForecastTCN)
- Unterstützung für viele Modelle durch Gruppieren
- Kreuzvalidierung mit rollierendem Ursprung
- Konfigurierbare Verzögerungen
- Aggregierte Zeitfenstermerkmale (Rolling Window Features)
Ein Beispiel für Prognose und automatisiertes maschinelles Lernen finden Sie in diesem Python-Notizbuch: Energy Demand.
Maschinelles Sehen
Die Unterstützung für Computervisionsaufgaben ermöglicht es Ihnen, auf einfache Weise Modelle zu generieren, die auf Bilddaten für Szenarien wie Bildklassifizierung und Objekterkennung trainiert wurden.
Diese Funktion ermöglicht Folgendes:
- Nahtlose Integration mit der Funktion zur Azure Machine Learning-Datenbeschriftung
- Verwenden von beschrifteten Daten zum Generieren von Bildmodellen
- Optimieren der Modellleistung durch Angabe des Modellalgorithmus und durch Abstimmen der Hyperparameter
- Herunterladen oder Bereitstellen des resultierenden Modells als Webdienst in Azure Machine Learning
- Operationalisierung im großen Stil durch Nutzung der MLOps- und ML Pipelines-Funktionen von Azure Machine Learning
Sie können AutoML-Modelle für Visionsaufgaben mithilfe des Azure Machine Learning Python SDK erstellen. Sie können auf die resultierenden Experimentieraufträge, Modelle und Ausgaben der Azure Machine Learning Studio-Benutzeroberfläche zugreifen.
Erfahren Sie, wie Sie das AutoML-Training für Modelle des maschinellen Sehens einrichten.
 Abbildung von: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Abbildung von: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Automatisiertes ML für Bilder unterstützt die folgenden Aufgaben für maschinelles Sehen:
| Aufgabe | BESCHREIBUNG |
|---|---|
| Bildklassifizierung mit mehreren Klassen | Aufgaben, bei denen ein Bild nur mit einer einzelnen Bezeichnung aus einer Reihe von Klassen klassifiziert wird, z. B. wird jedes Bild entweder als Bild einer „Katze“ oder eines „Hundes“ oder einer „Ente“ klassifiziert. |
| Bildklassifizierung mit mehreren Beschriftungen | Aufgaben, bei denen ein Bild eine oder mehrere Beschriftungen aus einer Reihe von Beschriftungen besitzen könnte, z. B. könnte ein Bild sowohl mit „Katze“ als auch mit „Hund“ beschriftet werden. |
| Objekterkennung | Aufgaben zur Identifizierung von Objekten in einem Bild und Lokalisierung der einzelnen Objekte mit einem Begrenzungsrahmen, z. B. die Lokalisierung aller Hunde und Katzen in einem Bild und Zeichnen eines Begrenzungsrahmens um jedes Objekt. |
| Instanzsegmentierung | Aufgaben zur Identifizierung von Objekten in einem Bild auf Pixelebene, indem ein Polygon um jedes Objekt im Bild gezeichnet wird. |
Linguistische Datenverarbeitung: NLP (Natural Language Processing)
Die Unterstützung für NLP-Aufgaben (Natural Language Processing) in automatisiertem ML ermöglicht Ihnen das einfache Generieren von Modellen, die auf Textdaten für textklassifizierungs- und benannte Entitätserkennungsszenarien trainiert wurden. Sie können automatisierte ML-trainierte NLP-Modelle über das Azure Machine Learning Python SDK erstellen. Sie können auf die resultierenden Experimentieraufträge, Modelle und Ausgaben der Azure Machine Learning Studio-Benutzeroberfläche zugreifen.
Die NLP-Funktion unterstützt:
- End-to-End-Deep Neural Network-NLP-Training mit den neuesten vortrainierten BERT-Modellen
- Nahtlose Integration mit Azure Machine Learning Datenbeschriftung
- Verwenden von beschrifteten Daten zum Generieren von NLP-Modellen
- Mehrsprachiger Support mit 104 Sprachen
- Verteiltes Training mit Horovod
Erfahren Sie, wie Sie das Automatisierte ML-Training für NLP-Modelle einrichten.
Trainieren, Überprüfen und Testen von Daten
Mit automatisiertem ML stellen Sie die Trainingsdaten zum Trainieren von ML-Modellen bereit, und Sie können angeben, welche Art von Modellüberprüfung ausgeführt werden soll. Automatisiertes ML führt die Modellvalidierung im Rahmen des Trainings aus. Das heißt, dass automatisiertes ML Validierungsdaten verwendet, um Modellhyperparameter basierend auf dem angewendeten Algorithmus zu optimieren, um die Kombination zu finden, die am besten zu den Trainingsdaten passt. Allerdings werden dieselben Validierungsdaten für jede Iteration der Optimierung verwendet, was zu einer Voreingenommenheit bei der Modellauswertung führt, da das Modell sich weiter verbessert und an die Validierungsdaten anpasst.
Um zu bestätigen, dass diese Verzerrungen nicht auf das endgültige empfohlene Modell angewendet werden, unterstützt das automatisierte ML die Verwendung von Testdaten, um das endgültige Modell zu bewerten, das automatisiertes ML am Ende Ihres Experiments empfiehlt. Wenn Sie Testdaten als Teil Ihrer Experimentkonfiguration für automatisiertes maschinelles Lernen bereitstellen, wird dieses empfohlene Modell standardmäßig am Ende des Experiments (Vorschauversion) getestet.
Wichtig
Das Testen Ihrer Modelle mit einem Testdatensatz zur Bewertung der generierten Modelle ist eine Previewfunktion. Diese Funktion ist eine experimentelle Previewfunktion, die jederzeit geändert werden kann.
Erfahren Sie, wie Sie Experimente für automatisiertes maschinelles Lernen für die Verwendung von Testdaten (Vorschauversion) mit dem SDK oder mit Azure Machine Learning Studio konfigurieren.
Featureentwicklung
Feature Engineering verwendet Domänenkenntnisse der Daten, um Features zu erstellen, die ML-Algorithmen dabei helfen, besser zu lernen. In Azure Machine Learning helfen Skalierungs- und Normalisierungstechniken beim Feature engineering. Zusammen werden diese Techniken und das Feature Engineering als Featurisierung bezeichnet.
Bei Experimenten für automatisiertes maschinelles Lernen erfolgt die Featurisierung automatisch, Sie können sie aber auch basierend auf Ihren Daten anpassen. Erfahren Sie mehr darüber, welche Featurisierung enthalten ist (SDK v1) und wie automatisiertes ML hilft, in Ihren Modellen Überanpassungen und unausgeglichene Daten zu verhindern.
Hinweis
Automatisierte Featurisierungsabläufe für maschinelles Lernen, wie Merkmalsnormalisierung, Behandlung fehlender Daten und Umwandlung von Text in numerische Werte, werden Teil des zugrunde liegenden Modells. Wenn Sie das Modell für Vorhersagen verwenden, werden dieselben Reifungsschritte, die während der Schulung angewendet werden, automatisch auf Ihre Eingabedaten angewendet.
Anpassen der Featurisierung
Sie können auch andere Feature engineering-Techniken verwenden, z. B. Codierung und Transformationen.
Diese Einstellung kann aktiviert werden über:
Azure Machine Learning Studio: Aktivieren Sie die Automatische Merkmalserstellung im Abschnitt Konfigurationsausführungmit diesen Schritten.
Python SDK: Angeben der Featurisierung in Ihrem Objekt für den AutoML-Auftrag. Weitere Informationen zur Aktivierung der Featurisierung.
Ensemblemodelle
Automatisiertes Machine Learning unterstützt Ensemblemodelle, die standardmäßig aktiviert sind. Ensemble Learning verbessert die Ergebnisse des maschinellen Lernens und die prädiktive Leistung, indem mehrere Modelle kombiniert werden, anstatt einzelne Modelle zu verwenden. Die Ensemble-Iterationen erfolgen als abschließende Iterationen Ihres Auftrags. Automatisiertes Machine Learning verwendet die beiden Ensemble-Methoden „voting“ (Abstimmen) und „stacking“ (Stapeln) gemeinsam, um Modelle zu kombinieren:
- Voting: Trifft Vorhersagen auf Grundlage des gewichteten Durchschnitts der vorhergesagten Klassenwahrscheinlichkeiten (für Klassifizierungsaufgaben) oder auf Grundlage der vorhergesagten Regressionsziele (für Regressionsaufgaben).
- Stacking: Kombiniert heterogene Modelle und trainiert ein Metamodell basierend auf der Ausgabe der einzelnen Modelle. Die aktuellen Standardmetamodelle sind LogisticRegression für Klassifizierungsaufgaben und ElasticNet für Regressions-/Vorhersageaufgaben.
Der Caruana Ensemble-Auswahlalgorithmus mit sortierter Ensembleinitialisierung entscheidet, welche Modelle innerhalb des Ensembles verwendet werden sollen. Generell initialisiert dieser Algorithmus das Ensemble mit bis zu fünf Modellen mit den besten Einzelbewertungen und überprüft, ob diese Modelle innerhalb des 5 %-Schwellenwerts der besten Bewertung liegen, um ein schlechtes Ausgangsensemble zu vermeiden. Dann wird für jede Ensemble-Iteration ein neues Modell zum vorhandenen Ensemble hinzugefügt, und die resultierende Bewertung wird berechnet. Wenn ein neues Modell die vorhandene Ensemblebewertung verbessert, wird das Ensemble so aktualisiert, dass es das neue Modell enthält.
Informationen zum Ändern der Standard-Ensembleeinstellungen beim automatisierten maschinellen Lern finden Sie im AutoML-Paket.
AutoML und ONNX
Mit Azure Machine Learning können Sie automatisiertes ML verwenden, um ein Python-Modell zu erstellen und in das ONNX-Format zu konvertieren. Sobald sich die Modelle im ONNX-Format befinden, können Sie sie auf verschiedenen Plattformen und Geräten ausführen. Erfahren Sie mehr über das Beschleunigen von ML-Modellen mit ONNX.
Informationen zum Konvertieren in das ONNX-Format finden Sie in diesem Jupyter Notebook-Beispiel. Erfahren Sie, welche Algorithmen in ONNX unterstützt werden.
Die ONNX-Runtime unterstützt auch C#, sodass Sie das erstellte Modell automatisch in Ihren C#-Apps verwenden können, ohne es neu codieren oder die Netzwerklatenzen in Kauf nehmen zu müssen, die REST-Endpunkte mit sich bringen. Erfahren Sie mehr über die Verwendung eines AutoML ONNX-Modells in einer .NET-Anwendung mit ML.NET und das Rückschließen von ONNX-Modellen mit der C#-API für die ONNX-Runtime.
Nächste Schritte
Verwenden Sie die folgenden Ressourcen, um mit AutoML auf dem Laufenden zu sein.
Tutorials und Anleitungen
Tutorials sind einführende End-to-End-Beispiele für AutoML-Szenarien.
Für eine erste Codeerfahrung folgen Sie dem Lernprogramm: Trainieren eines Objekterkennungsmodells mit AutoML und Python.
Für die Herangehensweise mit wenig/keinem Code sehen Sie sich die Informationen unter Tutorial: Trainieren eines Klassifizierungsmodells mit automatisiertem ML ohne Schreiben von Code in Azure Machine Learning Studio an.
Artikel mit Anleitungen enthalten weitere Details dazu, welche Funktionen automatisierte ML bietet. Beispiel:
Konfigurieren der Einstellungen für automatische Trainingsexperimente
Erfahren Sie, wie Sie Modelle für maschinelles Sehen mit Python trainieren.
Erfahren Sie, wie Sie den generierten Code aus Ihren Modellen für automatisiertes ML (SDK v1) anzeigen.
Jupyter Notebook-Beispiele
Überprüfen Sie detaillierte Codebeispiele und Anwendungsfälle im GitHub-Notebook-Repository für Beispiele zum automatisierten maschinellen Lernen.
Referenz zum Python SDK
Vertiefen Sie Ihre Kenntnisse über SDK-Entwurfsmuster und Klassenspezifikationen mit der Klassenreferenzdokumentation für AutoML-Aufträge.
Hinweis
Die Funktionen des automatisierten maschinellen Lernens sind auch in anderen Lösungen von Microsoft verfügbar: ML.NET, HDInsight, Power BI und SQL Server