Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel werden Überlegungen zum Verwalten von Daten in einer Microservices-Architektur beschrieben. Jeder Microservice verwaltet seine eigenen Daten, sodass Datenintegrität und Datenkonsistenz kritische Herausforderungen darstellen.
Zwei Dienste sollten keinen Datenspeicher freigeben. Jeder Dienst verwaltet einen eigenen privaten Datenspeicher, und andere Dienste können nicht direkt darauf zugreifen. Diese Regel verhindert unbeabsichtigte Kopplung zwischen Diensten, was geschieht, wenn Dienste dieselben zugrunde liegenden Datenschemas nutzen. Wenn sich das Datenschema ändert, muss die Änderung für jeden Dienst koordiniert werden, der auf dieser Datenbank basiert. Durch das Isolieren des Datenspeichers jedes Diensts wird der Umfang der Änderung begrenzt und die Flexibilität unabhängiger Bereitstellungen beibehalten. Jeder Microservice kann auch über eindeutige Datenmodelle, Abfragen oder Lese- und Schreibmuster verfügen. Ein freigegebener Datenspeicher schränkt die Fähigkeit jedes Teams ein, die Datenspeicherung für seinen spezifischen Dienst zu optimieren.
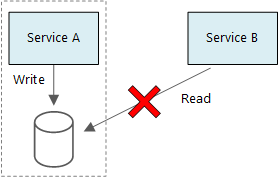
Das Diagramm zeigt Dienst A und eine Datenbank in einem Abschnitt auf der linken Seite. Ein Pfeil mit der Bezeichnung Schreibpunkte von Dienst A auf die Datenbank. Dienst B befindet sich außerhalb dieses Abschnitts auf der rechten Seite. Ein Pfeil mit der Bezeichnung "lesen" zeigt auf die Datenbank. Ein rotes X überschreitet diesen Pfeil.
Dieser Ansatz führt natürlich zu polyglot persistenz, was bedeutet, dass mehrere Datenspeichertechnologien in einer einzigen Anwendung verwendet werden. Ein Dienst benötigt möglicherweise die Schema-on-Read-Funktionen einer Dokumentdatenbank. Ein anderer Dienst benötigt möglicherweise die referenzielle Integrität, die ein relationales Datenbankverwaltungssystem (RDBMS) bereitstellt. Jedes Team kann die beste Option für seinen Dienst auswählen.
Hinweis
Dienste können denselben physischen Datenbankserver sicher gemeinsam nutzen. Probleme treten auf, wenn Dienste dasselbe Schema verwenden, oder sie lesen und schreiben in dieselbe Gruppe von Datenbanktabellen.
Herausforderungen
Der verteilte Ansatz zum Verwalten von Daten führt zu mehreren Herausforderungen. Zunächst kann Redundanz in allen Datenspeichern auftreten. Dasselbe Datenelement wird möglicherweise an mehreren Stellen angezeigt. Beispielsweise können Daten als Teil einer Transaktion gespeichert und dann an anderer Stelle für Analysen, Berichte oder Archivierungen gespeichert werden. Doppelte oder partitionierte Daten können zu Problemen mit Datenintegrität und Konsistenz führen. Wenn Datenbeziehungen mehrere Dienste umfassen, können herkömmliche Datenverwaltungstechniken diese Beziehungen nicht erzwingen.
Herkömmliche Datenmodellierung folgt der Regel einer Tatsache an einem Ort. Jede Entität wird genau einmal im Schema angezeigt. Andere Entitäten könnten darauf verweisen, aber es nicht duplizieren. Der Hauptvorteil des herkömmlichen Ansatzes besteht darin, dass Aktualisierungen an einem zentralen Ort auftreten, wodurch Datenkonsistenzprobleme verhindert werden. In einer Microservices-Architektur müssen Sie berücksichtigen, wie Updates über Dienste verteilt werden und wie sie die letztendliche Konsistenz verwalten, wenn Daten an mehreren Stellen ohne starke Konsistenz angezeigt werden.
Ansätze zum Verwalten von Daten
Für alle Fälle funktioniert kein einzelner Ansatz. Beachten Sie die folgenden allgemeinen Richtlinien zum Verwalten von Daten in einer Microservices-Architektur:
Definieren Sie die erforderliche Konsistenzstufe für jede Komponente und bevorzugen Sie, wo möglich, die Eventual-Konsistenz. Identifizieren Sie Bereiche im System, in denen Sie starke Konsistenz, Atomizität, Konsistenz, Isolation und Haltbarkeit in ACID-Transaktionen benötigen. Und identifizieren Sie Bereiche, in denen die mögliche Konsistenz akzeptabel ist. Weitere Informationen finden Sie unter Verwenden des taktischen domänengesteuerten Designs (DDD) für Microservices.
Verwenden Sie eine einzige Quelle der Wahrheit, wenn Sie eine starke Konsistenz erfordern. Ein Dienst kann die Quelle der Wahrheit für eine bestimmte Entität darstellen und über eine API verfügbar machen. Andere Dienste können ihre eigene Kopie der Daten oder eine Teilmenge der Daten enthalten, die letztendlich mit den primären Daten konsistent sind, aber nicht als Quelle der Wahrheit betrachtet werden. Beispielsweise kann der Empfehlungsdienst in einem E-Commerce-System, das über einen Kundendienst und einen Empfehlungsdienst verfügt, Ereignisse des Bestelldiensts abhören. Wenn ein Kunde jedoch eine Rückerstattung anfordert, hat der Bestellservice, nicht der Empfehlungsdienst, den vollständigen Transaktionsverlauf.
Wenden Sie Transaktionsmuster an, um Konsistenz über Dienste hinweg aufrechtzuerhalten. Verwenden Sie Muster wie Scheduler Agent Supervisor und Ausgleichstransaktion , um Daten über mehrere Dienste hinweg konsistent zu halten. Um einen teilweisen Fehler zwischen mehreren Diensten zu vermeiden, müssen Sie möglicherweise eine zusätzliche Datenmenge speichern, die den Status einer Arbeitseinheit erfasst, die mehrere Dienste umfasst. Behalten Sie beispielsweise ein Arbeitsobjekt in einer beständigen Warteschlange, während eine Transaktion mit mehreren Schritten abläuft.
Speichern Sie nur die Daten, die ein Dienst benötigt. Ein Dienst benötigt möglicherweise nur eine Teilmenge von Informationen zu einer Domänenentität. Beispielsweise müssen Sie im gebundenen Versandkontext wissen, welcher Kunde einer bestimmten Lieferung zugeordnet ist. Sie benötigen jedoch nicht die Rechnungsadresse des Kunden, da der gebundene Kontokontext diese Informationen verwaltet. Sorgfältige Domänenanalyse und ein DDD-Ansatz können diesen Grundsatz erzwingen.
Überlegen Sie, ob Ihre Dienste kohärent und lose gekoppelt sind. Wenn zwei Dienste kontinuierlich Informationen miteinander austauschen und chatty APIs erstellen, müssen Sie möglicherweise Ihre Dienstgrenzen neu zeichnen. Führen Sie die beiden Dienste zusammen, oder umgestalten Sie ihre Funktionalität.
Verwenden Sie einen ereignisgesteuerten Architekturstil. In diesem Architekturstil veröffentlicht ein Dienst ein Ereignis, wenn Änderungen an seinen öffentlichen Modellen oder Entitäten auftreten. Andere Dienste können diese Ereignisse abonnieren. Beispielsweise kann ein anderer Dienst die Ereignisse verwenden, um eine materialisierte Ansicht der Daten zu erstellen, die für die Abfrage besser geeignet sind.
Veröffentlichen sie ein Schema für Ereignisse. Ein Dienst, der Ereignisse besitzt, sollte ein Schema veröffentlichen, um die Serialisierung und Deserialisierung von Ereignissen zu automatisieren. Dieser Ansatz verhindert eine enge Kopplung zwischen Herausgebern und Abonnenten. Erwägen Sie das JSON-Schema oder ein Framework wie Protobuf oder Avro.
Reduzieren Sie Ereignisengpässe im großen Maßstab. Im großen Maßstab können Ereignisse zu einem Engpass auf dem System werden. Erwägen Sie die Verwendung von Aggregation oder Batchverarbeitung, um die Gesamtlast zu reduzieren.
Beispiel: Auswählen von Datenspeichern für die Drohnenzustellanwendung
Die vorherigen Artikel dieser Reihe beschreiben einen Drohnen-Lieferdienst als laufendes Beispiel. Weitere Informationen zum Szenario und zur entsprechenden Architektur finden Sie unter Entwerfen einer Microservices-Architektur.
Diese Anwendung definiert mehrere Mikroservices für die Planung von Lieferungen durch Drohnen. Wenn ein Benutzer eine neue Zustellung plant, enthält die Clientanforderung Informationen über die Zustellung, z. B. Abholungs- und Abgabeorte, und über das Paket, z. B. Größe und Gewicht. Diese Informationen definieren eine Arbeitseinheit.
Die verschiedenen Back-End-Dienste verwenden unterschiedliche Teile der Informationen in der Anforderung und weisen unterschiedliche Lese- und Schreibprofile auf.

Zustellungsdienst
Der Zustellungsdienst speichert Informationen zu jeder aktuell geplanten oder in Bearbeitung befindlichen Lieferung. Es lauscht auf Ereignisse von den Drohnen und verfolgt den Status der laufenden Lieferungen. Außerdem werden Domänenereignisse mit Aktualisierungen zum Übermittlungsstatus gesendet.
Benutzer überprüfen häufig den Status einer Lieferung, während sie auf ihr Paket warten. Daher erfordert der Lieferservice einen Datenspeicher, der auf Durchsatz (Lese- und Schreibzugriff) statt auf langfristige Speicherung fokussiert. Der Zustellungsdienst führt keine komplexen Abfragen oder Analysen durch. Er ruft nur den neuesten Status für eine bestimmte Zustellung ab. Das Übermittlungsdienstteam wählte Azure Managed Redis für seine hohe Lese-/Schreibleistung aus. Die in Azure Managed Redis gespeicherten Informationen sind kurzlebig. Nach Abschluss einer Lieferung wird der Lieferhistorienservice zum verbindlichen Datensystem.
Lieferhistoriedienst
Der Übermittlungsverlaufsdienst empfängt Statusupdates vom Zustellungsdienst. Diese Daten werden langfristig gespeichert. Diese historischen Daten unterstützen zwei Szenarien mit unterschiedlichen Speicheranforderungen.
Das erste Szenario aggregiert Daten für Datenanalysen, um das Unternehmen zu optimieren oder die Dienstqualität zu verbessern. Der Übermittlungsverlaufsdienst macht die eigentliche Datenanalyse nicht. Die Daten werden nur aufgenommen und gespeichert. Für dieses Szenario muss der Speicher für die Datenanalyse über große Datasets optimiert werden und einen Schema-on-Read-Ansatz verwenden, um verschiedene Datenquellen aufzunehmen. Azure Data Lake Storage eignet sich gut für dieses Szenario, da es sich um ein Apache Hadoop-Dateisystem handelt, das mit Hadoop Distributed File System (HDFS) kompatibel ist. Es ist auch für die Leistung für Datenanalyseszenarien optimiert.
Im zweiten Szenario können Benutzer den Verlauf einer Übermittlung nach Abschluss der Übermittlung nachschlagen. Data Lake Storage unterstützt dieses Szenario nicht. Um eine optimale Leistung zu erzielen, speichern Sie Datenreihen in Data Lake Storage in Ordnern, die nach Datum partitioniert sind. Diese Struktur macht jedoch einzelne ID-basierte Nachschlagevorgänge ineffizient. Sofern Sie nicht auch den Zeitstempel kennen, muss eine ID-Suche die gesamte Sammlung scannen. Um dieses Problem zu beheben, speichert der Übermittlungsverlaufsdienst auch eine Teilmenge der historischen Daten in Azure Cosmos DB für eine schnellere Suche. Die Datensätze müssen nicht unbegrenzt in Azure Cosmos DB bleiben. Sie können ältere Lieferungen nach einem bestimmten Zeitraum, z. B. einen Monat, archiviert werden, indem Sie einen gelegentlichen Batchprozess ausführen. Archivierungsdaten können die Kosten für Azure Cosmos DB reduzieren und die Daten für historische Berichte aus Data Lake Storage verfügbar halten.
Weitere Informationen finden Sie unter Tune Data Lake Storage for performance.
Paketdienst
Der Paketdienst speichert Informationen zu allen Paketen. Der Datenspeicher für den Paketdienst muss die folgenden Anforderungen erfüllen:
- Langfristige Speicherung
- Hoher Schreibdurchsatz zur Behandlung eines großen Paketvolumens
- Einfache Abfragen nach Paket-ID ohne komplexe Verknüpfungen oder Einschränkungen der referenziellen Integrität
Die Paketdaten sind nicht relational, daher funktioniert eine dokumentorientierte Datenbank gut. Azure DocumentDB kann einen hohen Durchsatz erzielen, indem Sharded-Sammlungen verwendet werden. Das Paketdienstteam ist mit dem MongoDB-, Express.js-, AngularJS- und Node.js (MEAN)-Stapel vertraut, sodass sie Azure DocumentDB implementieren. Mit dieser Wahl können sie ihre vorhandene MongoDB-Erfahrung verwenden und gleichzeitig die Vorteile eines vollständig verwalteten Hochleistungs-Azure-Diensts nutzen.