Überlegungen zur Anwendungsplattform für unternehmenskritische Workloads
Ein wichtiger Entwurfsbereich jeder kritischen Unternehmensarchitektur ist die Anwendungsplattform. Plattform bezieht sich auf die Infrastrukturkomponenten und Azure-Dienste, die bereitgestellt werden müssen, um die Anwendung zu unterstützen. Hier folgen nun ein paar übergreifende Empfehlungen.
Entwerfen Sie in Ebenen. Wählen Sie die richtige Gruppe von Diensten aus, deren Konfiguration und die anwendungsspezifischen Abhängigkeiten. Dieser Ebenenansatz hilft beim Erstellen einer logischen und physischen Segmentierung. Er ist nützlich beim Definieren von Rollen und Funktionen sowie beim Zuweisen entsprechender Berechtigungen und Bereitstellungsstrategien. Dieser Ansatz erhöht letztlich die Zuverlässigkeit des Systems.
Eine unternehmenskritische Anwendung muss hoch zuverlässig und widerstandsfähig gegenüber Rechenzentrums- und regionalen Ausfällen sein. Die Hauptstrategie besteht im Aufbau von zonaler und regionaler Redundanz in einer Aktiv/Aktiv-Konfiguration. Wenn Sie Azure-Dienste für die Plattform Ihrer Anwendung auswählen, berücksichtigen Sie deren Unterstützung für Verfügbarkeitszonen sowie deren Bereitstellungs- und Betriebsmuster für die Verwendung mehrerer Azure-Regionen.
Verwenden Sie eine auf Skalierungseinheiten basierende Architektur, um erhöhte Lasten verarbeiten zu können. Skalierungseinheiten ermöglichen es Ihnen, Ressourcen logisch zu gruppieren, und eine Einheit kann unabhängig von anderen Einheiten oder Diensten in der Architektur skaliert werden. Verwenden Sie Ihr Kapazitätsmodell und die erwartete Leistung, um die Grenzen, die Anzahl und die Baselineskalierung jeder Einheit zu definieren.
In dieser Architektur besteht die Anwendungsplattform aus globalen, Bereitstellungsstempel- und regionalen Ressourcen. Die regionalen Ressourcen werden als Teil eines Bereitstellungsstempels bereitgestellt. Jeder Stempel entspricht einer Skalierungseinheit und kann, falls es fehlerhaft wird, vollständig ersetzt werden.
Die Ressourcen auf jeder Ebene weisen unterschiedliche Merkmale auf. Weitere Informationen finden Sie unter Architekturmuster für unternehmenskritische Workloads in Azure.
| Merkmale | Überlegungen |
|---|---|
| Lebensdauer | Was ist die erwartete Lebensdauer der Ressource, relativ zu anderen Ressourcen in der Lösung? Sollte die Ressource eine länger oder dieselbe Lebensdauer wie das gesamte System oder die gesamte Region haben, oder sollte sie nur vorübergehend sein? |
| State | Welche Auswirkungen hat der persistente Zustand auf dieser Ebene auf Zuverlässigkeit oder Verwaltbarkeit? |
| Reach | Ist es erforderlich, dass die Ressource global verteilt wird? Kann die Ressource mit anderen Ressourcen, global oder in Regionen, kommunizieren? |
| Abhängigkeiten | Welche Abhängigkeit von anderen Ressourcen, global oder in anderen Regionen, bestehen? |
| Skalierungslimits | Wie hoch ist der erwartete Durchsatz für diese Ressource auf dieser Ebene? Wie viel Skalierung wird von der Ressource zur Anpassung an diese Nachfrage bereitgestellt? |
| Verfügbarkeit/Notfallwiederherstellung | Was sind die Auswirkungen auf die Verfügbarkeit oder Notfallwiederherstellung auf dieser Ebene? Würde es einen Systemausfall oder nur lokal begrenzte Kapazitäts- oder Verfügbarkeitsprobleme verursachen? |
Globale Ressourcen
Bestimmte Ressourcen in dieser Architektur werden von Ressourcen gemeinsam genutzt, die in Regionen bereitgestellt sind. In dieser Architektur werden sie verwendet, um Datenverkehr auf mehrere Regionen zu verteilen, den dauerhaften Zustand für die gesamte Anwendung zu speichern und globale statische Daten zwischenzuspeichern.
| Merkmale | Überlegungen zu Ebenen |
|---|---|
| Lebensdauer | Es wird erwartet, dass diese Ressourcen langlebig sein werden. Ihre Lebensdauer umfasst die Lebensdauer des Systems oder mehr. Häufig werden die Ressourcen mit lokalen Daten- und Steuerungsebenenupdates verwaltet, wobei vorausgesetzt wird, dass sie Updatevorgänge ohne jegliche Ausfallzeiten unterstützen. |
| State | Da diese Ressourcen mindestens für die Lebensdauer des Systems existieren, ist diese Ebene häufig für das Speichern globaler, georeplizierter Zustände verantwortlich. |
| Reach | Die Ressourcen sollten global verteilt werden. Es wird empfohlen, dass diese Ressourcen mit regionalen oder anderen Ressourcen mit geringer Latenz und der gewünschten Konsistenz kommunizieren. |
| Abhängigkeiten | Die Ressourcen sollten Abhängigkeiten von regionalen Ressourcen vermeiden, da deren Nichtverfügbarkeit eine Ursache für globale Ausfälle sein kann. Beispielsweise könnten Zertifikate oder Geheimnisse, die in einem einzelnen Tresor aufbewahrt werden, globale Auswirkungen haben, wenn es am Standort des Tresors zu einem regionalen Ausfall kommt. |
| Skalierungslimits | Häufig sind diese Ressourcen Singleton-Instanzen im System, und sollten als solche in der Lage sein, sich so zu skalieren, dass sie den Durchsatz des Systems als Ganzes verarbeiten können. |
| Verfügbarkeit/Notfallwiederherstellung | Da regionale und Stempelressourcen globale Ressourcen nutzen bzw. diese deren Front-End bilden können, ist es entscheidend, dass globale Ressourcen für die Integrität des gesamten Systems mit Hochverfügbarkeit und Notfallwiederherstellung konfiguriert sind. |
In dieser Architektur sind globale Ebenenressourcen Azure Front Door, Azure Cosmos DB, Azure Container Registry und Azure Log Analytics zum Speichern von Protokollen und Metriken aus anderen globalen Ebenenressourcen.
In diesem Design gibt es weitere grundlegende Ressourcen, z. B. Microsoft Entra ID und Azure DNS. Sie wurden in dieser Abbildung aus Gründen der Kürze ausgelassen.

Globaler Lastenausgleich
Azure Front Door wird als einziger Einstiegspunkt für den Benutzerdatenverkehr verwendet. Azure garantiert, dass Azure Front Door die angeforderten Inhalte ohne Fehler in 99,99 % der Zeit liefert. Weitere Details finden Sie unter Grenzwerte von Front Door Service. Wenn Front Door nicht mehr verfügbar ist, erscheint dem Endbenutzer das System als ausgefallen.
Die Front Door-Instanz sendet Datenverkehr an die konfigurierten Back-End-Dienste, z. B. den Computecluster, der die API und die Front-End-SPA hostet. Fehlkonfigurationen des Back-Ends in Front Door können zu Ausfällen führen. Um Ausfälle aufgrund von Fehlkonfigurationen zu vermeiden, sollten Sie Ihre Front Door-Einstellungen umfassend testen.
Ein weiterer gängiger Fehler kann von fehlkonfigurierten oder fehlenden TLS-Zertifikaten kommen, die verhindern können, dass Benutzer das Front-End oder Front Door verwenden können, das mit dem Back-End kommuniziert. Eine Mitigation erfordert möglicherweise manuelles Eingreifen. Sie können sich z. B. für ein Rollback auf die vorherige Konfiguration entschließen und das Zertifikat, falls möglich, erneut ausstellen. Planen Sie unabhängig davon ein, dass es zu Nichtverfügbarkeit kommen wird. Die Verwendung verwalteter Zertifikate, die von Front Door angeboten werden, wird empfohlen, um den Betriebsmehraufwand zu verringern, z. B. die Behandlung des Ablaufs.
Front Door bietet viele zusätzliche Funktionen neben dem globalen Datenverkehrsrouting. Eine wichtige Funktion ist die Web Application Firewall (WAF), da Front Door in der Lage ist, den durchlaufenden Datenverkehr zu überprüfen. Wenn sie im Präventionsmodus konfiguriert ist, wird verdächtiger Datenverkehr blockiert, sogar bevor er eins der Back-Ends erreichen kann.
Informationen zu Front Door-Funktionen finden Sie unter Häufig gestellte Fragen zu Azure Front Door.
Weitere Überlegungen zur globalen Verteilung des Datenverkehrs finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Globales Routing.
Container Registry
Azure Container Registry wird verwendet, um OCI-Artefakte (Open Container Initiative) zu speichern, insbesondere Helm-Diagramme und Containerimages. Sie nimmt nicht am Anforderungsflow teil, und der Zugriff darauf erfolgt nur zeitweise. Die Containerregistrierung muss vorhanden sein, bevor Stempelressourcen bereitgestellt werden, und sollte keine Abhängigkeiten von regionalen Ebenenressourcen haben.
Aktivieren Sie Zonenredundanz und Georeplikation von Registrierungen, damit der Laufzeitzugriff auf Images schnell und resilient gegenüber Fehlern erfolgt. Im Falle der Nichtverfügbarkeit kann die Instanz dann ein Failover auf Replikatregionen durchführen, woraufhin Anforderungen automatisch an eine andere Region umgeleitet werden. Erwarten Sie vorübergehende Fehler beim Pullen von Images, bis das Failover abgeschlossen ist.
Ausfälle können auch auftreten, wenn Images versehentlich gelöscht werden. Neue Serverknoten können dann keine Images pullen, aber vorhandene Knoten können weiterhin zwischengespeicherte Images verwenden. Die primäre Strategie für die Notfallwiederherstellung ist die erneute Bereitstellung. Die Artefakte in einer Containerregistrierung können aus Pipelines neu generiert werden. Die Containerregistrierung muss vielen gleichzeitigen Verbindungen standhalten können, um alle Ihre Bereitstellungen zu unterstützen.
Es wird empfohlen, die Premium-SKU zum Aktivieren der Georeplikation zu verwenden. Das Feature „Zonenredundanz“ stellt Resilienz und Hochverfügbarkeit innerhalb einer bestimmten Region sicher. Bei einem regionalen Ausfall stehen Replikate in anderen Regionen weiterhin für Datenebenenvorgänge zur Verfügung. Mit dieser SKU können Sie den Zugriff auf Bilder durch private Endpunkte einschränken.
Weitere Informationen finden Sie unter Bewährte Methoden für Azure Container Registry.
Datenbank
Es wird empfohlen, den gesamten Zustand global in einer Datenbank zu speichern, die von regionalen Stempeln getrennt ist. Erzeugen Sie Redundanz, indem Sie die Datenbank regionsübergreifend bereitstellen. Bei unternehmenskritischen Workloads sollte die regionsübergreifende Synchronisierung von Daten das wichtigste Anliegen sein. Auch im Falle eines Ausfalls sollten Schreibanforderungen an die Datenbank weiterhin funktionsfähig sein.
Datenreplikation in einer Aktiv/Aktiv-Konfiguration wird dringend empfohlen. Die Anwendung sollte in der Lage sein, sofort eine Verbindung mit einer anderen Region herzustellen. Alle Instanzen sollten in der Lage sein, Lese- und Schreibanforderungen zu verarbeiten.
Weitere Informationen finden Sie unter Datenplattform für unternehmenskritische Workloads.
Globale Überwachung
Azure Log Analytics wird verwendet, um Diagnoseprotokolle aus allen globalen Ressourcen zu speichern. Es wird empfohlen, das tägliche Kontingent für Speicher zu begrenzen, insbesondere in Umgebungen, die für Auslastungstest verwendet werden. Legen Sie außerdem eine Aufbewahrungsrichtlinie fest. Diese Einschränkungen verhindern Ausgabenüberschreitungen, die durch die grenzwertüberschreitende Speicherung von Daten verursacht werden, die nicht benötigt werden.
Überlegungen zu grundlegenden Diensten
Es ist wahrscheinlich, dass das System andere kritische Plattformdienste verwenden wird, die dazu führen können, dass das gesamte System gefährdet wird, wie z. B. Azure DNS und Microsoft Entra ID. Azure DNS garantiert eine SLA mit Verfügbarkeit von 100 % für gültige DNS-Anforderungen. Microsoft Entra garantiert mindestens 99,99 % Uptime. Dennoch sollten Sie sich der Auswirkungen im Falle eines Ausfalls bewusst sein.
Unumgängliche (harte) Abhängigkeiten von grundlegenden Diensten sind unvermeidlich, da viele Azure-Dienste davon abhängig sind. Erwarten Sie Unterbrechungen im System, wenn diese nicht verfügbar sind. Beispiel:
- Azure Front Door verwendet Azure DNS, um das Back-End und andere globale Dienste zu erreichen.
- Azure Container Registry verwendet Azure DNS, um ein Failover von Anforderungen in eine andere Region auszuführen.
In beiden Fällen sind beide Azure-Dienste davon betroffen, wenn Azure DNS nicht verfügbar ist. Die Namensauflösung für Benutzeranforderungen von Front Door schlägt fehl, und Docker-Images können nicht aus der Registrierung gepulllt werden. Die Verwendung eines externen DNS-Diensts als Sicherung verringert das Risiko nicht, da viele Azure-Dienste eine solche Konfiguration nicht zulassen und auf einem internen DNS basieren. Erwarten Sie einen vollständigen Ausfall.
Ebenso wird Microsoft Entra ID für Steuerungsebenenvorgänge wie das Erstellen neuer AKS-Knoten, das Pullen von Images aus der Containerregistrierung oder den Zugriff auf Key Vault beim Podstart verwendet. Wenn Microsoft Entra ID nicht verfügbar ist, sollten vorhandene Komponenten davon nicht betroffen sein, doch die Gesamtleistung kann sich verschlechtern. Neue Pods oder AKS-Knoten funktionieren dann nicht. Wenn also während dieser Zeit Skalierungsvorgänge erforderlich sein sollten, erwarten Sie eine verschlechterte Benutzererfahrung.
Regionale Bereitstellungsstempelressourcen
In dieser Architektur stellt der Bereitstellungsstempel die Workload sowie Ressourcen bereit, die an der Durchführung von Geschäftsvorgängen beteiligt sind. Ein Stempel entspricht normalerweise einer Bereitstellung in einer Azure-Region. Obwohl eine Region über mehr als einen Stempel verfügen kann.
| Merkmale | Überlegungen |
|---|---|
| Lebensdauer | Es wird erwartet, dass diese Ressourcen eine kurze Lebensdauer (kurzlebig) haben werden, mit der Absicht, dass sie dynamisch hinzugefügt und entfernt werden können, während regionale Ressourcen außerhalb des Stempels weiterhin bestehen bleiben. Die kurzlebige Natur ist erforderlich, um höhere Resilienz, Skalierung und Nähe zu Benutzern bereitzustellen. |
| State | Da Stempel kurzlebig sind und jederzeit zerstört werden können, sollte ein Stempel so zustandslos wie möglich sein. |
| Reach | Kann mit regionalen und globalen Ressourcen kommunizieren. Die Kommunikation mit anderen Regionen oder anderen Stempeln sollte jedoch vermieden werden. In dieser Architektur ist es nicht erforderlich, dass diese Ressourcen global verteilt sind. |
| Abhängigkeiten | Die Stempelressourcen müssen unabhängig sein. Das heißt, sie sollten nicht von anderen Stempeln oder Komponenten in anderen Regionen abhängig sein oder darauf basieren. Es wird erwartet, dass sie regionale und globale Abhängigkeiten besitzen. Die gemeinsam genutzten Hauptkomponenten sind die Datenbankebene und die Containerregistrierung. Diese Komponenten erfordern eine Synchronisierung zur Laufzeit. |
| Skalierungslimits | Der Durchsatz wird durch Tests bestimmt. Der Durchsatz des gesamten Stempels ist auf die Ressource mit der niedrigsten Leistung begrenzt. Der Stempeldurchsatz muss die geschätzte hohe Nachfrage berücksichtigen sowie jedes Failover als Ergebnis eines anderen Stempels, der in der Region ausfällt. |
| Verfügbarkeit/Notfallwiederherstellung | Aufgrund der temporären Natur von Stempeln erfolgt die Notfallwiederherstellung durch erneute Bereitstellung des Stempels. Wenn Ressourcen sich in einem fehlerhaften Zustand befinden, kann der Stempel als Ganzes zerstört und erneut bereitgestellt werden. |
In dieser Architektur sind Stempelressourcen Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault und Azure Blob Storage.
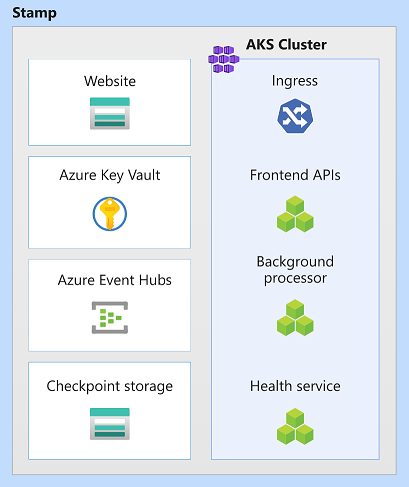
Skalierungseinheit
Ein Stempel kann auch als Skalierungseinheit (SU) betrachtet werden. Alle Komponenten und Dienste innerhalb eines bestimmten Stempels sind so konfiguriert und getestet, dass sie Anforderungen in einem bestimmten Bereich bedienen können. Hier finden Sie ein Beispiel für eine Skalierungseinheit, die in der Implementierung verwendet wird.
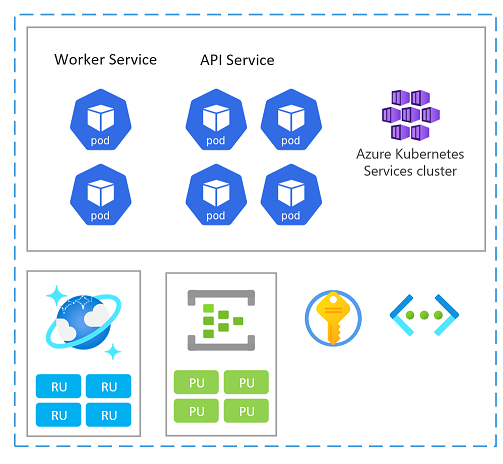
Jede Skalierungseinheit wird in einer Azure-Region bereitgestellt und verarbeitet daher primär Datenverkehr aus diesem vorgegebenen Bereich (obwohl sie bei Bedarf den Datenverkehr von anderen Regionen übernehmen kann). Diese geografische Verteilung führt wahrscheinlich zu Auslastungsmustern und Geschäftszeiten, die sich von Region zu Region unterscheiden können. Daher ist jede Skalierungseinheit so konzipiert, dass sie sich im Leerlauf ab- bzw. herunterskaliert.
Sie können einen neuen Stempel zu Skalierungszwecken bereitstellen. Innerhalb eines Stempels können einzelne Ressourcen auch Skalierungseinheiten sein.
Hier finden Sie ein paar Überlegungen zur Skalierung und Verfügbarkeit bei der Auswahl von Azure-Diensten in einer Einheit:
Evaluieren Sie Kapazitätsbeziehungen zwischen allen Ressourcen in einer Skalierungseinheit. Um beispielsweise 100 eingehende Anforderungen zu behandeln, wären 5 Eingangsdatencontroller-Pods und 3 Katalogdienstpods sowie 1000 RUs in Azure Cosmos DB erforderlich. Wenn Sie also die Eingangspods automatisch skalieren, rechnen Sie auch mit der Skalierung des Katalogdiensts und der Azure Cosmos DB-RUs für diese Bereiche.
Führen Sie Auslastungstests der Dienste durch, um einen Bereich zu ermitteln, in dem Anforderungen bedient werden können. Konfigurieren Sie auf Grundlage der Ergebnisse Mindest- und Maximalwerte für Instanzen sowie Zielmetriken. Wenn das Ziel erreicht wird, können Sie sich für die automatische Skalierung der gesamten Einheit entscheiden.
Überprüfen Sie die Skalierungsgrenzwerte und Kontingente des Azure-Abonnements, um das von den Geschäftsanforderungen bestimmte Kapazitäts- und Kostenmodell zu unterstützen. Überprüfen Sie außerdem die Grenzwerte einzelner Dienste, die Sie in Erwägung ziehen. Da Einheiten in der Regel zusammen bereitgestellt werden, berechnen Sie die Grenzwerte der Abonnementressource mit ein, die für Canary-Bereitstellungen erforderlich sind. Weitere Informationen finden Sie unter Grenzwerte des Azure-Diensts.
Wählen Sie Dienste aus, die Verfügbarkeitszonen unterstützen, um Redundanz zu erzeugen. Dies kann Ihre Technologieauswahl einschränken. Weitere Informationen finden Sie unter Verfügbarkeitszonen.
Weitere Überlegungen zur Größe einer Einheit und zu Kombinationen von Ressourcen finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Architektur von Skalierungseinheiten.
Computecluster
Um die Workload zu containerisieren, muss auf jedem Stempel ein Computecluster ausgeführt werden. In dieser Architektur wird Azure Kubernetes Service (AKS) ausgewählt, weil Kubernetes die beliebteste Computeplattform für moderne, containerisierte Anwendungen ist.
Die Lebensdauer des AKS-Clusters ist an die kurzlebige Natur des Stempels gebunden. Der Cluster ist zustandslos und verfügt über keine persistenten Volumes. Es verwendet kurzlebige Betriebssystemdatenträger anstelle verwalteter Datenträger, da nicht davon ausgegangen wird, dass Wartungen des Datenträgers auf Anwendungs- oder Systemebene durchgeführt werden.
Um die Zuverlässigkeit zu erhöhen, wird der Cluster so konfiguriert, dass er alle drei Verfügbarkeitszonen in einer bestimmten Region verwendet. Um die AKS Uptime SLA zu aktivieren, die 99,95 % SLA-Verfügbarkeit der AKS-Steuerungsebene garantiert, sollte der Cluster entweder die Standard- oder die Premium--Ebene verwenden. Weitere Informationen finden Sie unter AKS-Tarife.
Andere Faktoren wie Skalierungslimits, Computekapazität oder Abonnementkontingente können sich auch auf die Zuverlässigkeit auswirken. Wenn nicht genügend Kapazität vorhanden ist oder Grenzwerte erreicht werden, schlagen Auf- und Hochskalierungsvorgänge fehl, aber vorhandene Computekapazität sollte weiterhin funktionieren.
Für den Cluster ist die automatische Skalierung aktiviert, damit Knotenpools bei Bedarf automatisch aufskalieren können, was die Zuverlässigkeit verbessert. Wenn Sie mehrere Knotenpools verwenden, sollten alle Knotenpools automatisch skaliert werden.
Auf Podebene werden bei der „horizontalen automatischen Podskalierung“ (Horizontal Pod Autoscaler, HPA) Pods basierend auf konfigurierten CPU-, Arbeitsspeicher- oder benutzerdefinierten Metriken skaliert. Führen Sie Auslastungstests mit den Komponenten der Workload durch, um eine Baseline für die Werte Autoskalierungs- und HPA-Werte zu etablieren.
Der Cluster ist auch für automatische Knotenimageupgrades konfiguriert und kann während dieser Upgrades entsprechend skaliert werden. Diese Skalierung ermöglicht die Vermeidung jeglicher Ausfallzeiten, während Upgrades ausgeführt werden. Wenn der Cluster in einem Stempel während eines Upgrades ausfällt, sollten andere Cluster in anderen Stempeln davon nicht betroffen sein, doch stempelübergreifende Upgrades sollten zu unterschiedlichen Zeiten erfolgen, um die Verfügbarkeit aufrechtzuerhalten. Außerdem werden Clusterupgrades automatisch über Knoten hinweg ausgerollt, sodass sie nicht gleichzeitig nicht verfügbar sind.
Einige Komponenten wie der Zertifikat-Manager (cert-manager) und ingress-nginx erfordern Containerimages aus externen Containerregistrierungen. Wenn diese Repositorys oder Images nicht verfügbar sind, können neue Instanzen auf neuen Knoten (wo das Image nicht zwischengespeichert ist) möglicherweise nicht gestartet werden. Dieses Risiko könnte durch das Importieren dieser Images in die Azure Container Registry der Umgebung abgemildert werden.
Beobachtbarkeit ist in dieser Architektur kritisch, da Stempel kurzlebig sind. Diagnoseeinstellungen sind so konfiguriert, dass alle Protokoll- und Metrikdaten in einem regionalen Log Analytics-Arbeitsbereich gespeichert werden. Außerdem werden AKS-Containererkenntnisse über einen clusterinternen OMS-Agent aktiviert. Dieser Agent ermöglicht es dem Cluster, Überwachungsdaten an den Log Analytics-Arbeitsbereich zu senden.
Weitere Überlegungen zum Computecluster finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Containerorchestrierung und Kubernetes.
Schlüsseltresor
Azure Key Vault wird verwendet, um globale Geheimnisse wie Verbindungszeichenfolgen mit der Datenbank und Stempelgeheimnisse wie die Event Hubs-Verbindungszeichenfolge zu speichern.
Diese Architektur verwendet einen Geheimnisspeicher-CSI-Treiber im Computecluster, um Geheimnisse aus Key Vault abzurufen. Geheimnisse sind erforderlich, wenn neue Pods erzeugt werden. Wenn Key Vault nicht verfügbar ist, werden neue Pods möglicherweise nicht gestartet. Dadurch kann es zu Unterbrechungen kommen, Skalierungsvorgänge können beeinträchtigt werden, Updates können fehlschlagen, neue Bereitstellungen können nicht ausgeführt werden.
Key Vault hat einen Grenzwert für die Anzahl von Vorgängen. Aufgrund der automatischen Aktualisierung von Geheimnissen kann der Grenzwert erreicht werden, wenn viele Pods vorhanden sind. Sie können sich entschließen, die Häufigkeit der Updates zu verringern, um diese Situation zu vermeiden.
Weitere Überlegungen zur Verwaltung von Geheimnissen finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Schutz der Datenintegrität.
Event Hubs
Der einzige zustandsbehaftete Dienst im Stempel ist der Nachrichtenbroker „Azure Event Hubs“, der Anforderungen für einen kurzen Zeitraum speichert. Der Broker bedient den Bedarf für Pufferung und zuverlässiges Messaging. Die verarbeiteten Anforderungen werden persistent in der globalen Datenbank gespeichert.
In dieser Architektur wird die Standard-SKU verwendet, und die Zonenredundanz ist für Hochverfügbarkeit aktiviert.
Die Integrität von Event Hubs wird von der HealthService-Komponente überprüft, die auf dem Computecluster ausgeführt wird. Sie führt regelmäßige Überprüfungen verschiedener Ressourcen aus. Dies ist nützlich, um fehlerhafte Zustände zu erkennen. Wenn z. B. Nachrichten nicht an den Event Hub gesendet werden können, wäre der Stempel für alle Schreibvorgänge nicht nutzbar. HealthService sollte diesen Zustand automatisch erkennen und diesen fehlerhaften Zustand an Front Door melden, das den Stempel dann aus der Rotation herausnimmt.
Für Skalierbarkeit wird automatische Vergrößerung empfohlen.
Weitere Informationen finden Sie unter Messagingdienste für unternehmenskritische Workloads.
Weitere Überlegungen zum Messaging finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Asynchrones Messaging.
Speicherkonten
In dieser Architektur sind zwei Speicherkonten bereitgestellt. Beide Konten sind im zonenredundanten Modus (ZRS, zonenredundanter Speicher) bereitgestellt.
Ein Konto wird für Event Hubs-Prüfpunkte verwendet. Wenn dieses Konto nicht reagiert, kann der Stempel keine Nachrichten von Event Hubs verarbeiten und beeinträchtigt möglicherweise sogar andere Dienste im Stempel. Dieser Zustand wird regelmäßig vom HealthService überprüft, bei dem es sich um eine der Anwendungskomponenten handelt, die im Computecluster ausgeführt werden.
Das andere Konto wird verwendet, um die Benutzeroberflächen-Single-Page-Webanwendung zu hosten. Wenn es beim Bedienen der statischen Website Probleme gibt, erkennt Front Door das Problem und sendet keinen Datenverkehr an dieses Speicherkonto. Während dieser Zeit kann Front Door zwischengespeicherte Inhalte verwenden.
Weitere Informationen zur Wiederherstellung finden Sie unter Notfallwiederherstellung und Speicherkontofailover.
Regionale Ressourcen
Ein System kann über Ressourcen verfügen, die in der Region bereitgestellt sind, die Stempelressourcen aber „überleben“. In dieser Architektur werden Beobachtbarkeitsdaten von Stempelressourcen in regionalen Datenspeichern gespeichert.
| Merkmale | Aspekt |
|---|---|
| Lebensdauer | Die Ressourcen haben dieselbe Lebensdauer wie die Region und eine längere als die der Stempelressourcen. |
| State | Der in einer Region gespeicherte Zustand kann nicht über die Lebensdauer der Region hinaus erhalten bleiben. Wenn der Zustand regionsübergreifend geteilt werden muss, sollten Sie einen globalen Datenspeicher verwenden. |
| Reach | Die Ressourcen müssen nicht global verteilt sein. Direkte Kommunikation mit anderen Regionen sollte unter allen Umständen vermieden werden. |
| Abhängigkeiten | Die Ressourcen können Abhängigkeiten von globalen Ressourcen haben, aber nicht von Stempelressourcen, da Stempel als kurzlebig konzipiert sind. |
| Skalierungslimits | Bestimmen Sie die Skalierungslimits der regionalen Ressourcen, indem Sie alle Stempel innerhalb der Region kombinieren. |
Überwachen von Daten für Stempelressourcen
Die Bereitstellung von Überwachungsressourcen ist ein typisches Beispiel für regionale Ressourcen. In dieser Architektur verfügt jede Region über einen einzelnen Log Analytics-Arbeitsbereich, der so konfiguriert ist, dass er alle Protokoll- und Metrikdaten speichert, die von Stempelressourcen ausgegeben werden. Da regionale Ressourcen die Stempelressourcen „überleben“, stehen Daten auch dann noch zur Verfügung, nachdem der Stempel gelöscht wurde.
Azure Log Analytics und Azure Application Insights werden verwendet, um Protokolle und Metriken von der Plattform zu speichern. Es wird empfohlen, das tägliche Kontingent für Speicher zu begrenzen, insbesondere in Umgebungen, die für Auslastungstest verwendet werden. Legen Sie außerdem eine Aufbewahrungsrichtlinie fest, um alle Daten zu speichern. Diese Einschränkungen verhindern Ausgabenüberschreitungen, die durch die grenzwertüberschreitende Speicherung von Daten verursacht werden, die nicht benötigt werden.
Ähnlich wird auch Application Insights als regionale Ressource bereitgestellt, um alle Anwendungsüberwachungsdaten zu sammeln.
Entwurfsempfehlungen für die Überwachung finden Sie unter Unternehmenskritische Anleitungen im Well-Architected Framework: Integritätsmodellierung.
Nächste Schritte
Stellen Sie die Referenzimplementierung bereit, um ein umfassendes Verständnis der Ressourcen und ihrer Konfiguration in dieser Architektur zu erhalten.