Lösungsmöglichkeiten
In diesem Artikel ist ein Lösungsvorschlag beschrieben. Ihr Cloudarchitekt kann diesen Leitfaden verwenden, um die Hauptkomponenten einer typischen Implementierung dieser Architektur zu visualisieren. Verwenden Sie diesen Artikel als Ausgangspunkt, um eine gut durchdachte Lösung zu entwerfen, die den spezifischen Anforderungen Ihrer Workload entspricht.
Implementieren einer benutzerdefinierten Lösung für die Verarbeitung natürlicher Sprachen (NLP) in Azure. Verwenden Sie Spark NLP für Aufgaben wie Themen- und Stimmungserkennung und -analyse.
Apache®, Apache Spark und das Flammenlogo sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den USA und/oder anderen Ländern. Die Verwendung dieser Markierungen impliziert kein Endorsement durch die Apache Software Foundation.
Aufbau

Laden Sie eine Visio-Datei dieser Architektur herunter.
Workflow
- Azure Event Hubs, Azure Data Factory oder beide Dienste empfangen Dokumente oder unstrukturierte Textdaten.
- Event Hubs und Data Factory speichern die Daten im Dateiformat in Azure Data Lake Storage. Es wird empfohlen, eine Verzeichnisstruktur einzurichten, die den Geschäftsanforderungen entspricht.
- Die Azure Computer Vision-API verwendet ihre Funktion für die optische Zeichenerkennung (OCR), um die Daten zu nutzen. Die API schreibt dann die Daten in die Bronzeschicht. Diese Verbrauchsplattform verwendet eine Lakehouse-Architektur.
- In der Bronzeschicht verarbeiten verschiedene Spark NLP-Features den Text vor. Beispiele sind Aufteilung, Rechtschreibprüfung, Reinigung und Verständnis der Grammatik. Es wird empfohlen, die Dokumentklassifizierung auf der Bronzeschicht auszuführen und dann die Ergebnisse in die Silberschicht zu schreiben.
- In der Silberschicht führen erweiterte Spark NLP-Features Dokumentanalyseaufgaben wie Erkennung benannter Entitäten, Zusammenfassung und Informationsabruf aus. In einigen Architekturen wird das Ergebnis in die Goldschicht geschrieben.
- In der Goldschicht führt Spark NLP verschiedene sprachliche visuelle Analysen auf den Textdaten aus. Diese Analysen bieten Einblicke in Sprachabhängigkeiten und helfen bei der Visualisierung von NER-Bezeichnungen.
- Benutzer fragen die Textdaten der Goldschicht als Datenrahmen ab und zeigen die Ergebnisse in Power BI oder Web-Apps an.
Während der Verarbeitungsschritte werden Azure Databricks, Azure Synapse Analytics und Azure HDInsight mit Spark NLP verwendet, um NLP-Funktionen bereitzustellen.
Komponenten
- Data Lake Storage ist ein Hadoop-kompatibles Dateisystem, das über einen integrierten hierarchischen Namespace und die massive Skalierung und Wirtschaft von Azure Blob Storage verfügt.
- Azure Synapse Analytics ist ein Analysedienst für Data Warehouses und Big-Data-Systeme.
- Azure Databricks ist ein Analysedienst für Big Data, der einfach zu verwenden ist, die Zusammenarbeit vereinfacht und auf Apache Spark basiert. Azure Databricks ist für Data Science und Datentechnik konzipiert.
- Event Hubs erfasst Datenströme, die Clientanwendungen generieren. Event Hubs speichert die Streamingdaten und behält die Sequenz der empfangenen Ereignisse bei. Consumer können eine Verbindung mit Hubendpunkten herstellen, um Nachrichten zur Verarbeitung abzurufen. Event Hubs werden in Data Lake Storage integriert, wie diese Lösung zeigt.
- Azure HDInsight ist ein umfassender, verwalteter Open-Source-Analysedienst in der Cloud für Unternehmen. Sie können Open Source-Frameworks mit Azure HDInsight, z. B. Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm, R und HDInsight verwenden.
- Data Factory verschiebt automatisch Daten zwischen Speicherkonten unterschiedlicher Sicherheitsebenen, um die Aufgabentrennung sicherzustellen.
- Maschinelles Sehen verwendet Texterkennungs-APIs, um Textinformationen in Bildern zu erkennen und diese Informationen zu extrahieren. Die Lese-API verwendet die neuesten Erkennungsmodelle und ist für große, textintensive Dokumente und umfangreiche Bilder optimiert. Die OCR-API ist nicht für große Dokumente optimiert, unterstützt jedoch mehr Sprachen als die Lese-API. Diese Lösung nutzt OCR, um Daten im hOCR-Format zu erstellen.
Szenariodetails
Die Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) hat viele Verwendungen: Standpunktanalyse, Textgegenstandserkennung, Sprachenerkennung, Schlüsselbegriffserkennung und Dokumentkategorisierung.
Apache Spark ist ein Framework für die Parallelverarbeitung, das In-Memory-Verarbeitung unterstützt, um die Leistung von Big Data-Analyseanwendungen, z. B. NLP, zu steigern. Azure Synapse Analytics, Azure HDInsight und Azure Databricks bieten Zugriff auf Spark und nutzen seine Verarbeitungsleistung.
Für angepasste NLP-Workloads dient Open-Source-Bibliothek Spark NLP als effizientes Framework für die Verarbeitung einer großen Textmenge. In diesem Artikel wird eine Lösung für umfangreiche benutzerdefinierte NLP in Azure vorgestellt. Die Lösung verwendet Spark NLP-Features, um Text zu verarbeiten und zu analysieren. Weitere Informationen zu Spark NLP finden Sie weiter unten in diesem Artikel unter Spark NLP-Funktionen und -Pipelines.
Mögliche Anwendungsfälle
Dokumentklassifizierung: Spark NLP bietet mehrere Optionen für die Textklassifizierung:
- Textvorverarbeitung in Spark NLP und Machine-Learning-Algorithmen, die auf Spark ML basieren
- Textvorverarbeitung und Worteinbettung in Spark NLP- und Machine-Learning-Algorithmen wie GloVe, BERT und ELMo
- Textvorverarbeitung und Satzeinbettung in Spark NLP- und Machine-Learning-Algorithmen und Modelle wie den Universal Sentence Encoder
- Textvorverarbeitung und Klassifizierung in Spark NLP, die den KlassifiziererDL-Annotator verwendet und auf TensorFlow basiert
Namensentitätsextraktion (NER):In Spark NLP können Sie mit wenigen Codezeilen ein NER-Modell trainieren, das BERT verwendet, und Sie können modernste Genauigkeit erzielen. NER ist eine Teilaufgabe der Informationsextraktion. NER sucht benannte Entitäten im unstrukturierten Text und klassifiziert sie in vordefinierte Kategorien wie Personennamen, Organisationen, Standorte, medizinische Codes, Zeitausdrücke, Mengen, Geldwerte und Prozentwerte. Spark NLP verwendet ein modernes NER-Modell mit BERT. Das Modell ist von einem ehemaligen NER-Modell inspiriert, bidirektionales LSTM-CNN. Dieses ehemalige Modell verwendet eine neuartige neuronale Netzwerkarchitektur, die automatisch Funktionen auf Wortebene und Zeichenebene erkennt. Für diesen Zweck verwendet das Modell eine hybride bidirektionale LSTM- und CNN-Architektur, sodass es die Notwendigkeit für die meisten Feature-Engineering-Funktionen beseitigt.
Stimmungs- und Gefühlserkennung: Spark NLP kann automatisch positive, negative und neutrale Aspekte der Sprache erkennen.
Teil der Sprachausgabe (POS): Diese Funktionalität weist jedem Token im Eingabetext eine grammatikalische Bezeichnung zu.
Satzerkennung (SD): SD basiert auf einem allgemeinen neuronalen Netzwerkmodell für die Satzgrenzenerkennung, das Sätze innerhalb von Text identifiziert. Viele NLP-Aufgaben nehmen einen Satz als Eingabeeinheit. Beispiele für diese Aufgaben sind POS-Tagging, Abhängigkeitsanalyse, Erkennnung benannter Entitäten und maschinelle Übersetzung.
Spark NLP-Funktionen und Pipelines
Spark NLP bietet Python-, Java- und Scala-Bibliotheken, die die vollständige Funktionalität herkömmlicher NLP-Bibliotheken wie spaCy, NLTK, Stanford CoreNLP und Open NLP bieten. Spark NLP bietet auch Funktionen wie Rechtschreibprüfung, Stimmungsanalyse und Dokumentklassifizierung. Spark NLP verbessert die vorherigen Bemühungen, indem es die modernste Genauigkeit, Geschwindigkeit und Skalierbarkeit bietet.
Spark NLP ist die mit Abstand schnellste Open-Source-NLP-Bibliothek. Aktuelle öffentliche Benchmarks zeigen Spark NLP als 38 und 80 Mal schneller als spaCy – mit vergleichbarer Genauigkeit für das Training benutzerdefinierter Modelle. Spark NLP ist die einzige Open-Source-Bibliothek, die einen verteilten Spark-Cluster verwenden kann. Spark NLP ist eine native Erweiterung von Spark ML, die direkt auf Datenframes funktioniert. Infolgedessen führt die Beschleunigungen bei einem Cluster zu einer anderen Reihenfolge der Leistungsgewinne. Da jede Spark NLP-Pipeline eine Spark ML Pipeline ist, eignet sich Spark NLP gut für die Erstellung einheitlicher NLP- und Machine Learning-Pipelines wie Dokumentklassifizierung, Risikovorhersage und Empfehlungspipelinen.
Neben hervorragender Leistung bietet Spark NLP auch modernste Genauigkeit für eine wachsende Anzahl von NLP-Aufgaben. Das Spark NLP-Team liest regelmäßig die neuesten relevanten akademischen Dokumente und produziert die genauesten Modelle.
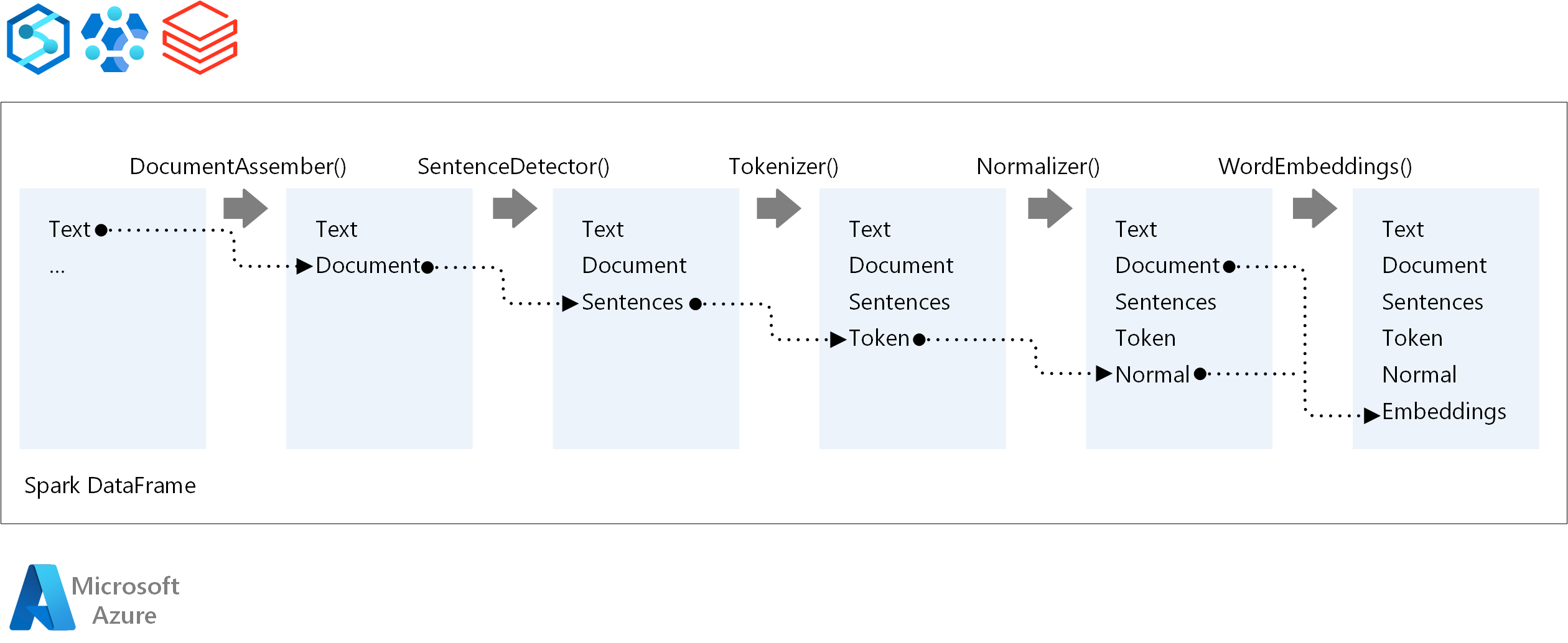
Für die Ausführungsreihenfolge einer NLP-Pipeline folgt Spark NLP demselben Entwicklungskonzept wie herkömmliche Spark Machine Learning-Modelle. Spark NLP wendet jedoch NLP-Techniken an. Das folgende Diagramm zeigt die Kernkomponenten einer Spark NLP-Pipeline.
Beitragende
Dieser Artikel wird von Microsoft gepflegt. Er wurde ursprünglich von folgenden Mitwirkenden geschrieben:
Hauptautor:
- Moritz Steller | Senior Cloud Solution Architect
Nächste Schritte
Spark NLP-Dokumentation:
Azure-Komponenten: