Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Verarbeitung natürlicher Sprachen umfasst Techniken, die menschliche Sprache aus Textdaten analysieren, verstehen und generieren. Azure bietet verwaltete API-gesteuerte Dienste und verteilte Open-Source-Frameworks, die Arbeitslasten für die Verarbeitung natürlicher Sprachen adressieren, die von der Stimmungsanalyse und Entitätserkennung bis hin zur Dokumentklassifizierung und Textzusammenfassung reichen. In diesem Leitfaden können Sie die wichtigsten Verarbeitungsoptionen für natürliche Sprachen auf Azure auswerten und auswählen, damit Sie die richtige Technologie an Ihre Workloadanforderungen anpassen können.
Hinweis
Dieser Leitfaden konzentriert sich auf funktionen für die Verarbeitung natürlicher Sprachen, die über Azure Language und Apache Spark mit Spark NLP auf Azure Databricks oder Microsoft Fabric verfügbar sind. Es bietet keine Anleitung zum Auswählen von Sprachmodellen oder zum Entwerfen von Azure OpenAI-Lösungen. Einige Plattformbeschreibungen verweisen möglicherweise auf unterstützte Foundation-Modell- oder Sprachmodellintegrationen als Implementierungsdetails, dieser Leitfaden konzentriert sich jedoch auf die Auswahl natürlicher Sprachverarbeitungsdienste. Weitere Informationen finden Sie unter Auswählen einer KI-Diensttechnologie.
Verstehen Sie die Verarbeitung natürlicher Sprache und Sprachmodelle
Bevor Sie Azure Dienste auswerten, verstehen, was die Verarbeitung natürlicher Sprachen ist, wie sie sich von Sprachmodellen unterscheidet und welche Aufgaben sie adressiert.
Unterscheiden der Verarbeitung natürlicher Sprachen von Sprachmodellen
In diesem Abschnitt wird die Grenze zwischen Verarbeitung natürlicher Sprache und Sprachmodellen erläutert, und es werden die Kernfunktionen untersucht, die die Verarbeitungstechniken der natürlichen Sprache ermöglichen.
| Abmessung | Verarbeitung natürlicher Sprache | Sprachmodelle |
|---|---|---|
| Geltungsbereich | Ein breites Feld, das verschiedene Textverarbeitungstechniken umfasst, einschließlich Tokenisierung, Stemming, Entitätserkennung, Stimmungsanalyse und Dokumentklassifizierung. | Eine Deep-Learning-Teilmenge der Verarbeitung natürlicher Sprachen konzentriert sich auf allgemeine Sprachverständnis- und Generierungsaufgaben. |
| Beispiele | Regelbasierte Parser, Begriffshäufigkeit-inverse Dokumenthäufigkeit (TF-IDF) Klassifizierer, Benannte Entitätserkennung, Stimmungsanalysatoren. | GPT-, BERT- und ähnliche transformatorbasierte Modelle, die menschenähnlichen, kontextbezogenen Text erzeugen. |
| Output | Strukturierte Signale wie Bezeichnungen, Bewertungen, extrahierte Spannen und analysierte Syntax. | Fließende natürliche Sprache wie generierter Text, Zusammenfassungen, Antworten und Vervollständigungen. |
| Beziehung | Die übergeordnete Domäne. Die Verarbeitung natürlicher Sprachen umfasst das gesamte Spektrum der Textverarbeitungsmethoden. | Ein Tool innerhalb der Verarbeitung natürlicher Sprachen. Sprachmodelle verbessern die Verarbeitung natürlicher Sprachen, ohne sie zu ersetzen. Sie behandeln umfassendere kognitive Aufgaben, sind aber nicht gleichbedeutend mit natürlicher Sprachverarbeitung. |
Verarbeitungsfunktionen für natürliche Sprachen
Klassifizieren Sie Dokumente, indem Sie sie als vertraulich oder spam kennzeichnen. Die Verarbeitung natürlicher Sprachen kategorisiert Dokumente automatisch basierend auf Inhalten, um Compliance- und Filterworkflows zu unterstützen.
Fassen Sie Text zusammen, indem Sie Entitäten im Dokument identifizieren. Die Verarbeitung natürlicher Sprachen extrahiert wichtige Entitäten, um präzise Zusammenfassungen zu erstellen, die die wichtigsten Informationen erfassen.
Markieren Sie Dokumente mit Schlüsselwörtern mithilfe von identifizierten Entitäten. Nachdem Sie Entitäten identifiziert haben, können Sie Stichworttags generieren, die die Dokumentorganisation vereinfachen. Verwenden Sie diese Tags für die inhaltsbasierte Suche und den Abruf.
Erkennung von Themen zur Navigation und zur Entdeckung verwandter Dokumente. Die Verarbeitung natürlicher Sprachen identifiziert wichtige Themen mithilfe extrahierter Entitäten, die Dokumentkategorisierung und themenbasierte Navigation unterstützen.
Bewerten sie die Textstimmung. Die Stimmungsanalyse wertet den emotionalen Textton aus und klassifiziert Inhalte als positiv, negativ oder neutral.
Ergebnisse der Verarbeitung natürlicher Sprache in nachgelagerte Arbeitsabläufe einspeisen. Ergebnisse wie extrahierte Entitäten, Stimmungsbewertungen und Themenbezeichnungen dienen als Eingaben für die Verarbeitung, Suchindizierung und Analyse.
Identifizieren potenzieller Anwendungsfälle
Geschäftsszenarien in vielen Branchen profitieren von Lösungen für die Verarbeitung natürlicher Sprachen. In den folgenden Anwendungsfällen wird gezeigt, wie techniken für die Verarbeitung natürlicher Sprachen den realen Herausforderungen gerecht werden, von der Verarbeitung unstrukturierter Dokumente bis hin zur Aktivierung neuer Anwendungen in Cybersicherheit und Barrierefreiheit.
Verarbeiten von Dokumenten und unstrukturiertem Text
Extrahieren Sie Intelligenz aus von computern erstellten Dokumenten. Die Verarbeitung natürlicher Sprachen ermöglicht die Dokumentverarbeitung über Finanz-, Gesundheits-, Einzelhandels-, Regierungs- und andere Sektoren hinweg. Sie können digital erstellte Dokumente analysieren, um strukturierte Informationen aus unstrukturierten Eingaben zu extrahieren. Verwenden Sie für handschriftliche Dokumente Azure Document Intelligence, um handschriftliche Inhalte in Text zu konvertieren, bevor Sie Techniken zur Verarbeitung natürlicher Sprachen anwenden.
Wenden Sie branchenunabhängige Verarbeitungsaufgaben für natürliche Sprachen für die Textverarbeitung an. Benannte Entitätserkennung (NER), Klassifizierung, Zusammenfassung und Beziehungsextraktion helfen Ihnen dabei, unstrukturierte Dokumentinhalte automatisch zu verarbeiten und zu analysieren. Diese Aufgaben funktionieren über Domänen hinweg und erfordern keine branchenspezifische Anpassung.
Erstellen Sie domänenspezifische Modelle für eine spezielle Analyse. Beispiele für diese Aufgaben sind Risikoschichtmodelle für das Gesundheitswesen, die Ontologieklassifizierung für das Wissensmanagement und Verkaufszusammenfassungen für Produkt- und Kundendaten. Benutzerdefinierte Modellschulungen in Azure Language und Spark NLP tragen zur Verbesserung der Genauigkeit für diese domänenspezifischen Dokumentformate bei.
Generieren Sie automatisierte Berichte aus strukturierten Dateneingaben. Sie können umfassende Textberichte aus strukturierten Daten synthetisieren und generieren. Diese Funktion hilft Sektoren wie Finanzen und Compliance, die eine gründliche Dokumentation erfordern.
Aktivieren von Such-, Übersetzungs- und Analysefunktionen
Erstellen Sie Wissensdiagramme, und aktivieren Sie die semantische Suche über den Informationsabruf. Die Verarbeitung natürlicher Sprachen unterstützt die Erstellung von Wissensdiagrammen und die semantische Suche, sodass Systeme die Bedeutung von Abfragen interpretieren können, anstatt nur auf den Schlüsselwortabgleich zu vertrauen.
Unterstützen Sie die Arzneimittelermittlung und klinische Studien mit medizinischen Wissensdiagrammen. Systeme zur Verarbeitung natürlicher Sprachen analysieren klinischen Text. Medizinische Wissensdiagramme, die aus diesem Text erstellt wurden, unterstützen Pipelines zur Erkennung von Medikamenten und klinischen Studienabgleich. Diese Diagramme verbinden Entitäten wie Drogen, Bedingungen und Ergebnisse, um Forschungsworkflows zu beschleunigen. Text analytics for health in Azure Language extrahiert medizinische Entitäten, Beziehungen und Assertionen, mit denen Sie diese Diagramme erstellen können.
Übersetzen Sie Text für konversationelle KI in kundenorientierten Anwendungen. Textübersetzung ermöglicht konversationelle KI in mehreren Branchen. Sie können mehrsprachige kundenorientierte Anwendungen erstellen, die die bevorzugte Sprache des Benutzers verarbeiten und beantworten. Spark NLP bietet Übersetzungsfunktionen direkt. Verwenden Sie auf Azure Azure Translator, bei dem es sich um einen separaten Dienst von Azure Sprache handelt.
Analysieren Sie Stimmung und emotionale Intelligenz für die Markenwahrnehmung. Die Stimmungsanalyse hilft Ihnen, die Markenwahrnehmung zu überwachen und Kundenfeedback zu analysieren, indem positive, negative und nuancenierte emotionale Signale aus Text angezeigt werden.
Erweitern der Verarbeitung natürlicher Sprachen auf neue Domänen
Erstellen Sie sprachaktive Schnittstellen für Internet of Things (IoT) und intelligente Geräte. Die Verarbeitung natürlicher Sprachen verarbeitet die Textausgabe von Spracherkennungssystemen, um die Benutzerabsicht zu verstehen und die Bedeutung in IoT- und Smart Device-Szenarien zu extrahieren. Sprachaktivierungsszenarien erfordern Azure Speech für die Sprach-zu-Text-Konvertierung vor der Verarbeitung der natürlichen Sprache.
Passen Sie die Sprachausgabe mithilfe von adaptiven Sprachmodellen dynamisch an. Adaptive Sprachmodelle passen die Sprachausgabe dynamisch an verschiedene Benutzergruppenverständnisebenen an, die die Bereitstellung und Barrierefreiheit von Bildungsinhalten unterstützen.
Erkennung von Phishing und Falschinformationen durch Textanalyse zur Cybersicherheit. Die Verarbeitung natürlicher Sprachen analysiert Kommunikationsmuster und Sprachverwendung in Echtzeit, um potenzielle Sicherheitsbedrohungen in der digitalen Kommunikation zu identifizieren. Diese Analyse hilft bei der Erkennung von Phishingversuchen und Falschinformationskampagnen.
Sprachdienst in Azure bewerten
Azure Language ist ein cloudbasierter Dienst, der Funktionen für die Verarbeitung natürlicher Sprachen zum Verständnis und Analysieren von Text bereitstellt. Sie können auf das Foundry-Portal, REST-APIs und Clientbibliotheken für Python, C#, Java und JavaScript zugreifen, ohne eine Infrastruktur zu verwalten. Für die KI-Agent-Entwicklung können Sie auch über den Azure Language Model Context Protocol (MCP)-Server auf diese Funktionen zugreifen. Sie können darauf sowohl im Microsoft Foundry-Toolkatalog als Remoteserver zugreifen, als auch als lokaler selbstgehosteter Server verwenden.
Vordefinierte Features
Vordefinierte Features erfordern keine Modellschulung und sind einsatzbereit:
NER: Identifiziert und kategorisiert Entitäten im Text in vordefinierte Typen wie Personen, Organisationen, Speicherorte und Datumsangaben.
PII-Erkennung: Identifiziert und redagiert persönlich identifizierbare Informationen (PII), einschließlich vertraulicher personenbezogener und gesundheitsbezogener Daten, in Text- und transkribierten Unterhaltungen.
Spracherkennung: Erkennt die Sprache eines Dokuments in einer Vielzahl von Sprachen und Dialekten.
Stimmungsanalyse und Meinungs-Mining: Identifiziert positive, negative oder neutrale Stimmungen in Text und verknüpft Meinungen mit bestimmten Elementen wie Produktattributen oder Dienstaspekten.
Schlüsselauszugsextraktion: Wertet unstrukturierten Text aus und gibt eine Liste der Hauptkonzepte und Schlüsselbegriffe zurück.
Zusammenfassung: Komprimiert Dokumente und Unterhaltungen mithilfe von extraktiven oder abstrahiven Ansätzen, die Text-, Chat- und Call Center-Zusammenfassungen unterstützen.
Textanalyse für Gesundheit: Extrahiert und kennzeichnet relevante Gesundheitsinformationen aus unstrukturiertem klinischem Text, einschließlich medizinischer Entitäten, Beziehungen und Aussagen.
Trainieren von benutzerdefinierten Modellen
Sie können anpassbare Features verwenden, um Modelle für Ihre Daten zu trainieren, um domänenspezifische Verarbeitungsaufgaben für natürliche Sprachen zu verarbeiten:
- Benutzerdefinierte benannte Entitätserkennung (CNER): Erstellen Sie benutzerdefinierte Modelle, um domänenspezifische Entitätskategorien aus unstrukturiertem Text zu extrahieren. Verwenden Sie CNER, wenn vordefinierte NER-Kategorien Ihr Domänenvokabular nicht abdecken.
Azure Language MCP-Server und -Agents
Hinweis
Der Azure Language MCP-Server und sowohl das Intenterkennungs-Routing als auch die genauen Frage-Antwort-Agenten befinden sich im Vorschau-Status. Vorschau-Funktionen beinhalten keine Service-Level-Vereinbarung (Service Level Agreement, SLA), und wir empfehlen sie nicht für den Produktionseinsatz. Einige Features werden möglicherweise nicht unterstützt oder verfügen über eingeschränkte Funktionen. Weitere Informationen finden Sie unter Supplementale Nutzungsbedingungen für Microsoft Azure Vorschauen.
Azure Language bietet vorgefertigte Agents und flexible Bereitstellungsoptionen für Arbeitslasten für die Verarbeitung natürlicher Sprachen für die Produktion:
Absichtsrouting-Agent: Verwaltet Konversationsabläufe. Es versteht Benutzerabsichten und leitet präzise Antworten durch deterministische, auditierbare Logik weiter. Verwenden Sie diesen Agenten, wenn Sie transparentes, deterministisches Konversationsrouting benötigen.
Exakter Fragebeantwortungs-Agent: Bietet zuverlässige, wörtliche Antworten auf geschäftskritische Fragen, während gleichzeitig die menschliche Aufsicht und Qualitätskontrolle gewahrt bleiben. Verwenden Sie diesen Agent, wenn die Antwortgenauigkeit und Konsistenz unerlässlich sind.
Sie können über den Findry-Toolkatalog auf beide Agents zugreifen. Weitere Informationen finden Sie unter Azure Language MCP-Server und -Agents (Vorschau).
Der MCP-Server Azure Sprache unterstützt mehrere Bereitstellungsoptionen:
Remote-in der Cloud gehosteter MCP-Server: Der Foundry-Toolkatalog listet diesen Server auf. Der Server bietet cloudverwalteten Zugriff auf Azure Sprachfunktionen und erfordert keine lokale Infrastruktur.
Lokaler selbst gehosteter MCP-Server: Unterstützt lokale oder selbstverwaltete Bereitstellungen für Compliance-, Sicherheits- oder Datenhaltungsanforderungen.
Containerisierte Bereitstellung: Die folgenden Features unterstützen die containerisierte Bereitstellung für Szenarien, die lokale Verarbeitung oder luftgespaltene Umgebungen erfordern. Die vollständige Liste der verfügbaren Container und deren Verfügbarkeitsstatus finden Sie unter Azure KI-Containerunterstützung.
- Stimmungsanalyse
- Spracherkennung
- Schlüsselbegriffserkennung
- NER
- PII-Erkennung
- CNER
- Textanalyse für das Gesundheitswesen
- Zusammenfassung (Vorschau)
Evaluierung von Apache Spark mit Spark NLP
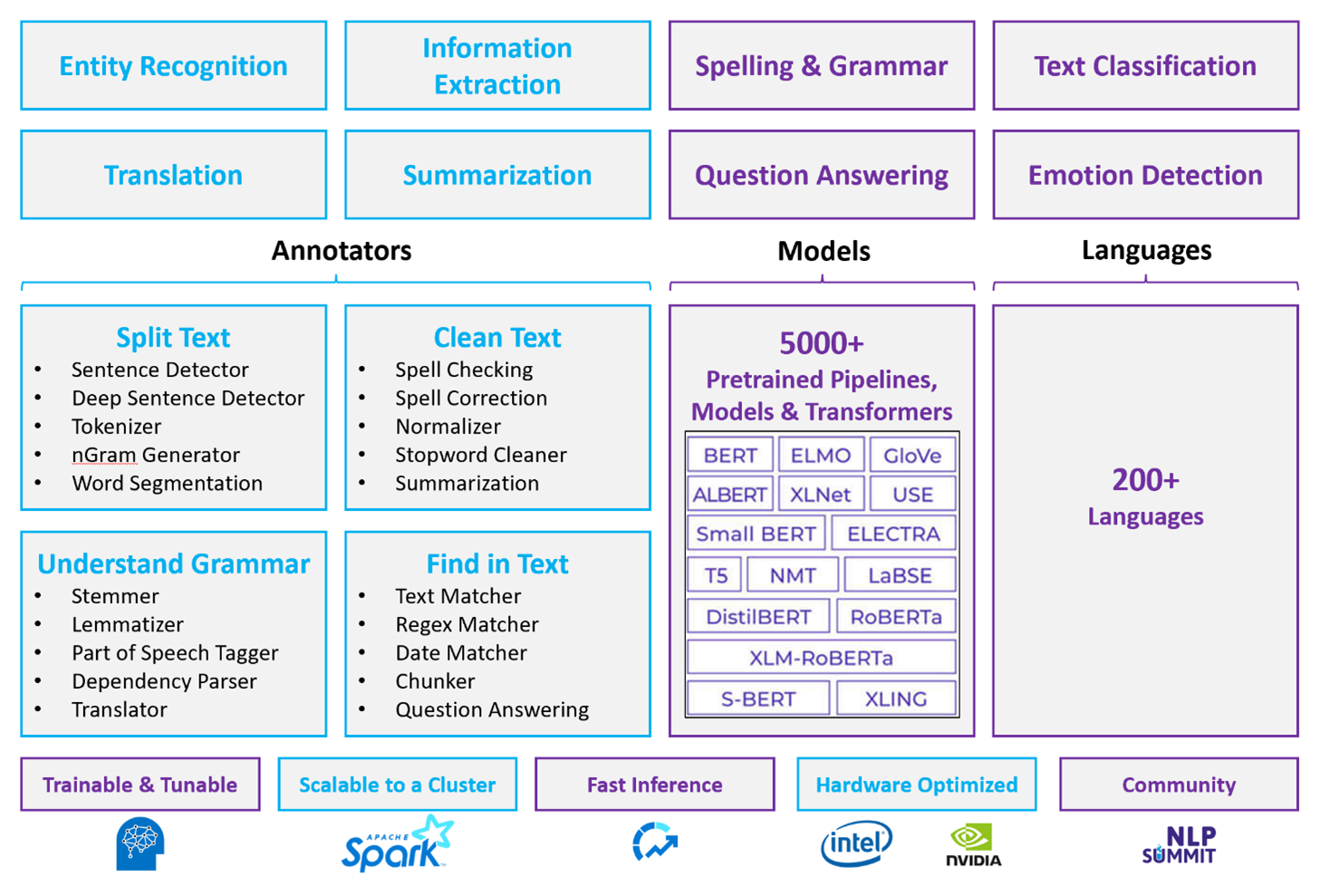
Apache Spark mit Spark NLP ist ein verteilter Open-Source-Ansatz für die Verarbeitung natürlicher Sprachen, die im Clustermaßstab ausgeführt wird. Die Spark NLP-Plattformarchitektur, -Leistung und das vordefinierte Modellökosystem machen sie zu einer starken Option für umfangreiche, anpassbare Workloads für die Verarbeitung natürlicher Sprachen auf Azure Databricks oder Fabric.
Grundlegendes zu Plattform und Architektur
Es wird empfohlen, Fabric oder Azure Databricks für Apache Spark-basierte Verarbeitungsworkloads für natürliche Sprachen zu verwenden.
Apache Spark bietet parallele Speicherverarbeitung für Big Data Analytics. Fabric und Azure Databricks bieten Ihnen Zugriff auf Apache Spark-Verarbeitungsfunktionen für umfangreiche Verarbeitungsworkloads in natürlicher Sprache.
Spark NLP fungiert als native Erweiterung von Spark ML für Datenframes. Diese Integration ermöglicht die einheitliche Verarbeitung natürlicher Sprachen und maschinelle Lernpipelinen mit verbesserter Leistung auf verteilten Clustern.
Spark NLP ist eine Open-Source-Bibliothek mit Python-, Java- und Scala-Unterstützung. Die Bibliothek bietet Funktionen, die mit spaCy und Natural Language Toolkit (NLTK) vergleichbar sind, einschließlich Rechtschreibprüfung, Stimmungsanalyse und Dokumentklassifizierung.

Apache®, Apache Spark und das Flammenlogo sind entweder eingetragene Marken oder Marken der Apache Software Foundation in den United States und/oder anderen Ländern. Es wird nicht impliziert, dass eine Unterstützung der Apache Software Foundation vorliegt, wenn diese Marken verwendet werden.
Die Leistung und Skalierbarkeit bewerten
Öffentliche Benchmarks zeigen erhebliche Geschwindigkeitsverbesserungen gegenüber anderen Verarbeitungsbibliotheken für natürliche Sprachen. Im Vergleich zu Frameworks wie spaCy und NLTK zeigt Spark NLP schnellere Schulungen und Rückschlüsse auf verteilte Cluster. Benutzerdefinierte Modelle, die von Spark NLP trainiert werden, erreichen Genauigkeitsstufen, die mit denen anderer Frameworks für die Verarbeitung natürlicher Sprache übereinstimmen, was sie für Produktions-Workloads geeignet macht, die auf Geschwindigkeit und Präzision angewiesen sind.
Optimierte Builds für CPUs, GPUs und Intel Xeon-Chips verwenden Apache Spark-Cluster vollständig. Diese Builds ermöglichen Schulungen und Schlussfolgerungen, um effizient über Clusterknoten hinweg zu skalieren.
MPNet-Einbettungen und ONNX-Unterstützung ermöglichen eine präzise, kontextabhängige Verarbeitung. MPNet erzeugt dichte Vektordarstellungen, die die semantische Bedeutung erfassen, und DIE ONNX-Unterstützung ermöglicht es Ihnen, optimierte Modelle für die Ableitung zu importieren und auszuführen.
Verwenden vordefinierter Modelle und Pipelines
Vorgefertigte Deep Learning-Modelle behandeln NER, Dokumentklassifizierung und Stimmungserkennung. Die Bibliothek verfügt über vorgefertigte Deep Learning-Modelle.
Vortrainierte Sprachmodelle unterstützen Wort-, Block-, Satz- und Dokumenteinbettungen. Die Bibliothek enthält vortrainierte Sprachmodelle, die Wort-, Segment-, Satz- und Dokumenteinbettungsebenen unterstützen. Diese Einbettungen stellen dichte Vektordarstellungen bereit, die nachgelagerte Aufgaben wie Ähnlichkeitssuche und Klassifizierung ermöglichen.
Einheitliche Verarbeitungs- und Machine Learning-Pipelines unterstützen Dokumentklassifizierung und Risikovorhersage. Die Integration in Spark ML unterstützt einheitliche Verarbeitungs- und Machine Learning-Pipelines für Aufgaben wie Dokumentklassifizierung und Risikovorhersage. Mit diesem einheitlichen Ansatz können Sie die Textverarbeitung mit herkömmlichen Machine Learning-Modellen in einer einzigen Pipeline kombinieren, wodurch die Architekturkomplexität reduziert wird.
Behandeln allgemeiner Herausforderungen bei der Verarbeitung natürlicher Sprachen
Sowohl Azure Language als auch Apache Spark mit Spark NLP stehen vor gemeinsamen Herausforderungen in der groß angelegten Verarbeitung natürlicher Sprache. Wenn Sie diese Herausforderungen verstehen, können Sie Ressourcen planen, Pipelines entwerfen und Genauigkeitserwartungen festlegen, bevor Sie sich für eine der beiden Optionen verpflichten.
Ressourcenverarbeitung
Die Verarbeitung von Freiformtext erfordert erhebliche Rechenressourcen und -zeit. Freiform-Textdokumente sind rechenaufwendig und zeitaufwendig zu analysieren. Jedes Dokument erfordert Tokenisierung, Normalisierung und Modellinferenz, bevor es verwendbare Ergebnisse erzeugt.
Spark NLP-Workloads erfordern häufig eine GPU-Computebereitstellung. Für große Spark NLP-Pipelines bieten GPU-beschleunigte Cluster auf Azure Databricks oder Fabric die parallele Verarbeitungsleistung, die für Schulungen und Rückschlüsse erforderlich ist. Optimierungen wie die Quantisierung von Llama 3.x-Modell tragen dazu bei, den Speicherbedarf zu reduzieren und den Durchsatz für diese intensiven Aufgaben zu verbessern.
Azure Sprache erfordert Durchsatzplanung und Kontingentverwaltung. Der Dienst verarbeitet die Ressourcenverwaltung, aber api-Aufrufe mit hohem Volumen erfordern eine sorgfältige Durchsatzplanung. Überwachen Sie Ihre Anforderungsraten anhand von Dienstgrenzwerten und -ratenlimits, um Drosselung zu vermeiden und eine konsistente Verarbeitungsleistung sicherzustellen.
Dokumentstandardisierung
Reale Dokumente folgen selten einer konsistenten Struktur. Diese Inkonsistenz schafft Herausforderungen für Extraktionspipelinen und erfordert bewusste Strategien, um die Genauigkeit über alle Quellen hinweg aufrechtzuerhalten.
Inkonsistente Formate: Ohne ein standardisiertes Dokumentformat kann das Extrahieren bestimmter Fakten aus Freiformtext schwierig sein. Beispielsweise kann es eine Herausforderung sein, Rechnungsnummern und Datumsangaben aus verschiedenen Lieferanten zu extrahieren, da Feldlayouts, Etiketten und Formatierungen in verschiedenen Quellen variieren.
Custom model training: Wenn Sie benutzerdefinierte Modelle in Spark NLP und Azure Language trainieren, können Sie sich an domänenspezifische Dokumentformate anpassen. Wenn Sie sich an repräsentativen Beispielen Ihrer tatsächlichen Dokumente trainieren, können Sie die Extraktionsgenauigkeit für Felder, Entitäten und Muster verbessern, die vordefinierte Modelle nicht gut verarbeiten.
Datenvielfalt und Komplexität
Vielfältige Dokumentstrukturen und sprachliche Nuancen fügen Komplexität hinzu. Reale Textdaten sind in vielen Formaten, Schreibstilen und Sprachen enthalten. Für die Behandlung dieser Variationen sind Modelle erforderlich, die Mehrdeutigkeit, Slang, Abkürzungen und domänenspezifische Terminologie verarbeiten können, während die Genauigkeit beibehalten wird.
MPNet-Einbettungen in Spark NLP bieten ein verbessertes kontextbezogenes Verständnis. MPNet-Einbettungen erfassen kontextbezogene Beziehungen zwischen Wörtern und Ausdrücken, wodurch Spark NLP-Pipelines differenzierter Text effektiver verarbeiten können. Diese Einbettungen erzeugen dichte Vektordarstellungen, die die semantische Bedeutung über verschiedene Dokumentformate hinweg bewahren.
Benutzerdefinierte Modelle in Azure Sprache passen sich an domänenspezifische Textmuster an. Mit CNER können Sie Modelle auf Ihren eigenen bezeichneten Daten trainieren, um Muster zu erkennen, die für Ihre Domäne spezifisch sind. Dieser Ansatz verbessert die Zuverlässigkeit, indem das Modell gelehrt wird, Entitäten und Kategorien zu erkennen, die vorgefertigte Modelle übersehen.
Anwenden von Schlüsselauswahlkriterien
Verwenden Sie die folgenden Kriterien, um zu bestimmen, welche Azure Option für die Verarbeitung natürlicher Sprachen ihren Anforderungen am besten entspricht. Jedes Kriterium beschreibt ein Arbeitsauslastungsmerkmal und identifiziert den Dienst, der ihn adressiert.
Verwaltete Fähigkeiten zur Verarbeitung natürlicher Sprache: Verwenden Sie die Azure Language-APIs für die Erkennung von Entities, die Identifizierung von Intentionen, die Themenanalyse oder die Sentiment-Analyse. Diese Funktionen sind als verwaltete Dienste mit minimalem Setup verfügbar, und Sie müssen keine Infrastruktur bereitstellen oder verwalten.
Prebuilt- oder vortrainierte Modelle: Verwenden Sie Azure Language, wenn Sie vorgefertigte oder vortrainierte Modelle nutzen möchten, ohne die Infrastruktur zu verwalten. Dieser Ansatz passt zu kleinen bis mittleren Datasets und Standardaufgaben für die Verarbeitung natürlicher Sprachen, bei denen vordefinierte Modelle eine ausreichende Genauigkeit liefern. Es bietet automatische Skalierung, integrierte Sicherheit und Bezahlung pro Anruf ohne den Verwaltungsaufwand für Cluster.
Custom-Modellschulung für große Textdatensätze: Verwenden Sie Azure Databricks oder Fabric mit Spark NLP. Diese Plattformen bieten die Rechenleistung und Flexibilität, die Sie für umfangreiche Modellschulungen für große Text-Datasets benötigen. Sie können modelle auch über Spark NLP herunterladen, einschließlich Llama 3.x und MPNet.
Niedrigstufige Verarbeitungskomponenten für natürliche Sprache: Verwenden Sie Azure Databricks oder Fabric mit Spark NLP für Tokenisierung, Stemming, Lemmatisierung und TF-IDF. Alternativ können Sie eine Open-Source-Bibliothek wie spaCy oder NLTK verwenden. Azure Sprache in Foundry Tools verwendet die Tokenisierung intern als Teil der Modellpipeline, aber sie macht diese Schritte nicht als eigenständige, steuerbare APIs verfügbar.
Erstellen von Pipelines für die Verarbeitung natürlicher Sprachen mithilfe von Spark NLP
Spark NLP folgt dem gleichen Entwicklungsmuster wie herkömmliche Spark ML-Modelle, wenn Sie eine Pipeline für die Verarbeitung natürlicher Sprachen ausführen. Sie verwalten trainierte Modelle mithilfe von MLflow zum Nachverfolgen von Experimenten und zur Produktionsbereitstellung.

Zusammenstellen von Kernpipelinekomponenten
Eine Spark NLP-Pipeline verkettet Annotatoren in einer Sequenz. Jeder Annotator transformiert die Ausgabe der vorherigen Stufe und baut von Rohtext in semantische Vektoren auf.
DocumentAssembler ist der Einstiegspunkt für jede Spark NLP-Pipeline. Verwenden Sie
setCleanupMode, um optionale Textvorverarbeitungen anzuwenden, wie z. B. HTML-Tag-Entfernung oder Leerzeichennormalisierung, bevor nachfolgende Annotatoren ausgeführt werden.SentenceDetector identifiziert Satzbegrenzungen im zusammengesetzten Dokument. Je nach Pipelinekonfiguration gibt es die erkannten Sätze entweder als
Arrayin einer einzelnen Zeile oder als separate Zeilen zurück. Eine genaue Satzerkennung ist wichtig, da viele nachgeschaltete Annotatoren auf Satzebene funktionieren.Tokenizer teilt unformatierten Text in diskrete Token wie Wörter, Zahlen und Symbole auf. Wenn die Standardregeln für Ihre Domäne nicht ausreichend sind, fügen Sie benutzerdefinierte Regeln hinzu, um spezielle Vokabular, Silbentrennungsbegriffe oder domänenspezifische Muster zu behandeln.
Normalizer optimiert Token durch Anwenden regulärer Ausdrücke und Wörterbuchtransformationen. Es bereinigt Text, um das Rauschen vor dem Einbetten zu reduzieren. Sie können beispielsweise in Kleinbuchstaben umwandeln, benutzerdefinierte Wörterbuchzuordnungen anwenden oder Akzente entfernen, um die Terminologie zu standardisieren.
WordEmbeddings ordnet Token semantischen Vektoren für die kontextbezogene Verarbeitung zu. Jedes Token wird als dichter Vektor dargestellt, der seine Bedeutung relativ zu anderen Token erfasst. Nicht aufgelöste Token, die nicht im Einbettungsvokabular angezeigt werden, werden standardmäßig auf Nullvektoren festgelegt.
Verwalten von Modellen mithilfe von MLflow
Spark NLP verwendet Spark MLlib-Pipelines mit nativer MLflow-Unterstützung . Sie müssen keinen benutzerdefinierten Serialisierungs- oder Integrationscode schreiben.
MLflow verwaltet die Experimentnachverfolgung, Modellversionsverwaltung und Bereitstellung. Sie können Pipelineparameter, Metriken und Artefakte während der Schulungsläufe protokollieren. MLflow verfolgt jedes Experiment nach, sodass Sie Ergebnisse zwischen Iterationen vergleichen und erfolgreiche Konfigurationen reproduzieren können.
MLflow ist direkt in Azure Databricks und Fabric integriert. Auf Azure Databricks ist MLflow vorinstalliert und wird eng in den Arbeitsbereich integriert. Fabric bietet auch eine built-in MLflow-Erfahrung mit systemeigener Experimentverfolgung und autologging, sodass Sie MLflow nicht separat installieren müssen. Wenn Sie Spark NLP auf einer anderen Apache Spark-basierten Umgebung ausführen, können Sie MLflow separat installieren und konfigurieren, um Experimente mit einem Remoteverfolgungsserver nachzuverfolgen.
Verwenden Sie die MLflow-Modellregistrierung, um Modelle zur Produktion zu fördern und Governance aufrechtzuerhalten. Die Modellregistrierung bietet ein zentrales Repository zum Verwalten von Modellversionen in Ihren Pipelines für die Verarbeitung natürlicher Sprachen. In klassischen Bereitstellungen durchlaufen Übergangsmodelle Phasen wie beispielsweise Staging, Produktion und Archivierung. In Azure Databricks verwenden neuere Bereitstellungen Models im Unity-Katalog, wodurch feste Phasen durch benutzerdefinierte Aliase und Tags für eine flexiblere Lebenszyklusverwaltung ersetzt werden. Auf Fabric stellt der Arbeitsbereich eine eigene MLflow-basierte Modellregistrierung bereit.
Funktionsmatrix
In den folgenden Tabellen sind die wichtigsten Unterschiede in den Fähigkeiten zwischen Spark NLP auf Azure Databricks oder Fabric und Azure Language zusammengefasst.
Allgemeine Funktionen
| Fähigkeit | Spark NLP (Azure Databricks oder Fabric) | Azure Sprache |
|---|---|---|
| Vortrainierte Modelle als Service | Ja | Ja |
| REST-API | Ja | Ja |
| Programmierbarkeit | Python, Scala | Siehe unterstützte Programmiersprachen. |
| Unterstützt die Verarbeitung großer Datasets und großer Dokumente | Ja | Begrenzt 1 |
1.Azure Sprache verfügt über Grenzwerte für die Dokumentgröße pro Anforderung, die je nach Modus variieren. Synchrone Anforderungen unterstützen bis zu 5.120 Zeichen pro Dokument und asynchrone Anforderungen unterstützen bis zu 125.000 Zeichen pro Dokument. Beide Modi unterstützen bis zu 25 Dokumente pro API-Aufruf. Sie können große Datasetvolumes durch Batchverarbeitung und Paginierung verarbeiten, aber einzelne Dokumente, die den Zeichengrenzwert für den ausgewählten Modus überschreiten, erfordern Blöcke. Weitere Informationen finden Sie unter Daten und Ratelimits für Azure Sprache.
Annotatorfunktionen
| Fähigkeit | Spark NLP (Azure Databricks oder Fabric) | Azure Sprache |
|---|---|---|
| Satzerkennung | Ja | Nein |
| Tiefe Satzerkennung | Ja | Nein |
| Tokenisierer | Ja | Nur intern (nicht als eigenständige API verfügbar gemacht) |
| N-Gramm-Generator | Ja | Nein |
| Word Segmentierung | Ja | Ja |
| Wortstammerkennung | Ja | Nein |
| Lemmatisierung | Ja | Nein |
| Satzteilmarkierung | Ja | Nein |
| Abhängigkeitsparser | Ja | Nein |
| Übersetzung | Ja | Nein |
| Stoppwortbereinigung | Ja | Nein |
| Rechtschreibkorrektur | Ja | Nein |
| Normalisator | Ja | Ja |
| Textabgleich | Ja | Nein |
| TF-IDF | Ja | Nein |
| Abgleich regulärer Ausdrücke | Ja | Begrenzt |
| Datumsabgleich | Ja | Begrenzt |
| Chunker | Ja | Nein |
Hochentwickelte Verarbeitungsfunktionen für natürliche Sprache
| Fähigkeit | Spark NLP (Azure Databricks oder Fabric) | Azure Sprache |
|---|---|---|
| Rechtschreibprüfung | Ja | Nein |
| Zusammenfassung | Ja | Ja |
| Fragenbeantwortung | Ja | Ja |
| Stimmungserkennung | Ja | Ja |
| Emotionserkennung | Ja | Begrenzt 2 |
| Tokenklassifizierung | Ja | Begrenzt 3 |
| Textklassifizierung | Ja | Begrenzt 3 |
| Textdarstellung | Ja | Nein |
| NER | Ja | Ja (vorkonfiguriert). CNER ist über benutzerdefinierte Modelle verfügbar. 3 |
| Spracherkennung | Ja | Ja |
| Unterstützt andere Sprachen als Englisch | Ja. Siehe Spark NLP unterstützte Sprachen. | Ja. Siehe von Azure unterstützte Sprachen. |
2.Azure Language unterstützt das Meinungsmining, das Stimmungen identifiziert, die mit bestimmten Aspekten des Texts verknüpft sind, aber keine dedizierte Gefühlserkennung (z. B. Freude, Ärger oder Traurigkeitsklassifizierung) bereitstellt).
3.Verfügbarüber benutzerdefinierte Modelle. Sie trainieren CNER- oder benutzerdefinierte Entitätserkennungsmodelle in Ihren eigenen beschrifteten Daten.
Beitragende
Microsoft verwaltet diesen Artikel. Die folgenden Mitwirkenden haben diesen Artikel geschrieben.
Hauptautoren:
- Ananya Ghosh Chowdhury | Principal Cloud Solution Architect
- Kranthi Manchikanti | Senior AI Solutions Engineer
Andere Mitwirkende:
- Freddy Ayala | Cloud-Lösungsarchitekt
- Tincy Elis | Senior Cloud Solution Architect
- Moritz Steller | Senior Cloud Solution Architect
Um nicht öffentliche LinkedIn-Profile zu sehen, melden Sie sich bei LinkedIn an.
Nächste Schritte
- Einführung in KI in Azure
- Entwickeln von Lösungen für die Verarbeitung natürlicher Sprachen mithilfe von Foundry Tools
Verwandte Ressourcen
Azure Sprachdokumentation:
Spark NLP-Dokumentation:
Azure Komponenten:
Lernressourcen: