Serverlose Computingebene für Azure SQL-Datenbank
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
„Serverlos“ ist ein Computetarif für Einzeldatenbanken in Azure SQL-Datenbank, bei dem Computeressourcen basierend auf dem Workloadbedarf automatisch skaliert werden und die Nutzung dieser Ressourcen sekundengenau abrechnet wird. Wenn nur der verwendete Speicher in Rechnung gestellt wird, hält die serverlose Computeebene außerdem Datenbanken während inaktiver Zeiträume automatisch an und startet diese wieder, wenn es wieder zu Aktivität kommt. Die serverlose Computingebene ist in der Dienstebene Universell und in der Hyperscale-Dienstebene verfügbar.
Hinweis
Automatisches Anhalten und automatisches Fortsetzen wird derzeit nur in der Dienstebene „Universell“ unterstützt.
Übersicht
Ein automatischer Compute-Skalierungsbereich und eine Verzögerung des automatischen Anhaltens sind wichtige Parameter für die serverlose Computeebene. Die Konfiguration dieser Parameter beeinflusst die Leistung und die Computekosten der Datenbank.
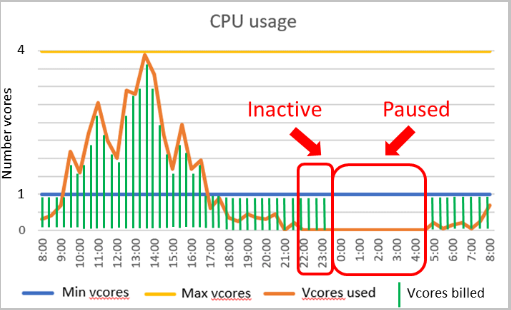
Leistungskonfiguration
- Die Mindestanzahl virtueller Kerne und die maximale Anzahl virtueller Kerne sind konfigurierbare Parameter, die den Bereich der Computekapazität definieren, die für die Datenbank verfügbar ist. Arbeitsspeicher- und E/A-Limits sind proportional zum angegebenen V-Kern-Bereich.
- Die Verzögerung durch automatisches Anhalten ist ein konfigurierbarer Parameter, der die Zeitspanne definiert, für die die Datenbank inaktiv sein muss, bevor sie automatisch pausiert wird. Bei der nächsten Anmeldung oder einer anderen Aktivität wird die Ausführung der Datenbank automatisch fortgesetzt. Alternativ kann das automatische Anhalten deaktiviert werden.
Kosten
- Die Kosten für eine serverlose Datenbank setzen sich aus der Summe der Computekosten und der Speicherkosten zusammen.
- Wenn die Computenutzung zwischen dem minimal und dem maximal konfigurierten Grenzwert liegt, basieren die Computekosten auf den verwendeten virtuellen Kernen und dem verwendeten Speicher.
- Wenn die Computenutzung unter dem minimal konfigurierten Grenzwert liegt, basieren die Computekosten auf der konfigurierten Mindestanzahl an virtuellen Kernen und Speicher.
- Wenn die Datenbank angehalten wird, fallen keine Computekosten an, und es wird nur der verwendete Speicher berechnet.
- Die Speicherkosten werden auf die gleiche Weise berechnet wie in der bereitgestellten Computeebene.
Weitere Informationen finden Sie unter Abrechnung.
Szenarien
Serverlos ist preis-/leistungsoptimiert für Einzeldatenbanken mit zeitweiligen, unvorhersehbaren Nutzungsmustern, bei denen eine gewisse Verzögerung in der Compute-Aufwärmphase nach Leerlaufzeiträumen ohne Nutzung akzeptabel ist. Die bereitgestellte Computeebene ist dagegen preis-/leistungsoptimiert für Einzeldatenbanken oder Datenbanken in Pools für elastische Datenbanken mit höherer durchschnittlicher Nutzung, bei denen eine Verzögerung in der Computeaufwärmphase nicht akzeptabel ist.
Ideal geeignete Szenarien für serverloses Computing
- Einzeldatenbanken mit wechselnden, unvorhersehbaren Nutzungsmustern, Perioden der Inaktivität und geringerer durchschnittlicher Computenutzung im Zeitverlauf.
- Einzeldatenbanken in der bereitgestellten Computeebene, die häufig neu skaliert werden, und Kunden, welche die Neuskalierung des Computings an den Dienst delegieren möchten.
- Neue Einzeldatenbanken ohne Nutzungsverlauf, bei denen das Schätzen der Computegröße vor der Bereitstellung in einer Azure SQL-Datenbank schwierig oder gar nicht möglich ist.
Ideal geeignete Szenarien für bereitgestelltes Computing
- Einzeldatenbanken mit regelmäßigeren, vorhersagbaren Nutzungsmustern und höherer durchschnittlicher Computenutzung im Zeitverlauf.
- Datenbanken, die keine Leistungskompromisse durch häufigeres Begrenzen des Speichers oder Verzögerung beim Fortsetzen aus dem angehaltenen Zustand tolerieren können.
- Mehrere Datenbanken mit wechselnden, unvorhersehbaren Nutzungsmustern, die für bessere Preis-/Leistungsoptimierung in Pools für elastische Datenbanken konsolidiert werden können.
Vergleichen von Computeebenen
Die folgende Tabelle enthält eine Zusammenfassung der Unterschiede zwischen der serverlosen Computeebene und der bereitgestellten Computeebene:
| Serverloses Computing | Bereitgestelltes Computing | |
|---|---|---|
| Datenbanknutzungsmuster | Wechselnde, unvorhersehbare Nutzung mit niedrigerer durchschnittlicher Computenutzung im Zeitverlauf. | Regelmäßigere Nutzungsmuster mit höherer durchschnittlicher Computenutzung im Zeitverlauf oder mehrere Datenbanken, die Pools für elastische Datenbanken verwenden. |
| Aufwand bei der Leistungsverwaltung | Geringer | Höher |
| Compute-Skalierung | Automatic | Manuell |
| Compute-Reaktionsfähigkeit | Geringer nach Inaktivitätszeiträumen | Unmittelbar |
| Granularität bei der Abrechnung | Pro Sekunde | Pro Stunde |
Kaufmodell und Dienstebene
In der folgenden Tabelle wird die serverlose Unterstützung basierend auf dem Kaufmodell, den Dienstebenen und der Hardware beschrieben:
| Kategorie | Unterstützt | Nicht unterstützt |
|---|---|---|
| Kaufmodell | Virtueller Kern | DTU |
| Dienstebene | Allgemeiner Zweck Hyperscale |
Unternehmenskritisch |
| Hardware | Standard-Serie (Gen5) | Gesamte andere Hardware |
Automatische Skalierung
Reaktionsfähigkeit hinsichtlich der Skalierung
Serverlose Datenbanken werden auf einem Computer mit ausreichender Kapazität zum unterbrechungsfreien Erfüllen des Ressourcenbedarfs für beliebige Volumen von angeforderten Computeressourcen innerhalb der Grenzen unterstützt, die durch den Wert für die maximale Anzahl virtueller Kerne festgelegt sind. Gelegentlich tritt automatisch ein Lastenausgleich auf, wenn der Computer den Ressourcenbedarf nicht innerhalb weniger Minuten erfüllen kann. Beispiel: Wenn vier virtuelle Kerne benötigt werden, aber nur zwei virtuelle Kerne verfügbar sind, dauert es unter Umständen einige Minuten, bis ein Lastausgleich vorgenommen wurde und vier virtuelle Kerne bereitgestellt werden. Die Datenbank bleibt während des Lastenausgleichs online, mit Ausnahme einer kurzen Zeitspanne am Schluss des Vorgangs, wenn Verbindungen verworfen werden.
Speicherverwaltung
Sowohl in den Dienstebenen „Universell“ als auch „Hyperscale“ wird Arbeitsspeicher für serverlose Datenbanken häufiger beansprucht als für bereitgestellte Computedatenbanken. Dieses Verhalten ist wichtig, um für serverlose Datenbanken die Kosten kontrollieren zu können, und es kann mit einer Beeinträchtigung der Leistung verbunden sein.
Freigabe von Cache
Im Gegensatz zu bereitgestellten Computedatenbanken wird der Speicher aus dem SQL-Cache von einer serverlosen Datenbank freigegeben, wenn eine geringe CPU-Auslastung vorliegt oder der Cache kaum aktiv genutzt wird.
- Die aktive Cachenutzung gilt als niedrig, wenn die Gesamtgröße der zuletzt verwendeten Cacheeinträge für einen bestimmten Zeitraum unter einen Schwellenwert fällt.
- Beim Auslösen der Cachefreigabe wird die Größe des Zielspeichers inkrementell auf einen Bruchteil der vorherigen Größe reduziert, und der Freigabevorgang wird nur fortgesetzt, wenn die Auslastung niedrig bleibt.
- Während der Cachefreigabe entspricht die Richtlinie für die Auswahl der zu entfernenden Cacheeinträge der Auswahlrichtlinie für bereitgestellte Computedatenbanken bei hoher Speicherauslastung.
- Der Cache wird niemals auf eine Größe verkleinert, die unter der Mindestgröße für den Arbeitsspeicher liegt. Dies wird über die Mindestanzahl von virtuellen Kernen definiert.
Sowohl in serverlosen als auch in bereitgestellten Computedatenbanken können Cacheeinträge entfernt werden, wenn der gesamte verfügbare Arbeitsspeicher verwendet wird.
Die aktive Cachenutzung kann je nach Verwendungsmuster trotz geringer CPU-Auslastung hoch bleiben und die Speicherfreigabe verhindern. Außerdem kann es nach Ende der Benutzeraktivität zu weiteren Verzögerungen kommen, bevor die Speicherfreigabe aufgrund von periodischen Hintergrundprozessen erfolgt, die auf vorherige Benutzeraktivitäten reagieren. Beispielsweise werden bei Löschvorgängen und Abfragespeicher-Bereinigungstasks inaktive Datensätze generiert, die zum Löschen markiert sind. Physisch werden sie jedoch erst gelöscht, wenn der Bereinigungsprozess inaktiver Datensätze ausgeführt wird. Die Bereinigung inaktiver Datensätze kann das Lesen der Datenseiten in den Cache umfassen.
Cachehydration
Der SQL-Cache wächst an, wenn Daten auf die gleiche Weise und mit der gleichen Geschwindigkeit wie für bereitgestellte Datenbanken vom Datenträger abgerufen werden. Wenn die Datenbank ausgelastet ist, kann die Größe des Caches uneingeschränkt zunehmen, solange Arbeitsspeicher verfügbar ist.
Verwaltung des Datenträgercaches
In der Hyperscale-Dienstebene für serverlose und bereitgestellte Computeebenen verwendet jedes Computereplikat einen RBPEX-Cache (Resilient Buffer Pool Extension), der Datenseiten auf einer lokalen SSD speichert, um die E/A-Leistung zu verbessern. In der serverlosen Computingebene für Hyperscale wächst und verkleinert sich der RBPEX-Cache für jedes Computereplikat jedoch automatisch als Reaktion auf zu- und abnehmende Workloadanforderungen. Die maximale Größe, auf die der RBPEX-Cache anwachsen kann, ist drei Mal so groß wie der für die Datenbank konfigurierte maximale Arbeitsspeicher. Ausführliche Informationen zu den Grenzwerten für maximale Arbeitsspeicher und RBPEX-Autoskalierung im serverlosen Modus finden Sie unter Serverlose Hyperscale-Ressourcenlimits.
AutoAnhalten und automatisches Fortsetzen
Derzeit werden serverloses automatisches Anhalten und automatisches Fortsetzen nur in der Dienstebene „Universell“ unterstützt.
Automatisches Anhalten
Automatisches Anhalten wird ausgelöst, wenn die folgenden Bedingungen für die Dauer der Verzögerung für automatisches Anhalten erfüllt sind:
- Anzahl von Sitzungen: 0
- CPU = 0 für Benutzerworkload im Benutzerressourcenpool
Es ist eine Option verfügbar, mit der AutoAnhalten ggf. deaktiviert werden kann.
Die folgenden Features unterstützen AutoAnhalten nicht, sondern nur automatische Skalierung. Bei Verwendung eines der folgenden Features muss AutoAnhalten deaktiviert werden, und die Datenbank bleibt online (ungeachtet der Dauer der Inaktivität der Datenbank):
- Georeplikation (aktive Georeplikation und Gruppen für automatisches Failover).
- Langzeitaufbewahrung von Sicherungen (LTR).
- In SQL-Datensynchronisierung verwendete Synchronisierungsdatenbank. Im Gegensatz zu Synchronisierungsdatenbanken unterstützen Hub-Datenbanken und Mitgliedsdatenbanken Auto-Anhalten.
- DNS-Alias, der für den logischen Server erstellt wurde, der eine serverlose Datenbank enthält.
- Elastische Aufträge Eine serverlose Datenbank, die AutoAnhalten unterstützt, wird nicht als Auftragsdatenbank unterstützt. Serverlose Datenbanken, auf die elastische Aufträge gerichtet sind, unterstützen das automatische Anhalten. Auftragsverbindungen setzen eine Datenbank fort.
Automatisches Anhalten wird während der Bereitstellung bestimmter Dienstupdates vorübergehend verhindert, die erfordern, dass die Datenbank online ist. In solchen Fällen ist AutoAnhalten wieder zulässig, sobald das Dienstupdate abgeschlossen ist.
Problembehandlung beim AutoAnhalten
Wenn automatisches Anhalten aktiviert ist und Features, die das automatische Anhalten blockieren, nicht verwendet werden, aber eine Datenbank nach dem Verzögerungszeitraum nicht automatisch angehalten wird, verhindern Anwendungs- oder Benutzersitzungen möglicherweise das automatische Anhalten.
Stellen Sie mithilfe eines beliebigen Clienttools eine Verbindung mit der Datenbank her, und führen Sie die folgende Abfrage aus, um herauszufinden, ob derzeit Anwendungs- oder Benutzersitzungen mit der Datenbank verbunden sind:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Tipp
Stellen Sie nach dem Ausführen der Abfrage sicher, dass Sie die Verbindung mit der Datenbank trennen. Andernfalls verhindert die von der Abfrage verwendete geöffnete Sitzung das AutoAnhalten.
- Wenn das Ergebnisset nicht leer ist, bedeutet dies, dass derzeit Sitzungen das automatische Anhalten verhindern.
- Wenn das Ergebnisset leer ist, ist es dennoch möglich, dass Sitzungen zu einem bestimmten Zeitpunkt während des Verzögerungszeitraums beim AutoAnhalten geöffnet waren, möglicherweise für kurze Zeit. Sie können Azure SQL Auditing verwenden und Überwachungsdaten für den relevanten Zeitraum untersuchen, um auf Aktivitäten während des Verzögerungszeitraums zu prüfen.
Wichtig
Das Vorhandensein von offenen Sitzungen mit oder ohne gleichzeitige CPU-Auslastung im Benutzerressourcenpool ist der häufigste Grund dafür, dass eine serverlose Datenbank nicht wie erwartet automatisch angehalten wird.
Automatisches Fortsetzen
Automatisches Fortsetzen wird ausgelöst, wenn eine der folgenden Bedingungen erfüllt ist:
| Funktion | Trigger für automatisches Fortsetzen |
|---|---|
| Authentifizierung und Autorisierung | Anmeldename |
| Bedrohungserkennung | Aktivieren/Deaktivieren von Einstellungen für die Bedrohungserkennung auf der Datenbank- oder Serverebene. Ändern von Einstellungen für die Bedrohungserkennung auf der Datenbank- oder Serverebene. |
| Datenermittlung und -klassifizierung | Hinzufügen, Ändern, Löschen oder Anzeigen von Vertraulichkeitsbezeichnungen |
| Überwachung | Anzeigen von Überwachungsdatensätzen. Aktualisieren oder Anzeigen von Überwachungsrichtlinien. |
| Datenmaskierung | Hinzufügen, Ändern, Löschen oder Anzeigen von Datenmaskierungsregeln |
| Transparent Data Encryption | Anzeigen des Status der transparenten Datenverschlüsselung |
| Sicherheitsrisikobewertung | Ad-hoc-Scans und periodische Scans, falls aktiviert |
| Abfragedatenspeicher (Leistung) | Ändern oder Anzeigen von Abfragespeichereinstellungen |
| Empfehlungen zur Leistung | Anzeigen oder Anwenden von Empfehlungen zur Leistung |
| Automatische Optimierung | Anwendung und Überprüfung von Empfehlungen für automatische Optimierung, z. B. automatische Indizierung |
| Kopieren von Datenbanken | Erstellen von Datenbanken als Kopie. Exportieren in eine BACPAC-Datei. |
| SQL-Datensynchronisierung | Die Synchronisierung zwischen Hub- und Mitgliedsdatenbanken, die nach einem konfigurierbaren Zeitplan oder manuell ausgeführt werden |
| Ändern bestimmter Datenbankmetadaten | Hinzufügen von neuen Datenbanktags. Ändern der Mindest- und Höchstwerte für virtuelle Kerne oder der Verzögerung für automatisches Anhalten. |
| SQL Server Management Studio (SSMS) | Durch Verwenden von SSMS-Versionen vor 18.1 und Öffnen eines neuen Abfragefensters für eine Datenbank auf dem Server wird jede automatisch angehaltene Datenbank auf dem betreffenden Server fortgesetzt. Dieses Verhalten tritt nicht auf, wenn mindestens Version 18.1 von SSMS verwendet wird. |
Überwachung und Verwaltung sowie andere Lösungen, die einen der oben aufgeführten Vorgänge ausführen, lösen eine automatische Fortsetzung aus. Automatisches Fortsetzen wird ebenfalls während der Bereitstellung bestimmter Dienstupdates ausgelöst, die erfordern, dass die Datenbank online ist.
Konnektivität
Wenn eine serverlose Datenbank angehalten wird, wird die Datenbank beim ersten Verbindungsversuch fortgesetzt, und es wird ein Fehler (Fehlercode 40613) mit dem Hinweis zurückgegeben, dass die Datenbank nicht verfügbar ist. Sobald die Datenbank fortgesetzt wird, kann die Anmeldung wiederholt werden, um die Verbindung herzustellen. Datenbankclients, die den Empfehlungen für die Verbindungswiederholungslogik folgen, sollten nicht geändert werden müssen. Informationen zu den Optionen und Empfehlungen für die Verbindungswiederholungslogik finden Sie unter:
- Verbindungswiederholungslogik in SqlClient
- Verbindungswiederholungslogik in SQL-Datenbank mit Entity Framework Core
- Verbindungswiederholungslogik in SQL-Datenbank mit Entity Framework 6
- Verbindungswiederholungslogik in SQL-Datenbank mithilfe von ADO.NET
Latency
Die Wartezeit für automatisches Fortsetzen und AutoAnhalten einer serverlosen Datenbank liegt normalerweise im Bereich von 1 für automatisches Fortsetzen und zwischen 1 und 10 Minuten nach Ablauf des Verzögerungszeitraums für AutoAnhalten.
Vom Kunden verwaltete transparente Datenverschlüsselung (BYOK)
Löschen oder Sperren von Schlüsseln
Falls die vom Kunden verwaltete transparente Datenverschlüsselung (BYOK) verwendet und die serverlose Datenbank automatisch angehalten wird, wenn ein Schlüssel gelöscht oder widerrufen wird, verbleibt die Datenbank im automatisch angehaltenen Zustand. Nach dem nächsten Fortsetzen der Datenbank kann in diesem Fall innerhalb von ungefähr 10 Minuten nicht mehr auf die Datenbank zugegriffen werden. Sobald der Zugriff auf die Datenbank nicht mehr möglich ist, wird der Wiederherstellungsvorgang identisch mit dem für bereitgestellte Computedatenbanken. Wenn die serverlose Datenbank zum Zeitpunkt des Löschens oder Widerrufens von Schlüsseln online ist, ist der Zugriff auf die Datenbank auch nach etwa 10 Minuten nicht mehr möglich, wie dies auch bei bereitgestellten Computedatenbanken der Fall ist.
Schlüsselrotation
Wenn die vom Kunden verwaltete Transparent Data Encryption (BYOK) genutzt wird und das serverlose automatische Anhalten aktiviert ist, wird die Datenbank bei der Rotation von Schlüsseln automatisch fortgesetzt und anschließend automatisch angehalten, sofern die Bedingungen dafür erfüllt sind.
Erstellen einer neuen serverlosen Datenbank
Beim Erstellen einer neuen Datenbank bzw. Verschieben einer vorhandenen Datenbank in eine serverlose Computeebene gilt dasselbe Muster wie beim Erstellen einer neuen Datenbank in der bereitgestellten Computeebene; dieser Vorgang umfasst die folgenden zwei Schritte:
Geben Sie das Dienstziel an. Das Dienstziel schreibt die Dienstebene, die Hardwarekonfiguration und die maximale Anzahl von virtuellen Kernen vor. Weitere Informationen zu Optionen für Dienstziele finden Sie unter Limits für serverlose Ressourcen
Geben Sie optional die Mindestanzahl virtueller Kerne und die Verzögerung für AutoAnhalten an, um deren Standardwerte zu ändern. In der folgenden Tabelle werden die verfügbaren Werte für diese Parameter aufgeführt.
Parameter Auswahlmöglichkeiten für Werte Standardwert Mindestanzahl virtueller Kerne Hängt von den konfigurierten maximalen virtuellen Kernen ab – siehe Ressourceneinschränkungen. 0,5 V-Kerne Verzögerung für automatisches Anhalten Minimum: 15 Minuten
Maximum: 10.080 Minuten (sieben Tage)
Inkremente: 1 Minuten
Automatisches Anhalten deaktivieren: -160 Minuten
Die folgenden Beispiele erstellen eine neue Datenbank in der serverlosen Computeebene.
Verwenden Azure Portal
Weitere Informationen finden Sie unter Schnellstart: Erstellen einer Einzeldatenbank in Azure SQL-Datenbank über das Azure-Portal.
Verwenden von PowerShell
Erstellen Sie mit dem folgenden PowerShell-Beispiel eine neue serverlose Datenbank vom Typ „Universell“:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Azure CLI verwenden
Erstellen Sie mit dem folgenden Azure CLI-Beispiel eine neue serverlose Datenbank vom Typ „Universell“:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Verwenden von Transact-SQL (T-SQL)
Wenn Sie T-SQL zum Erstellen einer neuen serverlosen Datenbank verwenden, werden Standardwerte für die minimalen vCores und die automatische Pausenverzögerung angewendet. Die Werte können anschließend über das Azure-Portal oder per API, einschließlich PowerShell, Azure CLI und REST, geändert werden.
Weitere Informationen finden Sie unter CREATE DATABASE.
Erstellen Sie mit dem folgenden T-SQL-Beispiel eine neue serverlose Datenbank vom Typ „Universell“:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Verschieben einer Datenbank zwischen Computeebenen oder Dienstebenen
Eine Datenbank kann zwischen der bereitgestellten Computeebene und der Ebene für serverloses Computing verschoben werden.
Eine serverlose Datenbank kann auch von der universellen Dienstebene in die Hyperscale-Dienstebene verschoben werden. Weitere Informationen finden Sie unter Verwalten von Hyperscale-Datenbanken.
Wenn Sie eine Datenbank zwischen Computeebenen verschieben, geben Sie den Parameter Computemodell als Serverless oder Provisioned bei Verwendung von PowerShell und der Azure CLI sowie SERVICE_OBJECTIVE bei Verwendung von T-SQL an. Prüfen Sie die Ressourcengrenzwerte zum Bestimmen des geeigneten Dienstobjekts.
In den folgenden Beispielen wird eine vorhandene einzelne Datenbank vom bereitgestellten Computing zum serverlosen Computing verschoben.
Verwenden von PowerShell
Verschieben Sie eine bereitgestellte Computedatenbank vom Typ „Universell“ mit dem folgenden PowerShell-Beispiel in die serverlose Computingebene:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Mithilfe der Azure-Befehlszeilenschnittstelle
Verschieben Sie eine bereitgestellte Computedatenbank vom Typ „Universell“ mit dem folgenden Azure CLI-Beispiel in die serverlose Computingebene:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Verwenden von Transact-SQL (T-SQL)
Wenn Sie T-SQL verwenden um eine Datenbank zwischen Computeebenen zu verschieben, werden Standardwerte für die minimalen vCores und die automatische Pausenverzögerung angewendet. Die Werte können anschließend über das Azure-Portal oder per API, einschließlich PowerShell, Azure CLI und REST, geändert werden. Weitere Informationen finden Sie unter ALTER DATABASE.
Verschieben Sie eine bereitgestellte Computedatenbank vom Typ „Universell“ mit dem folgenden T-SQL-Beispiel in die serverlose Computingebene:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Ändern der serverlosen Konfiguration
Verwenden von PowerShell
Verwenden Sie Set-AzSqlDatabase, um die maximale oder minimale Anzahl virtueller Kerne und die Verzögerung für automatisches Anhalten zu ändern. Verwenden Sie die MaxVcore-, – MinVcoreund AutoPauseDelayInMinutes-Argumente. Serverloses automatisches Anhalten wird im Hyperscale-Tarif derzeit nicht unterstützt, sodass das Argument für automatische Anhalteverzögerung nur für die Ebene „Universell“ gilt.
Mithilfe der Azure-Befehlszeilenschnittstelle
Verwenden Sie az sql db update, um die maximale oder minimale Anzahl von virtuellen Kernen und automatische Anhalteverzögerung zu ändern. Verwenden Sie die capacity-, – min-capacityund auto-pause-delay-Argumente. Serverloses automatisches Anhalten wird im Hyperscale-Tarif derzeit nicht unterstützt, sodass das Argument für automatische Anhalteverzögerung nur für die Ebene „Universell“ gilt.
Monitor
Genutzte und berechnete Ressourcen
Die Ressourcen einer serverlosen Datenbank umfassen das App-Paket, SQL-Instanz und Benutzerressourcenpool-Entitäten.
App-Paket
Das App-Paket ist die „Außengrenze“ der Ressourcenverwaltung für eine Datenbank, wobei es keine Rolle spielt, ob sich die Datenbank auf einer serverlosen oder einer bereitgestellten Computeebene befindet. Das App-Paket enthält die SQL-Instanz und externe Dienste wie Volltextsuche, die zusammen sämtliche Benutzer- und Systemressourcen umfassen, die von einer Datenbank in SQL-Datenbank genutzt werden. Die SQL-Instanz bestimmt generell die allgemeine Ressourcennutzung für das gesamte App-Paket.
Benutzerressourcenpool
Der Benutzerressourcenpool ist eine „Innengrenze“ der Ressourcenverwaltung für eine Datenbank, wobei es keine Rolle spielt, ob sich die Datenbank auf einer serverlosen oder einer bereitgestellten Computeebene befindet. Der Benutzerressourcenpool beschränkt CPU und E/A für Benutzer-Workload, die von DDL (CREATE und ALTER) und DML (INSERT, UPDATE, DELETE und MERGE und SELECT)-Abfragen generiert wird. Diese Abfragen sind im Allgemeinen für den Großteil der Auslastung des App-Pakets verantwortlich.
Metriken
Die folgende Tabelle umfasst Metriken für die Überwachung des Ressourcenverbrauchs des App-Pakets und des Benutzerressourcenpools einer serverlosen Datenbank einschließlich möglichen Georeplikaten:
| Entity | Metrik | BESCHREIBUNG | Units |
|---|---|---|---|
| App-Paket | app_cpu_percent | Prozentsatz der von der App genutzten virtuellen Kerne, bezogen auf die maximal zulässigen virtuellen Kerne für die App. Für serverlose Hyperscale wird diese Metrik für alle primären Replikate, benannten Replikate und Georeplikate verfügbar gemacht. | Prozentwert |
| App-Paket | app_cpu_billed | Die Menge der Computeressourcen, die im Berichtszeitraum für die App abgerechnet wurden. Der während dieses Zeitraums zu zahlende Betrag ist das Produkt aus dieser Metrik und dem Einzelpreis für virtuelle Kerne. Werte dieser Metrik werden bestimmt, indem der maximal genutzte Arbeitsspeicher und der pro Sekunde genutzte Speicher aggregiert werden. Liegt die genutzte Menge unter der bereitgestellten Mindestmenge (festgelegt durch Mindestanzahl virtueller Kerne und Minimalwert für Speicher), wird die bereitgestellte Mindestmenge berechnet. Der Arbeitsspeicher wird in Einheiten aus virtuellen Kernen normalisiert, indem der Arbeitsspeicher in GB nach 3 GB pro virtuellem Kern neu skaliert wird. So kann die CPU bei der Abrechnung mit dem Arbeitsspeicher verglichen werden. Für serverloses Hyperscale wird diese Metrik für das primäre Replikat und benannte Replikate verfügbar gemacht. |
Virtueller Kern – Sekunden |
| App-Paket | app_cpu_billed_HA_replicas | Gilt nur für serverloses Hyperscale. Summe der Computeleistung, die während des Berichtszeitraums für alle Apps für Hochverfügbarkeitsreplikate abgerechnet wurde. Diese Summe bezieht sich entweder auf die Hochverfügbarkeitsreplikate, die zum primären Replikat gehören, oder auf die Hochverfügbarkeitreplikate, die zu einem bestimmten benannten Replikat gehören. Vor der Berechnung dieser Summe für Hochverfügbarkeitsreplikate wird die Computemenge, die für ein einzelnes Hochverfügbarkeitsreplikat berechnet wird, auf die gleiche Weise wie für das primäre Replikat oder ein benanntes Replikat bestimmt. Für serverlose Hyperscale wird diese Metrik für alle primären Replikate, benannten Replikate und Georeplikate verfügbar gemacht. Der während dieses Zeitraums zu zahlende Betrag ist das Produkt aus dieser Metrik und dem Einzelpreis für virtuelle Kerne. | Virtueller Kern – Sekunden |
| App-Paket | app_memory_percent | Prozentsatz des von der App genutzten Speichers, bezogen auf den maximal zulässigen Speicher für die App. Für serverlose Hyperscale wird diese Metrik für alle primären Replikate, benannten Replikate und Georeplikate verfügbar gemacht. | Prozentwert |
| Benutzerressourcenpool | cpu_percent | Prozentsatz der von der Benutzerworkload genutzten virtuellen Kerne, bezogen auf die maximal zulässigen virtuellen Kerne für die Benutzerworkload. | Prozentwert |
| Benutzerressourcenpool | data_IO_percent | Prozentsatz der von der Benutzerworkload genutzten Daten-IOPS, bezogen auf die maximal zulässige Daten-IOPS für die Benutzerworkload. | Prozentwert |
| Benutzerressourcenpool | log_IO_percent | Prozentsatz der von der Benutzerworkload genutzten Protokollrate (MB/s), bezogen auf die maximal zulässige Protokollrate (MB/s) für die Benutzerworkload. | Prozentwert |
| Benutzerressourcenpool | workers_percent | Prozentsatz der von der Benutzerworkload genutzten Worker, bezogen auf die maximal zulässige Anzahl von Workern für die Benutzerworkload. | Prozentwert |
| Benutzerressourcenpool | sessions_percent | Prozentsatz der von der Benutzerworkload genutzten Sitzungen, bezogen auf die maximal zulässige Anzahl von Sitzungen für die Benutzerworkload. | Prozentwert |
Status für Anhalten und Fortsetzen
Wenn eine serverlose Datenbank mit aktivierter automatischer Pause aktiviert ist, enthält der gemeldete Status die folgenden Werte:
| Status | BESCHREIBUNG |
|---|---|
| Online | Die Datenbank ist online. |
| Wird angehalten | Die Datenbank wechselt von „Online“ zu „Angehalten“. |
| Angehalten | Die Datenbank wurde angehalten. |
| Wird fortgesetzt | Die Datenbank wechselt von „Angehalten“ zu „Online“. |
Verwenden des Azure-Portals
Im Azure-Portal wird der Datenbankstatus auf der Übersichtsseite der Datenbank und auf der Übersichtsseite des Servers angezeigt. Auch im Azure-Portal kann der Verlauf von Pausen- und Fortsetzungsereignissen einer serverlosen Datenbank im Aktivitätsprotokoll angezeigt werden.
Verwenden von PowerShell
Zeigen Sie die aktuellen Einstellungen mit dem folgenden PowerShell-Beispiel an:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Mithilfe der Azure-Befehlszeilenschnittstelle
Zeigen Sie den aktuellen Datenbankstatus mithilfe des folgenden Azure CLI-Beispiels an:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Ressourceneinschränkungen
Ressourceneinschränkungen werden unter serverlose Computeebene beschrieben.
Abrechnung
Die abgerechnete Computeleistung für eine serverlose Datenbank basiert auf der maximal verwendeten CPU und dem verwendeten Arbeitsspeicher (pro Sekunde). Wenn die CPU und der Arbeitsspeicher kleiner als die bereitgestellte Mindestmenge für jede Ressource sind, wird die bereitgestellte Menge abgerechnet. Um CPU und Arbeitsspeicher zu Abrechnungszwecken vergleichen zu können, wird der Arbeitsspeicher in Einheiten von virtuellen Kernen normalisiert, indem die Anzahl von GB mit 3 GB pro virtuellem Kern neu skaliert wird.
- Berechnete Ressource: CPU und Arbeitsspeicher
- Berechneter Betrag: Einzelpreis virtueller Kern * Max. (Min. virtuelle Kerne, genutzte virtuelle Kerne, Min. Speicher GB * 1/3, genutzter Speicher GB * 1/3)
- Fakturierungsintervall: Pro Sekunde
Der Einzelpreis für virtuelle Kerne ergibt sich aus den Kosten pro virtuellem Kern pro Sekunde.
Informationen zu Einzelpreisen in einer bestimmten Region finden Sie auf der Seite Azure SQL-Datenbank – Preise .
Die serverlose Computingmenge für eine Datenbank vom Typ „Universell“ oder ein primäres oder benanntes Hyperscale-Replikat wird durch die folgende Metrik verfügbar gemacht:
- Metrik: app_cpu_billed (virtueller Kern – Sekunden)
- Definition: Max. (min. virtuelle Kerne, genutzte virtuelle Kerne, min. Speicher GB * 1/3, genutzter Speicher GB * 1/3)
- Berichtshäufigkeit: Pro Minute basierend auf Messungen pro Sekunde, die über 1 Minute aggregiert wurden.
Die Menge an Compute, die serverlos für Hyperscale-Hochverfügbarkeitsreplikate abgerechnet wird, die zum primären Replikat oder einem benannten Replikat gehören, wird durch die folgende Metrik verfügbar gemacht:
- Metrik: app_cpu_billed_HA_replicas (virtueller Kern – Sekunden)
- Definition: Summe der maximalen Anzahl (min. virtuelle Kerne, verwendete virtuelle Kerne, min. Arbeitsspeicher in GB * 1/3, verwendeter Arbeitsspeicher in GB * 1/3) für alle Hochverfügbarkeitsreplikate, die zu ihrer übergeordneten Ressource gehören.
- Übergeordnete Ressource und Metrikendpunkt: Das primäre Replikat und alle benannten Replikate machen diese Metrik jeweils separat verfügbar, die die abzurechnende Computeleistung für alle zugeordneten Hochverfügbarkeitsreplikate misst.
- Berichtshäufigkeit: Pro Minute basierend auf Messungen pro Sekunde, die über 1 Minute aggregiert wurden.
Mindestrechnungsbetrag für Computeressourcen
Wurde eine serverlose Datenbank angehalten, so beläuft sich der Rechnungsbetrag für Computeressourcen auf 0 (null). Wurde sie nicht angehalten, so entspricht der Mindestrechnungsbetrag für Computeressourcen mindestens dem Betrag für die Anzahl von virtuellen Kernen basierend auf max. (min. virtuelle Kerne, min. Arbeitsspeicher GB * 1/3).
Beispiele:
- Angenommen, eine serverlose Datenbank im Tarif „Universell“ wird nicht angehalten und ist so konfiguriert, dass die maximale Anzahl von virtuellen Kernen 8 und die minimale Anzahl von virtuellen Kernen 1 ist, was einem Mindestarbeitsspeicher von 3,0 GB entspricht. Der Mindestrechnungsbetrag für Computeressourcen basiert dann auf max. (1 virtueller Kern, 3,0 GB * 1 virtueller Kern / 3 GB) = 1 virtueller Kern.
- Angenommen, eine serverlose Datenbank im Tarif „Universell“ wird nicht angehalten und ist so konfiguriert, dass die maximale Anzahl von virtuellen Kernen 4 und die minimale Anzahl von virtuellen Kernen 0,5 ist, was einem Mindestarbeitsspeicher von 2,1 GB entspricht. Der Mindestrechnungsbetrag für Computeressourcen basiert dann auf max. (0,5 virtuelle Kerne, 2,1 GB * 1 virtueller Kern / 3 GB) = 0,7 virtuelle Kerne.
- Angenommen, eine serverlose Datenbank im Hyperscale-Tarif verfügt über ein primäres Replikat mit einem Hochverfügbarkeitsreplikat und einem benannten Replikat ohne Hochverfügbarkeitsreplikate. Angenommen, jedes Replikat ist so konfiguriert, dass die maximale Anzahl von virtuellen Kernen 8 und die minimale Anzahl von virtuellen Kernen 1 ist, was einem Mindestarbeitsspeicher von 3 GB entspricht. Die minimale Computeabrechnung für das primäre Replikat, das Hochverfügbarkeitsreplikat und das benannte Replikat basiert jeweils auf maximal (1 virtueller Kern, 3 GB * 1 virtueller Kern/3 GB) = 1 virtueller Kern.
Der Preisrechner für Azure SQL-Datenbank für den Tarif Serverless kann verwendet werden, um den minimal konfigurierbaren Arbeitsspeicher zu bestimmen basierend auf der konfigurierten maximalen und minimalen Anzahl von virtuellen Kernen. Wenn die konfigurierte Mindestanzahl von virtuellen Kernen größer als 0,5 ist, ist der Mindestrechnungsbetrag für Computeressourcen in der Regel unabhängig vom konfigurierten minimalen Arbeitsspeicher und basiert nur auf der konfigurierten minimalen Anzahl von virtuellen Kernen.
Szenariobeispiele
Erwägen Sie die Verwendung einer serverlosen Datenbank im Tarif „Universell“, für die für virtuelle Kerne ein Mindestwert von 1 und ein Höchstwert von 4 konfiguriert ist. Diese Konfiguration entspricht ungefähr einem Arbeitsspeicher von mindestens 3 GB und maximal 12 GB. Angenommen, die Verzögerung für automatisches Anhalten ist auf sechs Stunden festgelegt, und die Datenbankworkload ist während der ersten beiden Stunden eines Zeitraums von 24 Stunden aktiv und ansonsten inaktiv.
In diesem Fall werden für die Datenbank Compute- und Speicherkosten während der ersten acht Stunden berechnet. Die Datenbank ist zwar nach der zweiten Stunde inaktiv, aber für die nachfolgenden sechs Stunden werden basierend auf der minimalen bereitgestellten Computeleistung trotzdem noch Computekosten berechnet, während die Datenbank online ist. Während die Datenbank angehalten ist, werden in der restlichen Zeit des 24-Stunden-Zeitraums nur Kosten für den Speicher berechnet.
Die genaue Berechnung der Computekosten für dieses Beispiel lautet:
| Zeitintervall | Pro Sekunde verwendete virtuelle Kerne | Pro Sekunde verwendete GB | Berechnete Computedimension | Für Zeitintervall berechnete Sekunden für virtuelle Kerne |
|---|---|---|---|---|
| 0:00 - 1:00 | 4 | 9 | Verwendete virtuelle Kerne | 4 virtuelle Kerne * 3.600 Sekunden = 14.400 Sekunden für virtuelle Kerne |
| 1:00 - 2:00 | 1 | 12 | Verwendeter Arbeitsspeicher | 12 GB * 1/3 * 3600 Sekunden = 14400 Sekunden für virtuelle Kerne |
| 2:00 - 8:00 | 0 | 0 | Mindestens bereitgestellter Arbeitsspeicher | 3 GB * 1/3 * 21.600 Sekunden = 21.600 Sekunden für virtuelle Kerne |
| 8:00 - 24:00 | 0 | 0 | Keine Berechnung von Computeleistung während des Anhaltens | 0 Sekunden für virtuelle Kerne |
| Gesamte berechnete Sekunden für virtuelle Kerne in 24 Stunden | 50.400 Sekunden für virtuelle Kerne |
Angenommen, der Compute-Einheitenpreis beträgt 0,000145 USD/V-Kern/Sekunde. Die Computeleistung, die für diesen 24-Stunden-Zeitraum berechnet wird, ist dann das Produkt aus dem Preis der Compute-Einheit und den berechneten Sekunden für virtuelle Kerne: 0,000145 USD/V-Kern/Sekunde * 50400 Sekunden für virtuelle Kerne ~ 7,31 USD.
Azure-Hybridvorteil und reservierte Kapazität
Rabatte für Azure-Hybridvorteil (Azure Hybrid Benefit, AHB) und reservierte Kapazität gelten nicht für die serverlose Computeebene.
Verfügbare Regionen
Serverlos für Allgemeinen Zweck und Hyperscale Tiers mit Unterstützung bis zu 40 maximum vCores ist weltweit verfügbar, außer die folgenden Regionen:
- China, Osten
- China, Norden
- Deutschland, Mitte
- Deutschland, Nordosten
- US-Regierungszentrale (Iowa)
Regionen mit Unterstützung von bis zu 80 virtuellen Kernen ohne Verfügbarkeitszonen für Universell und Hyperscale
Derzeit werden maximal 80 vCores in serverlosen Ebenen für allgemeine Zwecke und Hyperscale-Ebenen in den folgenden Regionen unterstützt:
- Australien, Mitte 1
- Australien, Mitte 2
- Australien (Osten)
- Australien, Südosten
- Brasilien Süd
- Brasilien, Südosten
- Kanada, Mitte
- Kanada, Osten
- USA (Mitte)
- China, Osten 2
- China, Osten 3
- China, Norden 2
- China, Norden 3
- Asien, Osten
- East US
- USA (Ost) 2
- Frankreich, Mitte
- Frankreich, Süden
- Deutschland, Norden
- Deutschland, Westen-Mitte
- Indien, Mitte
- Indien, Süden
- Israel, Mitte
- Italien, Norden
- Japan, Osten
- Japan, Westen
- Jio Indien, Mitte
- Jio Indien, Westen
- Korea, Mitte
- Korea, Süden
- Maylaysia Süd
- Mexiko, Mitte
- USA Nord Mitte
- Nordeuropa
- Norwegen, Osten
- Norwegen, Westen
- Polen, Mitte
- Katar, Mitte
- Südafrika, Norden
- Südafrika, Westen
- USA Süd Mitte
- Asien, Südosten
- Spanien, Mitte
- Schweden, Mitte
- Schweden, Süden
- Schweiz, Norden
- Schweiz, Westen
- Taiwan, Norden
- Taiwan Northwest
- VAE, Mitte
- Vereinigte Arabische Emirate, Norden
- UK, Süden
- UK, Westen
- US Gov, Osten
- US Gov, Süd Mitte
- US Gov, Südwesten
- Europa, Westen
- USA, Westen Mitte
- USA (Westen)
- USA, Westen 2
- USA, Westen 3
Regionen mit Unterstützung von bis zu 80 virtuellen Kernen mit Verfügbarkeitszonen für Universell und Hyperscale
Aktuell werden in den folgenden Regionen maximal 80 virtuelle Kerne mit Unterstützung der Verfügbarkeitszone in serverlos für die Stufen „Allgemeiner Zweck“ und „Hyperscale“ bereitgestellt, in den folgenden Regionen mit weiteren geplanten Regionen:
- Australien (Osten)
- Brasilien Süd
- Kanada, Mitte
- USA, Mitte
- Asien, Osten
- East US
- USA (Ost) 2
- Frankreich, Mitte
- Deutschland, Westen-Mitte
- Indien, Mitte
- Japan, Osten
- Korea, Mitte
- Nordeuropa
- Südafrika, Norden
- USA Süd Mitte
- Asien, Südosten
- Schweden, Mitte
- Vereinigte Arabische Emirate, Norden
- UK, Süden
- US Gov, Osten
- Europa, Westen
- USA, Westen 2
- USA, Westen 3
Zugehöriger Inhalt
- Informationen zu den ersten Schritten finden Sie unter Schnellstart: Erstellen einer Einzeldatenbank - Azure SQL-Datenbank.
- Informationen zu Optionen für serverlose Dienstebenen finden Sie unter Universell und Hyperscale.