Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Artikel wird das Feature automatisierte Sicherung für Hyperscale-Datenbanken in Azure SQL-Datenbank erläutert.
Hyperscale-Datenbanken nutzen eine einzigartige Architektur mit hoch skalierbaren Leistungsebenen für Speicher und Compute. Hyperscale-Backups sind snapshot-basiert und nahezu augenblicklich. Protokollsicherungen werden für die Dauer der Sicherungsaufbewahrung im Langzeitspeicher von Azure gespeichert.
Eine Hyperscale-Architektur erfordert nicht die gleiche Sicherungskette wie dateibasierte Sicherungen, die in SQL Server und anderen SQL-Datenbankebenen verwendet werden, erfüllt jedoch weiterhin die gleichen RTO- und RPO-Anforderungen. Das Transaktionsprotokoll verhält sich auf die gleiche Weise und ermöglicht die gleiche Point-in-Time-Wiederherstellungsfunktion. In Hyperscale unterscheiden sich Sicherungshäufigkeit, Speicherkosten, Planung, Speicherredundanz und Wiederherstellungsfunktionen von anderen Datenbanken in Azure SQL-Datenbank.
Sicherung- und Wiederherstellungsleistung
Durch die Trennung von Speicher und Compute können bei Hyperscale Sicherungs- und Wiederherstellungsvorgänge auf die Speicherebene verlagert werden, um den Ressourcenverbrauch auf Compute-Replikaten zu eliminieren. Datenbanksicherungen wirken sich nicht auf die Leistung primärer oder sekundärer Compute-Replikate aus.
Sicherung- und Wiederherstellungsvorgänge für Hyperscale-Datenbanken erfolgen dank der Verwendung von Speichermomentaufnahmen unabhängig von der Datengröße sehr schnell. Die Sicherung erfolgt praktisch sofort.
Sie können eine Datenbank an jedem beliebigen Zeitpunkt innerhalb des Aufbewahrungszeitraums der Sicherung folgendermaßen wiederherstellen:
- Durch Zurücksetzen auf anwendbare Dateimomentaufnahmen.
- Durch Anwenden von Transaktionsprotokollen, um die wiederhergestellte Datenbank transaktional konsistent zu machen.
Daher ist die Wiederherstellung kein Vorgang, bei dem die Datengröße gleich bleibt. Die Wiederherstellung einer Hyperscale-Datenbank innerhalb derselben Azure-Region erfolgt in Minuten anstelle von Stunden oder Tagen, auch für Datenbanken mit mehreren Terabyte.
Das Ändern der Speicherredundanz beim Ausführen einer Wiederherstellung kann zu längeren Wiederherstellungszeiten führen, da die Wiederherstellung der Größe der Daten entspricht und die Zeit daher proportional zur Datenbankgröße ist.
Die Erstellung neuer Datenbanken durch Wiederherstellen einer vorhandenen Sicherung oder Kopieren der Datenbank nutzt auch die Compute- und Speichertrennung in Hyperscale. Sie können Kopien für Entwicklungs- oder Testzwecke erstellen, selbst von Datenbanken mit mehreren Terabyte. Dies ist innerhalb derselben Region in wenigen Minuten möglich, wenn Sie denselben Speichertyp verwenden.
Sicherungsaufbewahrung
Die standardmäßige Kurzzeitaufbewahrung von Sicherungen für Hyperscale-Datenbanken beträgt 7 Tage.
Die Kurzzeitaufbewahrung von Sicherungen im Bereich von 1 bis 35 Tagen sowie die Langzeitaufbewahrung (LTR) von Sicherungen für Hyperscale-Datenbanken ist ab September 2023 allgemein verfügbar. Weitere Informationen finden Sie unter Langzeitaufbewahrung – Azure SQL Datenbank und Azure SQL Managed Instance.
Sicherungszeitplanung
Für Hyperscale-Datenbanken sind keine herkömmlichen vollständigen, differenziellen und Transaktionsprotokollsicherungen möglich. Stattdessen werden regelmäßige Snapshots von Datendateien erstellt.
Die generierten Transaktionsprotokolle werden für den konfigurierten Aufbewahrungszeitraum im unveränderten Zustand gespeichert. Bei der Wiederherstellung werden relevante Transaktionsprotokolldatensätze auf das wiederhergestellte Speicherabbild angewendet. Dies führt zu einer transaktional konsistenten Datenbank ohne Datenverlust ab dem festgelegten Zeitpunkt innerhalb des Aufbewahrungszeitraums.
Überwachen des Sicherungsspeicherverbrauchs
In Hyperscale geben Azure Monitor-Metriken die folgenden Verbrauchsinformationen an:
- Größe des Datensicherungsspeichers (Größe der Momentaufnahmensicherung)
- Größe des Datenspeichers (zugeordnete Datenbankgröße)
- Größe des Protokollsicherungsspeichers (Sicherungsgröße des Transaktionsprotokolls)
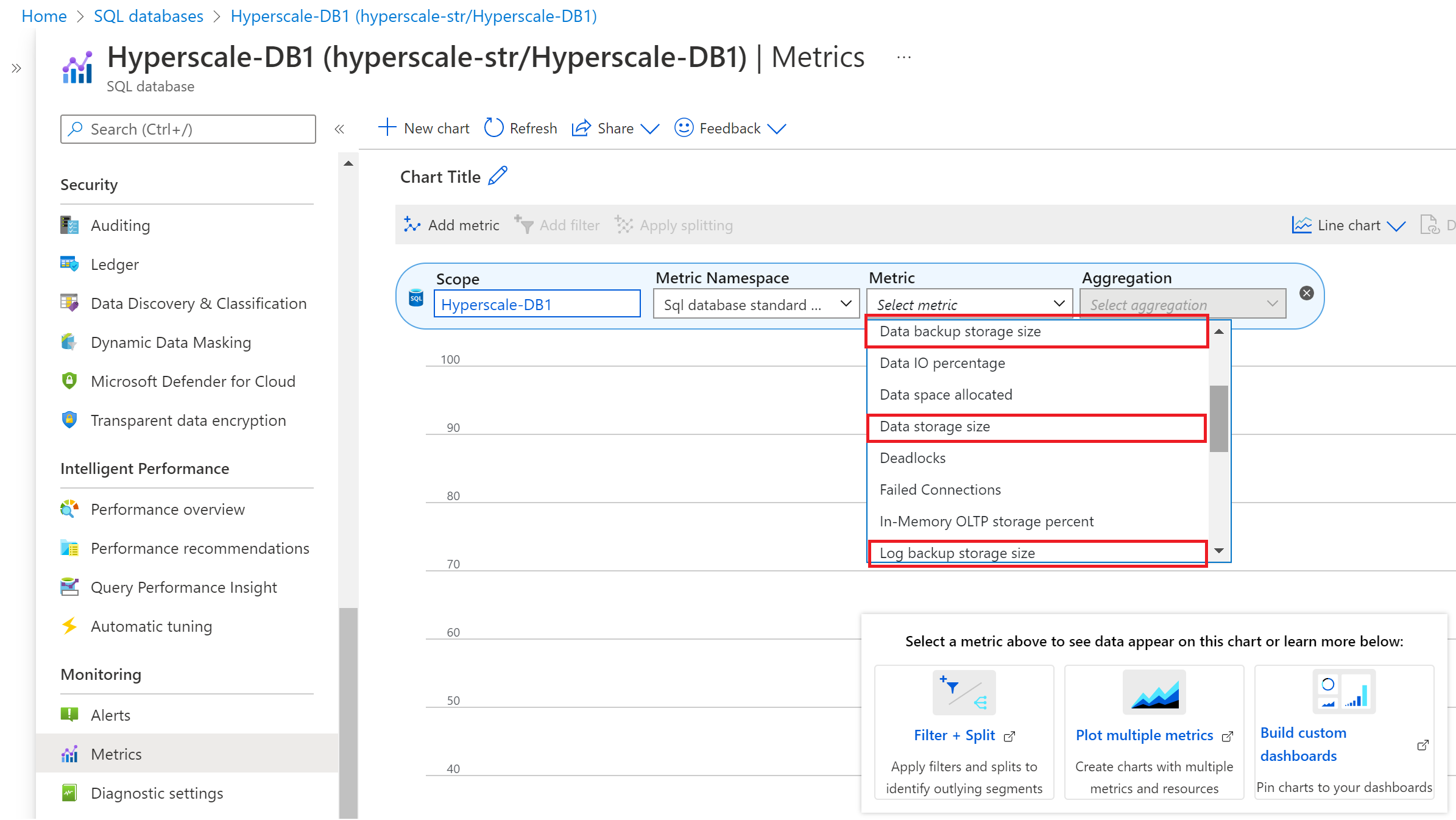
Führen Sie die folgenden Schritte aus, um Sicherungs- und Datenspeichermetriken im Azure-Portal anzuzeigen:
- Wechseln Sie zur Hyperscale-Datenbank, für die Sie Sicherungs- und Datenspeichermetriken überwachen möchten.
- Wählen Sie die Seite Metriken im Abschnitt Überwachung aus.
- Wählen Sie in der Dropdownliste Metrik die Metriken Datensicherungsspeicher, Datenspeichergröße und Protokollsicherungsspeicher mit den entsprechenden Aggregationsregeln aus.
Reduzieren des Sicherungsspeicherverbrauchs
Der Sicherungsspeicherverbrauch für eine Hyperscale-Datenbank hängt vom Aufbewahrungszeitraum, der Auswahl der Region, der Sicherungsspeicherredundanz und des Workloadtyps ab. Ziehen Sie einige der folgenden Optimierungstechniken in Betracht, um den Sicherungsspeicherverbrauch für eine Hyperscale-Datenbank zu reduzieren:
- Reduzieren Sie den Aufbewahrungszeitraum für Sicherungen auf die Mindestanforderungen für Ihre Zwecke.
- Vermeiden Sie es, häufiger als erforderlich große Schreibvorgänge auszuführen, beispielsweise die Indexwartung. Weitere Empfehlungen zur Indexpflege finden Sie unter Optimierung der Indexpflege zur Verbesserung der Abfrageleistung und Reduzierung des Ressourcenverbrauchs.
- Bei großen Datenladevorgängen sollten Sie ggf. die Datenkomprimierung verwenden.
- Verwenden Sie die
tempdb-Datenbank anstelle permanenter Tabellen in Ihrer Anwendungslogik zum Speichern temporärer Ergebnisse oder vorübergehender Daten. - Verwenden Sie einen lokal redundanten oder zonenredundanten Sicherungsspeicher, wenn die Geowiederherstellungsfunktion unnötig ist (wie etwa Entwicklungs-/Testumgebungen).
Kosten von Sicherungsspeicher
Die Kosten für die Hyperscale-Sicherungsspeicherung hängen von der Wahl der Region und der Redundanz des Sicherungsspeichers ab. Sie sind ebenso vom Workloadtyp abhängig.
Bei schreibintensiven Workloads ist es wahrscheinlicher, dass Datenseiten häufig geändert werden, was zu größeren Speichermomentaufnahmen führt. Solche Workloads generieren auch mehr Transaktionsprotokolle, was zu den Gesamtsicherungskosten beiträgt. Die Kosten für den Sicherungsspeicher werden auf Grundlage der verbrauchten Gigabytes pro Monat berechnet. Die Sicherungsspeichermenge, die der Datenbankgröße entspricht, wird ohne Zusatzkosten bereitgestellt. Ausführliche Informationen zu Preisen finden Sie auf der Seite Azure SQL-Datenbank – Preise.
Für Hyperscale wird der gebührenpflichtige Sicherungsspeicher wie folgt berechnet:
Total billable backup storage size = (data backup storage size + log backup storage size)
Die Größe des Datenspeichers ist nicht in der gebührenpflichtigen Sicherung enthalten, da sie bereits als zugewiesener Datenbankspeicher berechnet wird.
Gelöschte Hyperscale-Datenbanken verursachen Sicherungskosten, um die Wiederherstellung zu einem Zeitpunkt vor dem Löschen zu unterstützen. Bei einer gelöschten Hyperscale-Datenbank wird der gebührenpflichtige Sicherungsspeicher wie folgt berechnet:
Total billable backup storage size for deleted Hyperscale database = (data storage size + data backup size + log backup storage size) * (remaining backup retention period after deletion / configured backup retention period)
Die Größe des Datenspeichers ist in der Formel enthalten, da zugewiesener Datenbankspeicher nicht separat für eine gelöschte Datenbank berechnet wird. Bei einer gelöschten Datenbank werden Daten nach dem Löschen gespeichert, um die Wiederherstellung während des konfigurierten Sicherungsaufbewahrungszeitraums zu ermöglichen.
Der gebührenpflichtige Sicherungsspeicher für eine gelöschte Datenbank verringert sich schrittweise nach dem Löschen. Es wird null, wenn Sicherungen nicht mehr aufbewahrt werden, und dann ist die Wiederherstellung nicht mehr möglich. Wenn es sich um einen dauerhaften Löschvorgang handelt und Sie keine Sicherungen mehr benötigen, können Sie die Kosten optimieren, indem Sie die Aufbewahrung reduzieren, bevor Sie die Datenbank löschen.
Überwachen der Sicherungskosten
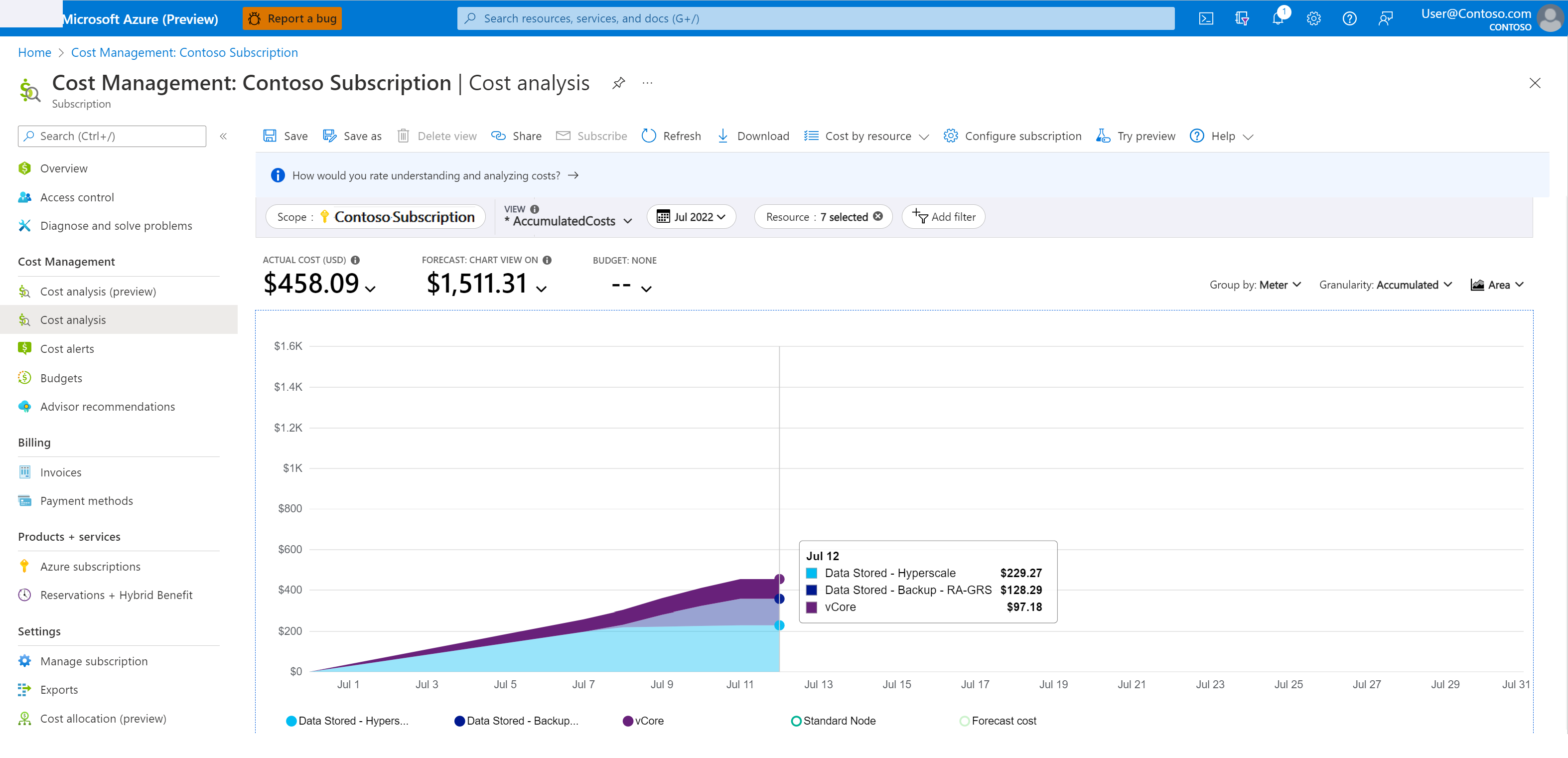
So können Sie die Sicherungsspeicherkosten einsehen:
Navigieren Sie im Azure-Portal zu Kostenverwaltung und Abrechnung.
Wählen Sie Kostenverwaltung>Kostenanalyse aus.
Wählen Sie unter Bereich das gewünschte Abonnement aus.
Filtern Sie nach dem Zeitraum und dem Dienst, an dem Sie interessiert sind, indem Sie die folgenden Schritte ausführen:
- Fügen Sie einen Filter für Dienstname hinzu.
- Wählen Sie sql-database in der Dropdownliste aus.
- Fügen Sie einen weiteren Filter für Zähler hinzu.
- Um die Sicherungskosten für die Wiederherstellung zu einem bestimmten Zeitpunkt zu überwachen, wählen Sie Gespeicherte Daten – Sicherung – RA in der Dropdown-Liste aus.
Der folgende Screenshot zeigt eine Beispielkostenanalyse.
Redundanz für Daten- und Sicherungsspeicher
Hyperscale unterstützt das Konfigurieren der Speicherredundanz. Wenn Sie eine Hyperscale-Datenbank erstellen, können Sie Ihren bevorzugten Speichertyp auswählen: geozonenredundanter Speicher mit Lesezugriff (RA-GZRS), georedundanter Speicher mit Lesezugriff (RA-GRS), zonenredundanter Speicher (ZRS) oder lokal redundanter Speicher (LRS).
- Geozonenredundanter Speicher: Die Sicherungen werden synchron in drei Azure-Verfügbarkeitszonen in der primären Region kopiert. Vergleichbar mit zonenredundantem Speicher (ZRS). Darüber hinaus kopiert sie Ihre Daten asynchron an einen einzelnen physischen Speicherort in der gekoppelten sekundären Region. Derzeit ist es nur in bestimmten Regionen verfügbar.
Weitere Informationen darüber, wie die Sicherungen für andere Speichertypen repliziert werden, finden Sie unter Redundanz für Sicherungsspeicher.
Da Hyperscale Speichermomentaufnahmen für Sicherungen verwendet, wird für Daten und Sicherungen dasselbe Speicherkonto genutzt. Daher gilt die ausgewählte Redundanz für Sicherungsspeicher sowohl für Daten als auch für Sicherungen.
Hinweis
Überlegen Sie sich die Redundanz des Sicherungsspeichers sorgfältig, wenn Sie eine Hyperscale-Datenbank erstellen, da Sie diese nur während der Erstellung der Datenbank festlegen können. Sie können diese Einstellung nach der Bereitstellung der Ressource nicht ändern.
Verwenden Sie aktive Georeplikation, um Einstellungen für die Sicherungsspeicherredundanz für eine vorhandene Hyperscale-Datenbank mit minimaler Downtime zu aktualisieren. Alternativ können Sie Datenbankkopie verwenden.
Warnung
- Geowiederherstellung wird deaktiviert, sobald die Datenbank so aktualisiert wurde, dass lokal redundanter oder zonenredundanter Speicher verwendet wird.
- Zonenredundanter Speicher steht zurzeit nur in bestimmten Regionen zur Verfügung.
- Geozonenredundanter Speicher steht zurzeit nur in bestimmten Regionen zur Verfügung.
Wiederherstellen einer Hyperscale-Datenbank in einer anderen Region
Möglicherweise müssen Sie Ihre Hyperscale-Datenbank in einer Region wiederherstellen, die sich von der aktuellen Region unterscheidet. Häufige Gründe dafür sind ein Notfallwiederherstellungs- oder Drillvorgang oder ein Umzug. Die primäre Methode besteht darin, eine Geowiederherstellung der Datenbank auszuführen. Sie verwenden dazu die gleichen Schritte wie beim Wiederherstellen jeder anderen Datenbank in Azure SQL-Datenbank in einer anderen Region:
- Erstellen Sie einen Server in der Zielregion, wenn Sie dort noch keinen geeigneten Server haben. Dieser Server muss zu demselben Abonnement wie der ursprüngliche Server (Quelle) gehören.
- Befolgen Sie die Anweisungen im Abschnitt Geowiederherstellung des Artikels zum Wiederherstellen einer Datenbank in Azure SQL-Datenbank aus automatischen Sicherungen.
Hinweis
Weil sich Quelle und Ziel in unterschiedlichen Regionen befinden, kann die Datenbank nicht wie bei Nicht-Geowiederherstellungen den Momentaufnahmespeicher mit der Quelldatenbank teilen. Die nicht-geografische Wiederherstellung passiert schnell, unabhängig von der Datenbankgröße.
Eine Geowiederherstellung einer Hyperscale-Datenbank ist ein Datengrößenvorgang, auch wenn sich das Ziel in der gekoppelten Region des georeplizierten Speichers befindet. Daher dauert eine Geowiederherstellung im Vergleich zu einer Zeitpunktwiederherstellung in derselben Region deutlich länger.
Wenn sich das Ziel in der gekoppelten Region befindet, erfolgt die Datenübertragung innerhalb einer Region. Diese Übertragung ist erheblich schneller als eine regionsübergreifende Datenübertragung. Aber es wird immer noch ein durch die Datengröße bestimmter Vorgang sein.
Wenn Sie möchten, können Sie die Datenbank in eine andere Region kopieren. Verwenden Sie diese Methode, wenn die Geowiederherstellung nicht verfügbar ist, da sie von dem ausgewählten Speicherredundanztyp nicht unterstützt wird. Ausführliche Informationen finden Sie unter Datenbankkopie für Hyperscale.
Zugehöriger Inhalt
Datenbanksicherungen sind ein wesentlicher Bestandteil jeder Strategie für Geschäftskontinuität und Notfallwiederherstellung, da sie dazu beitragen, Ihre Daten vor versehentlicher Beschädigung oder Löschung zu schützen.
- Übersicht über die Geschäftskontinuität mit Azure SQL-Datenbank
- Verwalten der langfristigen Aufbewahrung von Sicherungen in Azure SQL-Datenbank
- Wiederherstellen einer Datenbank aus einer Sicherung in Azure SQL-Datenbank
- Verwenden von PowerShell zum Wiederherstellen einer Datenbank in einem früheren Zustand