Azure Machine Learning als ein Datenprodukt für Analysen auf Cloudebene
Azure Machine Learning ist eine integrierte Plattform für die Verwaltung des Machine Learning-Lebenszyklus von Anfang bis Ende, einschließlich der Hilfe bei der Erstellung, dem Betrieb und der Verwendung von Machine Learning-Modellen und -Workflows. Zu den Vorteilen des Diensts gehören:
Funktionen unterstützen Ersteller bei der Steigerung ihrer Produktivität, indem sie sie beim Verwalten von Experimenten, zugreifen auf Daten, Nachverfolgen von Aufträgen, Optimieren von Hyperparametern und Automatisieren von Workflows unterstützen.
Die Fähigkeit des Modells, erklärt, reproduziert, geprüft und in DevOps integriert zu werden, sowie ein umfangreiches Sicherheitskontrollmodell können Betreiber dabei unterstützen, Governance- und Complianceanforderungen zu erfüllen.
Verwaltete Rückschlussfunktionen und eine stabile Integration in Azure-Compute- und -Datendienste können dazu beitragen, die Nutzung des Diensts zu vereinfachen.
Azure Machine Learning behandelt alle Aspekte des Data Science-Lebenszyklus. Er behandelt die Datenspeicher- und die Datensatzregistrierung für die Modellimplementierung. Es kann für alle Arten von maschinellem Lernen verwendet werden. Der Anwendungsbereich reicht von klassischem Machine Learning bis zu Deep Learning. Es beinhaltet überwachtes und unüberwachtes Lernen. Unabhängig davon, ob Sie es vorziehen, Python- oder R-Code zu schreiben oder Zero-Code- oder Low-Code-Optionen wie den Designer zu verwenden, können Sie präzise Modelle für maschinelles Lernen und Deep Learning in einem Azure Machine Learning-Arbeitsbereich erstellen, trainieren und verfolgen.
Azure Machine Learning, die Azure-Plattform und Azure KI-Dienste können zusammenarbeiten, um den Machine Learning-Lebenszyklus zu verwalten. Ein Machine Learning-Mitarbeiter kann Azure Synapse Analytics, Azure SQL-Datenbank oder Microsoft Power BI verwenden, um mit der Analyse von Daten und dem Übergang zu Azure Machine Learning für die Prototyperstellung, die Verwaltung von Experimenten und die Operationalisierung zu beginnen. In Azure-Zielzonen kann Azure Machine Learning als Datenprodukt betrachtet werden.
Azure Machine Learning in Analysen auf Cloudebene
Eine Cloud Adoption Framework-Zielzonengrundlage (CAF), Datenzielzonen für Analysen auf Cloudebene und die Konfiguration von Azure Machine Learning richten Machine Learning-Experten mit einer vorkonfigurierten Umgebung ein, in der sie wiederholt neue Machine Learning-Workloads bereitstellen oder vorhandene Workloads migrieren können. Diese Funktionen können Machine Learning-Experten dabei helfen, die Flexibilität und den Nutzen für ihre aufgewendete Zeit zu erhöhen.
Die folgenden Entwurfsprinzipien können die Implementierung von Azure Machine Learning-Zielzonen leiten:
Beschleunigter Datenzugriff: Konfigurieren Sie Zielzonenspeicherkomponenten vorab als Datenspeicher im Azure Machine Learning-Arbeitsbereich.
Aktivierte Zusammenarbeit: Organisieren Sie Arbeitsbereiche nach Projekt, und zentralisieren Sie die Zugriffsverwaltung für Zielzonenressourcen, um die Zusammenarbeit von Experten für Datentechnik, Data Science und maschinelles Lernen zu unterstützen.
Sichere Implementierung: Befolgen Sie als Standard für jede Bereitstellung bewährte Methoden, und verwenden Sie die Netzwerkisolation, Identitäts- und Zugriffsverwaltung, um Datenressourcen zu schützen.
Self-Service: Machine Learning-Experten können durch die Erkundung von Optionen zur Bereitstellung neuer Projektressourcen mehr Flexibilität und Organisation erreichen.
Trennung von Zuständigkeiten zwischen Datenverwaltung und Datenverbrauch: Identitätspassthrough ist der Standardauthentifizierungstyp für Azure Machine Learning und Speicher.
Schnellere Datenanwendung (quellenorientiert): Azure Data Factory-, Azure Synapse Analytics- und Databricks-Zielzonen können vorab konfiguriert werden, um eine Verknüpfung mit Azure Machine Learning herzustellen.
Beobachtbarkeit: Zentrale Protokollierungs- und Referenzkonfigurationen können bei der Überwachung der Umgebung helfen.
Implementierungsübersicht
Hinweis
In diesem Abschnitt werden Konfigurationen empfohlen, die speziell für Analysen auf Cloudebene geeignet sind. Er ergänzt die Azure Machine Learning-Dokumentation und bewährte Cloud Adoption Framework-Methoden.
Arbeitsbereichsorganisation und -einrichtung
Sie können die Anzahl der Machine Learning-Arbeitsbereiche, die für Ihre Workloads erforderlich sind und für jede von Ihnen bereitgestellte Zielzone, bereitstellen. Die folgenden Empfehlungen können Ihnen bei der Einrichtung helfen:
Stellen Sie mindestens einen Machine Learning-Arbeitsbereich pro Projekt bereit.
Stellen Sie je nach Lebenszyklus Ihres Machine Learning-Projekts einen Entwicklungsarbeitsbereich für Prototypanwendungsfälle bereit, und untersuchen Sie Daten frühzeitig. Stellen Sie für Arbeit, die kontinuierliches Experimentieren, Testen und Bereitstellen erfordert, einen Staging- und Produktionsarbeitsbereich zur Verfügung.
Wenn mehrere Umgebungen für Entwicklungs-, Staging- und Produktionsarbeitsbereiche in einer Zielzone erforderlich sind, wird empfohlen, eine Datenduplizierung zu vermeiden, indem jede Umgebung in derselben Zielzone für Produktionsdaten positioniert wird.
Weitere Informationen zum Organisieren und Einrichten von Azure Machine Learning-Ressourcen finden Sie unter Organisieren und Einrichten von Azure Machine Learning-Umgebungen.
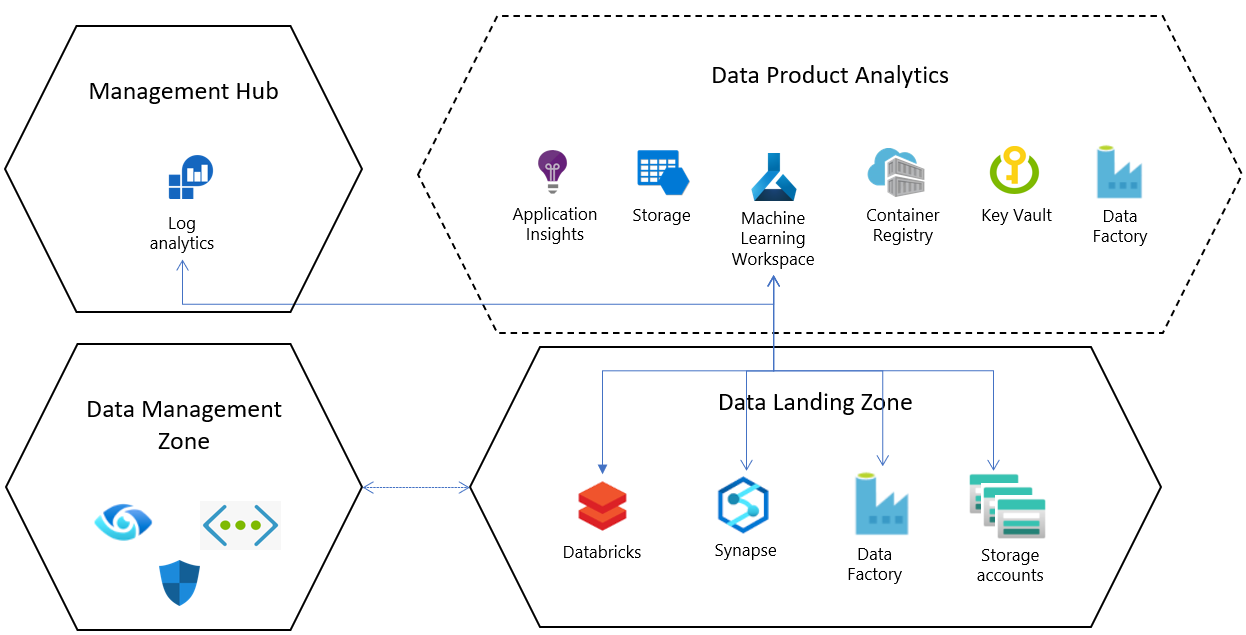
Für jede Standardressourcenkonfiguration in einer Datenzielzone wird eine Azure Machine Learning Service-Instanz in einer dedizierten Ressourcengruppe mit den folgenden Konfigurationen und abhängigen Ressourcen bereitgestellt:
- Azure-Schlüsseltresor
- Application Insights
- Azure Container Registry
- Verwenden Sie Azure Machine Learning, um eine Verbindung mit einem Azure Storage-Konto und der identitätsbasierten Authentifizierung von Microsoft Entra herzustellen, damit Benutzer*innen beim Herstellen einer Verbindung mit dem Konto unterstützt werden.
- Die Diagnoseprotokollierung wird für jeden Arbeitsbereich eingerichtet und für eine zentrale Log Analytics-Ressource auf Unternehmensebene konfiguriert. Dies kann dazu beitragen, dass Auftragsintegrität und Ressourcenstatus von Azure Machine Learning zentral innerhalb von Zielzonen sowie zielzonenübergreifend analysiert werden kann.
- Weitere Informationen zu Azure Machine Learning-Ressourcen und -Abhängigkeiten finden Sie unter Was ist ein Azure Machine Learning-Arbeitsbereich?.
Integration in Kerndienste für Datenzielzonen
Die Datenzielzone umfasst Standarddienste, die auf der Kerndienstebene bereitgestellt werden. Diese Kerndienste können konfiguriert werden, wenn Azure Machine Learning in einer Zielzone bereitgestellt wird.
Verbinden Sie Azure Synapse Analytics- oder Databricks-Arbeitsbereiche als verknüpfte Dienste, um Daten zu integrieren und Big Data zu verarbeiten.
Standardmäßig werden Data Lake-Dienste in der Datenzielzone bereitgestellt, und Azure Machine Learning-Produktbereitstellungen verfügen über Verbindungen (Datenspeicher), die für diese Speicherkonten vorkonfiguriert sind.
Netzwerkkonnektivität
Das Netzwerk für die Implementierung von Azure Machine Learning in Azure-Zielzonen wird mit den bewährten Sicherheitsmethoden für Azure Machine Learning und den bewährten CAF-Netzwerkmethoden eingerichtet. Zu diesen bewährten Methoden gehören die folgenden Konfigurationen:
- Azure Machine Learning und abhängige Ressourcen sind für die Verwendung von Private Link-Endpunkten konfiguriert.
- Verwaltete Computeressourcen werden nur mit privaten IP-Adressen bereitgestellt.
- Die Netzwerkkonnektivität zum öffentlichen Basisimagerepository von Azure Machine Learning und zu Partnerdiensten wie Azure Artifacts kann auf Netzwerkebene konfiguriert werden.
Identitäts- und Zugriffsverwaltung
Berücksichtigen Sie die folgenden Empfehlungen für die Verwaltung von Benutzeridentitäten und für den Zugriff mit Azure Machine Learning:
Datenspeicher in Azure Machine Learning können für die Verwendung der Authentifizierung auf Basis von Identitäten oder Anmeldeinformationen konfiguriert werden. Wenn Sie die Zugriffssteuerung und Data Lake-Konfigurationen in Azure Data Lake Storage Gen2 verwenden, konfigurieren Sie die Datenspeicher so, dass sie die identitätsbasierte Authentifizierung verwenden. Dadurch kann Azure Machine Learning die Zugriffsberechtigungen der Benutzer für den Speicher optimieren.
Verwenden Sie Microsoft Entra-Gruppen zum Verwalten von Benutzerberechtigungen für Speicher- und Machine Learning-Ressourcen.
Azure Machine Learning kann benutzerseitig zugewiesene verwaltete Identitäten für die Zugriffssteuerung verwenden und den Zugriffsbereich auf Azure Container Registry, Key Vault, Azure Storage und Application Insights einschränken.
Erstellen Sie benutzerseitig zugewiesene verwaltete Identitäten für verwaltete Computecluster, die in Azure Machine Learning erstellt wurden.
Bereitstellen der Infrastruktur über Self-Service
Self-Service kann aktiviert und mit Richtlinien für Azure Machine Learning gesteuert werden. In der folgenden Tabelle sind Standardrichtlinien aufgeführt, wenn Sie Azure Machine Learning bereitstellen. Weitere Informationen finden Sie unter Integrierte Azure Policy-Richtliniendefinitionen für Azure Machine Learning.
| Policy | type | Verweis |
|---|---|---|
| Azure Machine Learning-Arbeitsbereiche sollten Azure Private Link verwenden. | Integriert | Ansicht im Azure-Portal |
| Azure Machine Learning-Arbeitsbereiche sollten benutzerseitig zugewiesene verwaltete Identitäten verwenden. | Integriert | Ansicht im Azure-Portal |
| [Vorschau]: Konfigurieren Sie zulässige Registrierungen für angegebene Azure Machine Learning-Computeressourcen. | Integriert | Ansicht im Azure-Portal |
| Konfigurieren Sie Azure Machine Learning-Arbeitsbereiche mit privaten Endpunkten. | Integriert | Ansicht im Azure-Portal |
| Konfigurieren Sie Machine Learning-Computeressourcen zum Deaktivieren lokaler Authentifizierungsmethoden. | Integriert | Ansicht im Azure-Portal |
| Append-machinelearningcompute-setupscriptscreationscript | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearning-hbiworkspace | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearning-publicaccesswhenbehindvnet | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearning-AKS | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearningcompute-subnetid | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearningcompute-vmsize | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
| Deny-machinelearningcomputecluster-scale | Benutzerdefiniert (CAF-Zielzonen) | In GitHub anzeigen |
Empfehlungen für die Verwaltung Ihrer Umgebung
Datenzielzonen für Analysen auf Cloudebene beschreiben die Referenzimplementierung für wiederholbare Bereitstellungen, die Ihnen helfen können, verwaltbare und steuerbare Umgebungen festzulegen. Berücksichtigen Sie die folgenden Empfehlungen für die Verwendung von Azure Machine Learning zum Verwalten Ihrer Umgebung:
Verwenden Sie Microsoft Entra-Gruppen, um den Zugriff auf Machine Learning-Ressourcen zu verwalten.
Veröffentlichen Sie ein zentrales Überwachungsdashboard, um die Integrität von Pipelines, die Computeauslastung und die Kontingentverwaltung für maschinelles Lernen zu überwachen.
Wenn Sie traditionell integrierte Azure-Richtlinien verwenden und zusätzliche Complianceanforderungen erfüllen müssen, erstellen Sie benutzerdefinierte Azure-Richtlinien, um Governance und Self-Service zu verbessern.
Um die Kosten für Forschung und Entwicklung nachzuverfolgen, stellen Sie in den frühen Phasen der Untersuchung Ihres Anwendungsfalls einen Machine Learning-Arbeitsbereich in der Zielzone als freigegebene Ressource bereit.
Wichtig
Verwenden Sie die Azure Machine Learning-Cluster für das Modelltraining auf Produktionsqualität und den Azure Kubernetes Service (AKS) für Bereitstellungen auf Produktionsqualität.
Tipp
Verwenden Sie das Azure Machine Learning für Data Science-Projekte. Es deckt den End-to-End-Workflow mit untergeordneten Diensten und Features ab und ermöglicht eine vollständige Automatisierung des Prozesses.
Nächste Schritte
Verwenden Sie die Data Product Analysis-Vorlage und den Leitfaden, um Azure Machine Learning bereitzustellen, und lesen Sie die Azure Machine Learning-Dokumentation und die Tutorials, um mit dem Erstellen Ihrer Lösungen zu beginnen.
Fahren Sie mit den folgenden vier Cloud Adoption Framework-Artikeln fort, um mehr über die Azure Machine Learning-Bereitstellung und die bewährten Methoden für die Verwaltung für Unternehmen zu erfahren:
Organisieren und Einrichten von Azure Machine Learning-Umgebungen: Wie wirken sich bei der Planung einer Bereitstellung von Azure Machine Learning Teamstrukturen, Umgebungen oder die Geografie von Ressourcen auf die Einrichtung von Arbeitsbereichen aus?
Bewährte Azure Machine Learning-Methoden für die Unternehmenssicherheit: Erfahren Sie, wie Sie Ihre Umgebung und Ressourcen mit Azure Machine Learning schützen.
Verwalten von Budgets, Kosten und Kontingenten für Azure Machine Learning auf Organisationsebene: Organisationen stehen vor vielen Herausforderungen bei der Verwaltung und Optimierung von Workload-, Team- und Benutzercomputekosten, die durch Azure Machine Learning entstehen.
DevOps für maschinelles Lernen (MLOps) – ein Leitfaden: Der Ansatz „DevOps für maschinelles Lernen“ umfasst organisationsbezogene Änderungen, die auf einer Kombination von Personen, Prozessen und Technologien basieren, um stabile, skalierbare, zuverlässige und automatisierte Lösungen für das maschinelle Lernen bereitzustellen. Dieser Leitfaden fasst bewährte Methoden und Informationen für Unternehmen zusammen, um Azure Machine Learning für die Einführung von Machine Learning-DevOps zu verwenden.