Abrufen von Daten aus Azure Storage
Die Datenerfassung ist der Prozess, der zum Laden von Daten aus einer oder mehreren Quellen in eine Tabelle in Azure Data Explorer verwendet wird. Nach der Erfassung sind die Daten für Abfragen verfügbar. In diesem Artikel erfahren Sie, wie Sie Daten aus Azure Storage (ADLS Gen2-Container, Blobcontainer oder einzelne Blobs) in eine neue oder vorhandene Tabelle abrufen.
Die Erfassung kann als einmaliger Vorgang oder als kontinuierliche Methode erfolgen. Die fortlaufende Erfassung kann nur über das Portal konfiguriert werden.
Allgemeine Informationen zur Datenerfassung finden Sie unter Azure Data Explorer Übersicht über die Datenerfassung.
Voraussetzungen
- Ein Microsoft-Konto oder eine Microsoft Entra Benutzeridentität. Ein Azure-Abonnement ist nicht erforderlich.
- Melden Sie sich bei der Azure Data Explorer-Webbenutzeroberfläche an.
- Schnellstart: Erstellen eines Azure Data Explorer-Clusters und einer Datenbank. Erstellen eines Clusters und einer Datenbank
- Ein Speicherkonto.
Abrufen von Daten
Wählen Sie im linken Menü die Option Abfrage aus.
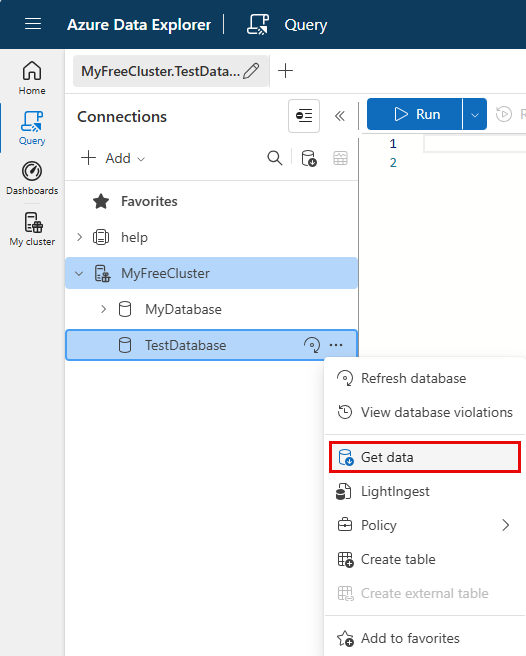
Klicken Sie mit der rechten Maustaste auf die Datenbank, in der Sie die Daten erfassen möchten. Wählen Sie Daten abrufen aus.

Quelle
Im Fenster Daten abrufen ist die Registerkarte Quelle ausgewählt.
Wählen Sie die Datenquelle aus der liste verfügbar aus. In diesem Beispiel erfassen Sie Daten aus Azure Storage.

Konfigurieren
Wählen Sie eine Zieldatenbank und -tabelle aus. Wenn Sie Daten in einer neuen Tabelle erfassen möchten, wählen Sie + Neue Tabelle aus, und geben Sie einen Tabellennamen ein.
Hinweis
Tabellennamen können bis zu 1024 Zeichen umfassen, einschließlich Leerzeichen, alphanumerischer Zeichen, Bindestrichen und Unterstrichen. Sonderzeichen werden nicht unterstützt.
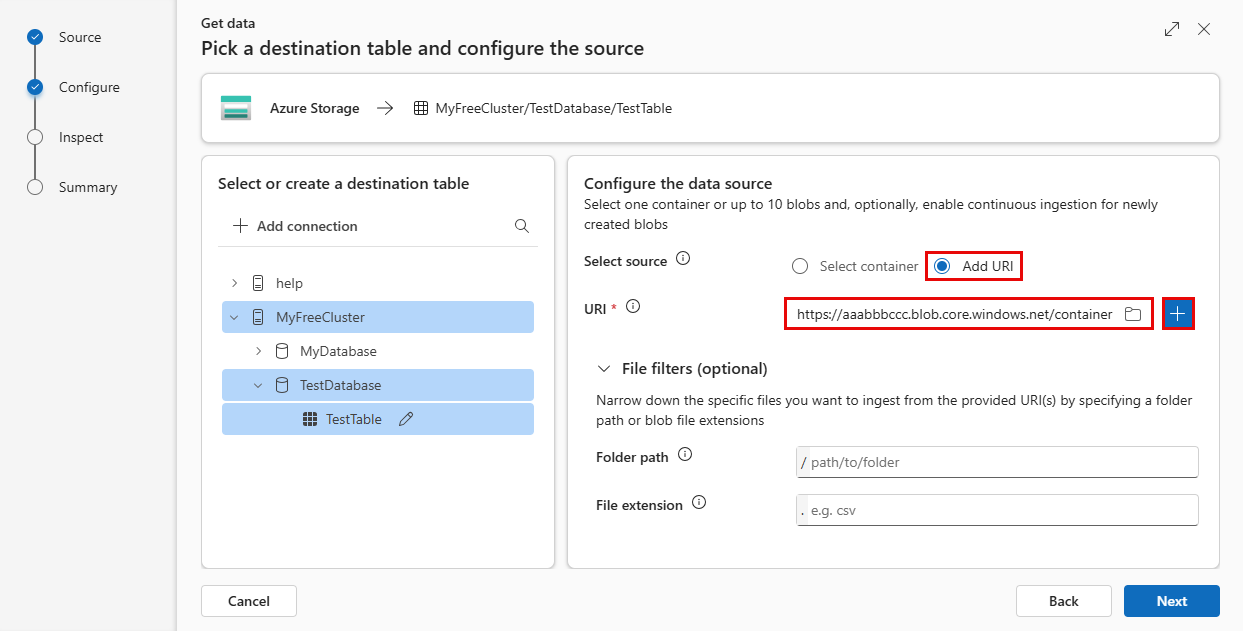
Um Ihre Quelle hinzuzufügen, wählen Sie Container auswählen oder URI hinzufügen aus.
Wenn Sie Container auswählen ausgewählt haben, füllen Sie die folgenden Felder aus:
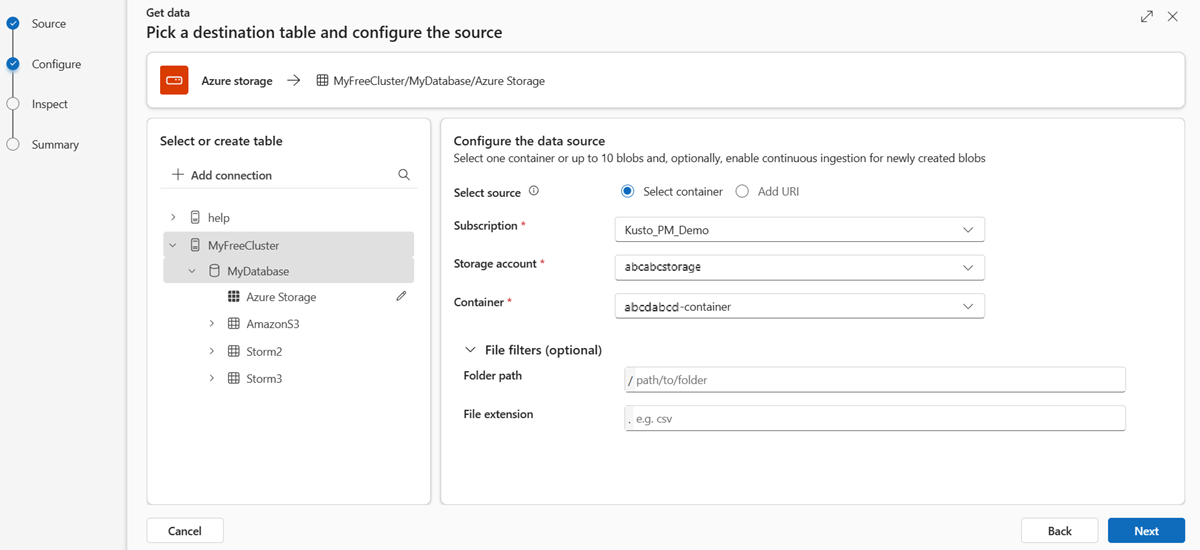
Einstellung Feldbeschreibung Subscription Die Abonnement-ID, in der sich das Speicherkonto befindet. Speicherkonto Der Name, der Ihr Speicherkonto identifiziert. Container Der Speichercontainer, den Sie erfassen möchten. Dateifilter (optional) Ordnerpfad Filtert Daten, um Dateien mit einem bestimmten Ordnerpfad zu erfassen. Dateierweiterung Filtert Daten nur, um Dateien mit einer bestimmten Dateierweiterung zu erfassen. Wenn Sie URI hinzufügen ausgewählt haben, fügen Sie Ihren Speicher Verbindungszeichenfolge für einen Blobcontainer oder einzelne Dateien in das URI-Feld ein, und wählen Sie dann aus+.
Hinweis
- Sie können bis zu 10 einzelne Blobs hinzufügen. Jedes Blob kann maximal 1 GB unkomprimiert sein.
- Sie können bis zu 5.000 Blobs aus einem einzelnen Container erfassen.
Wählen Sie Weiter aus.


Überprüfen
Die Registerkarte Überprüfen wird mit einer Vorschau der Daten geöffnet.
Um den Erfassungsprozess abzuschließen, wählen Sie Fertig stellen aus.

Optional:
- Wählen Sie Befehlsanzeige aus, um die automatischen Befehle anzuzeigen und zu kopieren, die aus Ihren Eingaben generiert wurden.
- Verwenden Sie die Dropdownliste Schemadefinitionsdatei , um die Datei zu ändern, aus der das Schema abgeleitet wird.
- Ändern Sie das automatisch abgeleitete Datenformat, indem Sie das gewünschte Format aus der Dropdownliste auswählen. Informationen zur Erfassung finden Sie unter Von Azure Data Explorer unterstützte Datenformate.
- Spalten bearbeiten.
- Erkunden Sie erweiterte Optionen basierend auf dem Datentyp.
Spalten bearbeiten
Hinweis
- Bei tabellenbasierten Formaten (CSV, TSV, PSV) können Sie eine Spalte nicht zweimal zuordnen. Löschen Sie bei einer Zuordnung zu einer vorhandenen Spalte zunächst die neue Spalte.
- Der Typ einer vorhandenen Spalte kann nicht geändert werden. Wenn Sie als Zuordnungsziel eine Spalte mit einem anderen Format verwenden, erhalten Sie ggf. leere Spalten.
Die Änderungen, die Sie an einer Tabelle vornehmen können, hängen von den folgenden Parametern ab:
- Die Tabelle ist neu oder vorhanden.
- Die Zuordnung ist neu oder vorhanden.
| Tabellentyp | Zuordnungstyp | Verfügbare Anpassungen |
|---|---|---|
| Neue Tabelle | Neue Zuordnung | Spalte umbenennen, Datentyp ändern, Datenquelle ändern, Zuordnungstransformation, Spalte hinzufügen, Spalte löschen |
| Vorhandene Tabelle | Neue Zuordnung | Spalte hinzufügen (in der Sie den Datentyp ändern, umbenennen und aktualisieren können) |
| Vorhandene Tabelle | Vorhandene Zuordnung | Keine |

Zuordnungstransformationen
Einige der Datenformatzuordnungen (Parquet, JSON und Avro) unterstützen einfache Transformationen während der Erfassung. Um Zuordnungstransformationen anzuwenden, erstellen oder aktualisieren Sie eine Spalte im Fenster Spalten bearbeiten .
Zuordnungstransformationen können für eine Spalte vom Typ string oder datetime ausgeführt werden, wobei die Quelle den Datentyp "int" oder "long" aufweist. Die folgenden Zuordnungstransformationen werden unterstützt:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Erweiterte Optionen basierend auf dem Datentyp
Tabellarisch (CSV, TSV, PSV):
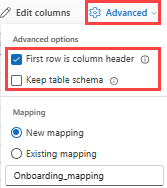
Wenn Sie tabellarische Formate in einer vorhandenen Tabelle erfassen, können Sie Erweitertes>Tabellenschema beibehalten auswählen. Tabellendaten enthalten nicht unbedingt die Spaltennamen, die verwendet werden, um Quelldaten den vorhandenen Spalten zuzuordnen. Wenn diese Option aktiviert ist, erfolgt die Zuordnung nach Reihenfolge, und das Tabellenschema bleibt unverändert. Wenn diese Option deaktiviert ist, werden unabhängig von der Datenstruktur neue Spalten für eingehende Daten erstellt.
Um die erste Zeile als Spaltennamen zu verwenden, wählen Sie Erweiterte>erste Zeile ist Spaltenüberschrift aus.
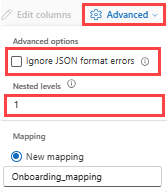
JSON:
Um die Spaltenteilung von JSON-Daten zu bestimmen, wählen Sie Erweiterte>geschachtelte Ebenen von 1 bis 100 aus.
Wenn Sie Erweiterte>Datenformatfehler ignorieren auswählen, werden die Daten im JSON-Format erfasst. Wenn Sie das Kontrollkästchen nicht aktivieren, werden die Daten im MultiJSON-Format erfasst.
Zusammenfassung
Im Fenster Datenaufbereitung sind alle drei Schritte mit grünen Häkchen gekennzeichnet, wenn die Datenerfassung erfolgreich abgeschlossen wurde. Sie können die Befehle anzeigen, die für jeden Schritt verwendet wurden, oder einen Karte auswählen, um die erfassten Daten abzufragen, zu visualisieren oder zu löschen.

Verwandte Inhalte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für