Zuordnungsdatenflüsse in Azure Data Factory
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Was sind Zuordnungsdatenflüsse?
Mapping Data Flows (Zuordnungsdatenflüsse) sind visuell entworfene Datentransformationen in Azure Data Factory. Mit Datenflüssen können Data Engineers eine Datentransformationslogik entwickeln, ohne Code schreiben zu müssen. Die daraus resultierenden Datenflüsse werden als Aktivitäten in Azure Data Factory-Pipelines ausgeführt, für die erweiterte Apache Spark-Cluster verwendet werden. Datenflussaktivitäten können mithilfe vorhandener Planungs-, Steuerungs-, Fluss- und Überwachungsfunktionen in Data Factory operationalisiert werden.
Zuordnungsdatenflüsse bieten eine vollständig visuelle Darstellung, ohne Code geschrieben werden muss. Ihre Datenflüsse werden in ADF-verwalteten Ausführungsclustern für erweiterte Datenverarbeitung ausgeführt. Azure Data Factory übernimmt die gesamte Codeübersetzung, Pfadoptimierung und Ausführung Ihrer Datenflussaufträge.
Erste Schritte
Datenflüsse werden über den Bereich mit Factory-Ressourcen wie Pipelines und Datasets erstellt. Wählen Sie zum Erstellen eines Datenflusses das Pluszeichen neben Factory-Ressourcen und dann die Option Datenfluss aus.
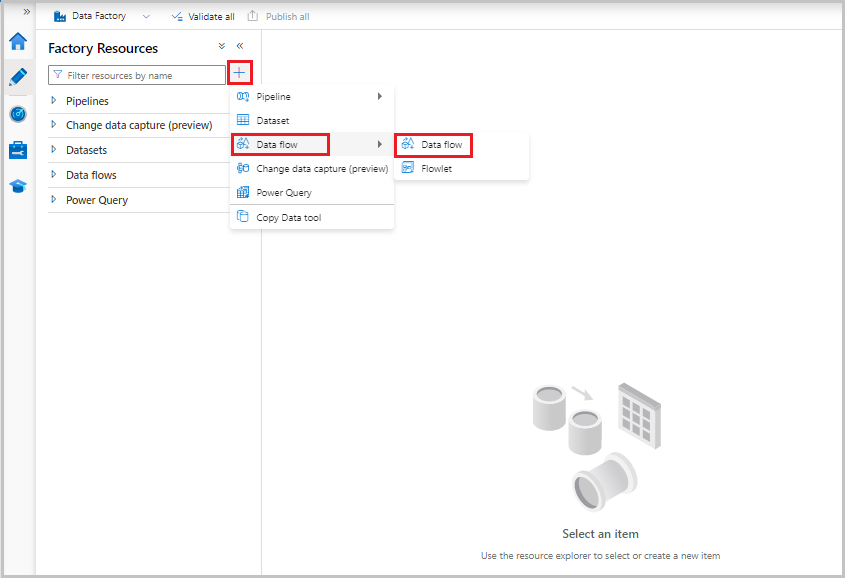 Mit dieser Aktion gelangen Sie zur Datenflusscanvas, auf der Sie Ihre Transformationslogik erstellen können. Wählen Sie Quelle hinzufügen aus, um mit der Konfiguration Ihrer Quelltransformation zu beginnen. Weitere Informationen finden Sie im Artikel zur Quelltransformation.
Mit dieser Aktion gelangen Sie zur Datenflusscanvas, auf der Sie Ihre Transformationslogik erstellen können. Wählen Sie Quelle hinzufügen aus, um mit der Konfiguration Ihrer Quelltransformation zu beginnen. Weitere Informationen finden Sie im Artikel zur Quelltransformation.
Erstellen von Datenflüssen
Ein Zuordnungsdatenfluss verfügt über einen einzigartigen Erstellungsbereich für das vereinfachte Erstellen von Transformationslogik. Die Datenflusscanvas ist in drei Bereiche unterteilt: die obere Leiste, das Diagramm und den Konfigurationsbereich.
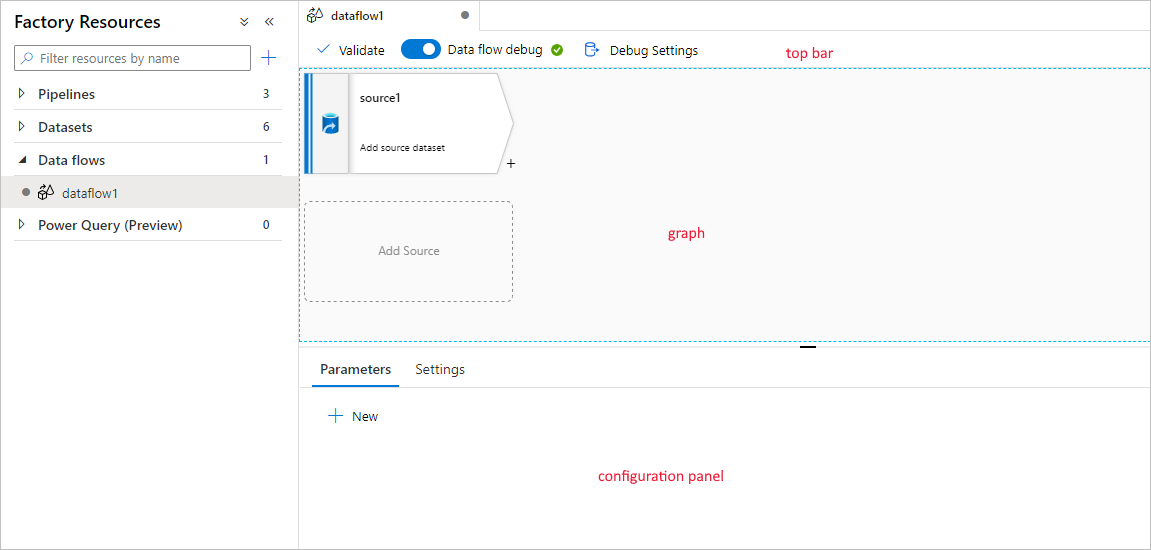
Graph
Das Diagramm zeigt den Transformationsdatenstrom. Es zeigt die Herkunft der Quelldaten beim Fließen in eine oder mehrere Senken. Senken können alle Datenquellenziele sein, an die Sie die Ergebnisse Ihrer transformierten Daten verschieben möchten. Wählen Sie die Option Quelle hinzufügen aus, um eine neue Quelle hinzuzufügen. Wählen Sie zum Hinzufügen einer neuen Transformation unten rechts in einer vorhandenen Transformation das Pluszeichen aus. Informieren Sie sich über das Verwalten des Datenflussdiagramms.
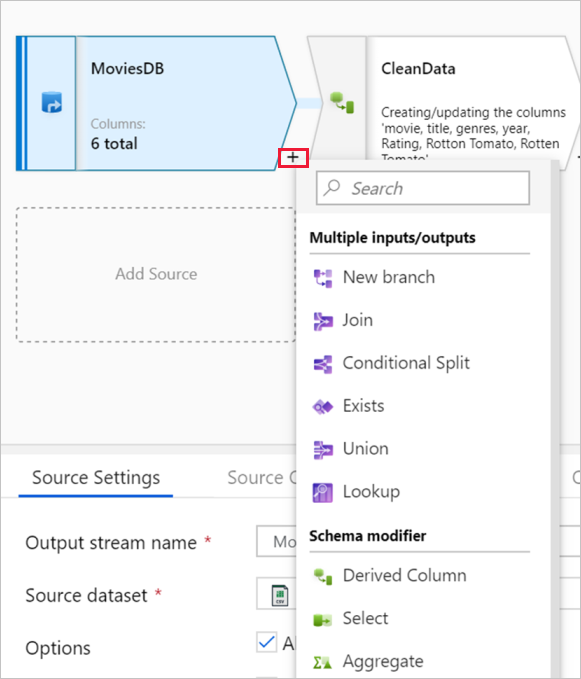
Konfigurationsbereich
Im Konfigurationsbereich werden die spezifischen Einstellungen für die derzeit ausgewählte Transformation angezeigt. Wenn keine Transformation ausgewählt ist, wird der Datenfluss angezeigt. In der allgemeinen Datenflusskonfiguration können Sie Parameter über die Registerkarte Parameter hinzufügen. Weitere Informationen finden Sie unter Mapping Data Flow-Parameter.
Jede Transformation enthält mindestens vier Registerkarten für die Konfiguration.
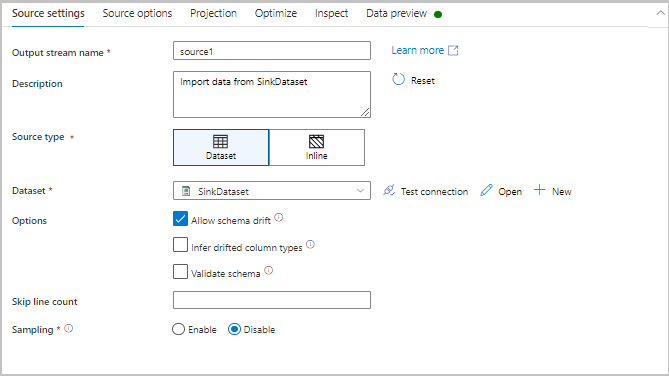
Transformationseinstellungen
Die erste Registerkarte im Konfigurationsbereich jeder Transformation enthält die Einstellungen, die für diese Transformation spezifisch sind. Weitere Informationen finden Sie auf der Dokumentationsseite für diese Transformation.
Optimieren
Die Registerkarte Optimieren enthält Einstellungen zum Konfigurieren von Partitionierungsschemas. Weitere Informationen zum Optimieren Ihrer Datenflüsse finden Sie in der Anleitung zur Leistung des Zuordnungsdatenflusses.
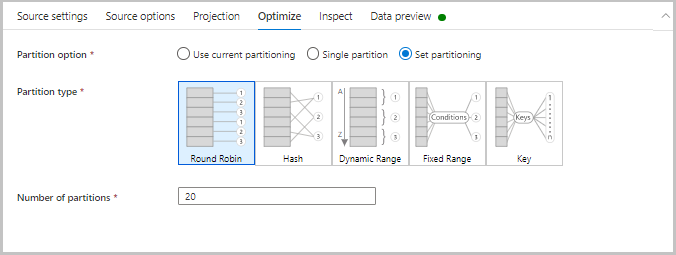
Überprüfen
Die Registerkarte Überprüfen bietet einen Einblick in die Metadaten des Datenstroms, den Sie transformieren. Sie können die Spaltenanzahl, geänderte Spalten, hinzugefügte Spalten, Datentypen, die Spaltensortierung und Spaltenverweise sehen. Überprüfen ist eine schreibgeschützte Ansicht Ihrer Metadaten. Der Debugmodus muss nicht aktiviert sein, um die Metadaten im Bereich Überprüfen anzeigen zu können.
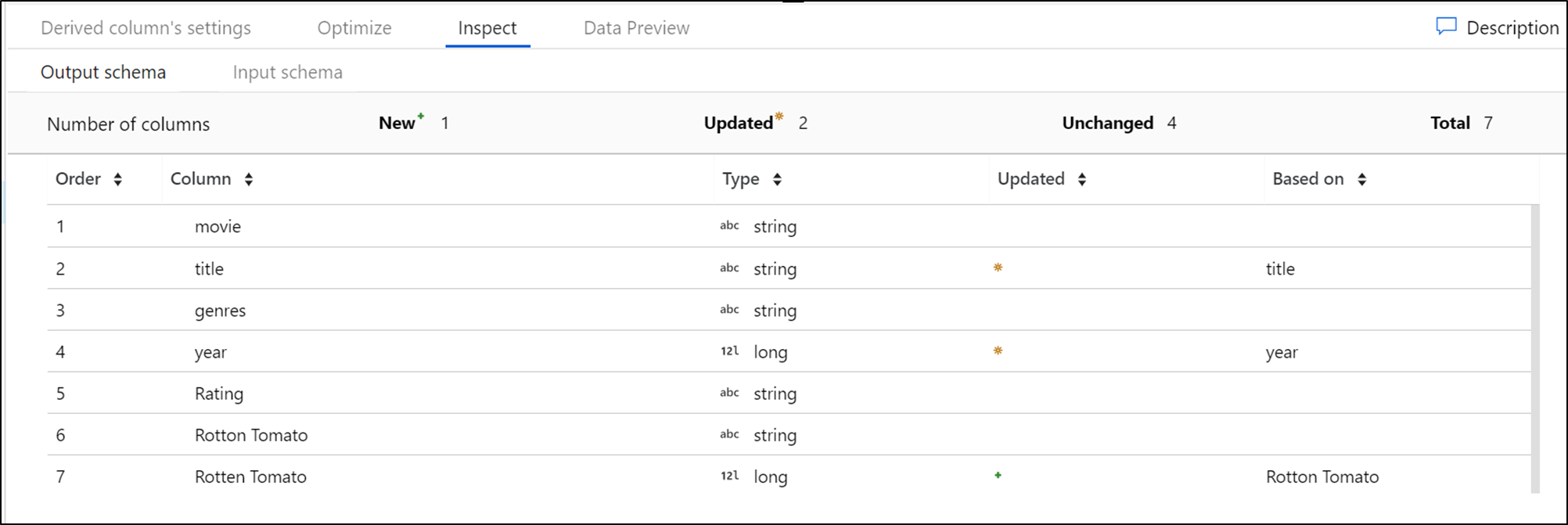
Wenn Sie die Form Ihrer Daten durch Transformationen ändern, wird der Fluss der Metadatenänderungen im Bereich Überprüfen angezeigt. Falls in Ihrer Quelltransformation kein definiertes Schema vorhanden ist, werden im Bereich Überprüfen keine Metadaten angezeigt. Fehlende Metadaten kommen in Schemaabweichungsszenarien häufiger vor.
Datenvorschau
Bei aktiviertem Debugmodus können Sie auf der Registerkarte Datenvorschau eine interaktive Momentaufnahme der Daten bei jeder Transformation anzeigen. Weitere Informationen finden Sie unter Datenvorschau im Debugmodus.
Obere Leiste
Die obere Leiste enthält Aktionen, die sich auf den gesamten Datenfluss auswirken, z. B. das Speichern und Überprüfen. Sie können auch den zugrunde liegenden JSON-Code und das Datenflussskript Ihrer Transformationslogik anzeigen. Weitere Informationen finden Sie unter Datenflussskript.
Verfügbare Transformationen
Unter Zuordnungsdatenfluss – Übersicht über Transformationen finden Sie eine Liste der verfügbaren Transformationen.
Datenfluss-Datentypen
- array
- BINARY
- boolean
- complex
- Dezimal (einschließlich Genauigkeit)
- Datum
- float
- integer
- long
- Karte
- short
- Zeichenfolge
- timestamp
Datenflussaktivität
Zuordnungsdatenflüsse werden innerhalb von ADF-Pipelines mithilfe der Datenflussaktivität operationalisiert. Der Benutzer muss lediglich angeben, welche Integration Runtime verwendet werden soll, und Parameterwerte übergeben. Weitere Informationen finden Sie unter Azure Integration Runtime.
Debugmodus
Im Debugmodus können Sie die Ergebnisse jedes Transformationsschritts interaktiv anzeigen, während Sie Datenflüsse erstellen und debuggen. Die Debugsitzung kann sowohl beim Erstellen der Datenflusslogik als auch beim Ausführen von Debugläufen für die Pipeline mit Datenflussaktivitäten ausgeführt werden. Weitere Informationen finden Sie in der Dokumentation zum Debugmodus.
Überwachen von Datenflüssen
Der Zuordnungsdatenfluss ist in vorhandene Azure Data Factory-Überwachungsfunktionen integriert. Informationen zum Verständnis der Ausgabe der Datenflussüberwachung finden Sie unter Überwachen von Zuordnungsdatenflüssen.
Das Azure Data Factory-Team hat eine Anleitung zur Leistungsoptimierung erstellt, mit deren Hilfe Sie die Ausführungszeit Ihrer Datenflüsse nach dem Erstellen der Geschäftslogik optimieren können.
Zugehöriger Inhalt
- Informieren Sie sich über die Erstellung einer Quelltransformation.
- Informieren Sie sich darüber, wie Sie Ihre Datenflüsse im Debugmodus erstellen.