Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Datenflüsse sind sowohl in Azure Data Factory Pipelines als auch in Azure Synapse Analytics Pipelines verfügbar. Dieser Artikel gilt für Datenflusszuordnungen. Wenn Sie mit Transformationen noch nicht fertig sind, lesen Sie den einführungsartikel Transformieren von Daten mithilfe von Zuordnungsdatenflüssen.
Tipp
Informationen zur entsprechenden Transformation (Get Data) in Dataflow Gen2 finden Sie in einer Anleitung zu Dataflow Gen2 zum Zuordnen von Datenflussbenutzern.
Mit einer Quelltransformation wird die Datenquelle für den Datenfluss konfiguriert. Beim Entwerfen von Datenflüssen besteht der erste Schritt stets in der Konfiguration einer Quelltransformation. Um eine Quelle hinzuzufügen, wählen Sie auf der Datenflusscanvas das Feld Quelle hinzufügen aus.
Jeder Datenfluss erfordert mindestens eine Quelltransformation, aber Sie können so viele Quellen wie erforderlich hinzufügen, um Ihre Datentransformationen abzuschließen. Sie können diese Quellen zusammen mit einer Join-, Lookup- oder Union-Transformation verwenden.
Jede Quelltransformation ist genau einem Dataset oder einem verknüpften Dienst zugeordnet. Das Dataset definiert die Form und Position der Daten, in die geschrieben oder aus denen gelesen werden soll. Wenn Sie ein dateibasiertes Dataset verwenden, können Sie Platzhalter und Dateilisten in Ihrer Quelle verwenden, um mit mehreren Dateien gleichzeitig zu arbeiten.
Inlinedatasets
Die erste Entscheidung, die Sie beim Erstellen einer Quelltransformation treffen, ist die, ob Ihre Quellinformationen innerhalb eines Datasetobjekts oder innerhalb der Quelltransformation definiert sind. Die meisten Formate sind nur in einem von beiden verfügbar. Weitere Informationen zur Verwendung eines bestimmten Connectors finden Sie im Dokument zu diesem Connector.
Wenn ein Format sowohl für Inline- als auch in einem Datasetobjekt unterstützt wird, ergeben sich Vorteile für beide. Datasetobjekte sind wiederverwendbare Entitäten, die in anderen Datenflüssen und Aktivitäten wie Kopiervorgängen genutzt werden können. Diese wiederverwendbaren Entitäten sind besonders nützlich, wenn Sie ein verstärktes Schema verwenden. Datasets befinden sich nicht in Spark. Gelegentlich müssen Sie bestimmte Einstellungen oder Schemaprojektionen in der Quelltransformation überschreiben.
Inline-Datasets werden empfohlen, wenn flexible Schemas, einmalige Quellinstanzen oder parametrisierte Quellen verwendet werden. Wenn Ihre Quelle stark parametrisiert ist, können Sie mit Inline-Datasets kein „Dummy“-Objekt erstellen. Inline-Datasets befinden sich in Spark, und ihre Eigenschaften sind für den Datenfluss nativ.
Um ein Inline-Dataset zu verwenden, wählen Sie das gewünschte Format im Selektor Quelltyp aus. Anstatt ein Quelldataset auszuwählen, wählen Sie den verknüpften Dienst aus, mit dem Sie eine Verbindung herstellen möchten.
Schemaoptionen
Da ein Inline-Dataset innerhalb des Datenflusses definiert wird, ist dem Inline-Dataset kein definiertes Schema zugeordnet. Auf der Registerkarte „Projektion“ können Sie das Quelldatenschema importieren und dieses Schema als Quellprojektion speichern. Auf dieser Registerkarte finden Sie die Schaltfläche „Schemaoptionen“, mit der Sie das Verhalten des Schemaermittlungsdiensts von ADF definieren können.
- Projiziertes Schema verwenden: Diese Option ist nützlich, wenn Sie über eine große Anzahl von Quelldateien verfügen, die ADF als Quelle scannen wird. Standardmäßig wird ADF das Schema jeder Quelldatei ermitteln. Wenn Sie jedoch bereits eine vordefinierte Projektion in Ihrer Quelltransformation gespeichert haben, können Sie dies auf TRUE festlegen, damit ADF die automatische Ermittlung jedes Schemas überspringt. Wenn diese Option aktiviert ist, kann die Quelltransformation alle Dateien viel schneller lesen, da sie das vordefinierte Schema auf jede Datei anwendet.
- Schemaabweichung zulassen: Aktivieren Sie die Schemaabweichung, sodass Ihr Datenfluss neue Spalten zulässt, die noch nicht im Quellschema definiert sind.
- Schema überprüfen: Durch das Festlegen dieser Option wird beim Datenfluss ein Fehler ausgelöst, wenn eine in der Projektion definierte Spalte und ein Typ nicht mit dem erkannten Schema der Quelldaten übereinstimmen.
- Abweichende Spaltentypen ableiten: Wenn neue abweichende Spalten von ADF identifiziert werden, werden diese neuen Spalten mit dem automatischen Typrückschluss von ADF in den entsprechenden Datentyp umgewandelt.
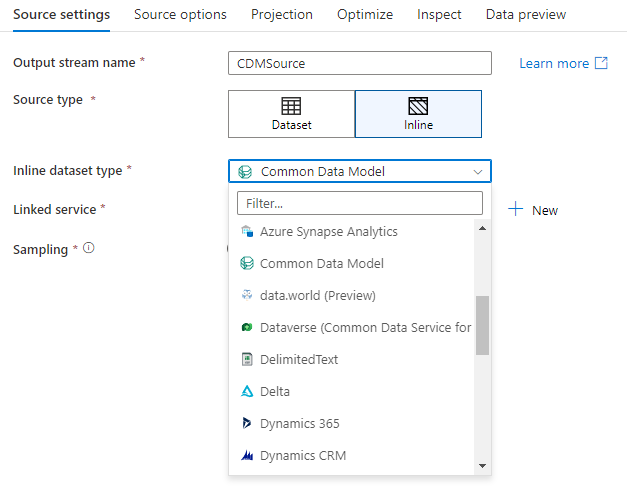
Workspace DB (nur Synapse-Arbeitsbereiche)
In Azure Synapse Arbeitsbereichen ist eine zusätzliche Option in Datenflussquellentransformationen vorhanden, die als Workspace DB bezeichnet werden. Dies ermöglicht Ihnen, eine Arbeitsbereichsdatenbank jedes verfügbaren Typs als Ihre Quelldaten auszuwählen, ohne dass zusätzliche verknüpfte Dienste oder Datasets erforderlich sind. Auf die datenbanken, die über die datenbankvorlagen Azure Synapse erstellt wurden, kann auch zugegriffen werden, wenn Sie "Arbeitsbereich DB" auswählen.
Unterstützte Quelltypen
Der Zuordnungsdatenfluss folgt einem Ansatz zum Extrahieren, Laden und Transformieren (ELT) und funktioniert mit Stagingdatasets in Azure. Derzeit können die folgenden Datasets in einer Quelltransformation verwendet werden.
Die für diese Connectors spezifischen Einstellungen befinden sich auf der Registerkarte Quelloptionen. Informationen und Beispiele zu Datenflussskripts zu diesen Einstellungen finden Sie in der Connectordokumentation.
Azure Data Factory- und Synapse-Pipelines haben Zugriff auf mehr als 90 native Connectors. Um Daten aus diesen anderen Quellen in Ihren Datenfluss einzubeziehen, verwenden Sie die Kopieraktivität, um die Daten in einen der unterstützten Stagingbereiche zu laden.
Quelleinstellungen
Nachdem Sie eine Quelle hinzugefügt haben, konfigurieren Sie sie auf der Registerkarte Quelleinstellungen. Hier können Sie das Dataset auswählen oder erstellen, auf das Ihre Quelle verweist. Sie können auch das Schema und die Samplingoptionen für Ihre Daten auswählen.
Entwicklungswerte für Datasetparameter können in Debugeinstellungen konfiguriert werden. (Der Debugmodus muss aktiviert sein.)
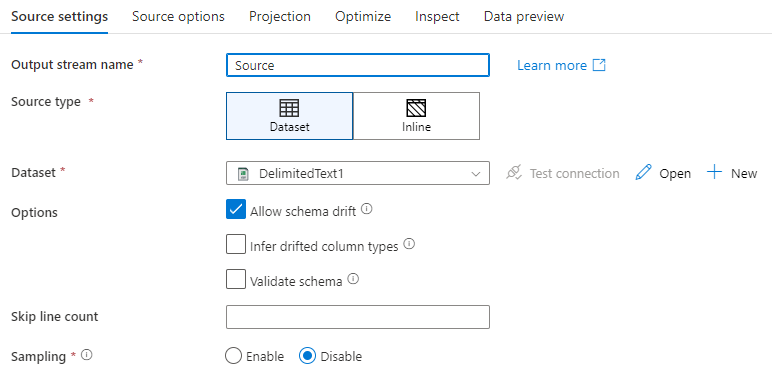
Name des Ausgabedatenstroms: Der Name der Quelltransformation.
Quellentyp: Wählen Sie aus, ob Sie ein Inline-Dataset oder ein bestehendes Datasetobjekt verwenden möchten.
Verbindung testen: Testen Sie, ob der Spark-Dienst des Datenflusses erfolgreich eine Verbindung mit dem verknüpften Dienst herstellen kann, der in Ihrem Quelldataset verwendet wird. Damit diese Funktion aktiviert werden kann, muss der Debugmodus aktiviert sein.
Schemaabweichung: Schemaabweichung ist die Fähigkeit des Diensts, flexible Schemas in Ihren Datenflüssen nativ zu verarbeiten, ohne Spaltenänderungen explizit definieren zu müssen.
Aktivieren Sie das Kontrollkästchen Schemaabweichung zulassen, wenn die Quellspalten sich häufig ändern. Diese Einstellung ermöglicht es, dass alle eingehenden Quellfelder durch die Transformationen zur Senke fließen.
Durch Aktivieren von Abweichende Spaltentypen ableiten wird der Dienst angewiesen, Datentypen für jede neue erkannte Spalte zu ermitteln und zu definieren. Wenn dieses Feature deaktiviert ist, weisen alle verschobenen Spalten den Datentyp „string“ auf.
Schema validieren: Ist Schema validieren ausgewählt, schlägt der Datenfluss fehl, wenn die eingehenden Quelldaten nicht mit dem definierten Schema des Datasets übereinstimmen.
Anzahl zu überspringender Zeilen: Das Feld Anzahl zu überspringender Zeilen gibt an, wie viele Zeilen am Anfang des Datasets ignoriert werden sollen.
Stichprobenerstellung: Aktivieren Sie Sampling, um die Anzahl der Zeilen aus der Quelle zu beschränken. Verwenden Sie diese Einstellung, wenn Sie für das Debuggen Stichproben der Daten an der Quelle erstellen möchten. Dies ist beim Ausführen von Datenflüssen im Debugmodus über eine Pipeline sehr nützlich.
Um zu überprüfen, ob die Quelle ordnungsgemäß konfiguriert ist, aktivieren Sie den Debugmodus, und rufen Sie eine Datenvorschau ab. Weitere Informationen finden Sie unter Debugmodus.
Hinweis
Wenn der Debugmodus aktiviert ist, überschreibt die Konfiguration für das Zeilenlimit in den Debugeinstellungen bei der Datenvorschau die Einstellung für die Stichprobenentnahme in der Quelle.
Quelloptionen
Die Registerkarte Quelloptionen enthält Einstellungen, die spezifisch für den gewählten Connector und das gewählte Format sind. Weitere Informationen und Beispiele finden Sie in der entsprechenden Connectordokumentation. Dies umfasst Details wie die Isolationsstufe für diejenigen Datenquellen, die es unterstützen (z. B. lokale SQL Server, Azure SQL-Datenbanken und Azure SQL Managed Instances), sowie andere spezifische Einstellungen für die jeweilige Datenquelle.
Projektion
Wie Schemas in Datasets definiert die Projektion in einer Quelle die Datenspalten, Datentypen und Datenformate aus den Quelldaten. Bei den meisten Datasettypen, z. B. SQL und Parquet, wird die Projektion in einer Quelle so festgelegt, dass sie das in einem Dataset definierte Schema widerspiegelt. Dies variiert je nach der Quelle. Wenn Ihre Quelldateien nicht stark typisiert sind (z. B. flache CSV-Dateien im Gegensatz zu Parquet-Dateien), können Sie in der Quelltransformation die Datentypen für jedes Feld definieren. Die folgende Abbildung zeigt eine Beispielprojektion:
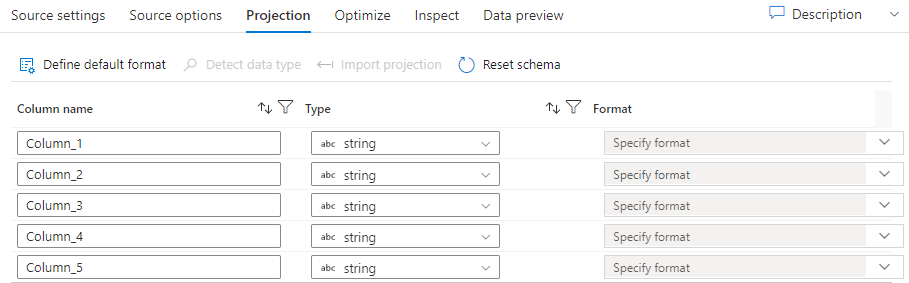
Wenn in Ihrer Textdatei kein Schema definiert wurde, wählen Sie Datentyp erkennen aus, damit der Dienst Stichproben erstellt und die Datentypen ableitet. Wählen Sie Standarddatenformat aus, um die Standarddatenformate automatisch zu ermitteln.
Schema zurücksetzen setzt die Projektion auf die Vorgaben im referenzierten Dataset zurück.
Durch das Überschreiben des Schemas können Sie die projizierten Datentypen hier in der Quelle ändern und dadurch die im Schema definierten Datentypen überschreiben. Alternativ können Sie die Datentypen der Spalten in einer nachgelagerten abgeleiteten Spaltentransformation ändern. Verwenden Sie eine Transformation, um die Spaltennamen zu ändern.
Schema importieren
Mithilfe der Schaltfläche Schema importieren auf der Registerkarte Projektion können Sie einen aktiven Debugcluster zum Erstellen einer Schemaprojektion verwenden. Diese Schaltfläche ist für jeden Quelltyp verfügbar. Durch das Importieren des Schemas wird die im Dataset definierte Projektion überschrieben. Das Datasetobjekt wird nicht geändert.
Das Importieren eines Schemas ist in Datasets wie Avro und Azure Cosmos DB nützlich, die komplexe Datenstrukturen unterstützen, für die keine Schemadefinitionen im Dataset vorhanden sind. Für Inline-Datasets ist das Importieren des Schemas die einzige Möglichkeit, ohne Schemaabweichung auf Spaltenmetadaten zu verweisen.
Optimieren der Quelltransformation
Die Registerkarte Optimieren ermöglicht die Bearbeitung von Partitionsinformationen bei jedem Transformationsschritt. In den meisten Fällen wird mit Aktuelle Partitionierung verwenden eine Optimierung durchgeführt, um die ideale Partitionsstruktur für eine Quelle zu erreichen.
Wenn Sie von einer Azure SQL-Datenbank-Quelle lesen, ermöglicht benutzerdefinierte Source-Partitionierung wahrscheinlich die schnellste Datenlesezeit. Der Dienst liest große Abfragen, indem er parallele Verbindungen mit Ihrer Datenbank herstellt. Diese Quellpartitionierung kann für eine Spalte oder über eine Abfrage erfolgen.
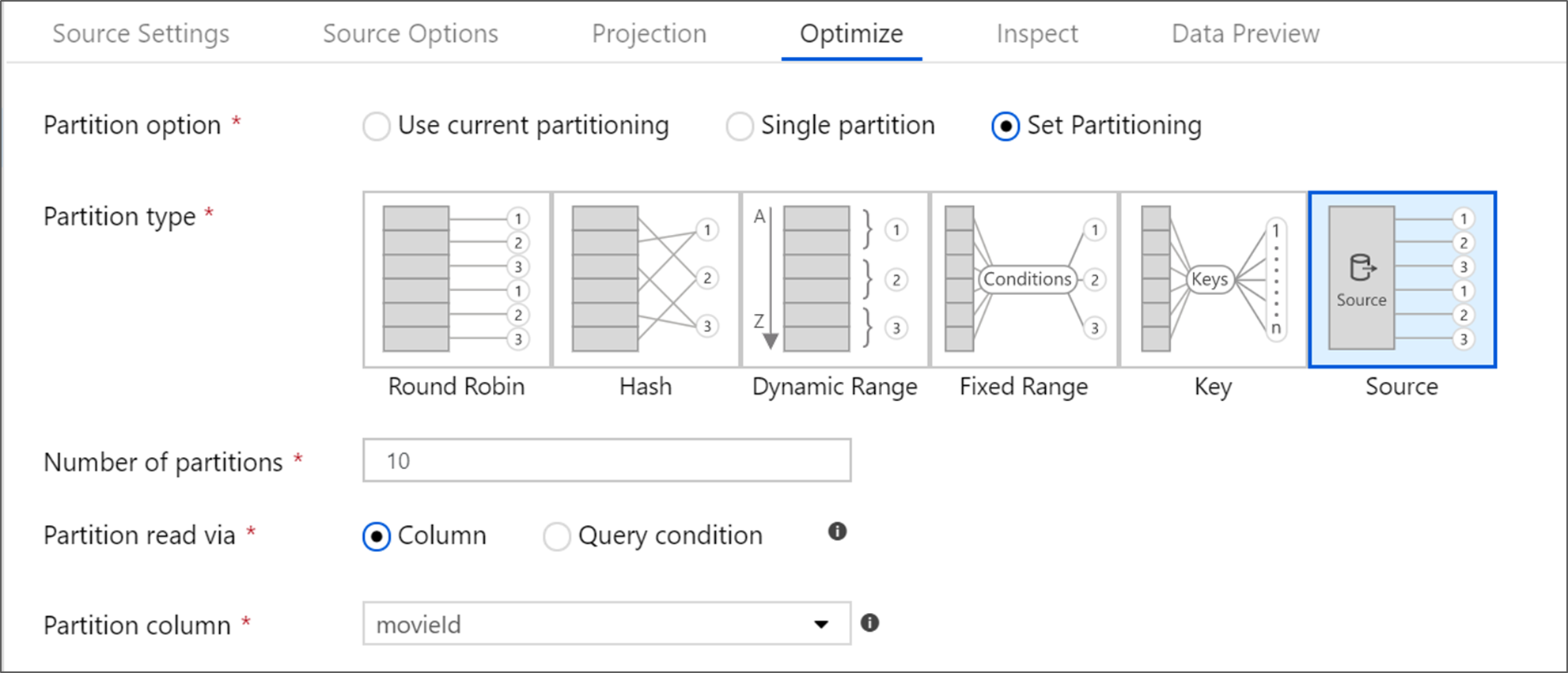
Weitere Informationen zur Optimierung in Mapping Data Flow finden Sie auf der Registerkarte „Optimieren“.
Zugehöriger Inhalt
Beginnen Sie die Erstellung Ihres Datenflusses mit einer Transformation für abgeleitete Spalten und einer select-Transformation.