Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie serverloses Rechnen für Notebooks verwenden. Informationen zur Verwendung der serverlosen Berechnung für Aufträge finden Sie unter Ausführen von Lakeflow-Aufträgen mit serverloser Berechnung für Workflows.
Informationen zu den Preisen für die Nutzung von Serverless-Computing in Notebooks finden Sie unter Databricks-Preise.
Anforderungen
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein.
- Ihr Arbeitsbereich muss sich in einer unterstützten Region befinden, damit serverlose Berechnungen ausgeführt werden können.
Verbinden eines Notebooks mit serverloser Rechenleistung
Wenn Ihr Arbeitsbereich für die serverlose interaktive Berechnung aktiviert ist, haben alle Benutzer im Arbeitsbereich Zugriff auf serverlose Berechnung für Notebooks. Es sind keine zusätzlichen Berechtigungen erforderlich.
Um sich mit dem serverlosen Compute zu verbinden, klicken Sie im Notebook auf das Dropdown-Menü "Compute" und wählen Sie Serverless aus. Bei neuen Notebooks wird die zugeordnete Rechenressource standardmäßig serverlos während der Codeausführung ausgeführt, wenn keine andere Ressource ausgewählt wurde.
Abfrageeinblicke anzeigen
Serverloses Computing für Notebooks und Aufträge verwendet Abfrageerkenntnisse zur Bewertung der Spark-Ausführungsleistung. Nachdem Sie eine Zelle in einem Notebook ausgeführt haben, können Sie Einblicke im Zusammenhang mit SQL- und Python-Abfragen anzeigen, indem Sie auf den Link "Leistung anzeigen" klicken.
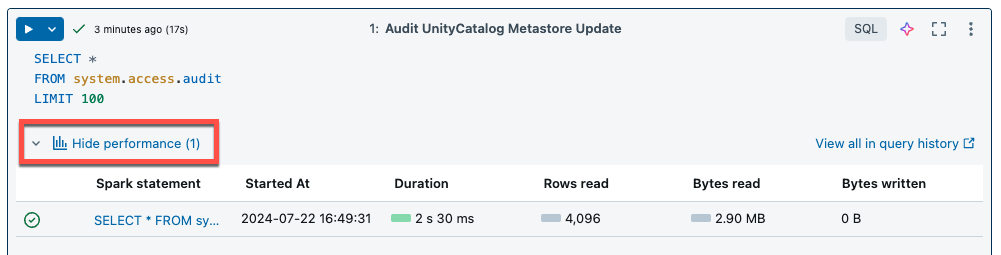
Sie können auf eine der Spark-Anweisungen klicken, um die Abfragemetriken anzuzeigen. Dort können Sie auf "Abfrageprofil anzeigen" klicken, um eine Visualisierung der Abfrageausführung anzuzeigen. Weitere Informationen zu Abfrageprofilen finden Sie unter "Abfrageprofil".
Hinweis
Um Leistungsanalysen Ihrer Auftragsläufe anzuzeigen, siehe Abfrageanalysen von Auftragsläufen anzeigen.
Abfrageverlauf
Alle Abfragen, die auf serverloser Berechnung ausgeführt werden, werden auch auf der Abfrageverlaufsseite Ihres Arbeitsbereichs aufgezeichnet. Informationen zum Abfrageverlauf finden Sie unter "Abfrageverlauf".
Einschränkungen für Abfrageeinsichten
- Metriken werden während der Abfrageausführung live aktualisiert, aber das vollständige Abfrageprofil ist erst verfügbar, nachdem die Abfrage beendet wurde.
- Es werden nur die folgenden Abfragestatus behandelt: RUNNING, CANCELED, FAILED, FINISHED.
- Die Ausführung von Abfragen kann nicht von der Abfrageverlaufsseite abgebrochen werden. Sie können in Notebooks oder Aufträgen abgebrochen werden.
- Ausführliche Metriken sind nicht verfügbar.
- Der Download von Abfrageprofilen ist nicht verfügbar.
- Der Zugriff auf die Spark-Benutzeroberfläche ist nicht verfügbar.
- Der Anweisungstext enthält nur die letzte Zeile, die ausgeführt wurde. Es kann jedoch mehrere Zeilen vor dieser Zeile geben, die als Teil derselben Anweisung ausgeführt wurden.
Serverloser Überlastungsschutz
Um lange ausgeführte Abfragen zu steuern, verfügen serverlose Notizbücher über ein Standardmäßiges Ausführungstimeout von 2,5 Stunden (9.000 Sekunden). Abfragen, die das Timeout überschreiten, werden abgebrochen.
Konfigurieren Sie das Timeout für alle Notebooks im Arbeitsbereich
Arbeitsbereichsadministratoren können das Standardmäßige Ausführungstimeout für serverlose Notizbücher ändern. Wechseln Sie in den Arbeitsbereichsadministratoreinstellungen zu "Computeeinstellungen>", und konfigurieren Sie unter "Serverless interactive" die Timeouteinstellung für die serverlose interaktive Ausführung. Änderungen dauern etwa 5 Minuten, bis sie verteilt werden.
Überschreiben Sie den Timeout für ein einzelnes Notebook
Um den Standard des Arbeitsbereichs für ein bestimmtes Notizbuch zu überschreiben, setzen Sie spark.databricks.execution.timeout im Notebook. Der Wert pro Notizbuch hat Vorrang vor der Arbeitsbereichseinstellung. Siehe Konfigurieren von Spark-Eigenschaften für serverlose Notizbücher und Aufträge.