Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Serverlose Berechnung für Workflows ermöglicht es Ihnen, Ihren Auftrag auszuführen, ohne Infrastruktur zu konfigurieren und bereitzustellen. Beim serverlosen Computing können Sie sich auf die Implementierung Ihrer Datenverarbeitungs- und Analysepipelines konzentrieren, während Azure Databricks die Computeressourcen effizient verwaltet, einschließlich der Optimierung und Skalierung des Computings für Ihre Workloads. Die automatische Skalierung und Photon werden automatisch für die zur Ausführung Ihres Auftrags verwendeten Computeressourcen aktiviert.
Serverloses Computing für Workflows optimiert automatisch und kontinuierlich die Infrastruktur, z. B. Instanztypen, Arbeitsspeicher und Verarbeitungs-Engines, um die beste Leistung basierend auf den spezifischen Verarbeitungsanforderungen Ihrer Workloads sicherzustellen.
Databricks aktualisiert automatisch die Databricks-Runtime-Version, um Verbesserungen und Upgrades auf die Plattform zu unterstützen und gleichzeitig die Stabilität Ihrer Aufträge sicherzustellen. Informationen zur aktuellen Databricks Runtime-Version, die für das serverlose Computing für Workflows verwendet wird, finden Sie in den Versionshinweisen zu serverlosem Computing.
Da die Berechtigung zum Erstellen von Clustern nicht erforderlich ist, können alle Benutzer im Arbeitsbereich serverloses Computing verwenden, um ihre Workflows auszuführen.
In diesem Artikel wird die Verwendung der Benutzeroberfläche für Lakeflow-Aufträge zum Erstellen und Ausführen von Aufträgen beschrieben, die serverlose Berechnungen verwenden. Sie können auch das Erstellen und Ausführen von Aufträgen, die serverloses Computing verwenden, mit der Auftrags-API, Databrick-Ressourcenbundles oder dem Databricks SDK für Python automatisieren.
- Weitere Informationen zur Verwendung der Auftrags-API zum Erstellen und Ausführen von Aufträgen, die serverloses Computing verwenden, finden Sie in der REST-API-Referenz unter Aufträge.
- Informationen zur Verwendung von Databricks Asset Bundles zum Erstellen und Ausführen von Aufträgen, die serverlose Berechnung verwenden, finden Sie unter Entwickeln eines Auftrags mit Databricks Asset Bundles.
- Informationen zur Verwendung des Databricks SDK für Python zum Erstellen und Ausführen von Aufträgen, die serverloses Computing verwenden, finden Sie unter Databricks SDK für Python.
Anforderungen
- In Ihrem Azure Databricks-Arbeitsbereich muss Unity Catalog aktiviert sein.
- Da serverlose Berechnung für Workflows den Standardzugriffsmodus verwendet, müssen Ihre Workloads diesen Zugriffsmodus unterstützen.
- Ihr Databricks-Arbeitsbereich muss sich in einer unterstützten Region befinden. Weitere Informationen finden Sie unter Features mit eingeschränkter regionaler Verfügbarkeit.
- Ihr Azure Databricks-Konto muss die serverlose Berechnungsleistung aktiviert haben. Weitere Informationen finden Sie unter Aktivieren des serverlosen Computings.
Einen Job mit serverlosen Computing erstellen
Hinweis
Da die serverlose Berechnung für Workflows sicherstellt, dass ausreichende Ressourcen bereitgestellt werden, um Ihre Workloads auszuführen, kann es zu erhöhten Startzeiten kommen, wenn ein Auftrag ausgeführt wird, der große Speichermengen erfordert oder viele Aufgaben umfasst.
Serverloses Computing wird mit den Aufgabentypen Notebook, Python-Skript, dbt und Python-Wheel unterstützt. Standardmäßig wird serverloses Computing als Computetyp ausgewählt, wenn Sie einen neuen Auftrag erstellen und einen dieser unterstützten Aufgabentypen hinzufügen.
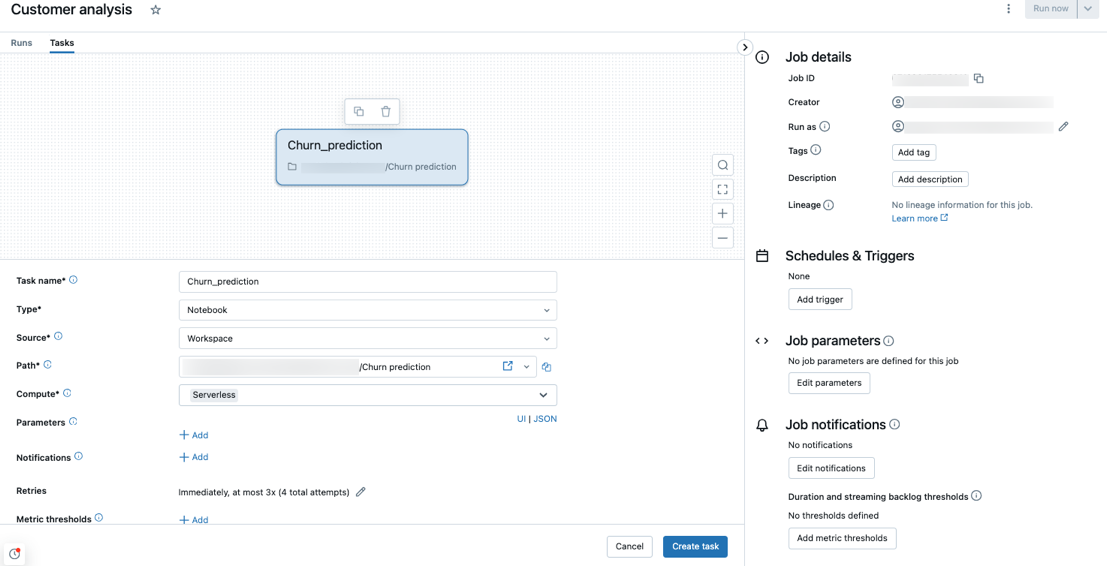
Databricks empfiehlt die Verwendung der serverlosen Computings für alle Auftragsaufgaben. Sie können auch unterschiedliche Computetypen für Aufgaben in einem Auftrag angeben. Dies ist möglicherweise erforderlich, wenn ein Aufgabentyp für das serverlose Computing für Workflows nicht unterstützt wird.
Informationen zum Verwalten ausgehender Netzwerkverbindungen für Ihre Aufträge finden Sie unter Was ist serverlose Egress-Kontrolle?
Konfigurieren eines vorhandenen Auftrags für die Verwendung von serverlosem Computing
Sie können einen vorhandenen Auftrag auf die Verwendung des serverlosen Computings für unterstützte Aufgabentypen umstellen, indem Sie den Auftrag bearbeiten. Um zu serverlosem Computing zu wechseln, führen Sie eine der folgenden Aktionen aus:
- Wählen Sie im Bereich Auftragsdetails unter Compute die Option Tauschen und dann Neu aus, geben Sie alle Einstellungen ein, oder ändern Sie diese, und wählen Sie dann Aktualisieren aus.
- Klicken Sie auf
 im Compute-Dropdown-Menü und wählen Sie Serverless aus.
im Compute-Dropdown-Menü und wählen Sie Serverless aus.

Planen eines Notebooks mit serverlosem Computing
Neben der Auftragsbenutzeroberfläche können Sie für das Erstellen und Planen eines Auftrags mit serverlosem Computing auch direkt aus einem Databricks-Notebook einen Auftrag erstellen und ausführen, der serverloses Computing verwendet. Weitere Informationen finden Sie unter Erstellen und Verwalten geplanter Notebookaufträge.
Wählen Sie eine serverlose Budgetrichtlinie für ihre serverlose Nutzung aus.
Wichtig
Dieses Feature befindet sich in der Public Preview.
Serverless-Budgetrichtlinien ermöglichen es Ihrer Organisation, benutzerdefinierte Tags auf die Nutzung von serverlosen Diensten für eine präzise Rechnungszuschreibung anzuwenden.
Wenn Ihr Arbeitsbereich serverlose Budgetrichtlinien verwendet, um die serverlose Verwendung zu attributieren, können Sie die serverlose Budgetrichtlinie Ihres Auftrags mithilfe der Budgetrichtlinieneinstellung in der Benutzeroberfläche für Auftragsdetails auswählen. Wenn Sie nur einer serverlosen Budgetrichtlinie zugewiesen sind, wird die Richtlinie automatisch für Ihre neuen Aufträge ausgewählt.
Hinweis
Nachdem Ihnen eine serverlose Budgetrichtlinie zugewiesen wurde, werden Ihre vorhandenen Aufträge nicht automatisch mit Ihrer Richtlinie kategorisiert. Sie müssen vorhandene Aufträge manuell aktualisieren, wenn Sie eine Richtlinie an diese anfügen möchten.
Weitere Informationen zu Serverlosen Budgetrichtlinien finden Sie unter Attributverwendung mit serverlosen Budgetrichtlinien.
Auswählen eines Leistungsmodus
Sie können auswählen, wie schnell die serverlosen Aufgaben Ihres Auftrags mithilfe der Einstellung "Leistungsoptimierte " auf der Seite "Auftragsdetails" ausgeführt werden.
Wenn Performance-Optimierung deaktiviert ist, verwendet der Auftrag den Standard-Performance-Modus. Dieser Modus wurde entwickelt, um die Kosten für Workloads zu reduzieren, bei denen eine etwas höhere Startlatenz akzeptabel ist. Aufträge können 4 bis 6 Minuten zum Starten benötigen, abhängig von der Rechenkapazität und der optimierten Zeitplanung.
Wenn die Leistung optimiert ist, wird der Auftrag gestartet und schneller ausgeführt. Dieser Modus wurde für zeitabhängige Workloads entwickelt.
Um die Einstellung "Leistungsoptimierte Leistung" in der Benutzeroberfläche zu konfigurieren, muss ein Auftrag mindestens eine serverlose Aufgabe haben. Diese Einstellung wirkt sich nur auf serverlose Aufgaben innerhalb des Auftrags aus.
Festlegen von Spark-Konfigurationsparametern
Um die Konfiguration von Spark auf serverlosem Computing zu automatisieren, ermöglicht Databricks das Festlegen nur bestimmter Spark-Konfigurationsparameter. Die Liste der zulässigen Parameter finden Sie unter Unterstützte Spark-Konfigurationsparameter.
Sie können Spark-Konfigurationsparameter nur auf Sitzungsebene festlegen. Legen Sie sie dazu in einem Notebook fest, und fügen Sie das Notebook zu einer Aufgabe hinzu, die in demselben Auftrag enthalten ist, der die Parameter verwendet. Weitere Informationen finden Sie unter Abrufen und Festlegen von Apache Spark-Konfigurationseigenschaften in einem Notebook.
Konfigurieren von Umgebungen und Abhängigkeiten
Informationen zum Installieren von Bibliotheken und Abhängigkeiten mithilfe der serverlosen Berechnung finden Sie unter Konfigurieren der serverlosen Umgebung.
Konfigurieren von hohem Arbeitsspeicher für Notizbuchaufgaben
Wichtig
Dieses Feature befindet sich in der Public Preview.
Sie können Notizbuchaufgaben so konfigurieren, dass sie eine höhere Arbeitsspeichergröße verwenden. Konfigurieren Sie hierzu die Speichereinstellung im Seitenbereich " Umgebung " des Notizbuchs. Weitere Informationen finden Sie unter Hochspeicherfähiges serverloses Rechnen einsetzen.
Hoher Arbeitsspeicher ist nur für Notizbuchaufgabentypen verfügbar.
Konfigurieren der automatischen Optimierung für serverloses Computing mit Verhinderung von Wiederholungen
Die automatische Optimierung für serverloses Rechnen von Workflows optimiert automatisch die Rechenressourcen, die zur Ausführung Ihrer Aufträge benötigt werden und versucht fehlerhafte Aufgaben erneut. Standardmäßig ist die automatische Optimierung aktiviert, und Databricks empfiehlt auch, sie aktiviert zu lassen, um sicherzustellen, dass kritische Workloads mindestens einmal erfolgreich ausgeführt werden. Wenn einige Ihrer Workloads höchstens einmal ausgeführt werden sollen (z. B. Aufträge, die nicht idempotent sind), können Sie die automatische Optimierung beim Hinzufügen oder Bearbeiten einer Aufgabe deaktivieren:
- Wählen Sie neben Wiederholungen die Option Hinzufügen aus (oder
 , wenn bereits eine Wiederholungsrichtlinie vorhanden ist).
, wenn bereits eine Wiederholungsrichtlinie vorhanden ist). - Deaktivieren Sie im Dialogfeld Wiederholungsrichtlinie die Option Serverlose automatische Optimierung aktivieren (möglicherweise zusätzliche Wiederholungen).
- Klicken Sie auf Confirm (Bestätigen).
- Wenn Sie eine Aufgabe hinzufügen, klicken Sie auf " Aufgabe erstellen". Wenn Sie eine Aufgabe bearbeiten, klicken Sie auf "Aufgabe speichern".
Überwachen der Kosten für Aufträge, die serverloses Computing für Workflows verwenden
Sie können die Kosten von Aufträgen überwachen, die serverloses Computing für Workflows verwenden, indem Sie die Systemtabelle für abrechenbaren Verbrauch abfragen. Diese Tabelle wird aktualisiert, um Benutzer- und Workloadattribute in die Kosten für serverloses Computing einzuschließen. Weitere Informationen finden Sie unter Referenz zur Systemtabelle für abrechnungsfähigen Verbrauch.
Informationen zu aktuellen Preisen und Werbeaktionen finden Sie auf der Seite "Workflows-Preise".
Abfragedetails für Auftragsausführungen anzeigen
Sie können detaillierte Laufzeitinformationen für Ihre Spark-Anweisungen anzeigen, z. B. Metriken und Abfragepläne.
Führen Sie die folgenden Schritte aus, um auf Abfragedetails über die Auftrags-UI zuzugreifen:
Klicken Sie in der Randleiste Ihres Azure Databricks-Arbeitsbereichs auf Aufträge und Pipelines.
Wählen Sie optional den Filter "Aufträge " aus.
Klicken Sie auf den Namen des Auftrags, den Sie anzeigen möchten.
Klicken Sie auf die spezifische Ausführung, die Sie anzeigen möchten.
Klicken Sie auf "Zeitachse" , um die Ausführung als Zeitachse anzuzeigen, und teilen Sie sie in einzelne Aufgaben auf.
Klicken Sie auf den Pfeil neben dem Aufgabennamen, um Abfrageanweisungen und deren Laufzeiten anzuzeigen.
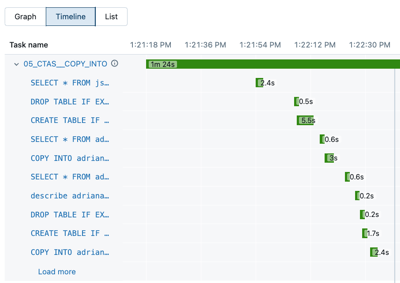
Klicken Sie auf eine Anweisung, um den Abfragedetailsbereich zu öffnen. Weitere Informationen zu den in diesem Bereich verfügbaren Informationen finden Sie unter "Abfragedetails anzeigen".
So zeigen Sie den Abfrageverlauf für eine Aufgabe an:
- Klicken Sie im Abschnitt Compute des Seitenbereichs Task ausgeführt auf Abfrageverlauf.
- Dadurch werden Sie zum Abfrageverlauf weitergeleitet, der basierend auf der Task-ID der Aufgabe, in der Sie waren, vorgefiltert ist.
Informationen zur Verwendung des Abfrageverlaufs finden Sie unter Access-Abfrageverlauf für Lakeflow Declarative Pipelines und Abfrageverlauf.
Begrenzungen
Eine Liste der Einschränkungen für serverloses Computing für Workflows finden Sie in den Versionshinweisen zu serverlosem Computing unter Einschränkungen für serverloses Computing.