Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hinweis
Dieser Artikel behandelt Databricks Connect für Databricks Runtime Version 13.3 LTS und höher.
Mit Databricks Connect können Sie beliebte IDEs wie IntelliJ IDEA, Notebookserver und andere benutzerdefinierte Anwendungen mit Azure Databricks-Clustern verbinden. Weitere Informationen finden Sie unter Was ist Databricks Connect?.
In diesem Artikel wird veranschaulicht, wie Sie schnell mit Databricks Connect für Scala mit IntelliJ IDEA und dem Scala-Plug-In beginnen.
- Die Python-Version dieses Artikels finden Sie unter Databricks Connect für Python.
- Die R-Version dieses Artikels finden Sie unter Databricks Connect für R.
Lernprogramm
Im folgenden Lernprogramm erstellen Sie ein Projekt in IntelliJ IDEA, installieren Databricks Connect für Databricks Runtime 13.3 LTS und höher, und führen Sie einfachen Code für die Berechnung in Ihrem Databricks-Arbeitsbereich aus IntelliJ IDEA aus. Weitere Informationen und Beispiele finden Sie in den nächsten Schritten.
Anforderungen
Um dieses Tutorial abzuschließen, müssen Sie die folgenden Anforderungen erfüllen:
Ihr Ziel-Azure Databricks-Arbeitsbereich und -Cluster müssen die Computeanforderungen für Databricks Connect erfüllen.
Sie müssen ihre Cluster-ID verfügbar haben. Um Ihre Cluster-ID abzurufen, klicken Sie in Ihrem Arbeitsbereich auf der Randleiste auf "Berechnen ", und klicken Sie dann auf den Namen Ihres Clusters. Kopieren Sie in der Adressleiste Ihres Webbrowsers die Zeichenfolge zwischen
clustersundconfigurationin der URL.Ihre lokale Umgebung und Ihr Rechner erfüllen die Anforderungen der Databricks Connect für die Scala-Installationsversion.
Das Java Development Kit (JDK) muss auf Ihrem Entwicklungscomputer installiert sein. Databricks empfiehlt, dass die Version Ihrer JDK-Installation mit der JDK-Version auf Ihrem Azure Databricks-Cluster übereinstimmt. Informationen zur JDK-Version der Databricks-Runtime auf Ihrem Cluster finden Sie im Abschnitt "Systemumgebung " der Versionshinweise zur Databricks-Runtime oder der Versionsunterstützungsmatrix.
Hinweis
Wenn Sie kein JDK installiert haben oder mehrere JDK-Installationen auf Ihrem Entwicklungscomputer installiert sind, können Sie später in Schritt 1 ein JDK installieren oder ein bestimmtes auswählen. Wenn Sie eine JDK-Installation auswählen, die deren Version älter oder neuer als die Version auf Ihrem Cluster ist, kann dies zu unerwarteten Ergebnissen führen. Möglicherweise wird Ihr Code auch überhaupt nicht ausgeführt.
Sie haben IntelliJ IDEA installiert. Dieses Tutorial wurde mit IntelliJ IDEA Community Edition 2023.3.6 getestet. Wenn Sie eine andere Version oder Edition von IntelliJ IDEA verwenden, können die folgenden Anweisungen variieren.
Sie haben das Scala-Plug-In für IntelliJ IDEA installiert.
Schritt 1: Konfigurieren der Azure Databricks-Authentifizierung
In diesem Tutorial werden die OAuth U2M-Authentifizierung (User-to-Machine) von Azure Databricks und ein Azure Databricks-Konfigurationsprofil für die Authentifizierung bei Ihrem Azure Databricks-Arbeitsbereich verwendet. Informationen zum Verwenden eines anderen Authentifizierungstyps finden Sie unter Konfigurieren von Verbindungseigenschaften.
Die Konfiguration der OAuth U2M-Authentifizierung erfordert die Verwendung der Databricks-Befehlszeilenschnittstelle (Command Line Interface, CLI). Gehen Sie dazu wie im Folgenden beschrieben vor:
Installieren Sie die Databricks CLI wie folgt, falls sie noch nicht installiert ist:
Linux, macOS
Verwenden Sie Homebrew, um die Databricks CLI zu installieren, indem Sie die folgenden beiden Befehle ausführen:
brew tap databricks/tap brew install databricksFenster
Sie können Winget, Chocolatey oder das Windows Subsystem für Linux (WSL) verwenden, um die Databricks CLI zu installieren. Wenn Sie
winget, Chocolatey oder das WSL nicht verwenden können, sollten Sie dieses Verfahren überspringen und stattdessen die Eingabeaufforderung oder PowerShell verwenden, um die Databricks CLI aus der Quelle zu installieren.Hinweis
Die Installation der Databricks CLI mit Chocolatey befindet sich in der experimentellen Phase.
Um
wingetzum Installieren der Databricks CLI zu verwenden, führen Sie die folgenden beiden Befehle aus, und starten Sie dann die Eingabeaufforderung neu:winget search databricks winget install Databricks.DatabricksCLIUm Chocolatey zum Installieren der Databricks CLI zu verwenden, führen Sie den folgenden Befehl aus:
choco install databricks-cliSo installieren Sie die Databricks CLI mit dem WSL
Installieren Sie
curlundzipüber das WSL. Weitere Informationen finden Sie in der Dokumentation Ihres Betriebssystems.Verwenden Sie WSL, um die Databricks CLI zu installieren, indem Sie den folgenden Befehl ausführen:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh
Vergewissern Sie sich, dass die Databricks CLI installiert ist, indem Sie den folgenden Befehl ausführen, der die aktuelle Version der installierten Databricks CLI anzeigt. Diese Version sollte 0.205.0 oder höher sein:
databricks -vHinweis
Wenn Sie
databricksausführen, aber einen Fehler wiecommand not found: databrickserhalten, oder wenn Siedatabricks -vausführen und eine Versionsnummer von 0.18 oder niedriger aufgeführt ist, bedeutet dies, dass Ihr Computer nicht die richtige Version der ausführbaren Databricks-CLI-Datei finden kann. Weitere Informationen zum Beheben dieses Problems finden Sie unter Überprüfen Ihrer CLI-Installation.
Initiieren Sie wie folgt die OAuth U2M-Authentifizierung:
Verwenden Sie die Databricks-CLI, um die OAuth-Tokenverwaltung lokal zu initiieren, indem Sie den folgenden Befehl für jeden Zielarbeitsbereich ausführen.
Ersetzen Sie
<workspace-url>im folgenden Befehl durch Ihre arbeitsbereichsspezifische Azure Databricks-URL, z. B.https://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Die Databricks-CLI fordert Sie auf, die von Ihnen eingegebenen Informationen als Azure Databricks-Konfigurationsprofil zu speichern. Drücken Sie die EINGABETASTE (
Enter), um den vorgeschlagenen Profilnamen zu übernehmen, oder geben Sie den Namen eines neuen oder bereits vorhandenen Profils ein. Ist bereits ein Profil mit dem gleichen Namen vorhanden, wird es mit den von Ihnen eingegebenen Informationen überschrieben. Sie können Profile verwenden, um Ihren Authentifizierungskontext schnell über mehrere Arbeitsbereiche hinweg zu wechseln.Um eine Liste vorhandener Profile abzurufen, führen Sie in der Databricks-CLI den Befehl
databricks auth profilesin einem separaten Terminal oder in einer separaten Eingabeaufforderung aus. Um die vorhandenen Einstellungen eines bestimmten Profils anzuzeigen, führen Sie den Befehldatabricks auth env --profile <profile-name>aus.Führen Sie in Ihrem Webbrowser die Anweisungen auf dem Bildschirm aus, um sich bei Ihrem Azure Databricks-Arbeitsbereich anzumelden.
Verwenden Sie in der Liste der verfügbaren Cluster, die im Terminal oder in der Eingabeaufforderung angezeigt wird, die NACH-OBEN- und NACH-UNTEN-TASTEN, um den Azure Databricks-Zielcluster in Ihrem Arbeitsbereich auszuwählen, und drücken Sie dann die EINGABETASTE (
Enter). Sie können auch einen beliebigen Teil des Anzeigenamens des Clusters eingeben, um die Liste der verfügbaren Cluster zu filtern.Um den aktuellen OAuth-Tokenwert eines Profils und den bevorstehenden Ablaufzeitstempel eines Profils anzuzeigen, führen Sie einen der folgenden Befehle aus:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Wenn Sie über mehrere Profile mit dem gleichen
--host-Wert verfügen, müssen Sie möglicherweise die Optionen--hostund-pangeben, damit die Databricks-CLI die richtigen übereinstimmenden OAuth-Tokeninformationen findet.
Schritt 2: Erstellen des Projekts
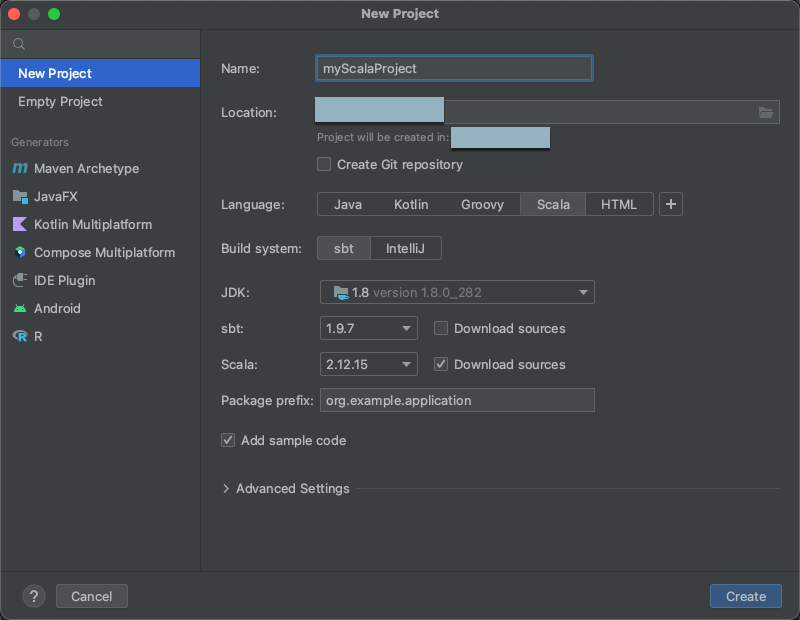
Starten Sie IntelliJ IDEA.
Klicken Sie im Hauptmenü auf Datei > Neu > Projekt.
Geben Sie Ihrem Projekt einen aussagekräftigen Namen.
Klicken Sie unter Speicherort auf das Ordnersymbol, und folgen Sie den Anweisungen auf dem Bildschirm, um den Pfad zu Ihrem neuen Scala-Projekt anzugeben.
Klicken Sie für Sprache auf Scala.
Klicken Sie für das Buildsystem auf sbt.
Wählen Sie in der JDK-Dropdownliste eine vorhandene Installation von JDK auf Ihrem Entwicklungscomputer aus, die der JDK-Version auf Ihrem Cluster entspricht, oder wählen Sie JDK herunterladen und befolgen Sie die Anweisungen auf dem Bildschirm, um ein JDK herunterzuladen, das der JDK-Version auf Ihrem Cluster entspricht. Weitere Informationen finden Sie unter Anforderungen.
Hinweis
Wenn Sie eine JDK-Installation auswählen, die älter oder neuer als die JDK-Version auf Ihrem Cluster ist, kann es zu unerwarteten Ergebnissen führen, oder Ihr Code wird möglicherweise überhaupt nicht ausgeführt.
Wählen Sie in der sbt-Dropdownliste die neueste Version aus.
Wählen Sie in der Scala-Dropdownliste die Version von Scala aus, die der Scala-Version auf Ihrem Cluster entspricht. Weitere Informationen finden Sie unter Anforderungen.
Hinweis
Wenn Sie eine Scala-Version auswählen, die älter oder neuer als die Scala-Version auf Ihrem Cluster ist, kann dies zu unerwarteten Ergebnissen führen. Möglicherweise wird Ihr Code auch überhaupt nicht ausgeführt.
Stellen Sie sicher, dass das Kontrollkästchen Quellen herunterladen neben Scala aktiviert ist.
Geben Sie einen Wert für das Paketpräfix für die Quellen Ihres Projekts ein, z. B.
org.example.application.Stellen Sie sicher, dass das Feld Beispielcode hinzufügen aktiviert ist.
Klicken Sie auf Erstellen.
Schritt 3: Hinzufügen des Databricks Connect-Pakets
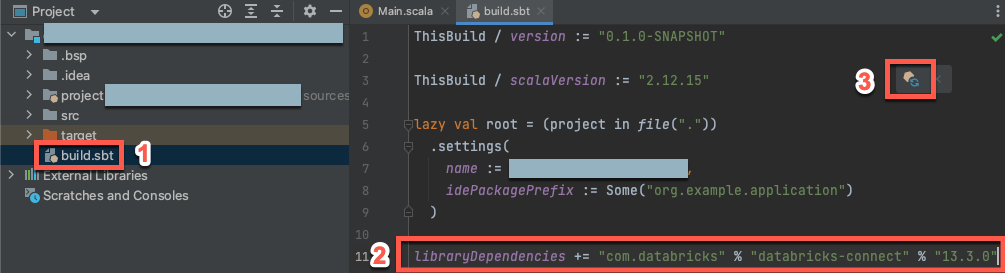
Wenn Ihr neues Scala-Projekt geöffnet ist, öffnen Sie in Ihrem Projekt-Toolfenster (Anzeigen > Windows-Tool > Projekt) die Datei mit dem Namen
build.sbtin Projekname> Ziel.Fügen Sie am Ende der
build.sbtDatei den folgenden Code hinzu, der die Abhängigkeit Ihres Projekts von einer bestimmten Version der Databricks Connect-Bibliothek für Scala deklariert, die mit der Databricks-Runtime-Version Ihres Clusters kompatibel ist:libraryDependencies += "com.databricks" % "databricks-connect" % "14.3.1"Ersetzen Sie
14.3.1durch die Version der Databricks Connect-Bibliothek, die der Databricks-Runtime-Version auf Ihrem Cluster entspricht. Beispielsweise entspricht Databricks Connect 14.3.1 Databricks Runtime 14.3 LTS. Die Versionsnummern der Databricks Connect-Bibliothek finden Sie im zentralen Maven-Repository.Klicken Sie auf das Benachrichtigungssymbol sbt-Änderungen laden, um Ihr Scala-Projekt mit dem neuen Bibliotheksspeicherort und der Abhängigkeit zu aktualisieren.
Warten Sie, bis die Statusanzeige
sbtam unteren Rand der IDE ausgeblendet wird. Der Ladevorgangsbtkann einige Minuten dauern.
Schritt 4: Hinzufügen von Code
Öffnen Sie in Ihrem Projekt-Toolfenster die Datei mit dem Namen
Main.scalain Scala >.Ersetzen Sie vorhandenen Code in der Datei durch den folgenden Code und speichern Sie die Datei dann abhängig vom Namen Ihres Konfigurationsprofils.
Wenn Ihr Konfigurationsprofil aus Schritt 1
DEFAULTlautet, ersetzen Sie den vorhandenen Code in der Datei durch den folgenden Code und speichern Sie die Datei:package org.example.application import com.databricks.connect.DatabricksSession import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = DatabricksSession.builder().remote().getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }Wenn Ihr Konfigurationsprofil aus Schritt 1 nicht
DEFAULTlautet, ersetzen Sie stattdessen den vorhandenen Code in der Datei durch den folgenden Code. Ersetzen Sie den Platzhalter<profile-name>durch den Namen Ihres Konfigurationsprofils aus Schritt 1 und speichern Sie dann die Datei:package org.example.application import com.databricks.connect.DatabricksSession import com.databricks.sdk.core.DatabricksConfig import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val config = new DatabricksConfig().setProfile("<profile-name>") val spark = DatabricksSession.builder().sdkConfig(config).getOrCreate() val df = spark.read.table("samples.nyctaxi.trips") df.limit(5).show() } }
Schritt 5: Ausführen des Codes
- Starten Sie den Zielcluster in Ihrem Azure Databricks-Remotearbeitsbereich.
- Nachdem der Cluster gestartet wurde, klicken Sie im Hauptmenü auf Ausführen > 'Main'.
- Im Ausführen-Toolfenster (Anzeigen > Windows-Tool > Ausführen) werden auf der Registerkarte Main die ersten 5 Zeilen der
samples.nyctaxi.trips-Tabelle angezeigt.
Schritt 6: Debuggen des Codes
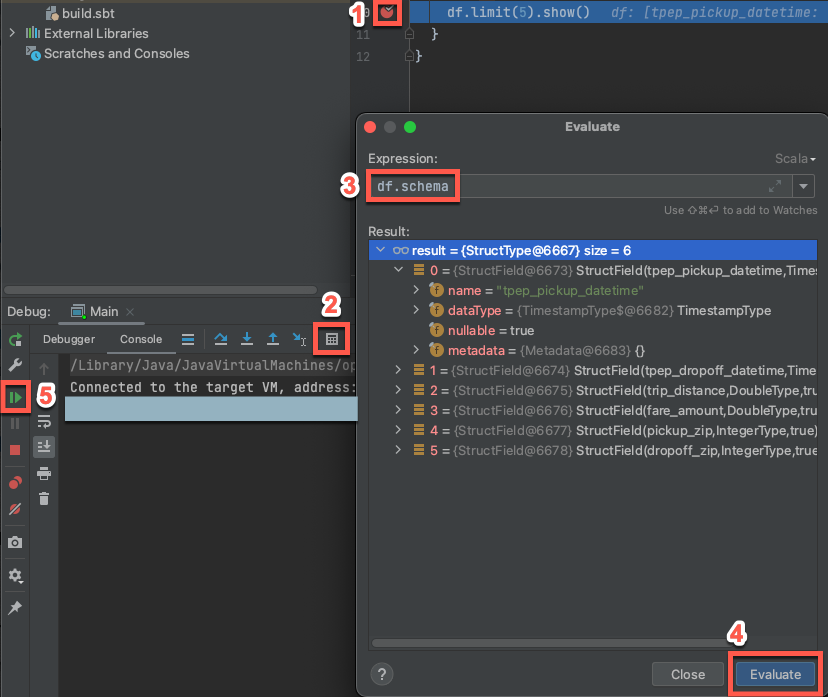
- Wählen Sie, während der Zielcluster noch ausgeführt wird, im vorherigen Code den Bundsteg neben
df.limit(5).show()aus, um einen Breakpoint festzulegen. - Klicken Sie im Hauptmenü auf "Debug 'Main' ausführen>".
- Klicken Sie im Debuggen-Toolfenster (Anzeigen> Windows-Tool> Debuggen) auf der Registerkarte Konsole auf das Rechnersymbol (Ausdruck auswerten).
- Geben Sie den Ausdruck
df.schemaein, und klicken Sie auf "Auswerten ", um das Schema von DataFrame anzuzeigen. - Klicken Sie in der Randleiste des Debugtools auf den grünen Pfeil (Programm fortsetzen).
- Im Konsolenbereich werden die ersten 5 Zeilen der Tabelle
samples.nyctaxi.tripsangezeigt.
Nächste Schritte
Weitere Informationen zu Databricks Connect finden Sie z. B. in den folgenden Artikeln:
- Informationen zur Verwendung anderer Azure Databricks-Authentifizierungstypen als ein persönliches Azure Databricks-Zugriffstoken finden Sie unter Konfigurieren von Verbindungseigenschaften.
- Weitere Codebeispiele finden Sie unter Codebeispiele für Databricks Connect für Scala.
- Informationen zum Anzeigen komplexerer Codebeispiele finden Sie in den Beispielanwendungen für das Databricks Connect-Repository in GitHub, insbesondere:
- Weitere Informationen zum Migrieren von Databricks Connect für Databricks Runtime bis Version 12.2 LTS an Databricks Connect für Databricks Runtime ab Version 13.3 LTS finden Sie unter Migrieren an Databricks Connect für Scala.
- Sehen Sie sich auch die Informationen zur Problembehandlung und die Einschränkungen an.