Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Databricks verfügt über mehrere Dienstprogramme und APIs für die Interaktion mit Dateien an den folgenden Speicherorten:
- Unity Catalog-Volumes
- Arbeitsbereichsdateien
- Cloudobjektspeicher
- DBFS-Einbindungen und DBFS-Stamm
- Ephemeralspeicher, der an den Treiberknoten des Clusters angefügt ist
Dieser Artikel enthält Beispiele für die Interaktion mit Dateien an diesen Speicherorten für die folgenden Tools:
- Apache Spark
- Spark SQL und Databricks SQL
- Databricks Dateisystemprogramme (
dbutils.fsoder%fs) - Databricks-Befehlszeilenschnittstelle
- Databricks-REST-API
- Bash-Shellbefehle (
%sh) - Installationen von Bibliotheken im Notebook-Bereich mit
%pip - Pandas
- OSS Python Dateiverwaltungs- und Verarbeitungsprogramme
Wichtig
Einige Vorgänge in Databricks, insbesondere solche, die Java- oder Scala-Bibliotheken verwenden, werden als JVM-Prozesse ausgeführt, z. B.:
- Angeben einer JAR-Dateiabhängigkeit in Spark-Konfigurationen unter Verwendung von
--jars - Aufrufen von
catoderjava.io.Filein Scala-Notizbüchern - Benutzerdefinierte Datenquellen, z. B.
spark.read.format("com.mycompany.datasource") - Bibliotheken, die Dateien mit Java's
FileInputStreamoderPaths.get()laden
Diese Vorgänge unterstützen nicht das Lesen von oder das Schreiben in Unity Catalog-Volumes oder Arbeitsbereichsdateien mit Standard-Dateipfaden wie z. B. /Volumes/my-catalog/my-schema/my-volume/my-file.csv. Wenn Sie auf Volumes oder Arbeitsbereiche aus JAR-Abhängigkeiten oder JVM-basierten Bibliotheken zugreifen müssen, kopieren Sie die Dateien zunächst in den lokalen Storage, indem Sie Python oder %sh Befehle wie z. B. %sh mv. verwenden. Verwenden Sie %fs und dbutils.fs nicht, die die JVM verwenden. Verwenden Sie sprachspezifische Befehle wie Python shutil oder %sh Befehle, um bereits lokal kopierte Dateien zuzugreifen. Wenn eine Datei während des Clusterstarts vorhanden sein muss, verwenden Sie ein Init-Skript, um die Datei zuerst zu verschieben. Siehe Was sind Init-Skripte?.
Muss ich ein URI-Schema für den Zugriff auf Daten bereitstellen?
Datenzugriffspfade in Azure Databricks folgen einem der folgenden Standards:
URI-artige Pfade enthalten ein URI-Schema. Bei Databricks-nativen Datenzugriffslösungen sind URI-Schemas für die meisten Anwendungsfälle optional. Wenn Sie direkt auf Daten im Cloudobjektspeicher zugreifen, müssen Sie das richtige URI-Schema für den Speichertyp angeben.
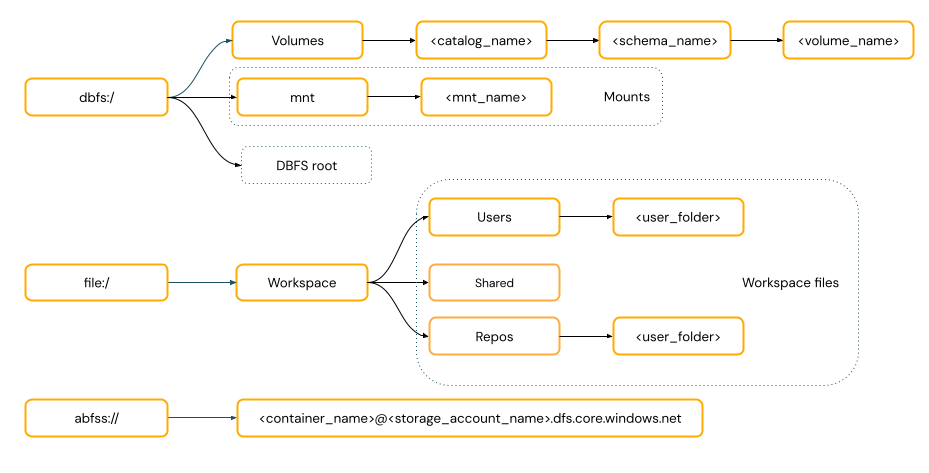
POSIX-ähnliche Pfade ermöglichen den Datenzugriff relativ zur Treiber-Root (
/). POSIX-Stilpfade erfordern nie ein Schema. Sie können Unity-Katalog-Volumes oder DBFS-Einbindungen verwenden, um POSIX-Stil-Zugriff auf Daten im Cloud-Objektspeicher bereitzustellen. Viele ML-Frameworks und andere OSS Python-Module erfordern FUSE und können nur POSIX-Stilpfade verwenden.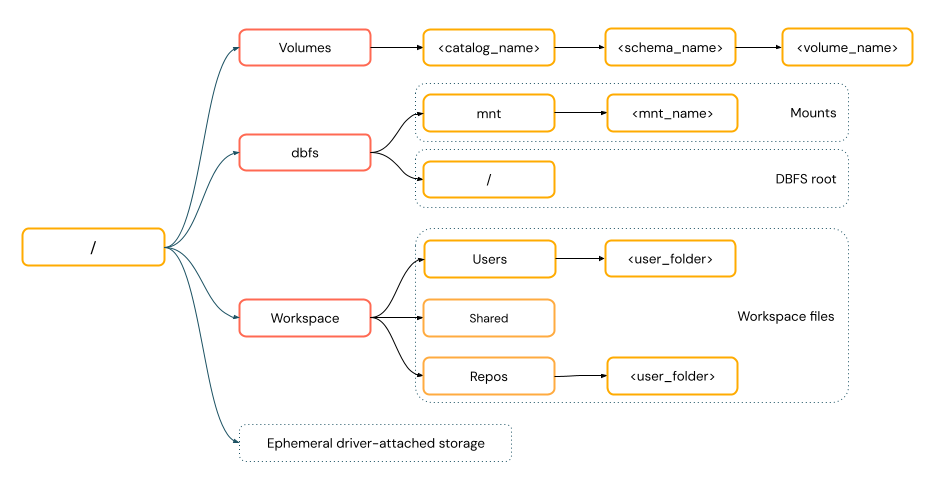
Anmerkung
Dateivorgänge, die FUSE-Datenzugriff erfordern, können nicht direkt auf den Cloudobjektspeicher mithilfe von URIs zugreifen. Databricks empfiehlt die Verwendung von Unity-Katalogvolumes zum Konfigurieren des Zugriffs auf diese Speicherorte für FUSE.
Bei der Berechnung, die mit dediziertem Zugriffsmodus (vormals Einzelbenutzerzugriffsmodus) und Databricks Runtime 14.3 und höher konfiguriert ist, unterstützt Scala FUSE für Unity-Katalogvolumes und Arbeitsbereichsdateien, mit Ausnahme von Unterprozessen, die aus Scala stammen, z. B. den Scala-Befehl "cat /Volumes/path/to/file".!!.
Arbeiten mit Dateien in Unity-Katalogvolumes
Databricks empfiehlt die Verwendung von Unity-Katalogvolumes zum Konfigurieren des Zugriffs auf nicht tabellarische Datendateien, die im Cloudobjektspeicher gespeichert sind. Vollständige Dokumentation zum Verwalten von Dateien in Volumes, einschließlich detaillierter Anweisungen und bewährter Methoden, finden Sie unter Arbeiten mit Dateien in Unity Catalog-Volumes.
Die folgenden Beispiele zeigen allgemeine Vorgänge mit unterschiedlichen Tools und Schnittstellen:
| Werkzeug | Beispiel |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL und Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`;LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Databricks-Dateisystem-Hilfsprogramme | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/")%fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks-Befehlszeilenschnittstelle | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks-REST-API | POST https://<databricks-instance>/api/2.1/jobs/create{"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash-Shellbefehle | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Bibliotheksinstallationen | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| Open-Source-Software Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Informationen zu Volumenbeschränkungen und Problemumgehungen finden Sie unter "Einschränkungen beim Arbeiten mit Dateien in Volumes".
Arbeiten mit Workspace-Dateien
Databricks Arbeitsbereich-Dateien sind die Dateien in einem Arbeitsbereich, die im Arbeitsbereich Storage-Konto gespeichert sind. Sie können Arbeitsbereichsdateien verwenden, um Dateien wie Notizbücher, Quellcodedateien, Datendateien und andere Arbeitsbereichsressourcen zu speichern und darauf zuzugreifen.
Wichtig
Da Arbeitsbereichsdateien Größenbeschränkungen aufweisen, empfiehlt Databricks, kleine Datendateien hier hauptsächlich für Entwicklung und Tests zu speichern. Empfehlungen zum Speichern anderer Dateitypen finden Sie unter "Dateitypen".
| Werkzeug | Beispiel |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL und Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Databricks-Dateisystem-Hilfsprogramme | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/")%fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks-Befehlszeilenschnittstelle | databricks workspace list |
| Databricks-REST-API | POST https://<databricks-instance>/api/2.0/workspace/delete{"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash-Shellbefehle | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Bibliotheksinstallationen | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| Open-Source-Software Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Anmerkung
Das file:/ Schema ist erforderlich, wenn Sie mit Databricks Utilities, Apache Spark oder SQL arbeiten.
In Arbeitsbereichen, in denen der DBFS-Stamm und die Mounts deaktiviert sind, können Sie dbfs:/Workspace auch verwenden, um mit Databricks-Dienstprogrammen auf Arbeitsbereichsdateien zuzugreifen. Dies erfordert Databricks Runtime 13.3 LTS oder höher. Siehe Deaktivieren des Zugriffs auf den DBFS-Stamm und die Einbindungen in Ihrem vorhandenen Azure Databricks-Arbeitsbereich.
Zu den Einschränkungen bei der Arbeit mit Arbeitsbereichsdateien siehe Einschränkungen.
Wo werden gelöschte Arbeitsbereichsdateien abgelegt?
Durch das Löschen einer Arbeitsbereichsdatei wird sie an den Papierkorb gesendet. Sie können Dateien mithilfe der Benutzeroberfläche aus dem Papierkorb wiederherstellen oder endgültig löschen.
Siehe Löschen eines Objekts.
Arbeiten mit Dateien im Cloudobjektspeicher
Databricks empfiehlt die Verwendung von Unity-Katalogvolumes, um den sicheren Zugriff auf Dateien im Cloudobjektspeicher zu konfigurieren. Sie müssen Berechtigungen konfigurieren, wenn Sie mithilfe von URIs direkt auf Daten im Cloudobjektspeicher zugreifen möchten. Siehe Verwaltete und externe Volumes.
Die folgenden Beispiele verwenden URIs für den Zugriff auf Daten im Cloudobjektspeicher:
| Werkzeug | Beispiel |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL und Databricks SQL |
SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`;
LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path';
|
| Databricks-Dateisystem-Hilfsprogramme |
dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/")
%fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/
|
| Databricks-Befehlszeilenschnittstelle | Nicht unterstützt |
| Databricks-REST-API | Nicht unterstützt |
| Bash-Shellbefehle | Nicht unterstützt |
| Bibliotheksinstallationen | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | Nicht unterstützt |
| Open-Source-Software Python | Nicht unterstützt |
Arbeiten mit Dateien in DBFS-Bereitstellungen und DBFS-Stamm
Wichtig
Sowohl DBFS-Root als auch DBFS-Einhängepunkte sind veraltet und werden von Databricks nicht empfohlen. Neue Konten werden ohne Zugriff auf diese Features bereitgestellt. Databricks empfiehlt stattdessen die Verwendung von Unity-Katalogvolumes, externen Speicherorten oder Arbeitsbereichsdateien .
| Werkzeug | Beispiel |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL und Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Databricks-Dateisystem-Hilfsprogramme | dbutils.fs.ls("/mnt/path")%fs ls /mnt/path |
| Databricks-Befehlszeilenschnittstelle | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks-REST-API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash-Shellbefehle | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Bibliotheksinstallationen | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| Open-Source-Software Python | os.listdir('/dbfs/mnt/path/to/directory') |
Anmerkung
Das dbfs:/ Schema ist erforderlich, wenn Sie mit der Databricks CLI arbeiten.
Arbeiten mit Dateien im kurzlebigen Speicher, der an den Treiberknoten angefügt ist
Der an den Treiberknoten angefügte kurzlebige Speicher ist Blockspeicher mit integriertem POSIX-basierten Pfadzugriff. Alle an diesem Speicherort gespeicherten Daten werden ausgeblendet, wenn ein Cluster beendet oder neu gestartet wird.
| Werkzeug | Beispiel |
|---|---|
| Apache Spark | Nicht unterstützt |
| Spark SQL und Databricks SQL | Nicht unterstützt |
| Databricks-Dateisystem-Hilfsprogramme | dbutils.fs.ls("file:/path")%fs ls file:/path |
| Databricks-Befehlszeilenschnittstelle | Nicht unterstützt |
| Databricks-REST-API | Nicht unterstützt |
| Bash-Shellbefehle | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Bibliotheksinstallationen | Nicht unterstützt |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| Open-Source-Software Python | os.listdir('/path/to/directory') |
Anmerkung
Das file:/ Schema ist beim Arbeiten mit Databricks Utilities erforderlich.
Daten von flüchtigem Speicher in Volumes verschieben
Möglicherweise möchten Sie mithilfe von Apache Spark auf heruntergeladene oder gespeicherte Daten im kurzlebigen Speicher zugreifen. Da der kurzlebige Speicher an den Treiber angefügt ist und Spark ein verteiltes Verarbeitungsmodul ist, können nicht alle Vorgänge hier direkt auf Daten zugreifen. Angenommen, Sie müssen Daten aus dem Treiberdateisystem in Unity-Katalogvolumes verschieben. In diesem Fall können Sie Dateien mit Magic Commands oder den Databricks Hilfsprogrammenkopieren, wie in den folgenden Beispielen gezeigt:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>