Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Databricks-Notizbücher unterstützen Codeformatierung, AutoVervollständigen, mehrere Sprachen und Zauberbefehle zum Entwickeln von Code in Python, SQL, Scala und R.
Weitere Informationen zu erweiterten Funktionen, die im Editor verfügbar sind, z. B. AutoVervollständigen, Variable Auswahl, Unterstützung für mehrere Cursor und parallele Diffs, finden Sie unter Navigieren im Databricks-Notizbuch und im Datei-Editor.
Wenn Sie das Notizbuch oder den Datei-Editor verwenden, steht Genie Code zur Verfügung, um Code zu generieren, zu erläutern und zu debuggen. Weitere Informationen finden Sie unter Verwenden von Genie Code .
Databricks-Notizbücher enthalten auch einen integrierten interaktiven Debugger für Python-Notizbücher. Siehe Debug Databricks-Notizbücher.
Wichtig
Das Notizbuch muss an eine aktive Compute-Sitzung angefügt werden, um Codeunterstützungsfeatures wie AutoVervollständigen, Python Codeformatierung und den Debugger zu unterstützen.
Modularisieren des Codes
Mit Databricks Runtime 11.3 LTS und höher können Sie Quellcodedateien im Azure Databricks Arbeitsbereich erstellen und verwalten und diese dann nach Bedarf in Ihre Notizbücher importieren.
Weitere Informationen zum Arbeiten mit Quellcodedateien finden Sie unter Code zwischen Databricks-Notebooks teilen und Mit Python- und R-Modulen arbeiten.
Formatieren von Codezellen
Azure Databricks bietet Tools, mit denen Sie Python und SQL-Code in Notizbuchzellen formatieren können. Diese Tools reduzieren den Aufwand für die Formatierung Ihres Codes und tragen dazu bei, in allen Notebooks die gleichen Codierungsstandards umzusetzen.
Python Black-Formatierer-Bibliothek
Wichtig
Dieses Feature befindet sich in der Public Preview.
Azure Databricks unterstützt Python Codeformatierung mithilfe von black innerhalb des Notizbuchs. Das Notizbuch muss an einen Cluster angefügt werden, wobei black und tokenize-rt Python Pakete installiert sind.
In Databricks Runtime 11.3 LTS und höher installiert Azure Databricks black und tokenize-rt vorab. Sie können den Formatierer direkt verwenden, ohne diese Bibliotheken installieren zu müssen.
Unter Databricks Runtime 10.4 LTS und früher müssen Sie black==22.3.0 und tokenize-rt==4.2.1 aus PyPI in Ihrem Notebook oder Cluster installieren, um den Python-Formatierer nutzen zu können. Sie können den folgenden Befehl in Ihrem Notebook ausführen:
%pip install black==22.3.0 tokenize-rt==4.2.1
oder die Bibliothek auf Ihrem Cluster installieren.
Weitere Informationen zum Installieren von Bibliotheken finden Sie unter Python Umgebungsverwaltung.
Für Dateien und Notizbücher in Den Git-Ordnern von Databricks können Sie den Python Formatierer basierend auf der Datei pyproject.toml konfigurieren. Um dieses Feature zu verwenden, erstellen Sie eine pyproject.toml-Datei im Stammverzeichnis des Git-Ordners, und konfigurieren Sie sie gemäß dem Konfigurationsformat „Black“. Bearbeiten Sie den Abschnitt [tool.black] in der Datei. Die Konfiguration wird angewendet, wenn Sie eine beliebige Datei und ein Notebook in diesem Git-Ordner formatieren.
Wie sie Python- und SQL-Zellen formatieren
Sie benötigen die KANN BEARBEITEN-Berechtigung für das Notebook, um Code zu formatieren.
Azure Databricks verwendet einen benutzerdefinierten SQL-Formatierer zum Formatieren von SQL und black Codeformatierer für Python.
Sie können die Formatierung auf folgende Weise auslösen:
Format einer einzelnen Zelle
- Tastenkombination: Drücken Sie CMD+UMSCHALT+F.
- Befehlskontextmenü:
- SQL-Zelle formatieren: Wählen Sie SQL formatieren im Befehlskontext-Dropdownmenü einer SQL-Zelle aus. Dieses Menüelement ist nur in SQL-Notebookzellen oder in Zellen mit einem
%sqlSprach-Magic-Befehl sichtbar. - Python-Zelle formatieren: Wählen Sie Python formatieren im Befehlskontext-Dropdownmenü einer Python-Zelle aus. Dieses Menüelement ist nur in Python Notebook-Zellen oder in solchen mit einer
%pythonSprache-Magie sichtbar.
- SQL-Zelle formatieren: Wählen Sie SQL formatieren im Befehlskontext-Dropdownmenü einer SQL-Zelle aus. Dieses Menüelement ist nur in SQL-Notebookzellen oder in Zellen mit einem
- Menü Bearbeiten eines Notebooks: Wählen Sie eine Python- oder SQL-Zelle aus, und wählen Sie dann Bearbeiten > Zelle(n) formatieren aus.
Formatieren mehrerer Zellen
Aktivieren Sie mehrere Zellen und dann Auswählen Bearbeiten > Format Zelle(n). Wenn Sie Zellen mehrerer Sprachen auswählen, werden nur SQL und Python Zellen formatiert. Dies schließt auch Zellen mit Verwendung von
%sqlund%pythonein.Formatieren Sie alle Python- und SQL-Zellen im Notizbuch
Wählen Sie Bearbeiten > Notebook formatieren aus. Wenn Ihr Notizbuch mehrere Sprachen enthält, werden nur SQL und Python Zellen formatiert. Dies schließt auch Zellen mit Verwendung von
%sqlund%pythonein.
Informationen zum Anpassen der Formatierung Ihrer SQL-Abfragen finden Sie unter SQL-Anweisungen im benutzerdefinierten Format.
Einschränkungen der Codeformatierung
- Black erzwingt PEP 8-Standards für einen Einzug aus 4 Leerzeichen. Der Einzug ist nicht konfigurierbar.
- Das Formatieren eingebetteter Python Zeichenfolgen in einer SQL-UDF wird nicht unterstützt. Ebenso wird das Formatieren von SQL-Zeichenfolgen in einer Python UDF nicht unterstützt.
Codesprachen in Notebooks
Standardsprache festlegen
Die Standardsprache für das Notizbuch wird unterhalb des Notizbuchnamens angezeigt.

Um die Standardsprache zu ändern, klicken Sie auf die Schaltfläche „Sprache“, und wählen Sie im Dropdownmenü die neue Sprache aus. Um sicherzustellen, dass vorhandene Befehle weiterhin funktionieren, wird Befehlen der vorherigen Standardsprache automatisch ein Magic-Befehl für Sprache vorangestellt.
Mix Sprachen
Standardmäßig verwenden Zellen die Standardsprache des Notebooks. Sie können die Standardsprache in einer Zelle überschreiben, indem Sie auf die Schaltfläche „Sprache“ klicken und eine Sprache aus dem Dropdownmenü auswählen.
Alternativ können Sie den Sprachzauberbefehl %<language> am Anfang einer Zelle verwenden. Die unterstützten Magic-Befehle sind: %python, %r, %scala und %sql.
Hinweis
Wenn Sie einen Magic-Befehl für Sprache aufrufen, wird der Befehl an die REPL im Ausführungskontext für das Notebook gesendet. Variablen, die in einer Sprache (und somit in der REPL für diese Sprache) definiert sind, sind in der REPL einer anderen Sprache nicht verfügbar. REPLs können den Status nur über externe Ressourcen wie Dateien im DBFS oder Objekte im Objektspeicher gemeinsam nutzen.
Notebooks unterstützen auch einige zusätzliche Magic-Befehle:
-
%sh: Ermöglicht Ihnen, Shell-Code in Ihrem Notizbuch auszuführen. Fügen Sie die Option-ehinzu, damit die Zelle einen Fehler auslöst, wenn der Shellbefehl einen Beendigungsstatus ungleich null aufweist. Dieser Befehl wird nur auf dem Apache Spark-Treiber und nicht auf den Workern ausgeführt. Um einen Shellbefehl auf allen Knoten auszuführen, verwenden Sie ein Initialisierungsskript. -
%fs: Ermöglicht die Nutzung vondbutilsDateisystembefehlen. Um beispielsweise den Befehldbutils.fs.lszum Auflisten von Dateien auszuführen, können Sie stattdessen%fs lsangeben. Weitere Informationen finden Sie unter Work with files on Azure Databricks. -
%md: Ermöglicht Ihnen, verschiedene Arten von Dokumentation einzuschließen, einschließlich Text, Bilder und mathematische Formeln und Gleichungen. Siehe nächster Abschnitt.
SQL-Syntax-Hervorhebung und Autovervollständigung in Python-Befehlen
Syntaxmarkierung und SQL autocomplete sind verfügbar, wenn Sie SQL in einem Python-Befehl verwenden, z. B. in einem Befehl spark.sql.
SQL-Zellenergebnisse erkunden
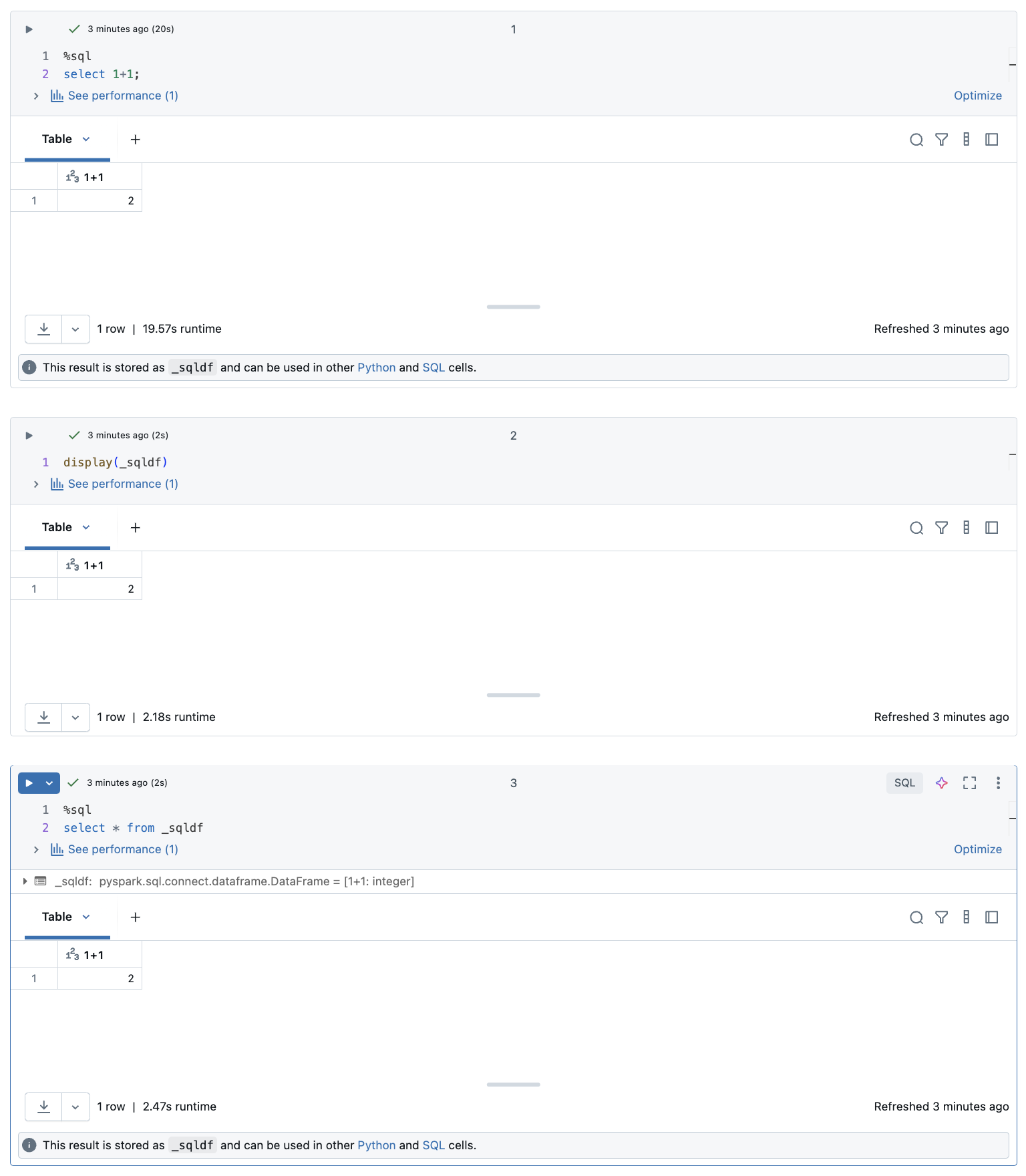
In einem Databricks-Notizbuch werden Ergebnisse aus einer SQL-Sprachen-Zelle automatisch als impliziter DataFrame verfügbar gemacht, der der Variable „_sqldf“ zugewiesen wird. Sie können diese Variable dann in allen Python- und SQL-Zellen verwenden, die Sie danach ausführen, unabhängig von ihrer Position im Notizbuch.
Hinweis
Für diese Funktion gelten folgende Einschränkungen:
- Die
_sqldfVariable ist in Notebooks, die ein SQL-Lagerort für Compute nutzen, nicht verfügbar. - Die Verwendung von
_sqldfin nachfolgenden Python Zellen wird in Databricks Runtime 13.3 und höher unterstützt. - Die Verwendung von
_sqldfin nachfolgenden SQL-Zellen wird nur auf Databricks Runtime 14.3 und höher unterstützt. - Wenn die Abfrage die Schlüsselwörter
CACHE TABLEoderUNCACHE TABLEverwendet, ist die Variable_sqldfnicht verfügbar.
Der folgende Screenshot zeigt, wie _sqldf in nachfolgenden Python- und SQL-Zellen verwendet werden kann:
Wichtig
Die Variable _sqldf wird jedes Mal neu zugewiesen, wenn eine SQL-Zelle ausgeführt wird. Um den Verweis auf ein spezifisches DataFrame-Ergebnis nicht zu verlieren, weisen Sie es einem neuen Variablennamen zu, bevor Sie die nächste SQL-Zelle ausführen:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Ausführen von SQL-Zellen parallel
Während ein Befehl ausgeführt wird und Ihr Notebook an einen interaktiven Cluster angefügt ist, können Sie eine SQL-Zelle gleichzeitig mit dem aktuellen Befehl ausführen. Die SQL-Zelle wird in einer neuen parallelen Sitzung ausgeführt.
So führen Sie eine Zelle parallel aus:
Führen Sie die Zelle aus.
Klicken Sie auf Jetzt ausführen. Die Zelle wird sofort ausgeführt.
Da die Zelle in einer neuen Sitzung ausgeführt wird, werden temporäre Ansichten, UDFs und die implicit Python DataFrame (_sqldf) nicht für Zellen unterstützt, die parallel ausgeführt werden. Darüber hinaus werden die Standardkatalog- und Datenbanknamen während der parallelen Ausführung verwendet. Wenn Ihr Code auf eine Tabelle in einem anderen Katalog oder in einer anderen Datenbank verweist, müssen Sie den Tabellennamen mithilfe des dreiteiligen Namespace (catalog.schema.table) angeben.
Ausführen von SQL-Zellen in einem SQL-Lagerhaus
Sie können SQL-Befehle in einem Databricks-Notebook in einem SQL-Warehouse ausführen, einem Computetyp, der für SQL-Analysen optimiert ist. Weitere Informationen finden Sie unter Verwenden eines Notebooks mit einem SQL-Warehouse.
Verwenden von Magischen Befehlen
Databricks-Notizbücher unterstützen verschiedene Magische Befehle, die Funktionen über die Standardsyntax hinaus erweitern, um allgemeine Aufgaben zu vereinfachen. Zeilen-Magics werden mit % versehen und auf eine einzelne Zeile angewendet. Zellen-Magie ist mit dem Präfix %% versehen und wird auf den gesamten Zelleninhalt angewendet.
| Magic-Befehl | Beispiel | Beschreibung |
|---|---|---|
%python |
%pythonprint("Hello") |
Wechseln Sie die Zellsprache zu Python. Führt Python Code in der Zelle aus. |
%r |
%rprint("Hello") |
Ändern Sie die Zellensprache auf R. Führt R-Code in der Zelle aus. |
%scala |
%scalaprintln("Hello") |
Wechseln Sie die Sprache der Zelle zu Scala. Führt Scala-Code in der Zelle aus. |
%sql |
%sqlSELECT * FROM table |
Wechseln der Zellensprache zu SQL. Ergebnisse sind als _sqldf in Python/SQL-Zellen verfügbar. |
%md |
%md# TitleContent here |
Wechseln Sie die Zellensprache auf Markdown. Rendert Markdown-Inhalt in der Zelle. Unterstützt Text, Bilder, Formeln und LaTeX. |
%pip |
%pip install pandas |
Installieren Sie Python-Pakete (im Notebook-spezifischen Bereich). Informationen finden Sie unter Python-Bibliotheken im Notebook-Bereich. |
%run |
%run /path/to/notebook |
Führen Sie ein anderes Notizbuch aus, und importieren Sie deren Funktionen und Variablen. Siehe Notizbuchworkflows. |
%fs |
%fs ls /path |
Führen Sie Dbutils-Dateisystembefehle aus. Kurzform für dbutils.fs Befehle. Siehe "Arbeiten mit Dateien". |
%sh |
%sh ls -la |
Führen Sie Shellbefehle aus. Wird nur auf Treiberknoten ausgeführt. Verwenden Sie -e, um im Fehlerfall ein Fehlschlagen zu verursachen. |
%tensorboard |
%tensorboard --logdir /logs |
Zeigt die TensorBoard-UI inline an. Nur für Databricks Runtime ML verfügbar. Siehe TensorBoard. |
%set_cell_max_output_size_in_mb |
%set_cell_max_output_size_in_mb 10 |
Legen Sie die maximale Zellenausgabegröße fest. Bereich: 1-20 MB. Gilt für alle nachfolgenden Zellen im Notizbuch. |
%skip |
%skipprint("This won't run") |
Überspringen der Zellausführung. Verhindert, dass die Zelle bei Ausführung des Notebooks ausgeführt wird. |
%%profile |
%%profilemy_function() |
Profilerstellung für Python-Code-Ausführung. Zeigt eine hierarchische Aufrufstruktur mit Zeitinformationen an. Erfordert Databricks Runtime 17.2 und höher. |
%%oprofile |
%%oprofilemy_function() |
Profilobjekterstellung während der Zellausführung. Zeigt eine Tabelle mit neuen Net-Objekten an, die nach Typ gruppiert wurden. Erfordert Databricks Runtime 17.2 und höher. |
%uv pip |
%uv pip install simplejson |
Installieren und verwalten Sie Python-Pakete (auf Notizbuchebene) mit uv und pip-Standardunterbefehlen (install, uninstall, list, show, freeze, check, tree). Siehe schnellere Installationen mit %uv pip. |
Hinweis
IPython Automagic: Databricks-Notizbücher haben standardmäßig IPython Automagic aktiviert, sodass bestimmte Befehle wie pip ohne das %-Präfix funktionieren können. Funktioniert z. B pip install pandas . genauso wie %pip install pandas.
Wichtig
- Variablen und Zustand sind zwischen verschiedenen Sprach-REPLs isoliert. Beispielsweise sind Python-Variablen in Scala-Zellen nicht zugreifbar.
- Eine Notebookzelle kann nur einen magischen Zellenbefehl haben, und sie muss die erste Zeile der Zelle sein.
-
%runmuss sich in einer eigenen Zelle befinden, da hiermit das gesamte Notebook inline ausgeführt wird. - Wenn Sie
%pipauf Databricks Runtime 12.2 LTS und darunter verwenden, platzieren Sie alle Paketinstallationsbefehle am Anfang Ihres Notizbuchs, da der Python-Zustand nach der Installation zurückgesetzt wird.