Konfigurieren von Compute für Aufträge
Dieser Artikel enthält Empfehlungen und Ressourcen zum Konfigurieren von Compute für Databricks-Aufträge.
Wichtig
Einschränkungen für das serverlose Computing von Aufträgen umfassen Folgendes:
- Keine Unterstützung für kontinuierliche Planung.
- Keine Unterstützung für Standard- oder zeitbasierte Intervalltrigger im strukturierten Streaming.
Weitere Einschränkungen finden Sie unter Beschränkungen von serverlosem Computing.
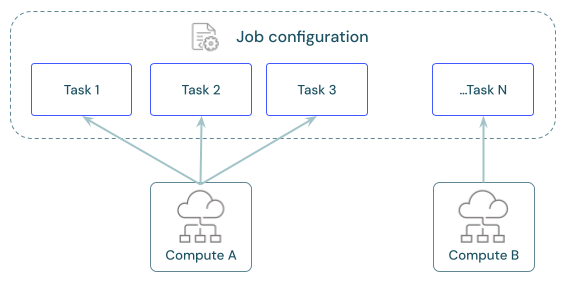
Jeder Auftrag kann eine oder mehrere Aufgaben enthalten. Sie definieren Computing-Ressourcen für jede Aufgabe. Mehrere Aufgaben, die für denselben Auftrag definiert sind, können dieselbe Computing-Ressource verwenden.
Was ist das empfohlene Computing für jede Aufgabe?
In der folgenden Tabelle sind die empfohlenen und unterstützten Computing-Typen für jeden Aufgabentyp aufgeführt.
Hinweis
Serverloses Computing für Aufträge unterliegt Einschränkungen und unterstützt nicht alle Workloads. Siehe Beschränkungen von serverlosem Computing.
| Aufgabe | Empfohlenes Compute | Unterstütztes Compute |
|---|---|---|
| Notebooks | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| Python-Skript | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| Python-Wheel | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| SQL | Serverloses SQL-Warehouse | Serverloses SQL-Warehouse, Pro-SQL-Warehouse |
| Delta Live Tables-Pipeline | Serverlose Pipeline | Serverlose Pipeline, klassische Pipeline |
| dbt | Serverloses SQL-Warehouse | Serverloses SQL-Warehouse, Pro-SQL-Warehouse |
| dbt CLI-Befehle | Serverlose Aufträge | Serverlose Aufträge, klassische Aufträge, klassische Allzweckaufträge |
| JAR | Klassische Aufträge | Klassische Aufträge, klassische Allzweckaufträge |
| Spark-Submit | Klassische Aufträge | Klassische Aufträge |
Die Preise für Aufträge sind an das für die Ausführung von Aufgaben verwendete Computing gebunden. Weitere Informationen finden Sie unter Databricks Preise.
Wie konfiguriere ich Compute für Aufträge?
Bei klassischen Aufträgen wird die Berechnung direkt über die Benutzeroberfläche von Databricks Jobs konfiguriert. Diese Konfigurationen sind Teil der Auftragsdefinition. Alle anderen verfügbaren Compute-Typen speichern ihre Konfigurationen in anderen Arbeitsbereichsressourcen. Weitere Informationen hierzu finden Sie in der folgenden Tabelle:
| Computetyp | Details |
|---|---|
| Klassisches Jobs Compute | Sie konfigurieren das Computing für klassische Aufträge mit der gleichen Benutzeroberfläche und den gleichen Einstellungen wie für die universelle Rechenleistung. Siehe Computekonfigurationsreferenz. |
| Serverloses Computing für Aufträge | Serverloses Computing für Aufträge ist die Standardeinstellung für alle Aufgaben, die sie unterstützen. Databricks verwaltet Computing-Einstellungen für das serverlose Computing. Weitere Informationen finden Sie unter Ausführen Ihres Azure Databricks-Auftrags mit serverlosem Computing für Workflows. nn Ein Arbeitsbereich-Administrator muss das serverlose Computing aktivieren, damit diese Option sichtbar ist. Weitere Informationen finden Sie unter Aktivieren des serverlosen Computings. |
| SQL-Warehouses | Serverlose und pro SQL-Lagerorte werden von Arbeitsbereich-Administratoren oder Benutzern mit uneingeschränkten Berechtigungen zur Cluster-Erstellung konfiguriert. Sie konfigurieren Aufgaben für die Ausführung für vorhandene SQL-Lagerorte. Siehe Herstellen einer Verbindung mit einem SQL-Warehouse. |
| Delta Live Tables-Pipelineberechnungen | Sie konfigurieren Computing-Einstellungen für Delta Live Tables-Pipelines während der Pipeline-Konfiguration. Siehe Konfigurieren der Compute für eine Delta Live Tables-Pipeline. nn Azure Databricks verwaltet Computing-Ressourcen für serverlose Delta Live Tables-Pipelines. Siehe Konfigurieren einer serverlosen Delta Live Tables-Pipeline. |
| All-Purpose compute | Sie können Aufgaben optional mithilfe von klassischem All-Purpose Compute konfigurieren. Databricks empfiehlt diese Konfiguration nicht für Produktionsaufträge. Siehe Computekonfigurationsreferenz und Sollte All-Purpose Compute jemals für Aufträge verwendet werden?. |
Freigeben von Compute über Aufgaben hinweg
Konfigurieren Sie Tasks so, dass sie dieselben Job-Rechenressourcen verwenden, um die Ressourcennutzung mit Jobs zu optimieren, die mehrere Tasks orchestrieren. Die Freigabe von Compute über Aufgaben hinweg kann die Wartezeit reduzieren, die mit Startzeiten verbunden ist.
Sie können eine einzelne Compute-Ressource verwenden, um alle Aufgaben auszuführen, die Teil des Auftrags sind, oder mehrere Auftragsressourcen, die für bestimmte Workloads optimiert sind. Jede als Teil eines Auftrags konfigurierte Auftragsberechnung ist für alle anderen Aufgaben in diesem Auftrag verfügbar.
Die folgende Tabelle zeigt die Unterschiede zwischen der für eine einzelne Aufgabe konfigurierten Auftragsberechnung und der von mehreren Aufgaben gemeinsam genutzten Auftragsberechnung:
| Einzelne Aufgabe | Gemeinsame Nutzung über Aufgaben hinweg | |
|---|---|---|
| Starten | Wenn der Aufgabenlauf beginnt. | Wenn der erste für die Nutzung der Computing-Ressource konfigurierte Aufgabenlauf beginnt. |
| Terminate | Nach Ausführung der Aufgabe. | Nachdem die letzte Aufgabe, die für die Nutzung der Computing-Ressource konfiguriert wurde, ausgeführt wurde. |
| Compute im Leerlauf | Nicht zutreffend. | Compute bleibt eingeschaltet und im Leerlauf, während Aufgaben ausgeführt werden, die die Computing-Ressource nicht verwenden. |
Ein freigegebener Auftragscluster ist auf eine einzelne Auftragsausführung beschränkt und kann nicht von anderen Aufträgen oder Ausführungen desselben Auftrags verwendet werden.
Bibliotheken können in einer Konfiguration für einen freigegebenen Auftragscluster nicht deklariert werden. Sie müssen abhängige Bibliotheken in den Aufgabeneinstellungen hinzufügen.
Überprüfen, Konfigurieren und Austauschen von Aufträgen
Der Abschnitt Compute im Fenster Job-Details listet alle für Aufgaben im aktuellen Job konfigurierten Berechnungen auf.
Aufgaben, die für die Verwendung einer Computing-Ressource konfiguriert sind, werden im Aufgabendiagramm hervorgehoben, wenn Sie den Mauszeiger über die Spezifikation der Computing-Ressource bewegen.
Verwenden Sie die Schaltfläche Austauschen, um die Berechnung für alle mit einer Computing-Ressource verbundenen Vorgänge zu ändern.
Klassische Aufträgen mit Compute-Ressourcen verfügen über eine Option Konfigurieren. Andere Compute-Ressourcen bieten Ihnen Optionen zum Anzeigen und Ändern von Details der Compute-Konfiguration.
Empfehlungen für die Konfiguration der Berechnung von klassischen Aufträgen
Dieser Abschnitt konzentriert sich auf allgemeine Empfehlungen zu Funktionen und Konfigurationen, die für bestimmte Workflows von Vorteil sein können. Spezifische Empfehlungen für die Konfiguration der Größe und der Arten von Computing-Ressourcen hängen vom jeweiligen Workload ab.
Databricks empfiehlt die Aktivierung von Photon Acceleration, die Verwendung aktueller Databricks Runtime-Versionen und die Verwendung von für Unity Catalog konfiguriertem Compute.
Serverloses Computing für Aufträge verwaltet alle Infrastruktur, ohne die folgenden Überlegungen zu berücksichtigen. Weitere Informationen finden Sie unter Ausführen Ihres Azure Databricks-Auftrags mit serverlosem Computing für Workflows.
Hinweis
Für strukturierte Streaming-Workflows gibt es spezielle Empfehlungen. Weitere Informationen finden Sie unter Produktionsüberlegungen für strukturiertes Streaming.
Verwenden des Zugriffsmodus „Freigegeben“
Databricks empfiehlt die Verwendung des Zugriffsmodus „Freigegeben“ für alle Aufträge. Weitere Informationen finden Sie unter Zugriffsmodi.
Hinweis
Der Modus für den gemeinsamen Zugriff unterstützt einige Workloads und Features nicht. Databricks empfiehlt für diese Workloads die Verwendung des Einzelbenutzer-Zugriffsmodus. Siehe Einschränkungen des Computezugriffsmodus für Unity Catalog.
Verwenden von Clusterrichtlinien
Databricks empfiehlt, dass Arbeitsbereich-Administratoren Cluster-Richtlinien für Jobs definieren und diese Richtlinien für alle Benutzer durchsetzen, die Jobs konfigurieren.
Mithilfe von Clusterrichtlinien können Arbeitsbereich-Administratoren Kostenkontrollen festlegen und die Konfigurationsoptionen von Benutzern einschränken. Einzelheiten zur Konfiguration von Cluster-Richtlinien finden Sie unter Erstellen und Verwalten von Compute-Richtlinien.
Azure Databricks bietet eine für Aufträge konfigurierte Standardrichtlinie. Administratoren können diese Richtlinie für andere Arbeitsbereichsbenutzer verfügbar machen. Siehe Jobs Compute.
Nutzung der automatischen Skalierung
Konfigurieren Sie die automatische Skalierung so, dass lang laufende Aufgaben dynamisch Arbeitsknoten während der Auftragsausführung hinzufügen und entfernen können. Siehe Aktivieren der automatischen Skalierung
Verwende einen Pool, um Cluster-Startzeiten zu reduzieren
Mit Computepools können Sie Computing-Ressourcen von Ihrem Cloudanbieter reservieren. Pools sind vorteilhaft, um die Startzeit neuer Job-Cluster zu verkürzen und die Verfügbarkeit von Computing-Ressourcen zu gewährleisten. Siehe Poolkonfigurationsreferenz.
Verwenden von Spot-Instanzen
Konfigurieren Sie Spot-Instances für Workloads, die geringe Latenzanforderungen haben, um die Kosten zu optimieren. Siehe Spot-Instanzen.
Sollte All-Purpose Compute jemals für Aufträge verwendet werden?
Es gibt zahlreiche Gründe, warum Databricks davon abrät, All-Purpose Compute für Aufträge zu verwenden, darunter die folgenden:
- Azure Databricks rechnet All-Purpose Compute zu einem anderen Satz ab als Jobs Compute.
- Jobs Compute wird automatisch beendet, wenn ein Joblauf abgeschlossen ist. All-Purpose Compute unterstützt die automatische Beendigung, die an Inaktivität und nicht an das Ende eines Joblaufs gebunden ist.
- All-Purpose Compute wird häufig von mehreren Benutzerteams gemeinsam genutzt. Bei Aufträgen, die für All-Purpose Compute geplant sind, kommt es aufgrund des Wettbewerbs um Computing-Ressourcen häufig zu längeren Wartezeiten.
- Viele Empfehlungen zur Optimierung der Konfiguration von Jobs Compute sind für die Art von Ad-hoc-Abfragen und interaktiven Workloads, die auf All-Purpose-Compute ausgeführt werden, nicht geeignet.
Im Folgenden finden Sie Anwendungsfälle, in denen Sie sich für die Verwendung von All-Purpose Compute für Aufträge entscheiden können:
- Sie entwickeln oder testen iterativ neue Aufgaben. Die Startzeiten für die Berechnung von Aufträgen können die iterative Entwicklung langwierig machen. All-Purpose Compute ermöglicht es Ihnen, Änderungen anzuwenden und Ihren Auftrag schnell auszuführen.
- Sie verfügen über kurzlebige Aufträge, die häufig oder in einem bestimmten Zeitplan ausgeführt werden müssen. Es gibt keine Anlaufzeit, die dem derzeit laufenden All-Purpose-Compute zugeordnet ist. Berücksichtigen Sie die Kosten, die mit Leerlaufzeiten verbunden sind, wenn Sie dieses Muster verwenden.
Serverloses Computing für Aufträge ist der empfohlene Ersatz für die meisten Aufgabentypen, die Sie mit All-Purpose Compute ausführen möchten.