Einführung in Databricks Lakehouse Monitoring
Wichtig
Dieses Feature befindet sich in der Public Preview.
In diesem Artikel wird Databricks Lakehouse Monitoring beschrieben. Er behandelt die Vorteile der Überwachung Ihrer Daten und bietet einen Überblick über die Komponenten und die Nutzung von Databricks Lakehouse Monitoring.
Mit Databricks Lakehouse Monitoring können Sie die statistischen Eigenschaften und die Qualität der Daten in allen Tabellen in Ihrem Konto überwachen. Sie können das Feature auch verwenden, um die Leistung von Machine Learning-Modellen und Modellbereitstellungsendpunkten nachzuverfolgen, indem Sie Rückschlusstabellen überwachen, die Modellausgaben und Vorhersagen enthalten. Das Diagramm zeigt den Datenfluss durch Daten- und ML-Pipelines in Databricks und veranschaulicht, wie Sie die Überwachung verwenden können, um die Datenqualität und Modellleistung kontinuierlich nachzuverfolgen.
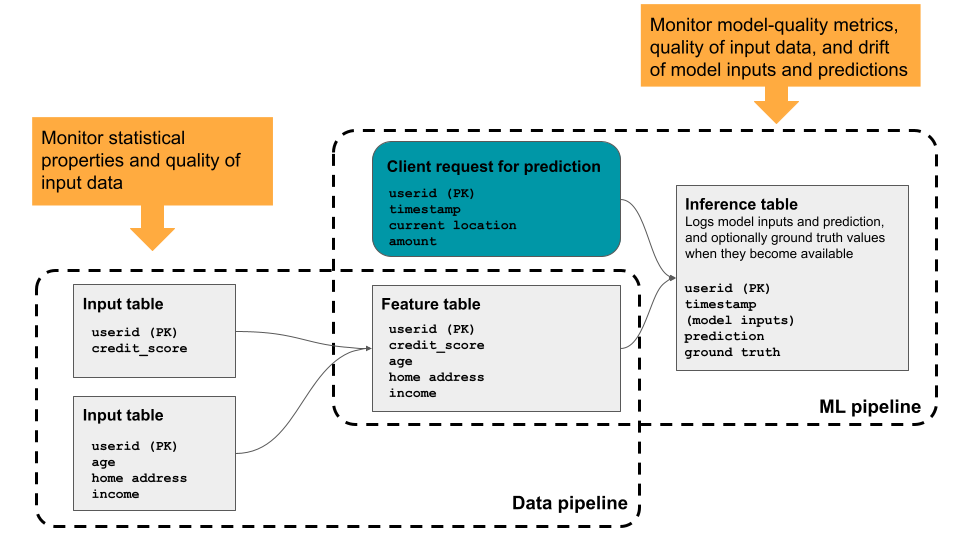
Gründe für die Verwendung von Databricks Lakehouse Monitoring
Um nützliche Erkenntnisse aus Ihren Daten zu gewinnen, müssen Sie auf die Qualität Ihrer Daten vertrauen können. Die Überwachung Ihrer Daten bietet quantitative Measures, mit denen Sie die Qualität und Konsistenz Ihrer Daten im Laufe der Zeit nachverfolgen und bestätigen können. Wenn Sie Änderungen an der Datenverteilung Ihrer Tabelle oder an der Leistung des entsprechenden Modells erkennen, können die von Databricks Lakehouse Monitoring erstellten Tabellen die Änderung erfassen, Sie darauf aufmerksam machen und Ihnen helfen, die Ursache zu identifizieren.
Databricks Lakehouse Monitoring hilft Ihnen bei der Beantwortung von Fragen wie den folgenden:
- Wie sieht die Datenintegrität aus und wie ändert sie sich im Laufe der Zeit? Was ist beispielsweise der Bruchteil der NULL- oder Nullwerte in den aktuellen Daten und hat er sich erhöht?
- Wie sieht die statistische Verteilung der Daten aus und wie verändert sie sich im Laufe der Zeit? Was ist beispielsweise das 90. Perzentil einer numerischen Spalte? Oder wie ist die Verteilung von Werten in einer kategoriebasierten Spalte und wie unterscheidet sie sich von gestern?
- Gibt es Abweichungen zwischen den aktuellen Daten und einer bekannten Baseline oder zwischen aufeinander folgenden Zeitfenstern der Daten?
- Wie sieht die statistische Verteilung oder Abweichung einer Teilmenge oder eines Slices der Daten aus?
- Wie verschieben sich ML-Modelleingaben und Vorhersagen im Laufe der Zeit?
- Wie ist die Modellleistung im Laufe der Zeit im Trend? Ist die Leistung von Modellversion A besser als Version B?
Darüber hinaus können Sie mit Databricks Lakehouse Monitoring die Zeitgranularität von Beobachtungen steuern und benutzerdefinierte Metriken einrichten.
Anforderungen
Für die Verwendung der Databricks Lakehouse-Überwachung müssen folgende Voraussetzungen erfüllt sein:
- Ihr Arbeitsbereich muss für Unity Catalog aktiviert sein und Sie müssen Zugriff auf Databricks SQL haben.
- Für die Überwachung werden nur Delta-Tabellen, einschließlich verwaltete Tabellen, externe Tabellen, Sichten, materialisierte Sichten und Streamingtabellen unterstützt. Überwachungen, die über materialisierte Sichten und Streamingtabellen erstellt wurden, unterstützen keine inkrementelle Verarbeitung.
- Nicht alle Regionen werden unterstützt. Regionale Unterstützung finden Sie unter Azure Databricks-Regionen.
Hinweis
Bei der Databricks Lakehouse-Überwachung wird serverloses Computing für Workflows verwendet. Informationen zum Nachverfolgen von Lakehouse Monitoring-Ausgaben finden Sie unter Anzeigen von Lakehouse Monitoring-Ausgaben.
Funktionsweise von Lakehouse Monitoring in Databricks
Um eine Tabelle in Databricks zu überwachen, erstellen Sie einen Monitor, der an die Tabelle angefügt ist. Um die Leistung eines Machine Learning-Modells zu überwachen, fügen Sie den Monitor an eine Rückschlusstabelle an, die die Eingaben und die entsprechenden Vorhersagen des Modells enthält.
Databricks Lakehouse Monitoring bietet die folgenden Arten von Analysen: Zeitreihe, Momentaufnahme und Rückschluss.
| Profiltyp | Beschreibung |
|---|---|
| Zeitreihe | Wird für Tabellen verwendet, die ein Zeitreihen-Dataset basierend auf einer Zeitstempelspalte enthalten. Die Überwachung berechnet Datenqualitätsmetriken in zeitbasierten Fenstern der Zeitreihe. |
| Rückschluss | Wird für Tabellen verwendet, die das Anforderungsprotokoll für ein Modell enthalten. Jede Zeile ist eine Anforderung mit Spalten für den Zeitstempel, den Modelleingaben, der entsprechenden Vorhersage und (optional) Der Bodenwahrerbeschriftung. Die Überwachung vergleicht Modellleistungs- und Datenqualitätsmetriken in zeitbasierten Fenstern des Anforderungsprotokolls. |
| Snapshot | Wird für alle anderen Tabellentypen verwendet. Die Überwachung berechnet Datenqualitätsmetriken über alle Daten in der Tabelle. Die vollständige Tabelle wird mit jeder Aktualisierung verarbeitet. |
In diesem Abschnitt werden kurz die von Databricks Lakehouse Monitoring verwendeten Eingabetabellen und die daraus erstellten Metriktabellen beschrieben. Das Diagramm zeigt die Beziehung zwischen den Eingabetabellen, den Metriktabellen, dem Monitor und dem Dashboard.
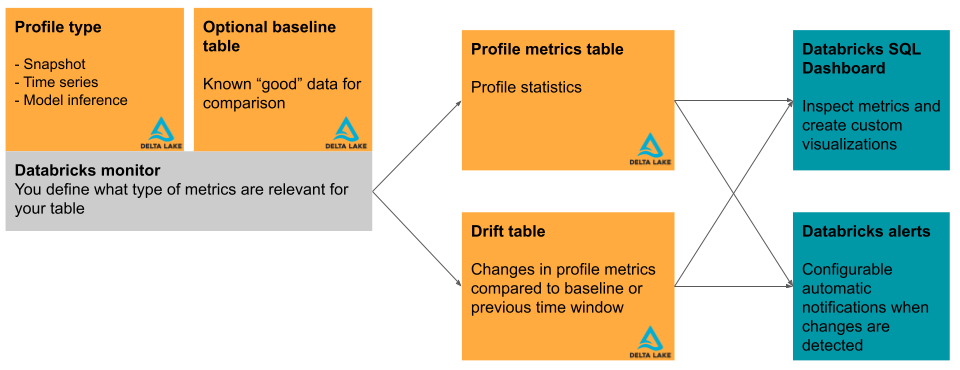
Primäre Tabelle und Basistabelle
Zusätzlich zu der zu überwachenden Tabelle, der so genannten „primären Tabelle“, können Sie optional eine Basistabelle angeben, die als Referenz für die Messung der Drift oder der Veränderung der Werte im Laufe der Zeit verwendet wird. Eine Basistabelle ist nützlich, wenn Sie ein Beispiel dafür haben, wie Ihre Daten aussehen sollen. Die Idee ist, dass die Drift dann relativ zu den erwarteten Datenwerten und Verteilungen berechnet wird.
Die Basistabelle sollte ein Dataset enthalten, das die erwartete Qualität der Eingabedaten in Bezug auf statistische Verteilungen, einzelne Spaltenverteilungen, fehlende Werte und andere Merkmale widerspiegelt. Sie sollte mit dem Schema der überwachten Tabelle übereinstimmen. Die Ausnahme ist die Zeitstempelspalte für Tabellen, die mit Zeitreihen- oder Rückschlussprofilen verwendet werden. Wenn Spalten in der primären Tabelle oder in der Basistabelle fehlen, verwendet die Überwachung eine heuristische Best-Effort-Methode, um die Ausgabemetriken zu berechnen.
Bei Monitoren, die ein Momentaufnahmenprofil verwenden, sollte die Basistabelle eine Momentaufnahme der Daten enthalten, bei denen die Verteilung einen akzeptablen Qualitätsstandard darstellt. Bei Daten zur Notenverteilung könnte man zum Beispiel eine frühere Klasse als Ausgangspunkt nehmen, in der die Noten gleichmäßig verteilt waren.
Für Monitore, die ein Zeitreihenprofil verwenden, sollte die Basistabelle Daten enthalten, die Zeitfenster darstellen, in denen Datenverteilungen einen akzeptablen Qualitätsstandard darstellen. Bei Wetterdaten könnten Sie zum Beispiel eine Woche, einen Monat oder ein Jahr als Basiswert festlegen, in dem die Temperatur nahe an den erwarteten normalen Temperaturen lag.
Bei Monitoren, die ein Rückschlussprofil verwenden, sind die Daten, die zum Trainieren oder Überprüfen des überwachten Modells verwendet wurden, eine gute Wahl für eine Basis. Auf diese Weise können Benutzer gewarnt werden, wenn die Daten im Vergleich zu den Daten, auf denen das Modell trainiert und validiert wurde, abgewichen sind. Diese Tabelle sollte dieselben Featurespalten enthalten wie die primäre Tabelle und zusätzlich die gleiche model_id_col haben, die für das InferenceLog der primären Tabelle festgelegt wurde, damit die Daten konsistent aggregiert werden. Im Idealfall sollte der Test- oder Validierungssatz zum Auswerten des Modells verwendet werden, um vergleichbare Modellqualitätsmetriken sicherzustellen.
Metriktabellen und Dashboard
Ein Tabellenmonitor erstellt zwei Metriktabellen und ein Dashboard. Metrikwerte werden für die gesamte Tabelle und für die Zeitfenster und Datenteilmengen (oder „Slices“) berechnet, die Sie beim Erstellen des Monitors angeben. Darüber hinaus werden für die Rückschlussanalyse Metriken für jede Modell-ID berechnet. Weitere Informationen zu den Metriktabellen finden Sie unter Monitormetriktabellen.
- Die Profilmetriktabelle enthält Zusammenfassungsstatistiken. Weitere Informationen finden Sie unter Schema von Profilmetrikentabellen.
- Die Driftmetriktabelle enthält Statistiken, die sich auf die Abweichung der Daten im Zeitverlauf beziehen. Wenn eine Basistabelle bereitgestellt wird, wird auch die Abweichung relativ zu den Basiswerten überwacht. Weitere Informationen finden Sie im Tabellenschema der Driftmetriken.
Die Metriktabellen sind Delta-Tabellen und werden in einem von Ihnen angegebenen Unity Catalog-Schema gespeichert. Sie können diese Tabellen über die Databricks-Benutzeroberfläche anzeigen, sie mit Databricks SQL abfragen und darauf basierend Dashboards und Warnmeldungen erstellen.
Für jeden Monitor erstellt Databricks automatisch ein Dashboard, das Sie für die Visualisierung und Präsentation der Monitorergebnisse verwenden können. Das Dashboard kann wie jedes andere Legacy-Dashboard vollständig angepasst werden.
Erste Schritte für die Verwendung von Lakehouse Monitoring in Databricks
Hinweise zu den ersten Schritten finden Sie in den folgenden Artikeln:
- Erstellen eines Monitors mithilfe der Databricks-Benutzeroberfläche
- Erstellen eines Monitors mithilfe der API
- Grundlegendes zu Monitormetriktabellen.
- Arbeiten mit dem Monitor-Dashboard
- Erstellen von SQL-Warnungen basierend auf einem Monitor
- Erstellen benutzerdefinierter Metriken
- Überwachen Sie Modellbereitstellungsendpunkte.
- Überwachung von Fairness und Trend für Klassifizierungsmodelle
- Weitere Informationen finden Sie im Referenzmaterial für die Databricks Lakehouse Monitoring-API.
- Beispielnotebooks