Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Nachdem Sie ein Notebook an einen Cluster angefügt und mindestens eine Zelle ausgeführt haben, weist das Notebook einen Status auf und zeigt Ergebnisse an. In diesem Abschnitt wird beschrieben, wie Sie den Status und die Ausgaben von Notebooks verwalten.
Löschen des Status und der Ausgaben von Notebooks
Um den Status und die Ausgaben des Notebooks zu löschen, wählen Sie eine der Löschen-Optionen unten im Ausführen-Menü aus.
| Menüoption | BESCHREIBUNG |
|---|---|
| Alle Zellenausgaben löschen | Löscht die Zellenausgaben. Dies ist nützlich, wenn Sie das Notizbuch freigeben und verhindern möchten, dass Ergebnisse eingeschlossen werden. |
| Status löschen | Löscht den Notebookstatus, einschließlich Funktions- und Variablendefinitionen, Daten und importierten Bibliotheken. |
| Löschen des Status und der Ausgaben | Löscht sowohl Zellenausgaben als auch den Notebook-Status. |
| Status löschen und alle ausführen | Löscht den Status des Notebooks und startet einen neuen Lauf. |
Ergebnistabelle
Wenn eine Zelle ausgeführt wird, werden die Ergebnisse in einer Ergebnistabelle angezeigt. Mit der Ergebnistabelle können Sie folgende Aktionen ausführen:
- Kopieren einer Spalte oder einer anderen Teilmenge von tabellarischen Ergebnissen in die Zwischenablage.
- Führen Sie eine Textsuche über die Ergebnistabelle aus.
- Daten sortieren und filtern
- Navigieren Sie mithilfe der Pfeiltasten auf der Tastatur zwischen Tabellenzellen.
- Wählen Sie einen Teil eines Spaltennamens oder Zellwerts aus, indem Sie auf den gewünschten Text doppelklicken und ziehen.
- Verwenden Sie den Spalten-Explorer , um Spalten zu durchsuchen, ein- oder auszublenden, anzuheften und neu anzuordnen.
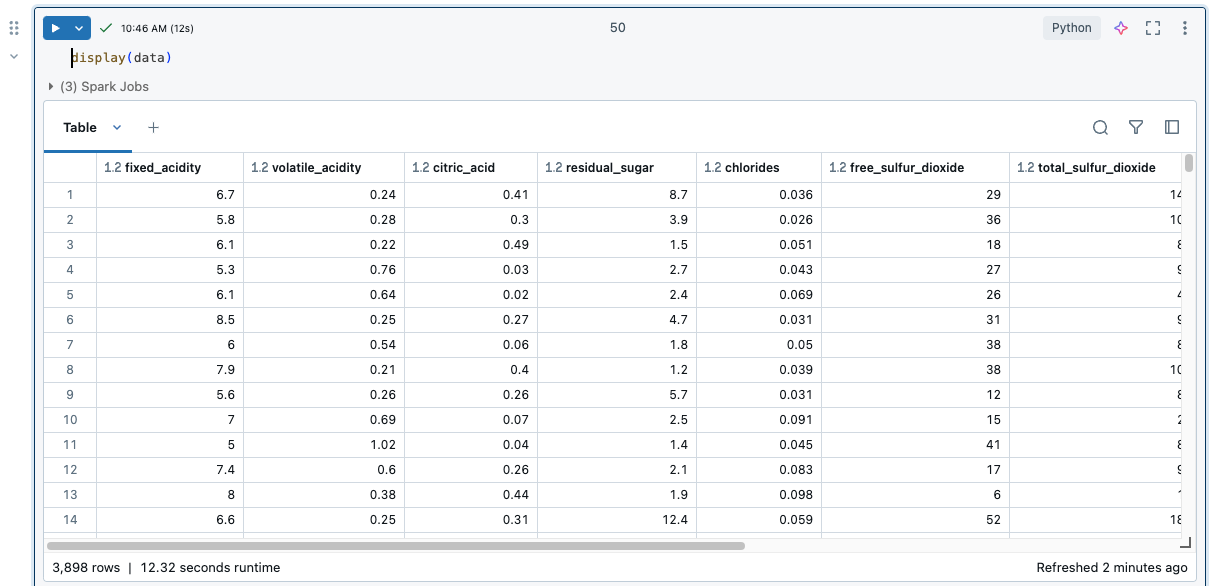
Informationen zum Anzeigen von Grenzwerten für die Ergebnistabelle finden Sie unter Einschränkungen für die Notebook-Ergebnistabelle.
Auswählen von Daten
Gehen Sie wie folgt vor, um Daten aus der Ergebnistabelle auszuwählen.
- Kopieren Sie die Daten oder eine Teilmenge der Daten in die Zwischenablage.
- Klicken Sie auf eine Spalten- oder Zeilenüberschrift.
- Klicken Sie in die obere linke Zelle der Tabelle, um die gesamte Tabelle auszuwählen.
- Ziehen Sie den Cursor über eine beliebige Gruppe von Zellen, um sie auszuwählen.
- Um mehrere Spalten auszuwählen, halten Sie Ctrl (Windows) oder Cmd (macOS) gedrückt, und klicken Sie auf zusätzliche Spaltenüberschriften. Anschließend können Sie mithilfe des
 Aktionen wie Kopieren, Filtern, Formatieren und Anheften gleichzeitig auf alle ausgewählten Spalten anwenden.
Aktionen wie Kopieren, Filtern, Formatieren und Anheften gleichzeitig auf alle ausgewählten Spalten anwenden.
Um einen Seitenbereich mit Auswahlinformationen zu öffnen, klicken Sie in der oberen rechten Ecke neben dem ![]() panel iconSuchfeld auf das Bereichssymbol.
panel iconSuchfeld auf das Bereichssymbol.
![]()
Kopieren von Daten in die Zwischenablage
Um die Ergebnistabelle im CSV-Format in die Zwischenablage zu kopieren, klicken Sie auf den Abwärtspfeil neben der Registerkarte "Tabellentitel" und dann auf Ergebnisse in die Zwischenablage kopieren.
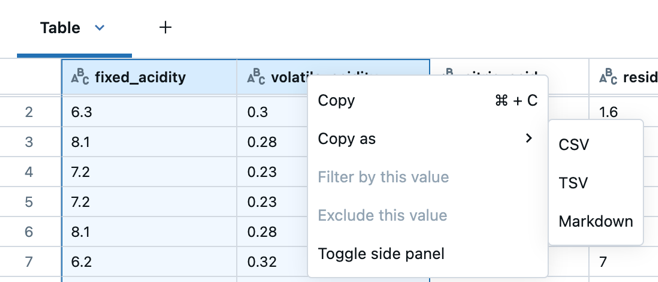
Klicken Sie alternativ auf das Feld in der oberen linken Ecke der Tabelle, um die vollständige Tabelle auszuwählen, und klicken Sie dann mit der rechten Maustaste, und wählen Sie im Dropdownmenü Kopieren aus.
Es gibt mehrere Möglichkeiten zum Kopieren ausgewählter Daten:
- Drücken Sie
Cmd + Cunter MacOS oderCtrl + Cauf Windows, um die Ergebnisse im CSV-Format in die Zwischenablage zu kopieren. - Klicken Sie mit der rechten Maustaste, und wählen Sie Kopieren aus, um die Ergebnisse in die Zwischenablage im CSV-Format zu kopieren.
- Klicken Sie mit der rechten Maustaste, und wählen Sie Kopieren als aus, um die ausgewählten Daten im CSV-, TSV- oder Markdown-Format zu kopieren.
Ergebnisse sortieren
Um die Ergebnistabelle in einer Spalte nach Wert zu sortieren, zeigen Sie mit Ihrem Mauszeiger auf den Spaltennamen. Rechts neben der Zelle, wird ein Symbol mit dem Spaltennamen angezeigt. Klicken Sie auf den Pfeil, um die Spalte zu sortieren.
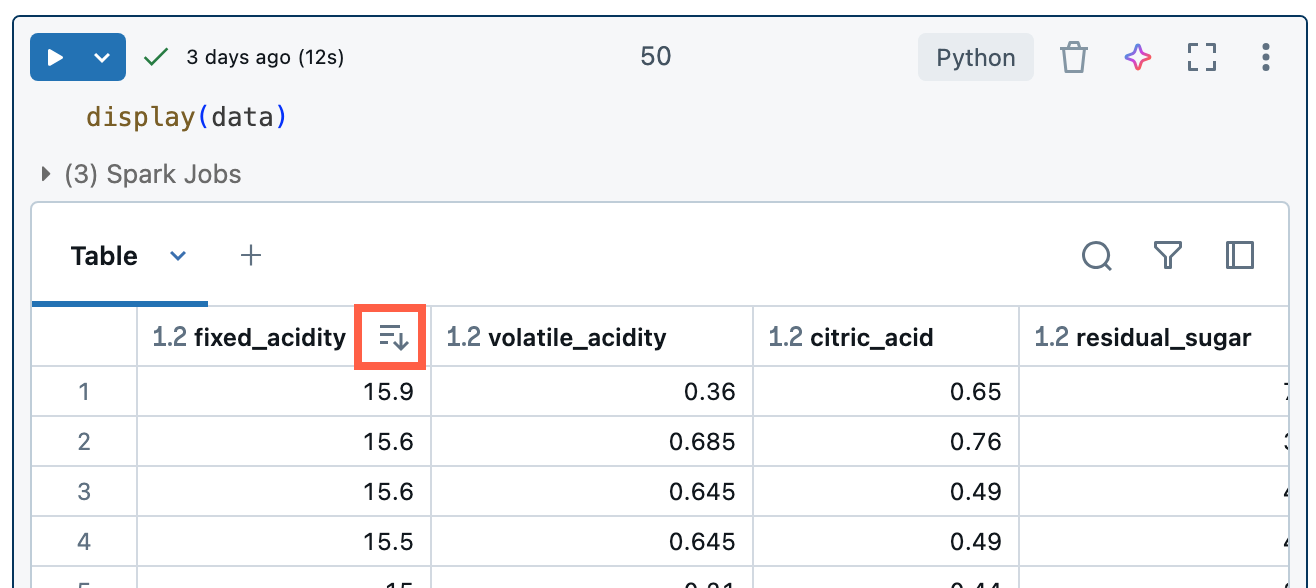
Um nach mehreren Spalten zu sortieren, halten Sie die UMSCHALTTASTE gedrückt, während Sie auf den Sortierpfeil für die Spalten klicken.
Die Sortierung folgt standardmäßig der natürlichen Sortierreihenfolge. Um eine lexikographische Sortierreihenfolge zu erzwingen, verwenden Sie ORDER BY in SQL oder die entsprechenden SORT Funktionen, die in Ihrer Umgebung verfügbar sind.
Filtern von Ergebnissen
Verwenden Sie Filter in einer Ergebnistabelle, um sich die Daten genauer anzusehen. Filter, die auf Ergebnistabellen angewendet werden, wirken sich auch auf Visualisierungen aus, wodurch eine interaktive Erkundung ohne Änderung der zugrunde liegenden Abfrage oder des Datasets ermöglicht wird. Siehe Filtern einer Visualisierung.
Es gibt mehrere Möglichkeiten zum Erstellen eines Filters:
Databricks Assistent
Verwenden Sie natürliche Spracheingaben mit dem Assistenten
Erstellen von Filtern mithilfe von Eingabeaufforderungen in natürlicher Sprache:
- Klicken Sie auf
 Rechts oben in den Zellergebnissen.
Rechts oben in den Zellergebnissen. - Geben Sie im daraufhin angezeigten Dialogfeld Text ein, der den gewünschten Filter beschreibt.
- Klicken Sie auf
 . Genie Code generiert und wendet den Filter für Sie an.
. Genie Code generiert und wendet den Filter für Sie an.
Wenn Sie zusätzliche Filter mit dem Assistenten erstellen möchten, klicken Sie auf das ![]() Klicken Sie neben den Filtern, um eine weitere Eingabeaufforderung einzugeben.
Klicken Sie neben den Filtern, um eine weitere Eingabeaufforderung einzugeben.
Weitere Informationen finden Sie unter Filtern von Daten mit Prompts in natürlicher Sprache.
Dialogfeld "Filter"
Verwenden des integrierten Filterdialogfelds
- Wenn Genie Code nicht aktiviert ist, klicken Sie auf das Klicken Sie oben rechts in den Zellergebnissen, um das Filterdialogfeld zu öffnen. Sie können auch auf dieses Dialogfeld zugreifen, indem Sie auf
 klicken.
klicken. - Wählen Sie die Spalte aus, die Sie filtern möchten.
- Wählen Sie die Filterregel aus, die Sie anwenden möchten.
- Wählen Sie die Werte aus, die Sie filtern möchten.
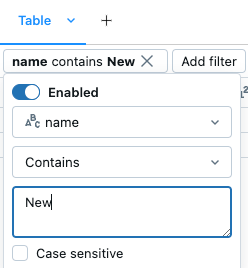
Nach Wert
Filtern nach einem bestimmten Wert
- Klicken Sie in der Ergebnistabelle mit der rechten Maustaste auf eine Zelle mit diesem Wert.
- Wählen Sie im Dropdownmenü " Nach diesem Wert filtern " aus.
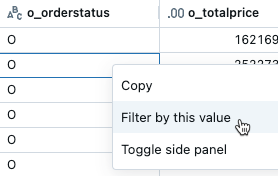
Nach Spalte
Filtern nach einer bestimmten Spalte
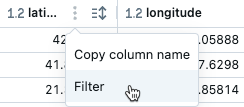
- Zeigen Sie mit der Maus auf die Spalte, nach der Sie filtern möchten.
- Klicken Sie auf
- Klicken Sie auf Filter.
- Wählen Sie die Werte aus, nach der Sie filtern möchten.
Um einen Filter vorübergehend zu aktivieren oder zu deaktivieren, klicken Sie im Dialogfeld auf die Schaltfläche "Aktiviert/Deaktiviert ".
Klicken Sie zum Löschen eines Filters auf das ![]() Klicken Sie neben dem Filternamen "
Klicken Sie neben dem Filternamen "  .
.
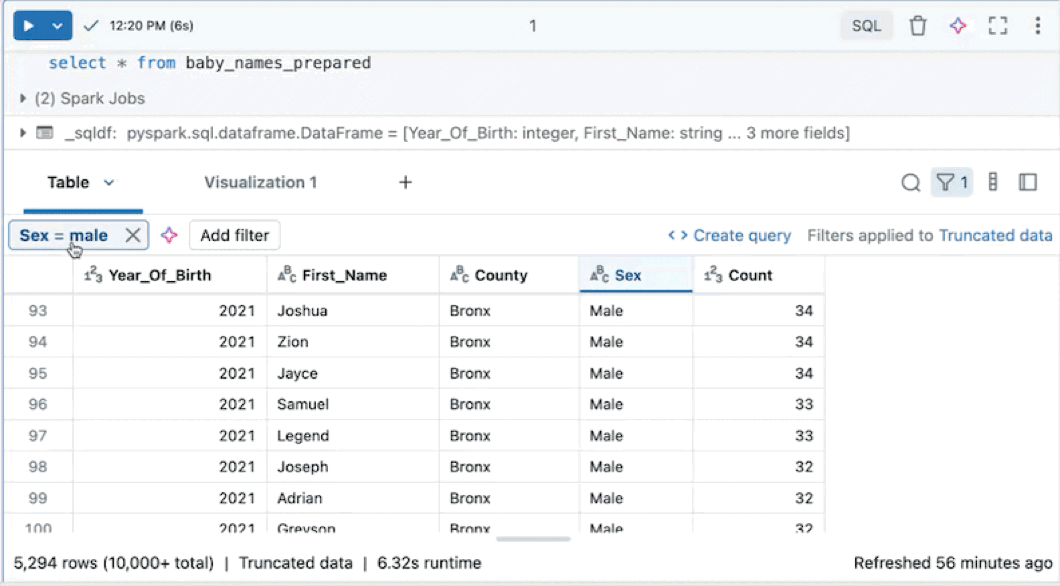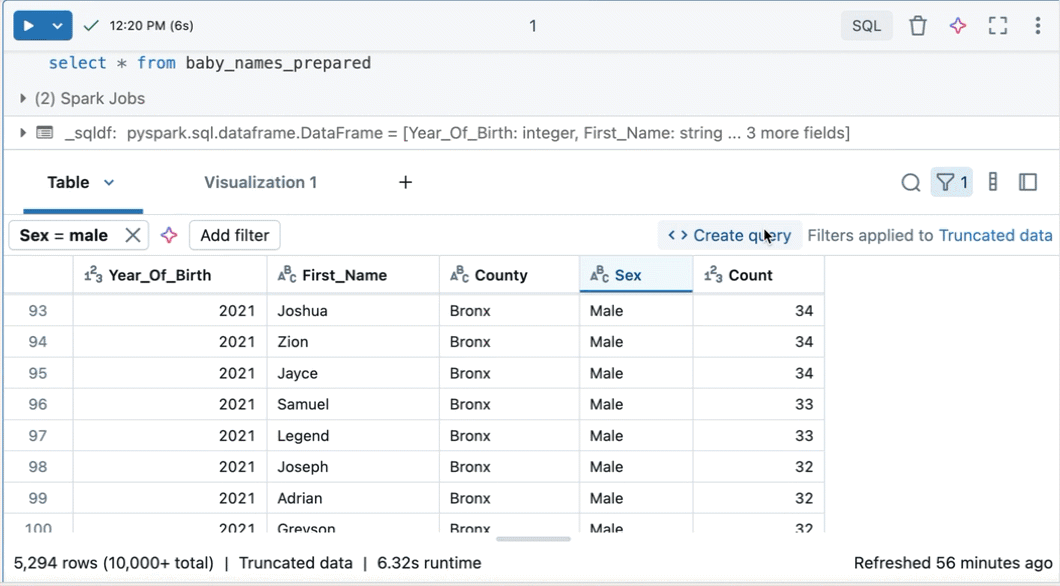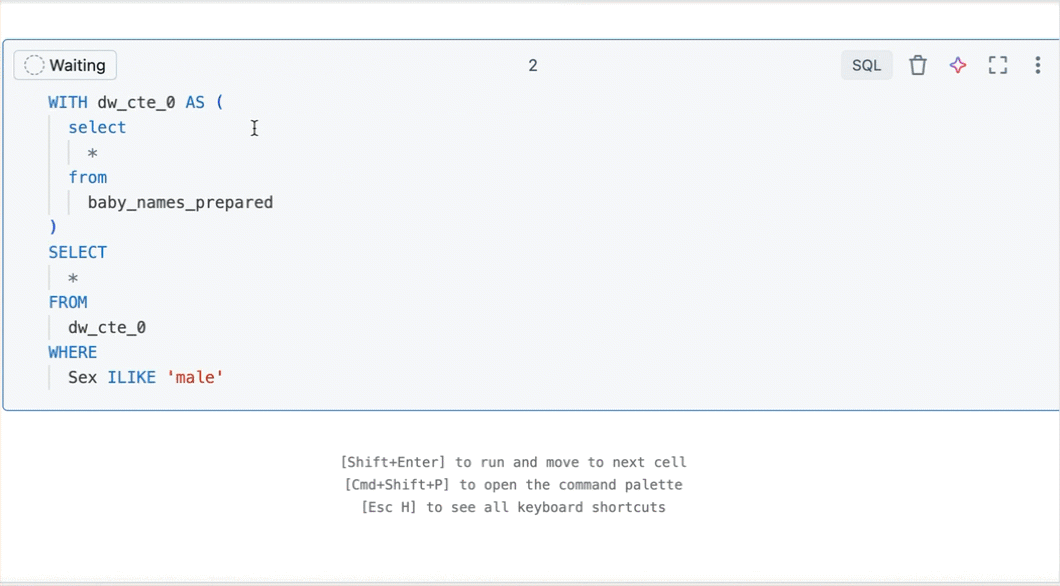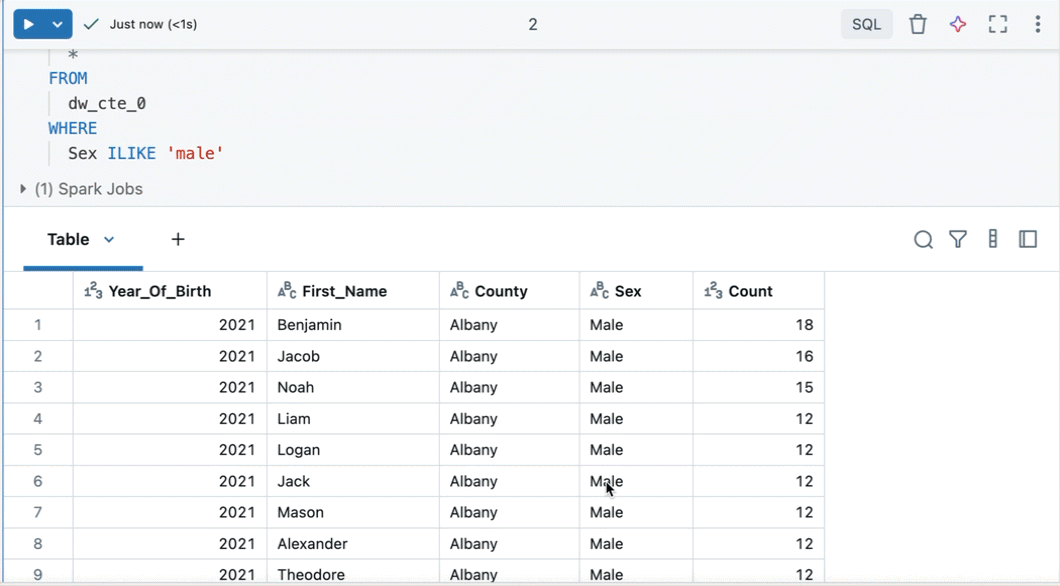
Anwenden von Filtern auf das vollständige Dataset
Standardmäßig werden Filter nur auf die Ergebnisse angewendet, die in der Ergebnistabelle angezeigt werden. Wenn die zurückgegebenen Daten abgeschnitten werden (z. B. wenn eine Abfrage mehr als 10.000 Zeilen zurückgibt oder das Dataset größer als 2 MB ist), wird der Filter nur auf die zurückgegebenen Zeilen angewendet. Eine Notiz oben rechts in der Tabelle gibt an, dass der Filter auf abgeschnittene Daten angewendet wurde.
Sie können stattdessen das vollständige Dataset filtern. Klicken Sie auf "Abgeschnittene Daten", und wählen Sie dann "Vollständiges Dataset" aus. Je nach Größe des Datasets kann es lange dauern, bis der Filter angewendet wird.

Erstellen einer Abfrage aus gefilterten Ergebnissen
Aus einer gefilterten Ergebnistabelle oder -visualisierung in einem Notizbuch mit SQL als Standardsprache können Sie eine neue Abfrage mit den angewendeten Filtern erstellen. Klicken Sie oben rechts in der Tabelle oder Visualisierung auf "Abfrage erstellen". Die Abfrage wird als nächste Zelle im Notizbuch hinzugefügt.
Die erstellte Abfrage wendet Ihre Filter auf die ursprüngliche Abfrage an. Auf diese Weise können Sie mit einem kleineren, relevanteren Dataset arbeiten und eine effizientere Datensuche und -analyse ermöglichen.
Durchsuchen von Spalten
Um das Arbeiten mit Tabellen mit vielen Spalten zu erleichtern, können Sie den Spalten-Explorer verwenden. Um den Spalten-Explorer zu öffnen, klicken Sie oben rechts in einer Ergebnistabelle auf das Spaltensymbol (![]()
Der Spalten-Explorer ermöglicht Folgendes:
- Suchen Sie nach Spalten: Geben Sie in die Suchleiste ein, um die Liste der Spalten zu filtern. Klicken Sie im Explorer auf eine Spalte, um sie in der Ergebnistabelle zu öffnen.
- Ein- oder Ausblenden von Spalten: Verwenden Sie die Kontrollkästchen, um die Sichtbarkeit der Spalten zu steuern. Das Kontrollkästchen oben schaltet die Sichtbarkeit aller Spalten gleichzeitig um. Einzelne Spalten können mithilfe der Kontrollkästchen neben ihren Namen angezeigt oder ausgeblendet werden.
- Anheften von Spalten: Fahren Sie mit der Maus über einen Spaltennamen, um das Pinsymbol sichtbar zu machen. Klicken Sie auf das Pinsymbol, um die Spalte anzuheften. Fixierte Spalten bleiben sichtbar, während Sie horizontal durch die Ergebnistabelle blättern.
-
Neu anordnen von Spalten: Klicken und halten Sie das Ziehsymbol (
 ) rechts neben dem Namen einer Spalte, und ziehen Sie dann die Spalte an die neue gewünschte Position. Dadurch werden die Spalten in der Ergebnistabelle neu angeordnet.
) rechts neben dem Namen einer Spalte, und ziehen Sie dann die Spalte an die neue gewünschte Position. Dadurch werden die Spalten in der Ergebnistabelle neu angeordnet.
Spalten formatieren
Spaltenüberschriften geben den Datentyp der Spalte an. So gibt  z. B. den Datentyp „Integer“ an. Zeigen Sie mit dem Cursor auf den Indikator, um den Datentyp anzuzeigen.
z. B. den Datentyp „Integer“ an. Zeigen Sie mit dem Cursor auf den Indikator, um den Datentyp anzuzeigen.
Sie können Spalten in Ergebnistabellen als Typen wie Währung, Prozentsatz, URL usw. formatieren, und Sie haben Kontrolle über Dezimalstellen für übersichtlichere Tabellen.
Formatieren Sie Spalten aus dem Kebab-Menü im Spaltennamen.
Herunterladen von Ergebnissen
Das Herunterladen von Ergebnissen ist standardmäßig aktiviert. Informationen zum Ändern dieser Einstellung finden Sie unter "Verwalten der Möglichkeit zum Herunterladen von Ergebnissen aus Notizbüchern".
Sie können ein Zellenergebnis mit tabellarischer Ausgabe auf Ihren lokalen Computer herunterladen. Klicken Sie auf den nach unten zeigenden Pfeil neben dem Registerkartentitel. Die Menüoptionen hängen von der Anzahl der Zeilen im Ergebnis und der Databricks Runtime-Version ab. Heruntergeladene Ergebnisse werden auf Ihrem lokalen Computer als CSV-Datei mit einem Namen gespeichert, der Ihrem Notebook-Namen entspricht.
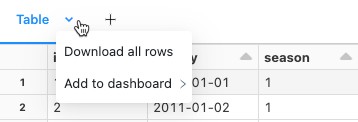
Für Notizbücher, die mit SQL-Lagerhäusern oder serverlosem Berechnen verbunden sind, können Sie die Ergebnisse auch als Excel Datei herunterladen.
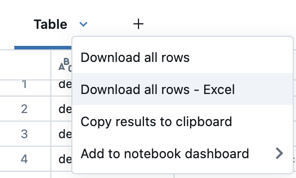
Ergebnisse in SQL-Zellen erkunden
In einem Databricks-Notizbuch sind Ergebnisse aus einer SQL-Sprachzelle automatisch als DataFrame verfügbar, der der Variablen _sqldfzugewiesen ist. Sie können die Variable _sqldf verwenden, um auf die vorherige SQL-Ausgabe in nachfolgenden Python- und SQL-Zellen zu verweisen. Ausführliche Informationen finden Sie unter "Erkunden der SQL-Zellergebnisse".
Anzeigen mehrerer Ausgaben pro Zelle
Python-Notizbücher und %python Zellen in nicht-Python-Notizbüchern unterstützen mehrere Ausgaben pro Zelle. Die Ausgabe des folgenden Codes enthält beispielsweise sowohl die Grafik als auch die Tabelle:
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
iris = pd.DataFrame(data=data.data, columns=data.feature_names)
ax = iris.plot()
print("plot")
display(ax)
print("data")
display(iris)
Ändern der Größe von Ausgaben
Ändern Sie die Größe von Zellausgaben, indem Sie die untere rechte Ecke der Tabelle oder Visualisierung ziehen.
Committen von Notebookausgaben in Databricks Git-Ordnern
Weitere Informationen zum Committen der Ausgaben von IPYNB-Notebooks finden Sie unter Zulassen des Commits für die Ausgabe von IPYNB-Notebooks.
- Das Notebook muss eine IPYNB-Datei sein
- Die Administratoreinstellungen des Arbeitsbereichs müssen das Committen von Notebookausgaben zulassen