Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Die Lakebase-Daten-API ist eine postgREST-kompatible RESTful-Schnittstelle, mit der Sie mithilfe standardmäßiger HTTP-Methoden direkt mit Ihrer Lakebase Postgres-Datenbank interagieren können. Es bietet API-Endpunkte, die aus Ihrem Datenbankschema abgeleitet wurden, und ermöglicht sichere CRUD-Vorgänge (Create, Read, Update, Delete) für Ihre Daten, ohne dass eine benutzerdefinierte Back-End-Entwicklung erforderlich ist.
Übersicht
Die Daten-API generiert automatisch RESTful-Endpunkte basierend auf Ihrem Datenbankschema. Auf jede Tabelle in Ihrer Datenbank kann über HTTP-Anforderungen zugegriffen werden, sodass Sie:
- Abfragen von Daten mithilfe von HTTP-Anforderungen GET mit flexibler Filterung, Sortierung und Paginierung
- Einfügen von Datensätzen mithilfe von HTTP POST-Anforderungen
- Aktualisieren von Datensätzen mithilfe von HTTP PATCH- oder PUT-Anforderungen
- Löschen von Datensätzen mithilfe von HTTP DELETE-Anforderungen
- Ausführen von Funktionen als RPCs mithilfe von HTTP POST-Anforderungen
Bei diesem Ansatz ist es nicht erforderlich, benutzerdefinierten API-Code zu schreiben und zu verwalten, sodass Sie sich auf Ihre Anwendungslogik und das Datenbankschema konzentrieren können.
PostgREST-Kompatibilität
Die Lakebase-Daten-API ist mit der PostgREST-Spezifikation kompatibel. Sie haben folgende Möglichkeiten:
- Verwenden vorhandener PostgREST-Clientbibliotheken und -tools
- Befolgen Sie die PostgREST-Konventionen zum Filtern, Sortieren und Paginieren
- Anpassen von Dokumentationen und Beispielen aus der PostgREST-Community
Hinweis
Die Lakebase-Daten-API ist Azure Databricks Implementierung, die mit der PostgREST-Spezifikation kompatibel ist. Da es sich bei der Daten-API um eine unabhängige Implementierung handelt, sind einige PostgREST-Features, die nicht für die Lakebase-Umgebung gelten, nicht enthalten. Ausführliche Informationen zur Featurekompatibilität finden Sie in der Featurekompatibilitätsreferenz.
Ausführliche Informationen zu API-Features, Abfrageparametern und Funktionen finden Sie in der PostgREST-API-Referenz.
Anwendungsfälle
Die Lakebase Data API ist ideal für:
- Webanwendungen: Erstellen von Frontends, die direkt mit Ihrer Datenbank über HTTP-Anforderungen interagieren
- Microservices: Erstellen von einfachen Diensten, die über REST-APIs auf Datenbankressourcen zugreifen
- Serverlose Architekturen: Integration in serverlose Funktionen und Edge Computing-Plattformen
- Mobile Anwendungen: Bereitstellen mobiler Apps mit direktem Datenbankzugriff über eine RESTful-Schnittstelle
- Integrationen von Drittanbietern: Ermöglichen sie externen Systemen, Daten sicher zu lesen und zu schreiben
Einrichten der Daten-API
Dieser Abschnitt führt Sie durch das Einrichten der Daten-API, von der Erstellung erforderlicher Rollen bis hin zur Erstellung Ihrer ersten API-Anforderung.
Voraussetzungen
Die Daten-API erfordert ein Lakebase-Postgres-Autoscaling-Datenbankprojekt. Wenn Sie keins haben, lesen Sie "Erste Schritte mit Datenbankprojekten".
Tipp
Wenn Sie Beispieltabellen zum Testen der Daten-API benötigen, erstellen Sie sie, bevor Sie die Daten-API aktivieren. Ein vollständiges Beispielschema finden Sie unter "Beispielschema ".
Aktivieren der Daten-API
Die Daten-API macht den gesamten Datenbankzugriff über eine einzelne Postgres-Rolle namens authenticator, die keine Berechtigungen erfordert, außer sich anzumelden. Wenn Sie die Daten-API über die Lakebase-App aktivieren, werden diese Rolle und die erforderliche Infrastruktur automatisch erstellt.
So aktivieren Sie die Daten-API:
- Navigieren Sie zu der Daten-API-Seite in Ihrem Projekt.
- Klicken Sie auf "Daten-API aktivieren".
Dadurch werden automatisch alle Setupschritte ausgeführt, einschließlich der Erstellung der authenticator Rolle, der Konfiguration des pgrst Schemas und des Verfügbarmachens des public Schemas über die API.
Hinweis
Wenn Sie zusätzliche Schemas (darüber hinaus public) verfügbar machen müssen, können Sie die verfügbar gemachten Schemas in den Erweiterten Daten-API-Einstellungen ändern.
Nach dem Aktivieren der Daten-API
Nachdem Sie die Daten-API aktiviert haben, zeigt die Lakebase-App die Daten-API-Seite mit zwei Registerkarten an: API und Einstellungen.
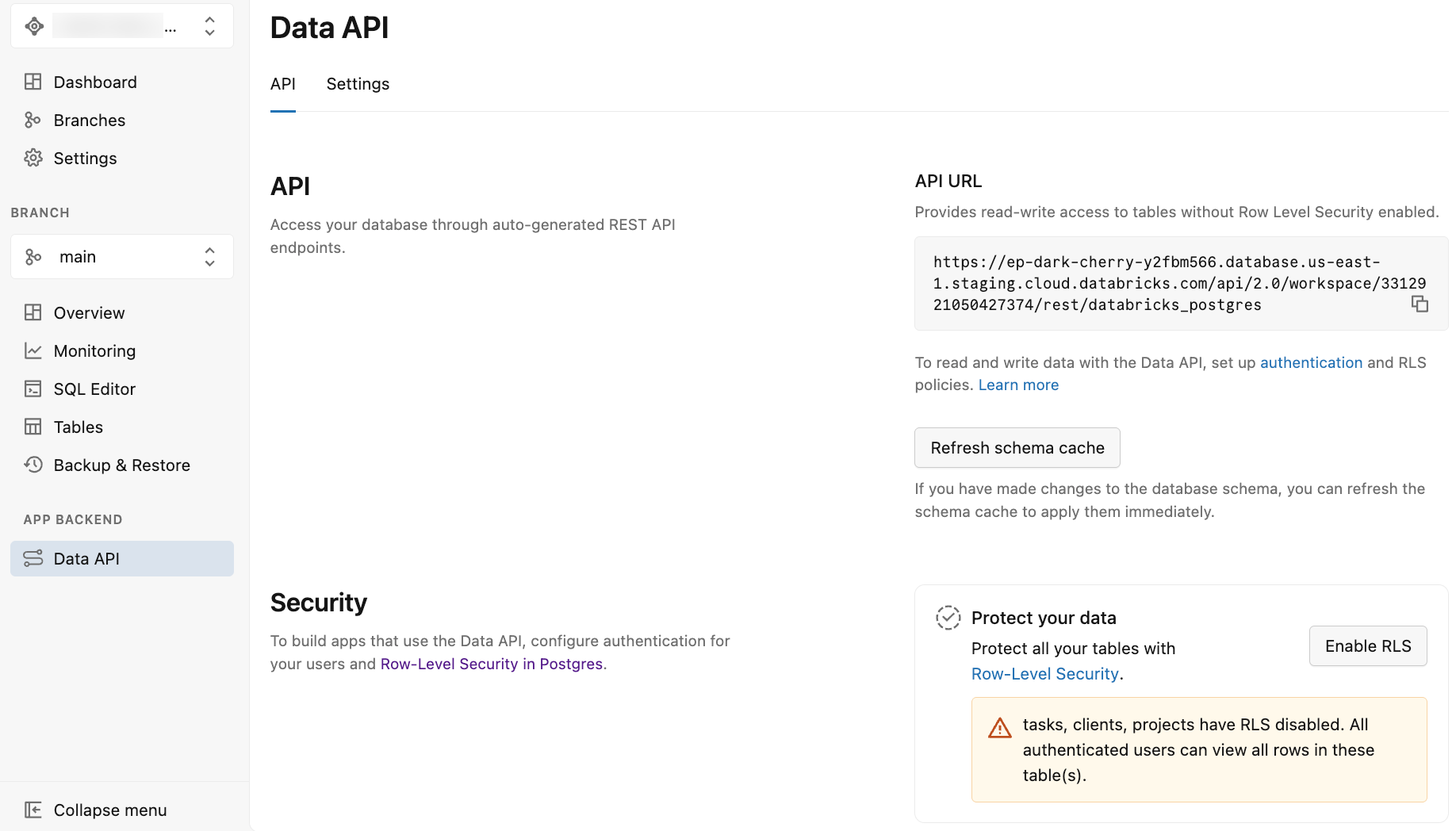
Die Registerkarte "API " bietet Folgendes:
-
API-URL: Die REST-Endpunkt-URL, die in Ihrem Anwendungscode und API-Anforderungen verwendet werden soll. Die angezeigte URL enthält das Schema nicht, daher sollten Sie den Schemanamen (z. B.
/public) bei API-Anforderungen an die URL anfügen. - Schemacache aktualisieren: Eine Schaltfläche zum Aktualisieren des Schemacaches der API, nachdem Sie Änderungen am Datenbankschema vorgenommen haben. Siehe Aktualisieren des Schemacaches.
- Schützen Sie Ihre Daten: Optionen zum Aktivieren der Sicherheit auf Listenebene (Row-Level Security, RLS) für Ihre Tabellen. Siehe Aktivieren der Sicherheit auf Zeilenebene.
Die Registerkarte "Einstellungen " bietet Optionen zum Konfigurieren des API-Verhaltens, z. B. verfügbar gemachte Schemas, maximale Zeilen, CORS-Einstellungen und vieles mehr. Weitere Informationen finden Sie unter "Erweiterte Daten-API-Einstellungen".
Beispielschema (optional)
In den Beispielen in dieser Dokumentation wird das folgende Schema verwendet. Sie können eigene Tabellen erstellen oder dieses Beispielschema zum Testen verwenden. Führen Sie diese SQL-Anweisungen mithilfe des Lakebase SQL-Editors oder eines beliebigen SQL-Clients aus:
-- Create clients table
CREATE TABLE clients (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT UNIQUE NOT NULL,
company TEXT,
phone TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create projects table with foreign key to clients
CREATE TABLE projects (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
description TEXT,
client_id INTEGER NOT NULL REFERENCES clients(id) ON DELETE CASCADE,
status TEXT DEFAULT 'active',
start_date DATE,
end_date DATE,
budget DECIMAL(10,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create tasks table with foreign key to projects
CREATE TABLE tasks (
id SERIAL PRIMARY KEY,
title TEXT NOT NULL,
description TEXT,
project_id INTEGER NOT NULL REFERENCES projects(id) ON DELETE CASCADE,
status TEXT DEFAULT 'pending',
priority TEXT DEFAULT 'medium',
assigned_to TEXT,
due_date DATE,
estimated_hours DECIMAL(5,2),
actual_hours DECIMAL(5,2),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample data
INSERT INTO clients (name, email, company, phone) VALUES
('Acme Corp', 'contact@acme.com', 'Acme Corporation', '+1-555-0101'),
('TechStart Inc', 'hello@techstart.com', 'TechStart Inc', '+1-555-0102'),
('Global Solutions', 'info@globalsolutions.com', 'Global Solutions Ltd', '+1-555-0103');
INSERT INTO projects (name, description, client_id, status, start_date, end_date, budget) VALUES
('Website Redesign', 'Complete overhaul of company website with modern design', 1, 'active', '2024-01-15', '2024-06-30', 25000.00),
('Mobile App Development', 'iOS and Android app for customer management', 1, 'planning', '2024-07-01', '2024-12-31', 50000.00),
('Database Migration', 'Migrate legacy system to cloud database', 2, 'active', '2024-02-01', '2024-05-31', 15000.00),
('API Integration', 'Integrate third-party services with existing platform', 3, 'completed', '2023-11-01', '2024-01-31', 20000.00);
INSERT INTO tasks (title, description, project_id, status, priority, assigned_to, due_date, estimated_hours, actual_hours) VALUES
('Design Homepage', 'Create wireframes and mockups for homepage', 1, 'in_progress', 'high', 'Sarah Johnson', '2024-03-15', 16.00, 8.00),
('Setup Development Environment', 'Configure local development setup', 1, 'completed', 'medium', 'Mike Chen', '2024-02-01', 4.00, 3.50),
('Database Schema Design', 'Design new database structure', 3, 'completed', 'high', 'Alex Rodriguez', '2024-02-15', 20.00, 18.00),
('API Authentication', 'Implement OAuth2 authentication flow', 4, 'completed', 'high', 'Lisa Wang', '2024-01-15', 12.00, 10.50),
('User Testing', 'Conduct usability testing with target users', 1, 'pending', 'medium', 'Sarah Johnson', '2024-04-01', 8.00, NULL),
('Performance Optimization', 'Optimize database queries and caching', 3, 'in_progress', 'medium', 'Alex Rodriguez', '2024-04-30', 24.00, 12.00);
Konfigurieren von Benutzerberechtigungen
Sie müssen alle Daten-API-Anforderungen mit Azure Databricks OAuth-Bearertoken authentifizieren, die über den Header Authorization gesendet werden. Die Daten-API schränkt den Zugriff auf authentifizierte Azure Databricks Identitäten ein, wobei Postgres die zugrunde liegenden Berechtigungen regelt.
Die authenticator Rolle geht von der Identität des anfordernden Benutzers bei der Verarbeitung von API-Anforderungen aus. Damit dies funktioniert, muss jede Azure Databricks Identität, die auf die Daten-API zugreift, eine entsprechende Postgres-Rolle in Ihrer Datenbank haben. Wenn Sie Ihrem Azure Databricks Konto zuerst Benutzer hinzufügen müssen, lesen Sie Benutzer zu Ihrem Konto hinzufügen.
Hinzufügen von Postgres-Rollen
Von Bedeutung
Verwenden Sie nicht Ihr Datenbankbesitzerkonto (die Azure Databricks Identität, die das Lakebase-Projekt erstellt hat), um auf die Daten-API zuzugreifen. Die authenticator Rolle erfordert die Möglichkeit, Ihre Rolle anzunehmen, und diese Berechtigung kann für Konten mit erhöhten Berechtigungen nicht erteilt werden. Verwenden Sie stattdessen einen Dienstprinzipal (empfohlen) oder ein anderes Azure Databricks-Benutzerkonto.
Erstellen Sie die Rolle mithilfe der folgenden SQL-Schritte. Eine Rolle, die über die Benutzeroberfläche Rollen & Datenbanken > Rolle hinzufügen hinzugefügt wurde, kann authenticator nicht gewährt werden, sodass der nächste Schritt mit einem Fehler wegen verweigerter Berechtigung fehlschlägt. Informationen hierzu finden Sie unter Problembehandlung.
Erstellen Sie mithilfe des Lakebase SQL-Editors eine Postgres-Rolle für jede Azure Databricks Identität, die Daten-API-Zugriff benötigt:
Erstellen Sie die
databricks_authErweiterung. Jede Postgres-Datenbank muss über eine eigene Erweiterung verfügen.CREATE EXTENSION IF NOT EXISTS databricks_auth;Verwenden Sie
databricks_create_role, um eine Postgres-Rolle für die Azure Databricks Identität hinzuzufügen:Für einen Benutzer:
SELECT databricks_create_role('user@databricks.com', 'USER');Für einen Dienstprinzipal verwenden Sie die Anwendungs-ID (UUID) als Identitätsnamen. Suchen Sie ihn in Ihrem Azure Databricks Arbeitsbereich unter Einstellungen > Identität und Zugriff > Service principals:
SELECT databricks_create_role('8c01cfb1-62c9-4a09-88a8-e195f4b01b08', 'SERVICE_PRINCIPAL');
Erteilen von Berechtigungen für Benutzer
Nachdem Sie nun entsprechende Postgres-Rollen für Ihre Azure Databricks Identitäten erstellt haben, müssen Sie diesen Postgres-Rollen Berechtigungen erteilen. Diese Berechtigungen steuern, mit welchen Datenbankobjekten (Schemas, Tabellen, Sequenzen, Funktionen) jeder Benutzer über API-Anforderungen interagieren kann.
Erteilen Sie Berechtigungen mithilfe von Standard-SQL-Anweisungen GRANT. In diesem Beispiel wird das public Schema verwendet. Wenn Sie ein anderes Schema bereitstellen, ersetzen Sie public durch Ihren Schemanamen.
-- Allow authenticator to assume the identity of the user
GRANT "user@databricks.com" TO authenticator;
-- Allow user@databricks.com to access everything in public schema
GRANT USAGE ON SCHEMA public TO "user@databricks.com";
GRANT SELECT, UPDATE, INSERT, DELETE ON ALL TABLES IN SCHEMA public TO "user@databricks.com";
GRANT USAGE ON ALL SEQUENCES IN SCHEMA public TO "user@databricks.com";
GRANT EXECUTE ON ALL FUNCTIONS IN SCHEMA public TO "user@databricks.com";
In diesem Beispiel wird vollzugriff auf das public Schema für die user@databricks.com Identität gewährt. Ersetzen Sie dies durch die tatsächliche Azure Databricks Identität, und passen Sie Berechtigungen basierend auf Ihren Anforderungen an. Verwenden Sie für Dienstprinzipale die Anwendungs-ID (UUID) als Namen der Postgres-Rolle in GRANT Anweisungen anstelle einer E-Mail-Adresse.
Von Bedeutung
Implementieren Sie die Sicherheit auf Zeilenebene: Die oben genannten Berechtigungen gewähren Zugriff auf Tabellenebene, aber die meisten API-Anwendungsfälle erfordern Einschränkungen auf Zeilenebene. Beispielsweise sollten Benutzer in mehrinstanzenfähigen Anwendungen nur ihre eigenen Daten oder die Daten ihrer Organisation sehen. Verwenden Sie PostgreSQL Sicherheitsrichtlinien auf Zeilenebene (RLS), um eine differenzierte Zugriffssteuerung auf Datenbankebene zu erzwingen. Siehe Implementieren der Sicherheit auf Zeilenebene.
Authentifizierung
Um auf die Daten-API zuzugreifen, müssen Sie ein Azure Databricks OAuth-Token im header Authorization Ihrer HTTP-Anforderung bereitstellen. Die authentifizierte Azure Databricks Identität muss über eine entsprechende Postgres-Rolle (erstellt in den vorherigen Schritten) verfügen, die ihre Datenbankberechtigungen definiert.
Abrufen eines OAuth-Tokens
Stellen Sie eine Verbindung mit Ihrem Arbeitsbereich als Azure Databricks Identität her, für die Sie in den vorherigen Schritten eine Postgres-Rolle erstellt haben, und rufen Sie ein OAuth-Token ab. Anweisungen finden Sie unter "Authentifizierung ".
Eine Anfrage stellen
Mit Ihrem OAuth-Token und ihrer API-URL (verfügbar auf der Registerkarte "API " in der Lakebase-App) können Sie API-Anforderungen mithilfe von Curl oder einem beliebigen HTTP-Client durchführen. Denken Sie daran, /publicden Schemanamen (z. B. ) an die API-URL anzufügen. In den folgenden Beispielen wird davon ausgegangen, dass Sie die DBX_OAUTH_TOKEN Variablen und REST_ENDPOINT Umgebungsvariablen exportiert haben.
Hier ist ein Beispielaufruf mit der erwarteten Ausgabe (unter Verwendung des Beispielschemas clients/projects/tasks):
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Beispielantwort:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Weitere Beispiele und ausführlichere Informationen zu API-Vorgängen finden Sie im API-Referenzabschnitt . Ausführliche Informationen zu Abfrageparametern und API-Funktionen finden Sie in der PostgREST-API-Referenz. Informationen zu Lakebase-spezifischen Kompatibilitätsinformationen finden Sie unter PostgREST-Kompatibilität.
Bevor Sie die API umfassend verwenden, konfigurieren Sie die Sicherheit auf Zeilenebene , um Ihre Daten zu schützen.
Verwalten der Daten-API
Nachdem Sie die Daten-API aktiviert haben, können Sie Schemaänderungen und Sicherheitseinstellungen über die Lakebase-App verwalten.
Schemacache aktualisieren
Wenn Sie Änderungen am Datenbankschema vornehmen (Hinzufügen von Tabellen, Spalten oder anderen Schemaobjekten), müssen Sie den Schemacache aktualisieren. Dadurch werden Ihre Änderungen sofort über die Daten-API verfügbar.
So aktualisieren Sie den Schemacache:
- Navigieren Sie im Abschnitt "App-Back-End" Ihres Projekts zur Daten-API.
- Klicken Sie auf "Schemacache aktualisieren".
Die Daten-API spiegelt jetzt Ihre neuesten Schemaänderungen wider.
Aktivieren der Sicherheit auf Zeilenebene
Die Lakebase-App bietet eine schnelle Möglichkeit, die Sicherheit auf Zeilenebene (RLS) für Tabellen in Ihrer Datenbank zu aktivieren. Wenn Tabellen in Ihrem Schema vorhanden sind, wird auf der Registerkarte "API " ein Abschnitt " Daten schützen " angezeigt, in dem Folgendes angezeigt wird:
- Tabellen mit aktivierter RLS
- Tabellen mit deaktivierten RLS (mit Warnungen)
- Eine Schaltfläche " RLS aktivieren ", um RLS für alle Tabellen zu aktivieren
Von Bedeutung
Durch aktivieren von RLS über die Lakebase-App wird die Sicherheit auf Zeilenebene für Ihre Tabellen aktiviert. Wenn RLS aktiviert ist, werden alle Zeilen standardmäßig für Benutzer nicht zugänglich (mit Ausnahme von Tabellenbesitzern, Rollen mit dem BYPASSRLS-Attribut und Superusern– obwohl Superbenutzer auf Lakebase nicht unterstützt werden). Sie müssen RLS-Richtlinien erstellen, um basierend auf Ihren Sicherheitsanforderungen Zugriff auf bestimmte Zeilen zu gewähren. Weitere Informationen zum Erstellen von Richtlinien finden Sie unter Sicherheit auf Zeilenebene.
So aktivieren Sie RLS für Ihre Tabellen:
- Navigieren Sie im Abschnitt "App-Back-End" Ihres Projekts zur Daten-API.
- Überprüfen Sie im Abschnitt " Schützen Ihrer Daten " die Tabellen, für die keine RLS aktiviert sind.
- Klicken Sie auf "RLS aktivieren ", um die Sicherheit auf Zeilenebene für alle Tabellen zu aktivieren.
Sie können RLS auch für einzelne Tabellen mit SQL aktivieren. Weitere Informationen finden Sie unter Sicherheit auf Zeilenebene.
Problembehandlung
Keine Berechtigung, eine Rolle zuzuweisen (SQLSTATE 42501)
ERROR: permission denied to grant role "<identity>" (SQLSTATE 42501)
Dies tritt auf, wenn Sie GRANT "<identity>" TO authenticator ausführen und entweder:
- Die Rolle wurde über die Benutzeroberfläche für Rollen und Datenbanken hinzugefügt. Erstellen Sie die Rolle stattdessen mit
databricks_create_roleim SQL-Editor. Siehe Hinzufügen von Postgres-Rollen. - Das Ziel ist Ihr Datenbankbesitzerkonto. Verwenden Sie einen Dienstprinzipal oder einen anderen Azure-Databricks-Benutzer, der kein Besitzer ist.
Die Daten-API ist für diesen Endpunkt nicht aktiviert.
Wenn Sie Lesereplikate hinzufügen, bevor Sie die Daten-API aktivieren, können Endpunkte diesen Fehler kurz zurückgeben. Aktivieren Sie zuerst die Daten-API, und fügen Sie dann Lesereplikate hinzu.
Erweiterte Daten-API-Einstellungen
Der Abschnitt "Erweiterte Einstellungen " auf der Registerkarte "API " in der Lakebase-App steuert die Sicherheit, Leistung und das Verhalten Ihres Daten-API-Endpunkts.
Offengelegte Schemas
Vorgabe:public
Definiert, welche PostgreSQL-Schemas als REST-API-Endpunkte verfügbar gemacht werden. Standardmäßig ist nur das public Schema zugänglich. Wenn Sie andere Schemas verwenden (z. B. api, v1), wählen Sie sie aus der Dropdownliste aus, um sie hinzuzufügen.
Hinweis
Berechtigungen gelten: Wenn Sie hier ein Schema hinzufügen, werden die Endpunkte verfügbar gemacht, aber die von der API verwendete Datenbankrolle muss weiterhin über Berechtigungen für das Schema und USAGE die Berechtigungen für die Tabellen verfügenSELECT.
Maximale Zeilenanzahl
Vorgabe: Leer
Erzwingt ein hartes Limit für die Anzahl der Zeilen, die in einer einzelnen API-Antwort zurückgegeben werden sollen. Dadurch wird eine versehentliche Leistungsbeeinträchtigung durch große Abfragen verhindert. Clients sollten Paginierungsgrenzwerte verwenden, um Daten innerhalb dieses Schwellenwerts abzurufen. Dies verhindert auch unerwartete Egress-Kosten durch große Datenübertragungen.
Zulässige CORS-Ursprünge
Standard: Leer (Lässt alle Ursprünge zu)
Steuert, welche Webdomänen Daten über einen Browser aus Ihrer API abrufen können.
-
Leer: Lässt
*(jede Domäne) zu. Nützlich für die Entwicklung. -
Produktion: Listen Sie Ihre spezifischen Domänen auf (z. B. ), um zu verhindern,
https://myapp.comdass nicht autorisierte Websites Ihre API abfragen.
OpenAPI-Spezifikation
Standard: Deaktiviert
Steuert, ob ein automatisch generiertes OpenAPI 3-Schema verfügbar ist unter /openapi.json. Dieses Schema beschreibt Ihre Tabellen, Spalten und REST-Endpunkte. Wenn diese Option aktiviert ist, können Sie sie für Folgendes verwenden:
- Generieren der API-Dokumentation (Swagger UI, Redoc)
- Typierte Clientbibliotheken erstellen (TypeScript, Python, Go)
- Importieren Ihrer API in Postman
- Integration mit API-Gateways und anderen openAPI-basierten Tools
Server-Timing-Header
Standard: Deaktiviert
Wenn diese Option aktiviert ist, enthält die Daten-API in jeder Antwort Server-Timing Kopfzeilen. Diese Header zeigen, wie lange verschiedene Teile der Anforderung verarbeitet wurden (z. B. Datenbankausführungszeit und interne Verarbeitungszeit). Sie können diese Informationen verwenden, um langsame Abfragen zu debuggen, die Leistung zu messen und Latenzprobleme in Ihrer Anwendung zu beheben.
Hinweis
Nachdem Sie Änderungen an den erweiterten Einstellungen vorgenommen haben, klicken Sie auf "Speichern ", um sie anzuwenden.
Sicherheit auf Zeilenebene
Richtlinien für Row-Level Security (RLS) bieten eine differenzierte Zugriffssteuerung, indem sie einschränken, auf welche Zeilen Benutzer in einer Tabelle zugreifen können.
Funktionsweise von RLS mit der Daten-API: Wenn ein Benutzer eine API-Anforderung vornimmt, übernimmt die authenticator Rolle die Identität dieses Benutzers. Alle für die Rolle dieses Benutzers definierten RLS-Richtlinien werden automatisch von PostgreSQL erzwungen und filtern die Daten, auf die sie zugreifen können. Dies geschieht auf Datenbankebene. Auch wenn Der Anwendungscode versucht, alle Zeilen abzufragen, gibt die Datenbank nur Zeilen zurück, die der Benutzer sehen darf. Dies bietet umfassende Sicherheit, ohne dass Filterlogik im Anwendungscode erforderlich ist.
Warum RLS für APIs wichtig ist: Im Gegensatz zu direkten Datenbankverbindungen, bei denen Sie den Verbindungskontext steuern, machen HTTP-APIs Ihre Datenbank für mehrere Benutzer über einen einzelnen Endpunkt verfügbar. Berechtigungen auf Tabellenebene allein bedeuten, dass ein Benutzer, wenn er auf die clients Tabelle zugreifen kann, auf alle Clientdatensätze zugreifen kann, es sei denn, Sie implementieren Filterung. RLS-Richtlinien stellen sicher, dass jeder Benutzer automatisch nur seine autorisierten Daten sieht.
RLS ist für Folgendes unerlässlich:
- Mehrinstanzenfähige Anwendungen: Isolieren von Daten zwischen verschiedenen Kunden oder Organisationen
- Benutzereigene Daten: Sicherstellen, dass Benutzer nur auf ihre eigenen Datensätze zugreifen
- Teambasierter Zugriff: Beschränken der Sichtbarkeit für Teammitglieder oder bestimmte Gruppen
- Complianceanforderungen: Erzwingen von Datenzugriffseinschränkungen auf Datenbankebene
RLS und Ansichten: RLS-Richtlinien werden auf Tabellenebene angewendet. Sie können eine RLS-Richtlinie nicht direkt für eine Sicht definieren. Wenn ein Benutzer eine Ansicht abfragt, wertet Postgres standardmäßig RLS-Richtlinien für den Ansichtsbesitzer aus, nicht für den Abfragebenutzer. Dies bedeutet, dass, wenn der Besitzer der Sicht der Tabellenbesitzer oder ein Superuser ist, RLS für die zugrunde liegende Tabelle effektiv für jeden umgangen wird, der SELECT für die Sicht ausführen kann.
Um RLS-Richtlinien für den Benutzer zu erzwingen, der die Abfrage tatsächlich ausführt, erstellen Sie die Ansicht mit security_invoker = true:
CREATE VIEW my_view WITH (security_invoker = true) AS
SELECT * FROM clients;
Oder aktualisieren Sie eine vorhandene Ansicht:
ALTER VIEW my_view SET (security_invoker = true);
Alternativ können Sie FORCE ROW LEVEL SECURITY auf die zugrunde liegende Tabelle anwenden, sodass RLS auch für den Tabelleneigentümer gilt:
ALTER TABLE clients FORCE ROW LEVEL SECURITY;
Wenn Sie den Zugriff auf die Ansicht selbst einschränken möchten (steuern, wer sie abfragen kann), verwenden Sie Die Postgres-Rollenberechtigungen (GRANT/REVOKE) anstelle von RLS-Richtlinien.
Aktivieren von RLS
Sie können RLS über die Lakebase-App oder sql-Anweisungen aktivieren. Anweisungen zur Verwendung der Lakebase-App finden Sie unter Aktivieren der Sicherheit auf Zeilenebene.
Warnung
Wenn Tabellen ohne RLS aktiviert sind, zeigt die Registerkarte "API" in der Lakebase-App eine Warnung an, dass authentifizierte Benutzer alle Zeilen in diesen Tabellen anzeigen können. Die Daten-API interagiert direkt mit Ihrem Postgres-Schema, und da auf die API über das Internet zugegriffen werden kann, ist es wichtig, die Sicherheit auf Datenbankebene mithilfe der Sicherheitsstufe auf PostgreSQL-Zeilenebene zu erzwingen.
Führen Sie den folgenden Befehl aus, um RLS mit SQL zu aktivieren:
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Erstellen Sie RLS-Richtlinien
Nachdem Sie RLS für eine Tabelle aktiviert haben, müssen Sie Richtlinien erstellen, die Zugriffsregeln definieren. Ohne Richtlinien können Benutzer nicht auf Zeilen zugreifen (alle Zeilen sind standardmäßig ausgeblendet).
Funktionsweise von Richtlinien: Wenn RLS in einer Tabelle aktiviert ist, können Benutzer nur Zeilen sehen, die mindestens einer Richtlinie entsprechen. Alle anderen Zeilen werden herausgefiltert. Tabellenbesitzer, Rollen mit dem BYPASSRLS Attribut und Superuser können das Zeilensicherheitssystem umgehen (obwohl Superbenutzer auf Lakebase nicht unterstützt werden).
Hinweis
Gibt in Lakebase current_user die E-Mail-Adresse des authentifizierten Benutzers zurück (z. B user@databricks.com. ). Verwenden Sie dies in Ihren RLS-Richtlinien, um zu ermitteln, welcher Benutzer die Anforderung vornimmt.
Grundlegende Richtliniensyntax:
CREATE POLICY policy_name ON table_name
[TO role_name]
USING (condition);
- policy_name: Ein beschreibender Name für die Richtlinie
- table_name: Die Tabelle, auf die die Richtlinie angewendet werden soll
- TO role_name: Optional. Gibt die Rolle für diese Richtlinie an. Lassen Sie diese Klausel aus, um die Richtlinie auf alle Rollen anzuwenden.
- USING (Bedingung): Die Bedingung, die bestimmt, welche Zeilen sichtbar sind
RLS-Lernprogramm
Im folgenden Lernprogramm wird das Beispielschema aus dieser Dokumentation (Clients, Projekte, Aufgaben-Tabellen) verwendet, um zu zeigen, wie die Sicherheit auf Zeilenebene implementiert wird.
Szenario: Sie haben mehrere Benutzer, die nur ihre zugewiesenen Clients und verwandten Projekte sehen sollen. Zugriff einschränken, sodass:
-
alice@databricks.comkann nur Clients mit den IDs 1 und 2 anzeigen -
bob@databricks.comkann nur Clients mit den IDs 2 und 3 anzeigen
Schritt 1: Aktivieren von RLS in der Clients-Tabelle
ALTER TABLE clients ENABLE ROW LEVEL SECURITY;
Schritt 2: Erstellen einer Richtlinie für Alice
CREATE POLICY alice_clients ON clients
TO "alice@databricks.com"
USING (id IN (1, 2));
Schritt 3: Erstellen einer Richtlinie für Bob
CREATE POLICY bob_clients ON clients
TO "bob@databricks.com"
USING (id IN (2, 3));
Schritt 4: Testen der Richtlinien
Wenn Alice eine API-Anforderung sendet:
# Alice's token in the Authorization header
curl -H "Authorization: Bearer $ALICE_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Antwort (Alice sieht nur Clients 1 und 2):
[
{ "id": 1, "name": "Acme Corp" },
{ "id": 2, "name": "TechStart Inc" }
]
Wenn Bob eine API-Anforderung sendet:
# Bob's token in the Authorization header
curl -H "Authorization: Bearer $BOB_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name"
Antwort (Bob sieht nur Clients 2 und 3):
[
{ "id": 2, "name": "TechStart Inc" },
{ "id": 3, "name": "Global Solutions" }
]
Allgemeine RLS-Muster
Diese Muster decken typische Sicherheitsanforderungen für die Daten-API ab:
Benutzerbesitz – Schränkt Zeilen auf den authentifizierten Benutzer ein:
CREATE POLICY user_owned_data ON tasks
USING (assigned_to = current_user);
Mandantenisolation – Beschränkt Zeilen auf die Organisation des Benutzers:
CREATE POLICY tenant_data ON clients
USING (tenant_id = (
SELECT tenant_id
FROM user_tenants
WHERE user_email = current_user
));
Teammitgliedschaft – Schränkt Zeilen auf die Teams ein, zu denen der Benutzer gehört:
CREATE POLICY team_projects ON projects
USING (client_id IN (
SELECT client_id
FROM team_clients
WHERE team_id IN (
SELECT team_id
FROM user_teams
WHERE user_email = current_user
)
));
Rollenbasierter Zugriff – Beschränkt Zeilen basierend auf der Rollenmitgliedschaft:
CREATE POLICY manager_access ON tasks
USING (
status = 'pending' OR
pg_has_role(current_user, 'managers', 'member')
);
Schreibgeschützt für bestimmte Rollen – Unterschiedliche Richtlinien für unterschiedliche Operationen:
-- Allow all users to read their assigned tasks
CREATE POLICY read_assigned_tasks ON tasks
FOR SELECT
USING (assigned_to = current_user);
-- Only managers can update tasks
CREATE POLICY update_tasks ON tasks
FOR UPDATE
TO "managers"
USING (true);
Weitere Ressourcen
Umfassende Informationen zur Implementierung von RLS, einschließlich Richtlinientypen, bewährten Sicherheitsmethoden und erweiterten Mustern, finden Sie in der Dokumentation zu Den Sicherheitsrichtlinien für PostgreSQL Row.
Weitere Informationen zu Berechtigungen finden Sie unter Verwalten von Berechtigungen.
API-Referenz
In diesem Abschnitt wird davon ausgegangen, dass Sie die Einrichtungsschritte, die konfigurierten Berechtigungen und die Implementierung der Sicherheit auf Zeilenebene abgeschlossen haben. Die folgenden Abschnitte enthalten Referenzinformationen für die Verwendung der Daten-API, einschließlich allgemeiner Vorgänge, erweiterter Features, Sicherheitsaspekte und Kompatibilitätsdetails.
Grundlegende Vorgänge
Datensätze abfragen
Abrufen von Datensätzen aus einer Tabelle mit HTTP GET:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients"
Beispielantwort:
[
{ "id": 1, "name": "Acme Corp", "email": "contact@acme.com", "company": "Acme Corporation", "phone": "+1-555-0101" },
{
"id": 2,
"name": "TechStart Inc",
"email": "hello@techstart.com",
"company": "TechStart Inc",
"phone": "+1-555-0102"
}
]
Ergebnisse filtern
Verwenden Sie Abfrageparameter, um Ergebnisse zu filtern. In diesem Beispiel werden Clients mit id größer oder gleich 2 abgerufen:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=gte.2"
Beispielantwort:
[
{ "id": 2, "name": "TechStart Inc", "email": "hello@techstart.com" },
{ "id": 3, "name": "Global Solutions", "email": "info@globalsolutions.com" }
]
Auswählen bestimmter Spalten und Verknüpfen von Tabellen
Verwenden Sie den select Parameter, um bestimmte Spalten abzurufen und verknüpfte Tabellen zu verknüpfen:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?select=id,name,projects(id,name)&id=gte.2"
Beispielantwort:
[
{ "id": 2, "name": "TechStart Inc", "projects": [{ "id": 3, "name": "Database Migration" }] },
{ "id": 3, "name": "Global Solutions", "projects": [{ "id": 4, "name": "API Integration" }] }
]
Einfügen von Datensätzen
Erstellen neuer Datensätze mithilfe von HTTP POST:
curl -X POST \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"name": "New Client",
"email": "newclient@example.com",
"company": "New Company Inc",
"phone": "+1-555-0104"
}' \
"$REST_ENDPOINT/public/clients"
Datensätze aktualisieren
Aktualisieren vorhandener Datensätze mithilfe von HTTP PATCH:
curl -X PATCH \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
-H "Content-Type: application/json" \
-d '{"phone": "+1-555-0199"}' \
"$REST_ENDPOINT/public/clients?id=eq.1"
Datensätze löschen
Löschen von Datensätzen mithilfe von HTTP DELETE:
curl -X DELETE \
-H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/clients?id=eq.5"
Erweiterte Features
Paginierung
Steuern Sie die Anzahl der Datensätze, die mit den Parametern limit und offset zurückgegeben werden.
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?limit=10&offset=0"
Sortieren
Sortierergebnisse mithilfe des order Parameters:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?order=due_date.desc"
Komplexe Filterung
Kombinieren mehrerer Filterbedingungen:
curl -H "Authorization: Bearer $DBX_OAUTH_TOKEN" \
"$REST_ENDPOINT/public/tasks?status=eq.in_progress&priority=eq.high"
Allgemeine Filteroperatoren:
-
eq- gleich -
gte- größer oder gleich -
lte- kleiner oder gleich -
neq- ungleich -
like-Mustervergleich -
in- entspricht einem beliebigen Wert in der Liste.
Weitere Informationen zu unterstützten Abfrageparametern und API-Features finden Sie in der PostgREST-API-Referenz. Informationen zu Lakebase-spezifischen Kompatibilitätsinformationen finden Sie unter PostgREST-Kompatibilität.
Referenz zur Feature-Kompatibilität
Die Lakebase-Daten-API ist vollständig mit der PostgREST-Spezifikation kompatibel, einschließlich Ressourceneinbettung (Fremdschlüssel und berechnete Beziehungen, Inner/Left Join-Hinweise), Antwortformate (JSON, CSV, GeoJSON, benutzerdefinierte Medientypen), Filterung, Paginierung, Zählmodi (exact, planned, estimated), Anforderungseinstellungen (handling, timezone, tx), Abfrageplan-Belichtung und RPC-Features.
Die folgenden PostgREST-Features sind in der Lakebase-Umgebung nicht anwendbar oder nicht verfügbar:
Authentifizierung
| Merkmal | Der Status | Einzelheiten |
|---|---|---|
| JWT-Konfiguration | Nicht anwendbar | Die Lakebase-Daten-API verwendet Azure Databricks OAuth-Token anstelle der JWT-Authentifizierung. JWT-spezifische Konfigurationsoptionen (benutzerdefinierte geheime Schlüssel, RS256-Schlüssel, Zielgruppenüberprüfung) sind nicht verfügbar. |
Erweiterte Konfiguration
| Merkmal | Der Status | Einzelheiten |
|---|---|---|
| Anwendungseinstellungen (GUCs) | Nicht unterstützt | Das Übergeben von benutzerdefinierten Konfigurationswerten an Datenbankfunktionen über PostgreSQL-GUCs wird nicht unterstützt. |
| Voranforderungsfunktion | Nicht unterstützt | Die db-pre-request Konfiguration, die das Ausführen einer Datenbankfunktion vor jeder Anforderung ermöglicht, wird nicht unterstützt. |
Observierbarkeit
| Merkmal | Der Status | Einzelheiten |
|---|---|---|
| Weitergabe von Ablaufverfolgungsheadern | Nicht anwendbar | Lakebase implementiert eigene Beobachtbarkeitsfeatures anstelle von X-Request-Id von PostgREST und der benutzerdefinierten Weitergabe von Ablaufverfolgungsheadern. |
Weitere Informationen zu PostgREST-Features finden Sie in der PostgREST-Dokumentation.
Sicherheitsüberlegungen
Die Daten-API erzwingt das Sicherheitsmodell Ihrer Datenbank auf mehreren Ebenen:
- Authentifizierung: Für alle Anforderungen ist eine gültige OAuth-Tokenauthentifizierung erforderlich.
- Rollenbasierter Zugriff: Berechtigungen auf Datenbankebene steuern, auf welche Tabellen und Vorgänge Benutzer zugreifen können
- Sicherheit auf Zeilenebene: RLS-Richtlinien erzwingen eine differenzierte Zugriffssteuerung, wodurch eingeschränkt wird, welche bestimmten Zeilen Benutzer sehen oder ändern können
- Benutzerkontext: Die API setzt die Identität des authentifizierten Benutzers voraus, um sicherzustellen, dass Datenbankberechtigungen und -richtlinien ordnungsgemäß angewendet werden.
Empfohlene Sicherheitsmaßnahmen
Für Produktionsumgebungen:
- Implementieren der Sicherheit auf Zeilenebene: Verwenden Sie RLS-Richtlinien, um den Datenzugriff auf Zeilenebene einzuschränken. Dies ist besonders wichtig für mandantenfähige Anwendungen und benutzereigene Daten. Siehe Sicherheit auf Zeilenebene.
-
Erteilen Sie minimale Berechtigungen: Gewähren Sie nur den Berechtigungen, die Benutzer benötigen (
SELECT,INSERT,UPDATE,DELETE) für bestimmte Tabellen, anstatt einen breiten Zugriff zu gewähren. - Verwenden Sie separate Rollen pro Anwendung: Erstellen Sie dedizierte Rollen für verschiedene Anwendungen oder Dienste, anstatt eine einzelne Rolle zu teilen.
- Regelmäßiger Überwachungszugriff: Überprüfen Sie erteilte Berechtigungen und RLS-Richtlinien, um sicherzustellen, dass sie Ihren Sicherheitsanforderungen entsprechen.
Informationen zum Verwalten von Rollen und Berechtigungen finden Sie unter: