Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Am Ende dieses Leitfadens haben Sie eine laufende Postgres-Datenbank mit Beispieldaten, die bereit sind, eine Verbindung mit Ihrer Anwendung herzustellen oder in das Databricks Lakehouse zu integrieren.
Schritte: (1) Erstellen eines Projekts → (2) Verbinden → (3) Erstellen einer Tabelle
Schritt 1: Erstellen Ihres ersten Projekts
Öffnen Sie die Lakebase-App über den App-Switcher.
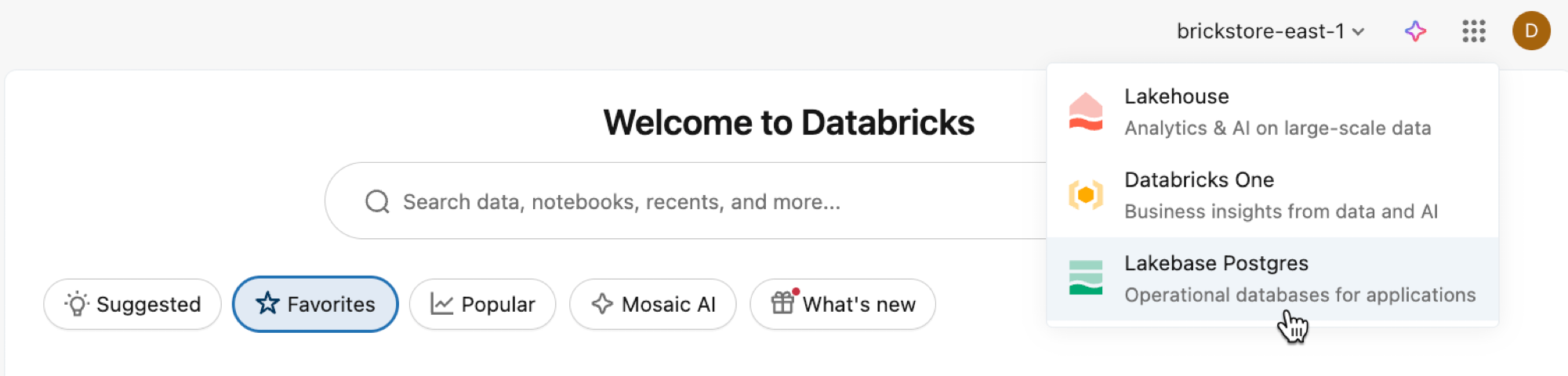
Wählen Sie "Automatische Skalierung" aus, um auf die Lakebase-Benutzeroberfläche für die automatische Skalierung zuzugreifen.
Klicke auf Neues Projekt. Geben Sie Ihrem Projekt einen Namen, und wählen Sie Ihre Postgres-Version aus. Ihr Projekt wird mit einem einzelnen production Branch, einer Standard databricks_postgres Datenbank und konfigurierten Computerressourcen für den Branch erstellt.
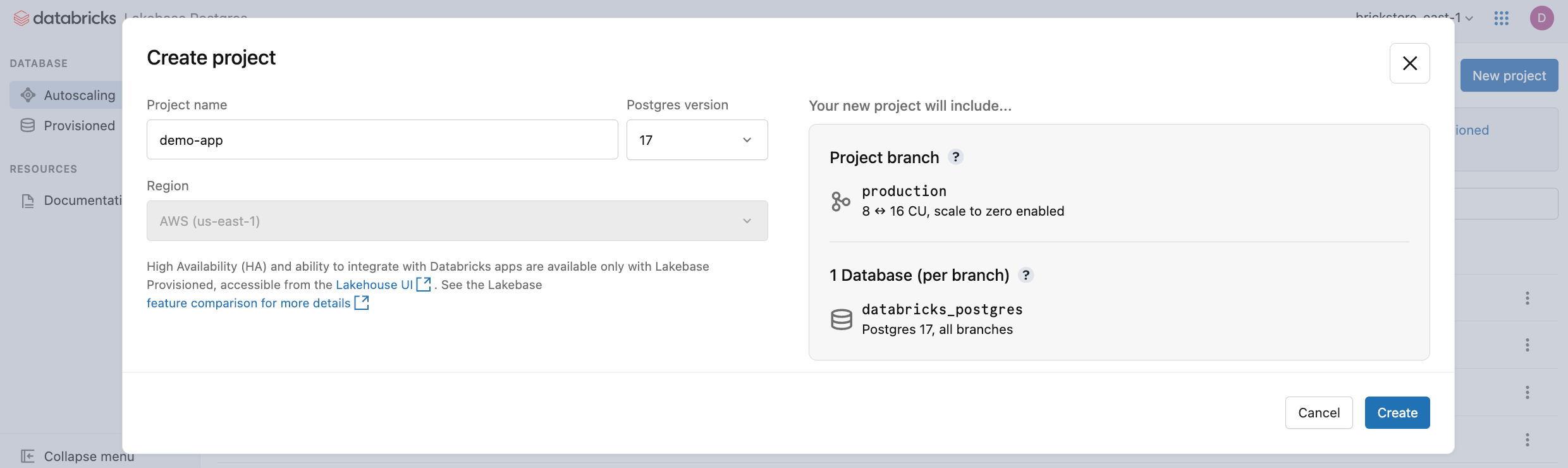
Es kann einige Minuten dauern, bis Die Berechnung aktiviert wird. Für den production Branch ist Scale-to-Zero standardmäßig mit einem Inaktivitäts-Timeout von 24 Stunden aktiviert, Sie können diese Einstellung jedoch bei Bedarf konfigurieren.
Die Region für Ihr Projekt wird automatisch auf Ihre Arbeitsbereichsregion festgelegt. Weitere Informationen finden Sie unter Regionale Verfügbarkeit.
Weitere Informationen: Erstellen eines Projekts | für die automatische Skalierung | auf Null
Schritt 2: Herstellen einer Verbindung mit Ihrer Datenbank
Wählen Sie im Projekt den Produktionszweig aus, und klicken Sie auf "Verbinden". Verbindungszeichenfolgen funktionieren mit jedem Standard-Postgres-Client (psql, pgAdmin, DBeaver oder Anwendungsframework).
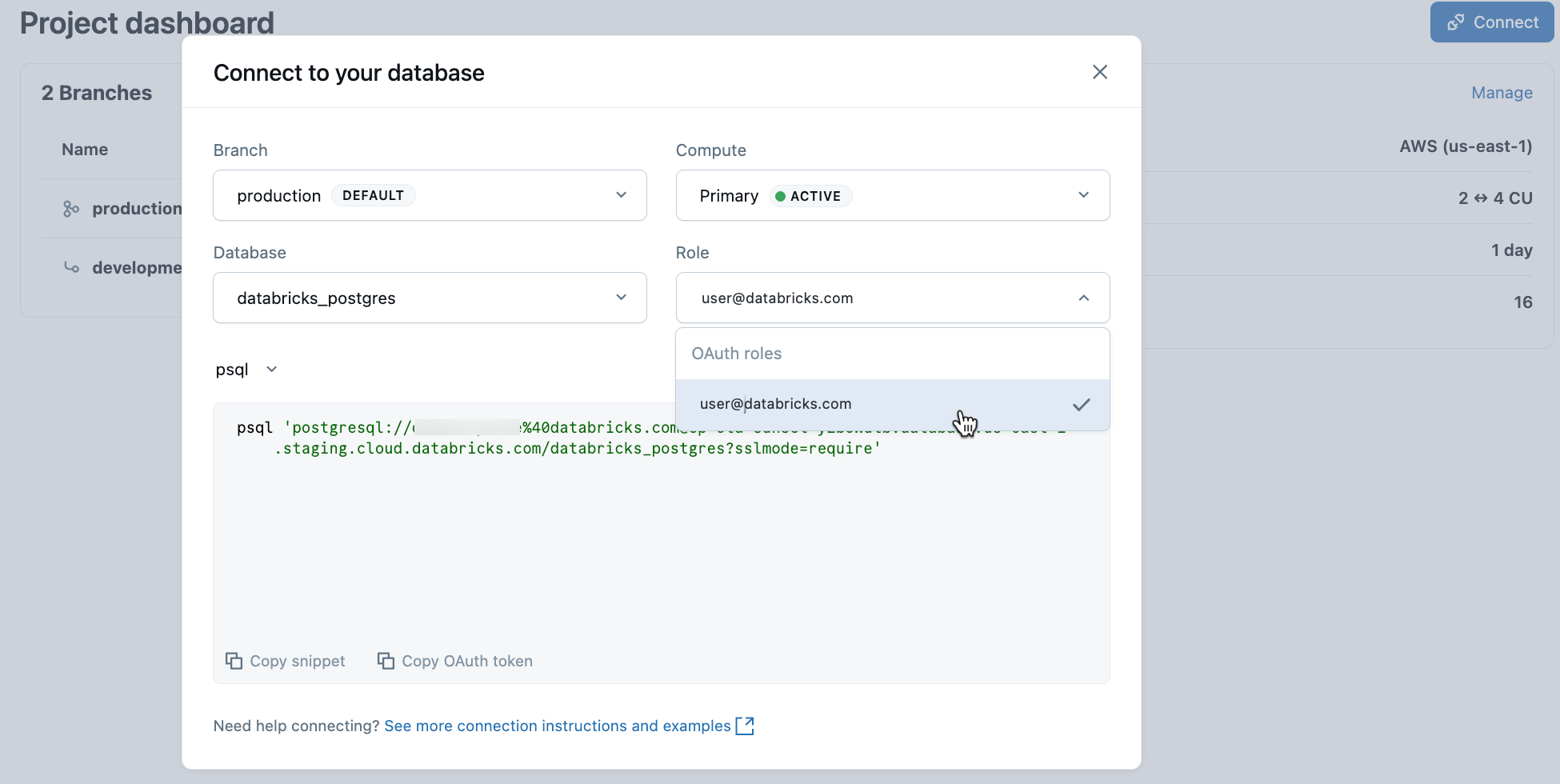
Um eine Verbindung mit Ihrer Databricks-Identität herzustellen, kopieren Sie den psql Codeausschnitt aus dem Verbindungsdialogfeld, und fügen Sie das OAuth-Token ein, wenn Sie dazu aufgefordert werden:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Weitere Informationen: Verbindungsschnellstart | psql | pgAdmin | Postgres-Clients
Schritt 3: Erstellen der ersten Tabelle
Der Lakebase SQL-Editor ist bereits mit SQL-Beispielen geladen. Wählen Sie in Ihrem Projekt den Produktionszweig aus, öffnen Sie den SQL-Editor, und führen Sie die bereitgestellten Anweisungen aus, um eine playing_with_lakebase Tabelle zu erstellen und Beispieldaten einzufügen.
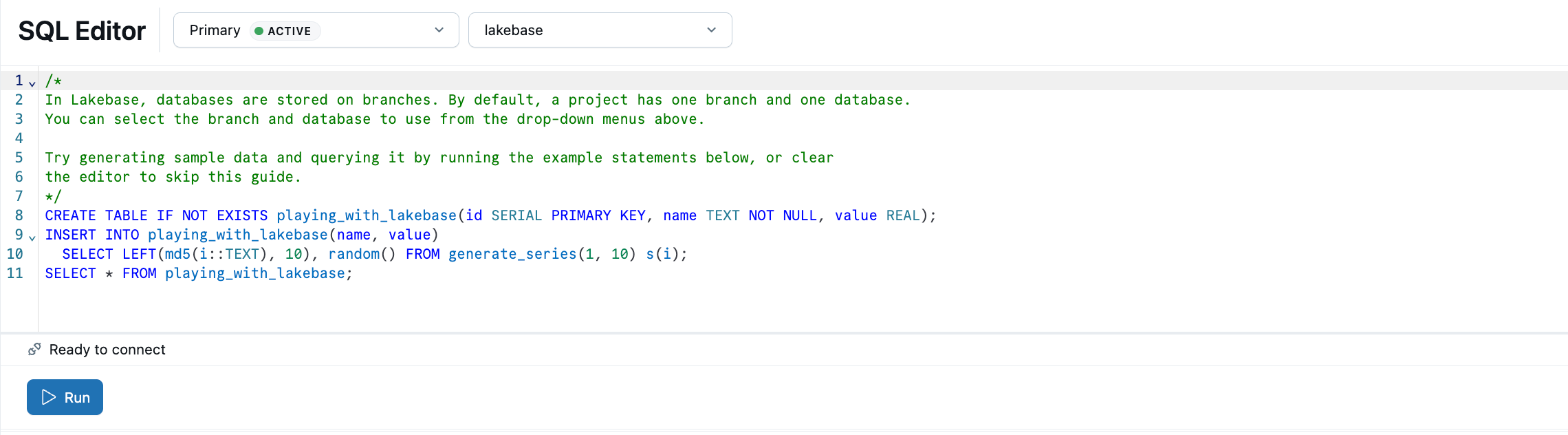
Weitere Informationen: SQL Editor | Tables Editor | Postgres-Clients
Nächste Schritte
| Nächster Schritt | Description |
|---|---|
| Lakehouse-Daten bereitstellen | Synchronisieren Sie Unity Catalog-Tabellen in Postgres für Lesevorgänge mit geringer Latenz. |
Weitere Informationen
| Ressource | Description |
|---|---|
| Erstellen einer App | Stellen Sie eine Databricks-App mit automatischer Lakebase-Verbindung bereit. |
| Registrieren im Unity-Katalog | Einheitliche Governance-, Lineage- und quellübergreifende Abfragen. |
| Kernkonzepte | Autoskalierung, Skalierung auf null, Branching und wie sie funktionieren. |
| Projekte | Architektur, Verzweigungsmodell und Produktübersicht. |