Bedarfsorientiertes Extrahieren, Transformieren und Laden (ETL)
ETL (Extrahieren, Transformieren und Laden) ist der Prozess, mit dem Daten aus verschiedenen Quellen abgerufen werden. Die Daten werden an einem Standardspeicherort gesammelt, bereinigt und verarbeitet. Zuletzt werden die Daten in einen Datenspeicher geladen, aus dem sie abgerufen werden können. Legacy-ETL-Prozesse importieren Daten, bereinigen Sie am Ursprungsort und speichern sie dann in einer relationalen Daten-Engine. Bei Azure HDInsight unterstützt eine Vielzahl von Apache Hadoop-Umgebungskomponenten bedarfsorientiertes ETL.
Die Verwendung von HDInsight im ETL-Prozess wird in dieser folgenden Pipeline zusammengefasst:
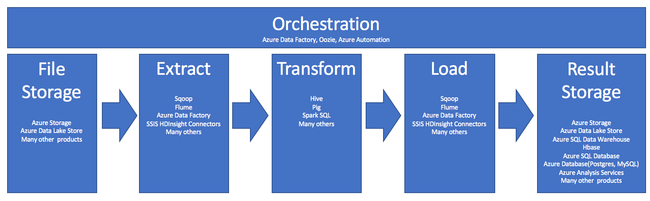
In den folgenden Abschnitten wird jede der ETL-Phasen mit den jeweils zugehörigen Komponenten eingehender untersucht.
Orchestrierung
Orchestrierung erstreckt sich über alle Phasen der ETL-Pipeline. ETL-Aufträge in HDInsight umfassen häufig mehrere verschiedene Produkte, die zusammenarbeiten. Beispiel:
- Sie können Apache Hive verwenden, um einen Teil der Daten zu bereinigen und einen anderen Teil mit Apache Pig bereinigen.
- Sie könnten Azure Data Factory verwenden, um Daten aus Azure Data Lake Store in Azure SQL-Datenbank zu laden.
Orchestrierung ist erforderlich, um den geeigneten Auftrag zum richtigen Zeitpunkt auszuführen.
Apache Oozie
Apache Oozie ist ein Koordinationssystem für Workflows zur Verwaltung von Hadoop-Aufträgen. Oozie wird innerhalb eines HDInsight-Clusters ausgeführt und ist in den Hadoop-Stapel integriert. Oozie unterstützt Hadoop-Aufträge für Apache Hadoop MapReduce, Pig, Hive und Sqoop. Sie können Oozie dazu verwenden, bestimmte Aufträge für ein System zu planen, z. B. Java-Programme oder Shellskripts.
Weitere Informationen finden Sie unter Verwenden von Apache Oozie mit Apache Hadoop zum Definieren und Ausführen eines Workflows in Linux-basiertem Azure HDInsight. Weitere Informationen finden Sie unter Operationalisieren einer Datenanalysepipeline.
Azure Data Factory
Azure Data Factory bietet Orchestrierungsfunktionen als Platform-as-a-Service (PaaS). Azure Data Factory ist ein cloudbasierter Datenintegrationsdienst. Damit können Sie datengesteuerte Workflows zur Orchestrierung und Automatisierung der Datenverschiebung und Transformation von Daten erstellen.
Verwenden Sie Azure Data Factory für Folgendes:
- Erstellen und planen Sie datengesteuerte Workflows. Diese Pipelines erfassen Daten aus unterschiedlichen Datenspeichern.
- Verarbeiten und transformieren Sie die Daten mithilfe von Compute Services wie HDInsight oder Hadoop. Sie können für diesen Schritt auch Spark, Azure Data Lake Analytics, Azure Batch oder Azure Machine Learning verwenden.
- Veröffentlichen von Ausgabedaten für Datenspeicher wie Azure Synapse Analytics für die Nutzung durch BI-Anwendungen
Weitere Informationen zu Azure Data Factory finden Sie in der Dokumentation.
Erfassungsdatei- und Ergebnisspeicher
Quelldatendateien werden in der Regel an einen Speicherort in Azure Storage oder Azure Data Lake Storage geladen. Die Dateien sind normalerweise in einem flachen Format wie CSV. Aber sie können in einem beliebigen Format vorliegen.
Azure Storage
Azure Storage hat spezifische Flexibilitätsziele. Weitere Informationen finden Sie unter Skalierbarkeits- und Leistungsziele für Blob Storage. Für die meisten analytische Knoten lässt sich Azure Storage am besten skalieren, wenn viele kleinere Dateien verarbeitet werden. Sofern Sie sich innerhalb Ihrer Grenzwerte bewegen, garantiert Azure Storage dieselbe Leistung, unabhängig von der Größe der Dateien. Sie können Terabyte an Daten speichern und dennoch eine konsistente Leistung erzielen. Diese Aussage gilt unabhängig davon, ob Sie eine Teilmenge oder alle Daten verwenden.
Azure Storage verfügt über verschiedene Arten von Blobs. Ein Anfügeblob ist eine großartige Möglichkeit zum Speichern von Webprotokollen oder Sensordaten.
Blobs können auf mehrere Server verteilt werden, um den Zugriff auf diese horizontal zu skalieren. Ein einzelnes Blob kann jedoch kann nur von einem einzelnen Server verarbeitet werden. Blobs können zwar logisch in Blobcontainern zusammengefasst werden, allerdings wirkt sich dies nicht auf die Partitionierung einer solchen Gruppierung aus.
Azure Storage verfügt über eine WebHDFS-API-Ebene für den Blobspeicher. Alle HDInsight-Dienste können auf Dateien in Azure Blob Storage zugreifen, um Daten zu bereinigen und zu verarbeiten. Dies ist vergleichbar mit der Verwendung von HDFS-Dateien (Hadoop Distributed File System) durch diese Dienste.
Daten werden in der Regel mithilfe von PowerShell, dem Azure Storage SDK oder mit AzCopy in Azure Storage erfasst.
Azure Data Lake Storage
Azure Data Lake Storage ist ein verwaltetes Hyperscalerepository für Analysedaten. Es ist kompatibel mit einem Entwurfsparadigma, das HDFS ähnlich ist, und verwendet es auch. Data Lake Store bietet unbegrenzte Flexibilität im Hinblick auf die Gesamtkapazität und die Größe einzelner Dateien. Es ist eine gute Wahl bei der Arbeit mit großen Dateien, da diese über mehrere Knoten gespeichert werden können. Die Partitionierung von Daten in Data Lake Storage erfolgt im Hintergrund. Sie erhalten einen enormen Durchsatz, um Analyseaufträge mit Tausenden gleichzeitiger Executors durchführen können, die Hunderte Terabytes von Daten effizient lesen und schreiben.
Die Daten werden in der Regel über Azure Data Factory in Data Lake Storage erfasst. Sie können auch Data Lake Storage-SDKs, den AdlCopy-Dienst, Apache DistCp oder Apache Sqoop verwenden. Der von Ihnen gewählte Dienst hängt davon ab, wo sich die Daten befinden. Wenn sie sich in einem vorhandenen Hadoop-Cluster befinden, können Sie Apache DistCp, den AdlCopy-Dienst oder Azure Data Factory verwenden. Wenn sie sich in Azure Blob Storage befinden, können Sie das Azure Data Lake Storage-.NET SDK, Azure PowerShell oder Azure Data Factory verwenden.
Data Lake Storage ist für die Ereigniserfassung über Azure Event Hubs optimiert.
Überlegungen zu beiden Speicheroptionen
Beim Hochladen von Datasets im Terabyte-Bereich kann die Netzwerklatenz ein großes Problem darstellen. Dies gilt insbesondere dann, wenn die Daten von einem lokalen Standort stammen. In solchen Fällen können Sie die folgenden Optionen verwenden:
Azure ExpressRoute: Erstellen Sie private Verbindungen zwischen Azure-Rechenzentren und Ihrer lokalen Infrastruktur. Diese Verbindungen bieten eine zuverlässige Möglichkeit zur Übertragung großer Datenmengen. Weitere Informationen finden Sie in der Dokumentation zu Azure ExpressRoute.
Hochladen von Daten von Festplattenlaufwerken: Sie können über den Azure Import/Export-Dienst Festplattenlaufwerke mit Ihren Daten an ein Azure-Rechenzentrum senden. Ihre Daten werden zunächst in Azure Blob Storage hochgeladen. Anschließend können Sie mit Azure Data Factory oder dem Tool AdlCopy Daten aus Azure Blob Storage in Data Lake Storage kopieren.
Azure Synapse Analytics
Azure Synapse Analytics ist eine geeignete Option zum Speichern vorbereiteter Ergebnisse. Sie können Azure HDInsight verwenden, um diese Dienste für Azure Synapse Analytics auszuführen.
Azure Synapse Analytics ist ein für analytische Workloads optimierter relationaler Datenbankspeicher. Es lässt sich am besten bei partitionierten Tabellen skalieren. Tabellen können über mehrere Knoten hinweg partitioniert werden. Die Knoten werden zum Zeitpunkt der Erstellung ausgewählt. Sie können gemäß dem Fakt skaliert werden, aber dies ist ein aktiver Prozess, der möglicherweise das Verschieben von Daten erfordert. Weitere Informationen finden Sie unter Verwalten von Computeressourcen in Azure Synapse Analytics.
Apache HBase
Apache HBase ist ein in Azure HDInsight verfügbarer Schlüssel-Wert-Speicher. Es ist eine Open-Source-NoSQL-Datenbank, die auf Hadoop basiert und nach dem Vorbild von Google BigTable erstellt wurde. HBase bietet leistungsfähigen, zufälligen Zugriff und ein hohes Maß an Konsistenz für große Mengen an unstrukturierten und teilweise strukturierten Daten.
Da HBase eine Datenbank ohne Schema ist, brauchen Sie keine Spalten und Datentypen zu definieren, bevor Sie sie verwenden. Daten werden in den Zeilen einer Tabelle gespeichert und nach Spaltenfamilie zusammengefasst.
Der Open-Source-Code lässt sich linear skalieren, sodass Petabytes von Daten auf Tausenden von Knoten verarbeitet werden können. HBase nutzt Datenredundanz, Stapelverarbeitung und andere Funktionen, die von verteilten Anwendungen in der Hadoop-Umgebung zur Verfügung gestellt werden.
HBase ist ein geeignetes Ziel für Sensor- und Protokolldaten zur zukünftigen Analyse.
Die Flexibilität von HBase hängt von der Anzahl der Knoten im HDInsight-Cluster ab.
Azure SQL-Datenbanken
Azure bietet drei relationale PaaS-Datenbanken:
- Azure SQL-Datenbank ist eine Implementierung von Microsoft SQL Server. Weitere Informationen zur Leistung finden Sie unter Optimieren der Leistung bei Azure SQL-Datenbank.
- Azure Database for MySQL ist eine Implementierung von Oracle MySQL.
- Azure Database for PostgreSQL ist eine Implementierung von PostgreSQL.
Erhöhen Sie die Anzahl der CPUs, und erweitern Sie den Arbeitsspeicher, um diese Produkte hochzuskalieren. Sie können sich auch entschließen, Premium-Datenträger mit den Produkten zu verwenden, um eine bessere E/A-Leistung zu erzielen.
Azure Analysis Services
Azure Analysis Services ist eine analytische Daten-Engine, die für die Entscheidungsunterstützung und Business Analytics verwendet wird. Es stellt die analytischen Daten für Geschäftsberichte und Clientanwendungen wie Power BI bereit. Die analytischen Daten funktionieren auch mit Excel, SQL Server Reporting Services-Berichten und anderen Tools zur Datenvisualisierung.
Skalieren Sie Analyse-Cubes durch Ändern der Ebenen für jeden einzelnen Cube. Weitere Informationen finden Sie unter Azure Analysis Services – Preise.
Extrahieren und Laden
Nachdem die Daten in Azure vorhanden sind, können Sie viele Dienste verwenden, um sie zu extrahieren und in andere Produkte zu laden. HDInsight unterstützt Sqoop und Flume.
Apache Sqoop
Apache Sqoop ist ein Tool für die effiziente Datenübertragung zwischen strukturierten, halb strukturierten und unstrukturierten Datenquellen.
Sqoop verwendet MapReduce zum Importieren und Exportieren der Daten, um Parallelbetrieb und Fehlertoleranz bereitzustellen.
Apache Flume
Apache Flume ist ein verteilter, zuverlässiger und verfügbarer Dienst für das effiziente Sammeln, Aggregieren und Verschieben großer Mengen von Protokolldaten. Seine flexible Architektur basiert auf Streamingdatenflüssen. Flume ist robust und fehlertolerant mit einstellbaren Zuverlässigkeitsmechanismen. Es verfügt über viele Failover- und Wiederherstellungsmechanismen. Flume verwendet ein einfaches, erweiterbares Datenmodell, das analytische Onlineanwendungen zulässt.
Apache Flume kann nicht mit Azure HDInsight verwendet werden. Aber eine lokale Hadoop-Installation kann Flume verwenden, um Daten an Azure Blob Storage oder Azure Data Lake Storage zu senden. Weitere Informationen finden Sie unter Verwenden von Apache Flume mit HDInsight.
Transformieren
Nachdem Daten am ausgewählten Speicherort vorhanden sind, müssen Sie sie bereinigen, kombinieren oder für ein bestimmtes Verwendungsmuster vorbereiten. Hive, Pig und Spark SQL sind alle eine gute Wahl für diese Art von Arbeit. Sie werden alle unter HDInsight unterstützt.