Verwenden von Apache Hive als Tool zum Extrahieren, Transformieren und Laden (ETL)
In der Regel müssen Sie eingehende Daten bereinigen und transformieren, bevor Sie sie auf ein Ziel laden, das für Analysezwecke geeignet ist. ETL-Vorgänge (Extrahieren, Transformieren und Laden) werden genutzt, um Daten vorzubereiten und auf ein Datenziel zu laden. Apache Hive in HDInsight kann unstrukturierte Daten lesen, die Daten je nach Bedarf verarbeiten und sie dann in ein relationales Data Warehouse für Systeme zur Entscheidungsunterstützung laden. Bei dieser Vorgehensweise werden Daten aus der Quelle extrahiert. Dann werden sie in anpassbarem Speicher gespeichert, z. B in Azure Storage-Blobs oder Azure Data Lake Storage. Im nächsten Schritt werden die Daten mithilfe einer Abfolge von Hive-Abfragen transformiert. Schließlich werden sie innerhalb von Hive bereitgestellt, um das Massenladen in den Zieldatenspeicher vorzubereiten.
Übersicht über den Anwendungsfall und das Modell
Die folgende Abbildung enthält eine Übersicht über den Anwendungsfall und das Modell für die ETL-Automatisierung. Eingabedaten werden transformiert, um die jeweilige Ausgabe zu generieren. Während dieser Transformation wird bei den Daten die Form, der Datentyp und sogar die Sprache geändert. Für ETL-Prozesse können Maße von „Britisch“ in „Metrisch“ konvertiert, Zeitzonen geändert und die Genauigkeit verbessert werden, um eine Anpassung an die vorhandenen Daten am Ziel durchzuführen. Außerdem können für ETL-Prozesse neue Daten mit vorhandenen Daten kombiniert werden, um die Berichterstellung aktuell zu halten oder weitere Einblicke in vorhandene Daten zu ermöglichen. Anwendungen, z. B. Berichterstellungstools und Dienste, können diese Daten dann im gewünschten Format nutzen.
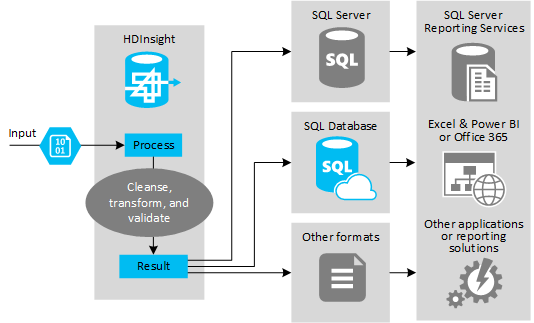
Hadoop wird normalerweise in ETL-Prozessen verwendet, bei denen eine große Anzahl von Textdateien (z B. CSV-Dateien) importiert wird. Oder es wird eine kleinere, aber sich häufig ändernde Anzahl von Textdateien (oder aber beides) importiert. Hive ist ein hervorragendes Tool zum Vorbereiten der Daten, bevor diese auf das Datenziel geladen werden. Hive ermöglicht Ihnen die Erstellung eines Schemas für CSV und die Verwendung einer SQL-ähnlichen Sprache zum Generieren von MapReduce-Programmen, die mit den Daten interagieren.
Die typischen Schritte zur Ausführung von ETL-Vorgängen mithilfe von Hive lauten wie folgt:
Laden Sie Daten in Azure Data Lake Storage oder Azure Blob Storage.
Erstellen Sie eine Metadatenspeicher-Datenbank (mit Azure SQL-Datenbank), die von Hive beim Speichern Ihrer Schemas verwendet werden kann.
Erstellen Sie einen HDInsight-Cluster, und stellen Sie eine Verbindung mit dem Datenspeicher her.
Definieren Sie das Schema, das zur Lesezeit auf Daten im Datenspeicher angewendet werden soll:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';Transformieren Sie die Daten, und laden Sie sie auf das Ziel. Es gibt mehrere Möglichkeiten, Hive während der Transformation und beim Laden zu verwenden:
- Führen Sie mit Hive das Abfragen und Vorbereiten der Daten durch. Speichern Sie sie im CSV-Format in Azure Data Lake Storage oder Azure Blob Storage. Verwenden Sie anschließend ein Tool wie SQL Server Integration Services (SSIS), um diese CSVs zu beschaffen, und laden Sie die Daten dann in eine relationale Zieldatenbank, z.B. SQL Server.
- Fragen Sie die Daten aus Excel oder über C# ab, indem Sie den Hive ODBC-Treiber verwenden.
- Verwenden Sie Apache Sqoop, um die vorbereiteten CSV-Flatfiles zu lesen, und laden Sie sie in die relationale Zieldatenbank.
Datenquellen
Bei Datenquellen handelt es sich in der Regel um externe Daten, die an vorhandene Daten in Ihrem Datenspeicher angepasst werden können, z.B.:
- Social Media-Daten, Protokolldateien, Sensoren und Anwendungen, die Datendateien generieren.
- Von Datenanbietern beschaffte Datasets, z.B. Wetterstatistiken oder Verkaufszahlen von Herstellern.
- Streamingdaten, die über ein geeignetes Tool oder Framework erfasst, gefiltert und verarbeitet werden.
Ausgabeziele
Sie können Daten mithilfe von Hive auf verschiedenen Arten von Zielen ausgeben, z. B.:
- Eine relationale Datenbank, z.B. SQL Server oder Azure SQL-Datenbank
- Ein Data Warehouse, z. B. Azure Synapse Analytics.
- Excel
- Azure-Tabellen- und -Blobspeicher
- Anwendungen oder Dienste, für die Daten in bestimmten Formaten oder als Dateien mit bestimmten Arten von Informationsstrukturen verarbeitet werden müssen.
- Ein JSON-Dokumentspeicher wie Azure Cosmos DB.
Überlegungen
Das ETL-Modell wird normalerweise für die folgenden Fälle verwendet:
* Laden von Streamingdaten oder großen Mengen von halb- oder unstrukturierten Daten aus externen Quellen in eine vorhandene Datenbank oder ein Informationssystem.
* Bereinigen, Transformieren und Überprüfen der Daten vor dem Laden, ggf. mit mehr als einem Transformationsdurchlauf durch den Cluster.
* Generieren von Berichten und Visualisierungen, die regelmäßig aktualisiert werden. Falls die Berichterstellung während des Tags beispielsweise zu lange dauert, können Sie die Erstellung des Berichts für die Nacht planen. Um eine Hive-Abfrage automatisch auszuführen, können Sie Azure Logic Apps und PowerShell verwenden.
Wenn das Ziel für die Daten keine Datenbank ist, können Sie eine Datei im passenden Format innerhalb der Abfrage generieren, z.B. eine CSV-Datei. Diese Datei kann dann in Excel oder Power BI importiert werden.
Falls Sie im Rahmen des ETL-Prozesses mehrere Vorgänge für die Daten ausführen müssen, sollten Sie die damit verbundene Verwaltung berücksichtigen. Entscheiden Sie bei Vorgängen, die durch ein externes Programm (und nicht als Workflow innerhalb der Lösung) gesteuert werden, ob einige Vorgänge parallel ausgeführt werden können. Und ob erkannt werden soll, wann jeder Auftrag abgeschlossen ist. Die Verwendung eines Workflowmechanismus wie Oozie in Hadoop kann einfacher als der Versuch sein, mithilfe von externen Skripts oder benutzerdefinierten Programmen eine Sequenz von Vorgängen zu orchestrieren.
Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für