Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieses Tutorial veranschaulicht die Verwendung des strukturierten Apache Spark-Streamings zum Lesen und Schreiben von Daten mit Apache Kafka in Azure HDInsight.
Strukturiertes Spark-Streaming ist ein auf Spark SQL beruhendes Modul zur Streamverarbeitung. Sie können damit Streamingberechnungen genauso wie Batchberechnung auf statischen Daten ausdrücken.
In diesem Tutorial lernen Sie Folgendes:
- Verwenden einer Azure Resource Manager-Vorlage zum Erstellen von Clustern
- Verwenden des strukturierten Spark-Streamings mit Kafka
Denken Sie nach dem Ausführen der Schritte in diesem Dokument daran, die Cluster zu löschen, um das Anfallen von Gebühren zu verhindern.
Voraussetzungen
jq, ein JSON-Befehlszeilenprozessor. Siehe https://stedolan.github.io/jq/.
Kenntnisse im Umgang mit Jupyter Notebooks mit Spark in HDInsight. Weitere Informationen finden Sie im Dokument Tutorial: Laden von Daten und Ausführen von Abfragen auf einem Apache Spark-Cluster in Azure HDInsight.
Kenntnisse in der Programmiersprache Scala. Der in diesem Tutorial verwendete Code ist in Scala geschrieben.
Kenntnisse im Erstellen von Kafka-Themen. Weitere Informationen finden Sie im Dokument Schnellstart: Erstellen eines Apache Kafka-Clusters in HDInsight.
Wichtig
Für die in diesem Dokument beschriebenen Schritte wird eine Azure-Ressourcengruppe benötigt, die sowohl einen Spark- und einen Kafka-Cluster in HDInsight beinhaltet. Die Cluster befinden sich innerhalb eines virtuellen Azure-Netzwerks, wodurch Spark- und Kafka-Cluster direkt miteinander kommunizieren können.
Der Einfachheit halber enthält dieses Dokument Links zu einer Vorlage, mit der die erforderlichen Azure-Ressourcen erstellt werden können.
Weitere Informationen zur Verwendung von HDInsight in einem virtuellen Netzwerk finden Sie im Dokument Plan a virtual network for Azure HDInsight (Planen eines virtuellen Netzwerks für HDInsight).
Strukturiertes Streaming mit Apache Kafka
Das strukturierte Spark-Streaming ist eine auf Spark SQL basierende Streamverarbeitungs-Engine. Wenn Sie das strukturierte Streaming verwenden, können Sie Streamingabfragen auf dieselbe Weise wie Batchabfragen schreiben.
Die folgenden Codeausschnitte veranschaulichen das Lesen aus Kafka und das Speichern in einer Datei. Der erste ist ein Batchvorgang, und der zweite ist ein Streamingvorgang:
// Read a batch from Kafka
val kafkaDF = spark.read.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data and write to file
kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip")
.write
.format("parquet")
.option("path","/example/batchtripdata")
.option("checkpointLocation", "/batchcheckpoint")
.save()
// Stream from Kafka
val kafkaStreamDF = spark.readStream.format("kafka")
.option("kafka.bootstrap.servers", kafkaBrokers)
.option("subscribe", kafkaTopic)
.option("startingOffsets", "earliest")
.load()
// Select data from the stream and write to file
kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip")
.writeStream
.format("parquet")
.option("path","/example/streamingtripdata")
.option("checkpointLocation", "/streamcheckpoint")
.start.awaitTermination(30000)
In beiden Ausschnitten werden die Daten aus Kafka gelesen und in eine Datei geschrieben. Folgende Unterschiede weisen die Beispiele auf:
| Batch | Streaming |
|---|---|
read |
readStream |
write |
writeStream |
save |
start |
Der Streamingvorgang verwendet außerdem awaitTermination(30000), sodass der Stream nach 30.000 ms beendet wird.
Um das strukturierte Streaming mit Kafka zu verwenden, benötigt das Projekt eine Abhängigkeit im Paket org.apache.spark : spark-sql-kafka-0-10_2.11. Die Version dieses Pakets sollte der Version von Spark in HDInsight entsprechen. Für Spark 2.4 (verfügbar in HDInsight 4.0) finden Sie die Abhängigkeitsinformationen für verschiedene Projekttypen unter https://search.maven.org/#artifactdetails%7Corg.apache.spark%7Cspark-sql-kafka-0-10_2.11%7C2.2.0%7Cjar.
Für das in diesem Tutorial verwendete Jupyter Notebook lädt die folgende Zelle diese Paketabhängigkeit:
%%configure -f
{
"conf": {
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0",
"spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11"
}
}
Erstellen von Clustern
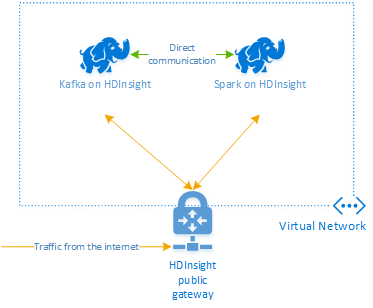
Apache Kafka in HDInsight ermöglicht keinen Zugriff auf die Kafka-Broker über das öffentliche Internet. Alle von Kafka verwendeten Elemente müssen sich im gleichen virtuellen Azure-Netzwerk befinden. In diesem Tutorial befinden sich der Kafka- und der Spark-Cluster im gleichen virtuellen Azure-Netzwerk.
Das folgende Diagramm zeigt den Kommunikationsfluss zwischen Spark und Kafka:
Hinweis
Der Kafka-Dienst ist auf die Kommunikation innerhalb des virtuellen Netzwerks beschränkt. Auf andere Dienste auf dem Cluster, wie z.B. SSH und Ambari, kann über das Internet zugegriffen werden. Weitere Informationen zu den öffentlichen Ports, die für HDInsight verfügbar sind, finden Sie unter Von HDInsight verwendete Ports und URIs.
Führen Sie zum Erstellen eines virtuellen Azure-Netzwerks und zum anschließenden Erstellen der Kafka- und Spark-Cluster in diesem die folgenden Schritte aus:
Verwenden Sie die folgende Schaltfläche, um sich bei Azure anzumelden, und öffnen Sie die Vorlage im Azure-Portal.

Die Azure Resource Manager-Vorlage finden Sie unter https://raw.githubusercontent.com/Azure-Samples/hdinsight-spark-kafka-structured-streaming/master/azuredeploy.json .
Diese Vorlage erstellt die folgenden Ressourcen:
Ein Kafka-Cluster unter HDInsight 4.0 oder 5.0.
Ein Spark 2.4- oder 3.1-Cluster unter HDInsight 4.0 oder 5.0.
Ein Azure Virtual Network, das die HDInsight-Cluster enthält.
Wichtig
Das in diesem Tutorial für strukturiertes Streaming verwendete Notebook benötigt Spark 2.4 oder 3.1 unter HDInsight 4.0 oder 5.0. Bei Verwendung einer früheren Version von Spark auf HDInsight erhalten Sie Fehlermeldungen, wenn Sie das Notebook verwenden.
Geben Sie im Abschnitt Benutzerdefinierte Vorlage folgende Informationen an:
Einstellung Wert Subscription Ihr Azure-Abonnement Resource group Die Ressourcengruppe mit den Ressourcen. Standort Die Azure-Region, in der die Ressourcen erstellt werden. Spark Cluster Name (Spark-Clustername) Der Name des Spark-Clusters. Die ersten sechs Zeichen müssen sich vom Kafka-Clusternamen unterscheiden. Kafka Cluster Name (Kafka-Clustername) Der Name des Kafka-Clusters. Die ersten sechs Zeichen müssen sich vom Spark-Clusternamen unterscheiden. Benutzername für Clusteranmeldung Der Administratorbenutzername für die Cluster. Kennwort für Clusteranmeldung Das Administratorbenutzerkennwort für die Cluster. SSH-Benutzername Der SSH-Benutzer, der für die Cluster erstellt werden soll. SSH-Kennwort Das Kennwort für den SSH-Benutzer. 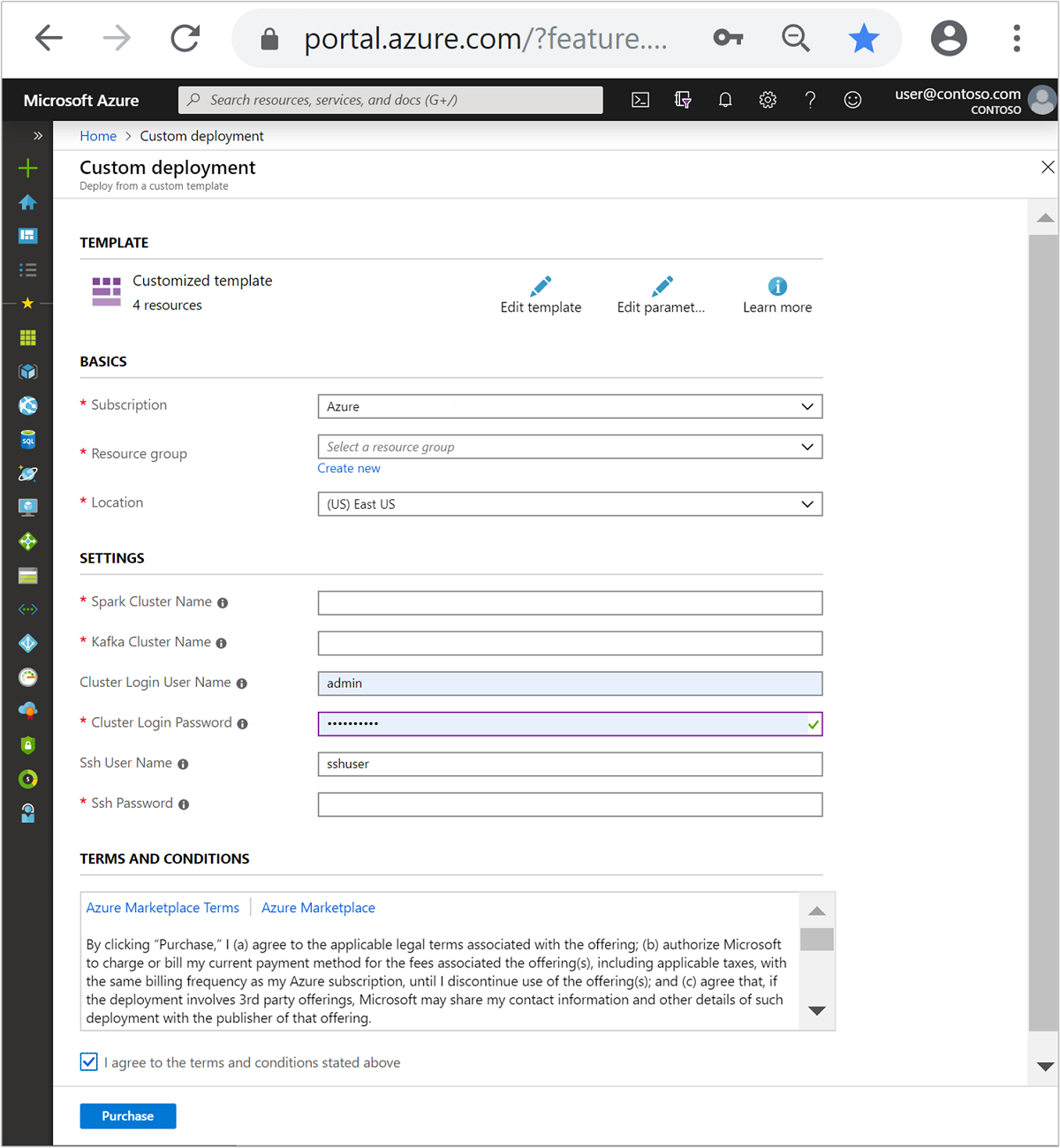
Lesen Sie die Geschäftsbedingungen, und wählen Sie anschließend die Option Ich stimme den oben genannten Geschäftsbedingungen zu aus.
Wählen Sie die Option Kaufen.
Hinweis
Die Clustererstellung kann bis zu 20 Minuten dauern.
Verwenden des strukturierten Spark-Streamings
Dieses Beispiel zeigt, wie Sie strukturiertes Spark-Streaming mit Kafka in HDInsight verwenden. Im Beispiel werden von New York City bereitgestellte Daten für Taxifahrten verwendet. Das von diesem Notebook verwendete Dataset stammt aus 2016 Green Taxi Trip Data.
Sammeln Sie Hostinformationen. Verwenden Sie die unten stehenden cURL- und jq-Befehle, um Ihre Kafka ZooKeeper- und -Broker-Hostinformationen abzurufen. Die Befehle sind für eine Windows-Eingabeaufforderung vorgesehen. Für andere Umgebungen sind geringfügige Änderungen erforderlich. Ersetzen Sie
KafkaClusterdurch den Namen Ihres Kafka-Clusters undKafkaPassworddurch das Kennwort für die Clusteranmeldung. Ersetzen Sie außerdemC:\HDI\jq-win64.exedurch den tatsächlichen Pfad zu Ihrer jq-Installation. Geben Sie die Befehle an einer Windows-Eingabeaufforderung ein, und speichern Sie die Ausgabe zur Verwendung in späteren Schritten.REM Enter cluster name in lowercase set CLUSTERNAME=KafkaCluster set PASSWORD=KafkaPassword curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/ZOOKEEPER/components/ZOOKEEPER_SERVER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):2181"""] | join(""",""")" curl -u admin:%PASSWORD% -G "https://%CLUSTERNAME%.azurehdinsight.net/api/v1/clusters/%CLUSTERNAME%/services/KAFKA/components/KAFKA_BROKER" | C:\HDI\jq-win64.exe -r "["""\(.host_components[].HostRoles.host_name):9092"""] | join(""",""")"Navigieren Sie in einem Webbrowser zu
https://CLUSTERNAME.azurehdinsight.net/jupyter, wobeiCLUSTERNAMEder Name Ihres Clusters ist. Geben Sie bei Aufforderung den Clusterbenutzernamen (Administrator) und das Kennwort ein, den bzw. das Sie beim Erstellen des Clusters verwendet haben.Wählen Sie Neu > Spark aus, um ein Notebook zu erstellen.
Spark-Streaming beinhaltet Mikrobatchverarbeitung. Das bedeutet, dass Daten als Batches vorliegen und Executors für die Datenbatches ausgeführt werden. Ist das Leerlauftimeout des Executors geringer als die für die Verarbeitung des Batches benötigte Zeit, werden die Executors ständig hinzugefügt und entfernt. Ist das Leerlauftimeout der Executors länger als die Batchdauer, wird der Executor nie entfernt. Daher wird empfohlen, die dynamische Zuteilung zu deaktivieren, indem Sie „spark.dynamicAllocation.enabled“ bei der Ausführung von Streaminganwendungen auf „false“ festlegen.
Laden Sie die vom Notebook verwendeten Pakete, indem Sie die folgenden Informationen in einer Zelle des Notebooks eingeben. Führen Sie den Befehl mit STRG+EINGABETASTEaus.
%%configure -f { "conf": { "spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.2.0", "spark.jars.excludes": "org.scala-lang:scala-reflect,org.apache.spark:spark-tags_2.11", "spark.dynamicAllocation.enabled": false } }Erstellen Sie das Kafka-Thema. Bearbeiten Sie den folgenden Befehl, indem Sie
YOUR_ZOOKEEPER_HOSTSdurch die ZooKeeper-Hostinformationen ersetzen, die Sie im ersten Schritt extrahiert haben. Geben Sie den bearbeiteten Befehl in Ihrem Jupyter Notebook ein, um das Thematripdatazu erstellen.%%bash export KafkaZookeepers="YOUR_ZOOKEEPER_HOSTS" /usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic tripdata --zookeeper $KafkaZookeepersRufen Sie Daten zu Taxifahrten ab. Geben Sie den Befehl in der nächsten Zelle ein, um Daten zu Taxifahrten in New York City zu laden. Die Daten werden in einen Datenrahmen geladen, der dann als Zellenausgabe angezeigt wird.
import spark.implicits._ // Load the data from the New York City Taxi data REST API for 2016 Green Taxi Trip Data val url="https://data.cityofnewyork.us/resource/pqfs-mqru.json" val result = scala.io.Source.fromURL(url).mkString // Create a dataframe from the JSON data val taxiDF = spark.read.json(Seq(result).toDS) // Display the dataframe containing trip data taxiDF.show()Legen Sie die Hostinformationen für den Kafka-Broker fest. Ersetzen Sie
YOUR_KAFKA_BROKER_HOSTSdurch die Broker-Hostinformationen, die Sie in Schritt 1 extrahiert haben. Geben Sie den bearbeiteten Befehl in der nächsten Zelle des Jupyter Notebooks ein.// The Kafka broker hosts and topic used to write to Kafka val kafkaBrokers="YOUR_KAFKA_BROKER_HOSTS" val kafkaTopic="tripdata" println("Finished setting Kafka broker and topic configuration.")Senden Sie die Daten an Kafka. Im folgenden Befehl wird das Feld
vendoridals Schlüsselwert für die Kafka-Nachricht verwendet. Der Schlüssel wird beim Partitionieren von Daten von Kafka verwendet. Alle Felder werden in der Kafka-Nachricht als JSON-Zeichenfolgenwert gespeichert. Geben Sie den folgenden Befehl in Jupyter ein, um die Daten mithilfe einer Batchabfrage in Kafka zu speichern.// Select the vendorid as the key and save the JSON string as the value. val query = taxiDF.selectExpr("CAST(vendorid AS STRING) as key", "to_JSON(struct(*)) AS value").write.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("topic", kafkaTopic).save() println("Data sent to Kafka")Deklarieren Sie ein Schema. Der folgende Befehl zeigt, wie Sie beim Lesen von JSON-Daten aus Kafka ein Schema verwenden. Geben Sie den Befehl in der nächsten Jupyter-Zelle ein.
// Import bits used for declaring schemas and working with JSON data import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ // Define a schema for the data val schema = (new StructType).add("dropoff_latitude", StringType).add("dropoff_longitude", StringType).add("extra", StringType).add("fare_amount", StringType).add("improvement_surcharge", StringType).add("lpep_dropoff_datetime", StringType).add("lpep_pickup_datetime", StringType).add("mta_tax", StringType).add("passenger_count", StringType).add("payment_type", StringType).add("pickup_latitude", StringType).add("pickup_longitude", StringType).add("ratecodeid", StringType).add("store_and_fwd_flag", StringType).add("tip_amount", StringType).add("tolls_amount", StringType).add("total_amount", StringType).add("trip_distance", StringType).add("trip_type", StringType).add("vendorid", StringType) // Reproduced here for readability //val schema = (new StructType) // .add("dropoff_latitude", StringType) // .add("dropoff_longitude", StringType) // .add("extra", StringType) // .add("fare_amount", StringType) // .add("improvement_surcharge", StringType) // .add("lpep_dropoff_datetime", StringType) // .add("lpep_pickup_datetime", StringType) // .add("mta_tax", StringType) // .add("passenger_count", StringType) // .add("payment_type", StringType) // .add("pickup_latitude", StringType) // .add("pickup_longitude", StringType) // .add("ratecodeid", StringType) // .add("store_and_fwd_flag", StringType) // .add("tip_amount", StringType) // .add("tolls_amount", StringType) // .add("total_amount", StringType) // .add("trip_distance", StringType) // .add("trip_type", StringType) // .add("vendorid", StringType) println("Schema declared")Wählen Sie Daten aus, und starten Sie den Stream. Der folgende Befehl zeigt, wie Sie mithilfe einer Batchabfrage Daten aus Kafka abrufen. Anschließend schreiben Sie die Ergebnisse in HDFS im Spark-Cluster. In diesem Beispiel ruft
selectdie Nachricht (Wertfeld) aus Kafka ab und wendet das Schema an. Die Daten werden dann im Parquet-Format in das Hadoop Distributed File System (WASB oder ADL) geschrieben. Geben Sie den Befehl in der nächsten Jupyter-Zelle ein.// Read a batch from Kafka val kafkaDF = spark.read.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data and write to file val query = kafkaDF.select(from_json(col("value").cast("string"), schema) as "trip").write.format("parquet").option("path","/example/batchtripdata").option("checkpointLocation", "/batchcheckpoint").save() println("Wrote data to file")Sie können überprüfen, ob die Dateien erstellt wurden, indem Sie den Befehl in Ihrer nächsten Jupyter-Zelle eingeben. Der Befehl listet die Dateien im Verzeichnis
/example/batchtripdataauf.%%bash hdfs dfs -ls /example/batchtripdataIm vorherige Beispiel wurde eine Batchabfrage verwendet. Der folgende Befehl zeigt, wie Sie den gleichen Vorgang mit einer Streamingabfrage ausführen. Geben Sie den Befehl in der nächsten Jupyter-Zelle ein.
// Stream from Kafka val kafkaStreamDF = spark.readStream.format("kafka").option("kafka.bootstrap.servers", kafkaBrokers).option("subscribe", kafkaTopic).option("startingOffsets", "earliest").load() // Select data from the stream and write to file kafkaStreamDF.select(from_json(col("value").cast("string"), schema) as "trip").writeStream.format("parquet").option("path","/example/streamingtripdata").option("checkpointLocation", "/streamcheckpoint").start.awaitTermination(30000) println("Wrote data to file")Führen Sie die folgende Zelle aus, um zu überprüfen, ob die Dateien von der Streamingabfrage geschrieben wurden.
%%bash hdfs dfs -ls /example/streamingtripdata
Bereinigen von Ressourcen
Zum Bereinigen der im Rahmen dieses Tutorials erstellten Ressourcen können Sie die Ressourcengruppe löschen. Beim Löschen der Ressourcengruppe wird auch der zugehörige HDInsight-Cluster gelöscht. Darüber hinaus werden auch alle anderen Ressourcen gelöscht, die der Ressourcengruppe zugeordnet sind.
So entfernen Sie die Ressourcengruppe über das Azure-Portal:
- Erweitern Sie im Azure-Portal das Menü auf der linken Seite, um das Menü mit den Diensten zu öffnen, und wählen Sie Ressourcengruppen aus, um die Liste mit Ihren Ressourcengruppen anzuzeigen.
- Suchen Sie die zu löschende Ressourcengruppe, und klicken Sie mit der rechten Maustaste rechts neben dem Eintrag auf die Schaltfläche Mehr (...).
- Klicken Sie auf Ressourcengruppe löschen, und bestätigen Sie den Vorgang.
Warnung
Die Abrechnung für einen HDInsight-Cluster beginnt, sobald der Cluster erstellt wurde, und endet mit dem Löschen des Clusters. Die Gebühren werden anteilig nach Minuten erhoben. Daher sollten Sie Ihren Cluster immer löschen, wenn Sie ihn nicht mehr verwenden.
Wenn Sie einen Kafka-Cluster in HDInsight löschen, werden auch alle in Kafka gespeicherten Daten gelöscht.