Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Big Data-Echtzeitlösungen verarbeiten Daten während der Übertragung. In der Regel sind diese Daten zum Zeitpunkt des Eingangs am nützlichsten. Wenn der eingehende Datenstrom aufgrund seiner Größe nicht mehr verarbeitet werden kann, müssen die Ressourcen gedrosselt werden. Alternativ kann ein HDInsight-Cluster hochskaliert werden, um die Anforderungen Ihrer Lösung durch bedarfsgerechtes Hinzufügen von Knoten zu erfüllen.
Von den Datenquellen einer Streaminganwendung können pro Sekunde Millionen von Ereignissen generiert werden, die schnell und ohne den Verlust nützlicher Informationen erfasst werden müssen. Die eingehenden Ereignisse werden durch Streampufferung (auch Ereignisqueuing genannt) von einem Dienst wie Apache Kafka oder Event Hubs verarbeitet. Nachdem die Ereignisse erfasst wurden, können Sie die Daten innerhalb der Streamverarbeitungsschicht mithilfe eines Echtzeitanalysesystems. Die verarbeiteten Daten können langfristig in entsprechenden Systemen wie Azure Data Lake Storage gespeichert und in Echtzeit in einem Business Intelligence-Dashboard wie Power BI oder Tableau oder auf einer benutzerdefinierten Webseite angezeigt werden.
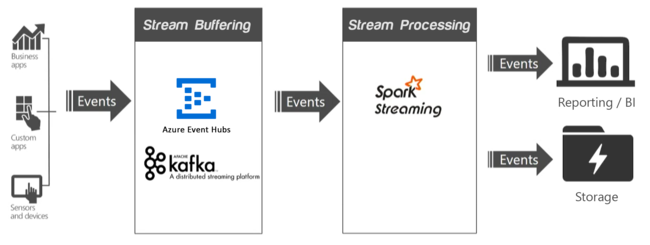
Apache Kafka
Apache Kafka bietet einen Message Queuing-Dienst mit hohem Durchsatz und geringer Wartezeit und ist nun Teil der Apache-OOS-Suite (Open Source Software). Kafka verwendet ein auf Veröffentlichung und Abonnements basierendes Messagingmodell und speichert Streams von partitionierten Daten sicher in einem verteilten, replizierten Cluster. Bei zunehmendem Durchsatz wird Kafka linear skaliert.
Weitere Informationen finden Sie unter Einführung in Apache Kafka in HDInsight.
Spark Streaming
Spark Streaming ist eine Erweiterung für Spark, mit der Sie den gleichen Code wie für die Batchverarbeitung verwenden können. Batchabfragen und interaktive Abfragen können in einer einzelnen Anwendung kombiniert werden. Im Gegensatz zu Spark bietet Streaming eine zustandsbehaftete Semantik zur genau einmaligen Verarbeitung. In Kombination mit der Kafka Direct-API, die sicherstellt, dass alle Kafka-Daten genau einmal von Spark Streaming empfangen werden, können End-to-End-Garantien vom Typ „Genau einmal“ erreicht werden. Zu den Stärken von Spark Streaming zählen seine fehlertoleranten Funktionen und die damit verbundene schnelle Wiederherstellung fehlerhafter Knoten bei Verwendung mehrerer Knoten im Cluster.
Weitere Informationen finden Sie in der Übersicht über Apache Spark-Streaming.
Skalieren eines Clusters
Die Anzahl von Knoten im Cluster kann zwar bei der Erstellung angegeben werden, manchmal muss der Cluster jedoch abhängig von der Workload vergrößert oder verkleinert werden. Bei allen HDInsight-Clustern können Sie die Anzahl von Knoten im Cluster ändern. Spark-Cluster können ohne Datenverlust verworfen werden, da alle Daten in Azure Storage oder Data Lake Storage gespeichert werden.
Die Entkopplung von Technologien hat gewisse Vorteile. Bei Kafka handelt es sich beispielsweise um eine Technologie zum Puffern von Ereignissen. Sie ist sehr E/A-lastig und benötigt nur wenig Rechenleistung. Datenstromverarbeitungslösungen wie Spark Streaming sind hingegen rechenintensive Lösungen, die virtuelle Computer mit mehr Leistung benötigen. Dank der Entkopplung dieser Technologien mittels unterschiedlicher Cluster können Sie sie unabhängig voneinander skalieren und die virtuellen Computer optimal nutzen.
Skalieren der Ebene für die Streampufferung
Die Streampufferungstechnologien Event Hubs und Kafka verwenden jeweils Partitionen, die von Consumern ausgelesen werden. Zum Skalieren des Eingabedurchsatzes muss die Anzahl von Partitionen erhöht werden, wodurch sich wiederum die Parallelität erhöht. In Event Hubs kann die Anzahl von Partitionen nach der Bereitstellung nicht mehr geändert werden. Daher ist es wichtig, sich schon zu Beginn Gedanken über die Zielgröße zu machen. Bei Kafka können Sie Partitionen hinzufügen – und das sogar während Kafka Daten verarbeitet. Kafka verfügt über ein Tool zum Neuzuweisen von Partitionen: kafka-reassign-partitions.sh. HDInsight verfügt über ein Tool zum Ausgleichen von Partitionsreplikaten: rebalance_rackaware.py. Dieses Ausgleichstool ruft das Tool kafka-reassign-partitions.sh so auf, dass sich jedes Replikat in einer separaten Fehler- und Updatedomäne befindet. Kafka wird dadurch rackfähig und fehlertoleranter.
Skalieren der Ebene für die Streamverarbeitung
Apache Spark Streaming unterstützt das Hinzufügen von Workerknoten zu den Clustern – und das sogar während der Datenverarbeitung.
Apache Spark verwendet für die Konfiguration der Umgebung je nach Anwendungsanforderungen drei zentrale Parameter: spark.executor.instances, spark.executor.cores und spark.executor.memory. Ein Executor ist ein Prozess, der für eine Spark-Anwendung gestartet wird. Er wird auf dem Workerknoten ausgeführt und ist für die Ausführung der Anwendungsaufgaben zuständig. Die Standardanzahl von Executors und die Executorgrößen für jeden Cluster werden basierend auf der Anzahl von Workerknoten und der Größe der Workerknoten berechnet. Diese Werte werden auf den einzelnen Clusterhauptknoten in der Datei spark-defaults.conf gespeichert.
Die drei Parameter können auf der Clusterebene (für alle Anwendungen, die im Cluster ausgeführt werden) konfiguriert oder für jede einzelne Anwendung angegeben werden. Weitere Informationen finden Sie unter Verwalten von Ressourcen für den Apache Spark-Cluster unter Azure HDInsight.