Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie eine Verbindung zwischen einem Apache Spark-Cluster in Azure HDInsight und Azure SQL-Datenbank herstellen. Daten in der SQL-Datenbank lesen, schreiben und streamen. In diesem Artikel wird ein Jupyter Notebook zum Ausführen der Scala-Codeausschnitte verwendet. Sie können allerdings auch eine eigenständige Anwendung in Scala oder Python erstellen und die gleichen Aufgaben ausführen.
Voraussetzungen
Azure HDInsight Spark-Cluster. Befolgen Sie dazu die Anweisungen unter Erstellen eines Apache Spark-Clusters in HDInsight.
Azure SQL-Datenbank. Befolgen Sie dazu die Anweisungen unter Erstellen einer Datenbank in Azure SQL-Datenbank. Stellen Sie sicher, dass Sie eine Datenbank mit dem AdventureWorksLT-Beispielschema und den zugehörigen Daten erstellen. Stellen Sie außerdem sicher, dass Sie eine Firewallregel auf Serverebene erstellen, sodass die IP-Adresse des Clients auf die SQL-Datenbank zugreifen kann. Die Anweisungen zum Hinzufügen der Firewallregel sind im gleichen Artikel enthalten. Halten Sie nach dem Erstellen der SQL-Datenbank die folgenden Werte bereit. Sie benötigen sie, um über einen Spark-Cluster eine Verbindung mit der Datenbank herzustellen.
- Servername.
- Datenbankname.
- Benutzername/Kennwort des Azure SQL-Datenbankadministrators.
SQL Server Management Studio (SSMS). Befolgen Sie dazu die Anweisungen unter Verwenden von SQL Server Management Studio zum Herstellen der Verbindung und Abfragen von Daten.
Erstellen eines Jupyter Notebooks
Erstellen Sie zunächst ein dem Spark-Cluster zugeordnetes Jupyter Notebook. Sie verwenden dieses Notebook, um die in diesem Artikel verwendeten Codeausschnitte auszuführen.
- Öffnen Sie Ihren Cluster im Azure-Portal.
- Wählen Sie auf der rechten Seite unterhalb von Clusterdashboards die Option Jupyter Notebook aus. Sollte Clusterdashboards nicht angezeigt werden, wählen Sie im linken Menü die Option Übersicht aus. Geben Sie die Administratoranmeldeinformationen für den Cluster ein, wenn Sie dazu aufgefordert werden.

Hinweis
Sie können das Jupyter Notebook im Spark-Cluster auch aufrufen, indem Sie im Browser die folgende URL öffnen. Ersetzen Sie CLUSTERNAME durch den Namen Ihres Clusters:
https://CLUSTERNAME.azurehdinsight.net/jupyter
- Klicken Sie im Jupyter Notebook oben rechts auf New (Neu) und dann auf Spark, um ein Scala-Notebook zu erstellen. Jupyter Notebooks in einem HDInsight Spark-Cluster umfassen zudem den PySpark-Kernel für Python2-Anwendungen und den PySpark3-Kernel für Python3-Anwendungen. In diesem Artikel wird ein Scala-Notebook erstellt.
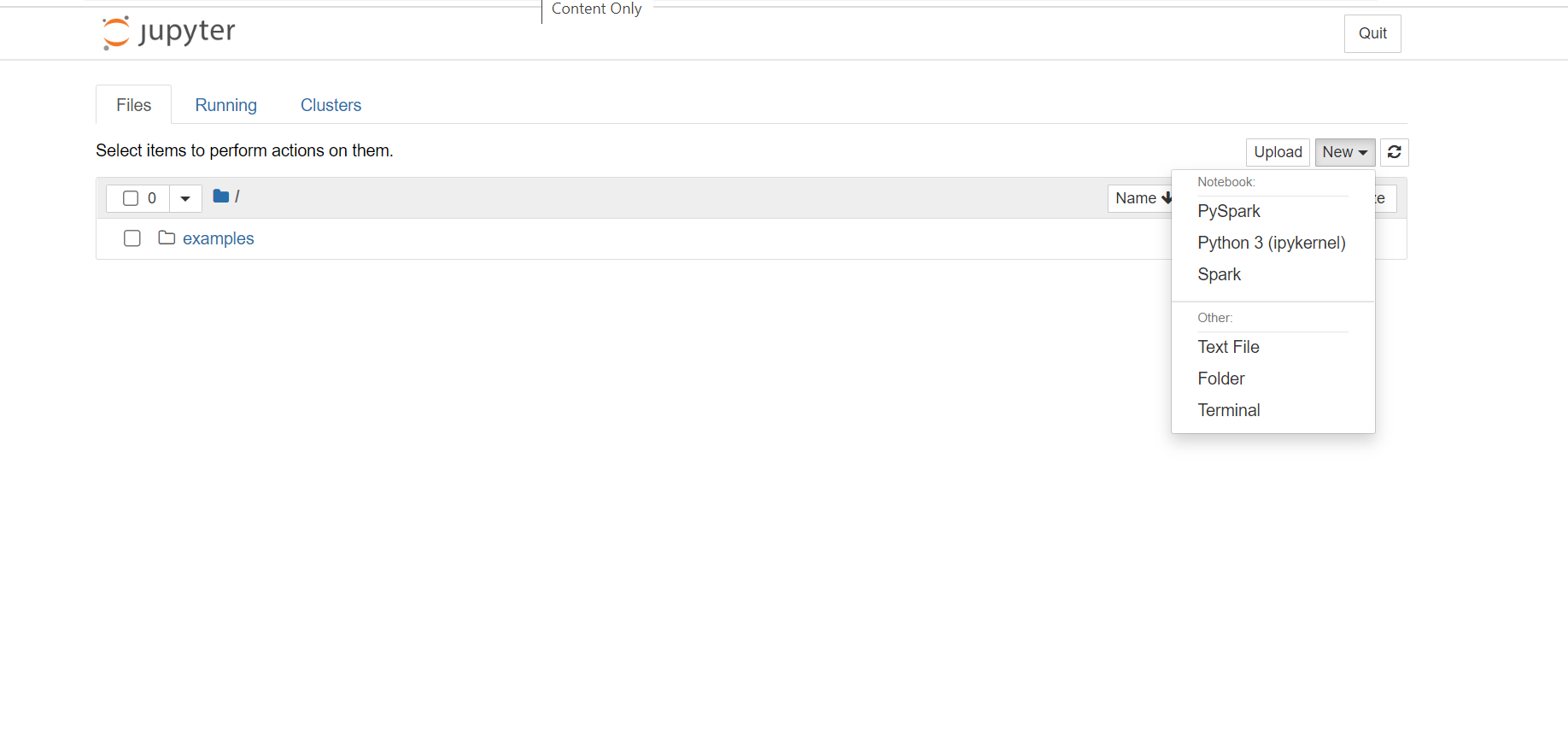
Weitere Informationen zu den Kernels finden Sie unter Verfügbare Kernels für Jupyter Notebooks mit Apache Spark-Clustern unter HDInsight (Linux).
Hinweis
In diesem Artikel wird ein Spark-Kernel (Scala) verwendet, da das Streamen von Daten von Spark in SQL-Datenbank derzeit nur in Scala und Java unterstützt wird. Das Lesen und Schreiben von Daten in SQL kann zwar auch über Python erfolgen. Aus Gründen der Einheitlichkeit wird in diesem Artikel jedoch Scala für alle drei Vorgänge verwendet.
Ein neues Notebook mit dem Standardnamen Unbenannt wird geöffnet. Klicken Sie auf den Namen des Notebooks, und geben Sie den gewünschten Namen ein.
Nun können Sie die Anwendung erstellen.
Lesen von Daten aus der Azure SQL-Datenbank
In diesem Abschnitt lesen Sie Daten aus einer Tabelle (z.B. SalesLT.Address) in der AdventureWorks-Datenbank.
Fügen Sie den folgenden Codeausschnitt in einem neuen Jupyter Notebook in einer Codezelle ein, und ersetzen Sie die Platzhalterwerte durch die Werte für Ihre Datenbank.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Drücken Sie UMSCHALT+EINGABE, um die Codezelle auszuführen.
Mit dem folgenden Codeausschnitt wird eine JDBC-URL erstellt, die Sie an die Spark-Dataframe-APIs übergeben können. Der Code erstellt ein
Properties-Objekt, um die Parameter zu speichern. Fügen Sie den Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE, um sie auszuführen.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Verwenden Sie den folgenden Codeausschnitt, um einen Dataframe mit den Daten aus einer Tabelle in der Datenbank zu erstellen. In diesem Codeausschnitt wird die Tabelle
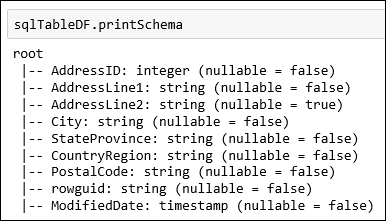
SalesLT.Addressverwendet, die als Bestandteil der AdventureWorksLT-Datenbank verfügbar ist. Fügen Sie den Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE, um sie auszuführen.val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)Sie können nun Vorgänge für den Dataframe ausführen, z. B. Abrufen des Datenschemas:
sqlTableDF.printSchemaEine Ausgabe ähnlich der folgenden Abbildung wird angezeigt:
Sie können beispielsweise auch die ersten 10 Zeilen abrufen.
sqlTableDF.show(10)Oder Sie können bestimmte Spalten aus dem Dataset abrufen.
sqlTableDF.select("AddressLine1", "City").show(10)
Schreiben von Daten in die Azure SQL-Datenbank
In diesem Abschnitt wird über eine im Cluster verfügbare CSV-Datei eine Tabelle in Ihrer Datenbank erstellt und diese dann mit Daten aufgefüllt. Die CSV-Beispieldatei (HVAC.csv) steht für alle HDInsight-Cluster unter HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv zur Verfügung.
Fügen Sie den folgenden Codeausschnitt in einem neuen Jupyter Notebook in einer Codezelle ein, und ersetzen Sie die Platzhalterwerte durch die Werte für Ihre Datenbank.
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"Drücken Sie UMSCHALT+EINGABE, um die Codezelle auszuführen.
Mit dem folgenden Codeausschnitt wird eine JDBC-URL erstellt, die Sie an die Spark-Dataframe-APIs übergeben können. Der Code erstellt ein
Properties-Objekt, um die Parameter zu speichern. Fügen Sie den Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE, um sie auszuführen.import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")Verwenden Sie den folgenden Codeausschnitt, um das Schema der Daten in der Datei „HVAC.csv“ zu extrahieren und das Schema zum Laden der Daten aus der CSV-Datei in den Dataframe
readDfzu verwenden. Fügen Sie den Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE, um sie auszuführen.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")Verwenden Sie den Dataframe
readDfzum Erstellen der temporären Tabelletemphvactable. Verwenden Sie die temporäre Tabelle dann zum Erstellen der Hive-Tabellehvactable_hive.readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")Verwenden Sie schließlich die Hive-Tabelle zum Erstellen einer Tabelle Ihrer Datenbank. Mit dem folgenden Codeausschnitt wird
hvactablein der Azure SQL-Datenbank erstellt.spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)Stellen Sie über SSMS eine Verbindung mit der Azure SQL-Datenbank her, und überprüfen Sie, ob darin
dbo.hvactableangezeigt wird.a. Starten Sie SSMS, und stellen Sie unter Angabe der entsprechenden Verbindungsdetails (siehe dazu Screenshot unten) eine Verbindung mit der Azure SQL-Datenbank her.
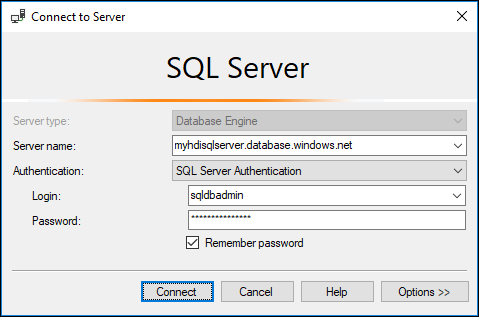
b. Erweitern Sie im Objekt-Explorer die Datenbank und den Knoten „Tables“, um die erstellte Tabelle dbo.hvactable anzuzeigen.
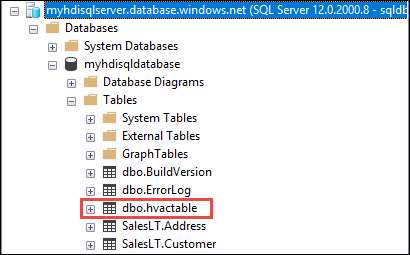
Führen Sie eine Abfrage in SSMS aus, um die Spalten in der Tabelle zu sehen.
SELECT * from hvactable
Streamen von Daten in die Azure SQL-Datenbank
In diesem Abschnitt werden Daten in die Tabelle hvactable gestreamt, die Sie im vorherigen Abschnitt erstellt haben.
Stellen Sie in einem ersten Schritt sicher, dass in
hvactablekeine Datensätze vorhanden sind. Führen Sie unter Verwendung von SSMS die folgende Abfrage für die Tabelle aus.TRUNCATE TABLE [dbo].[hvactable]Erstellen Sie ein neues Jupyter Notebook im HDInsight Spark-Cluster. Fügen Sie den folgenden Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE:
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}Die Daten aus der Datei HVAC.csv werden in die Tabelle
hvactablegestreamt. Die Datei „HVAC.csv“ ist auf dem Cluster unter/HdiSamples/HdiSamples/SensorSampleData/HVAC/verfügbar. Mit dem folgenden Codeausschnitt wird zunächst das Schema der zu streamenden Daten abgerufen. Anschließend wird unter Verwendung dieses Schemas ein Streaming-Dataframe erstellt. Fügen Sie den Codeausschnitt in einer Codezelle ein, und drücken Sie UMSCHALT+EINGABE, um sie auszuführen.val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchemaIn der Ausgabe wird das Schema von HVAC.csv angezeigt. Die Tabelle
hvactableweist dasselbe Schema auf. In der Ausgabe werden die Spalten in der Tabelle angezeigt.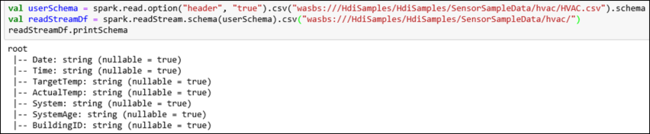
Verwenden Sie schließlich den folgenden Codeausschnitt, um Daten aus der Datei „HVAC.csv“ zu lesen und in die Tabelle
hvactablein Ihrer Datenbank zu streamen. Fügen Sie den Codeausschnitt in eine Codezelle ein, ersetzen Sie die Platzhalterwerte durch die Werte für Ihre Datenbank, und drücken Sie dann UMSCHALT+EINGABE, um die Codezelle auszuführen.val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.windows.net val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()Überprüfen Sie, ob die Daten in die Tabelle
hvactablegestreamt werden, indem Sie die folgende Abfrage in SQL Server Management Studio (SSMS) ausführen. Bei jedem Ausführen der Abfrage wird die zunehmende Anzahl der Zeilen in der Tabelle angezeigt.SELECT COUNT(*) FROM hvactable