Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Nachdem Sie Machine Learning-Modelle oder Pipelines trainiert oder geeignete Modelle aus dem Modellkatalog gefunden haben, müssen Sie sie für andere in der Produktion bereitstellen, um sie zur Ableitung zu verwenden. Inference ist der Prozess der Anwendung neuer Eingabedaten auf ein Machine Learning-Modell oder eine Pipeline zum Generieren von Ausgaben. Obwohl diese Ergebnisse normalerweise als „Vorhersagen“ bezeichnet werden, können sie auch für andere Aufgaben des maschinellen Lernens wie Klassifizierung und Clustering erzeugt werden. In Azure Machine Learning führen Sie eine Ableitung mithilfe von endpoints aus.
Endpunkte und Bereitstellungen
Ein Endpunkt ist eine stabile und dauerhafte URL, die zum Anfordern oder Aufrufen eines Modells verwendet werden kann. Sie stellen die erforderlichen Eingaben für den Endpunkt bereit und empfangen die Ausgaben. Azure Machine Learning unterstützt Standard-Deployments, Online-Endpoints und Batch-Endpoints. Ein Endpunkt bietet Folgendes:
- Eine stabile und dauerhafte URL (z. B. endpoint-name.region.inference.ml.azure.com)
- Authentifizierungsmechanismus
- Ein Autorisierungsmechanismus
Eine Bereitstellung ist eine Reihe von Ressourcen und Berechnungen, die erforderlich sind, um das Modell oder die Komponente zu hosten, die die tatsächliche Schlussfolgerung durchführt. Ein Endpunkt enthält eine Bereitstellung. Für Online- und Batchendpoints kann ein Endpoint mehrere Deployments enthalten. Die Bereitstellungen können unabhängige Anlagen hosten und unterschiedliche Ressourcen basierend auf den Anforderungen der Anlagen nutzen. Ein Endpunkt verfügt auch über einen Routingmechanismus, der Anforderungen an jede seiner Bereitstellungen weiterleiten kann.
Einige Arten von Endpunkten in Azure Machine Learning dedizierte Ressourcen für ihre Bereitstellungen nutzen. Damit diese Endpunkte ausgeführt werden können, müssen Sie ein Computekontingent für Ihr Azure-Abonnement haben. Bestimmte Modelle unterstützen jedoch eine serverlose Bereitstellung, sodass sie kein Kontingent aus Ihrem Abonnement nutzen können. Für serverlose Bereitstellungen werden Sie basierend auf der Nutzung in Rechnung gestellt.
Intuition
Angenommen, Sie arbeiten an einer Anwendung, die den Typ und die Farbe eines Autos aus einem Foto vorhersagt. Für diese Anwendung stellt ein Benutzer mit bestimmten Anmeldeinformationen eine HTTP-Anforderung an eine URL und stellt ein Bild eines Autos als Teil der Anforderung bereit. Im Gegenzug erhält der Benutzer eine Antwort, die den Typ und die Farbe des Autos als Zeichenfolgenwerte enthält. In diesem Szenario dient die URL als Endpunkt.
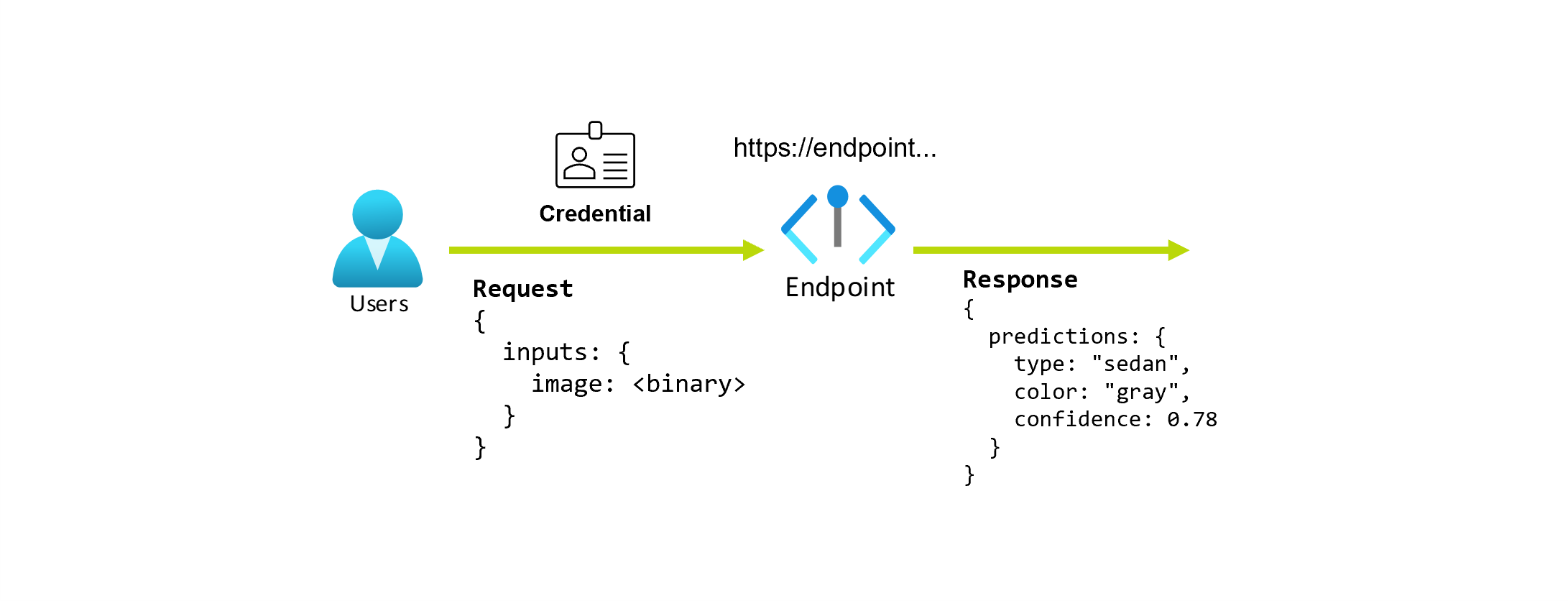
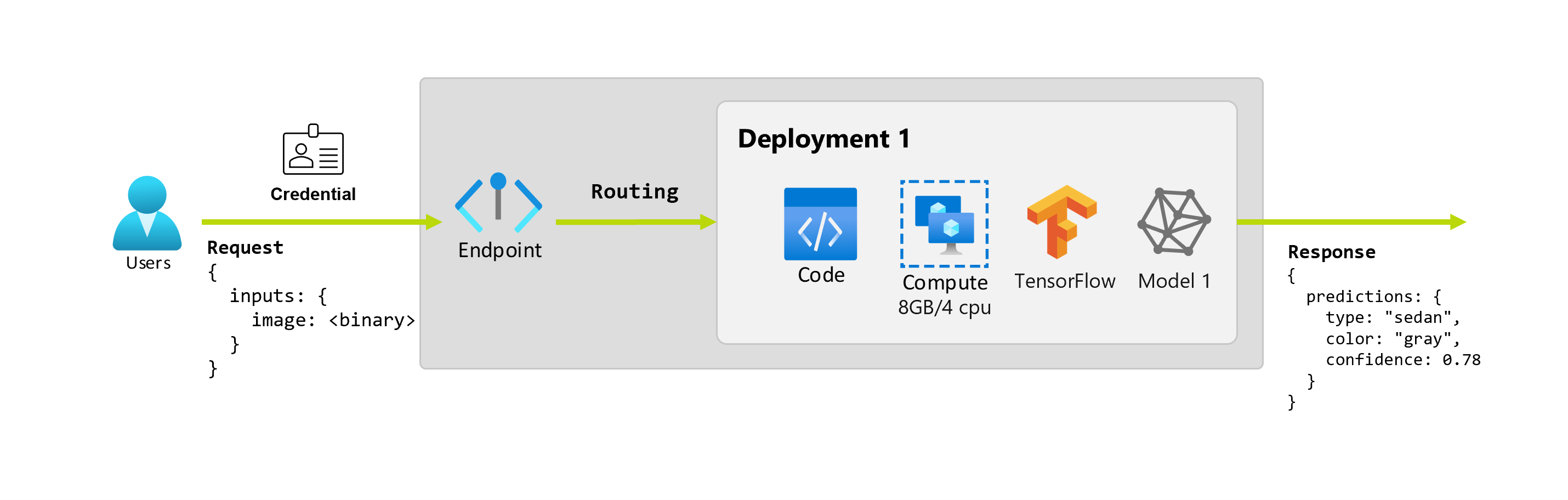
Angenommen, ein Datenwissenschaftler, Alice, implementiert die Anwendung. Alice verfügt über umfangreiche TensorFlow-Erfahrung und entscheidet, das Modell mit einem sequenziellen Keras-Klassifizierer mit einer ResNet-Architektur vom TensorFlow Hub zu implementieren. Nach dem Testen des Modells ist Alice mit seinen Ergebnissen zufrieden und entscheidet, das Modell zur Lösung des Autovorhersageproblems zu verwenden. Das Modell ist groß und benötigt 8 GB Arbeitsspeicher sowie 4 Kerne zum Ausführen. In diesem Szenario bilden das Modell von Alice und die Ressourcen, wie zum Beispiel der Code und die Rechenleistung, die zum Ausführen des Modells erforderlich sind, eine Bereitstellung unter dem Endpunkt.
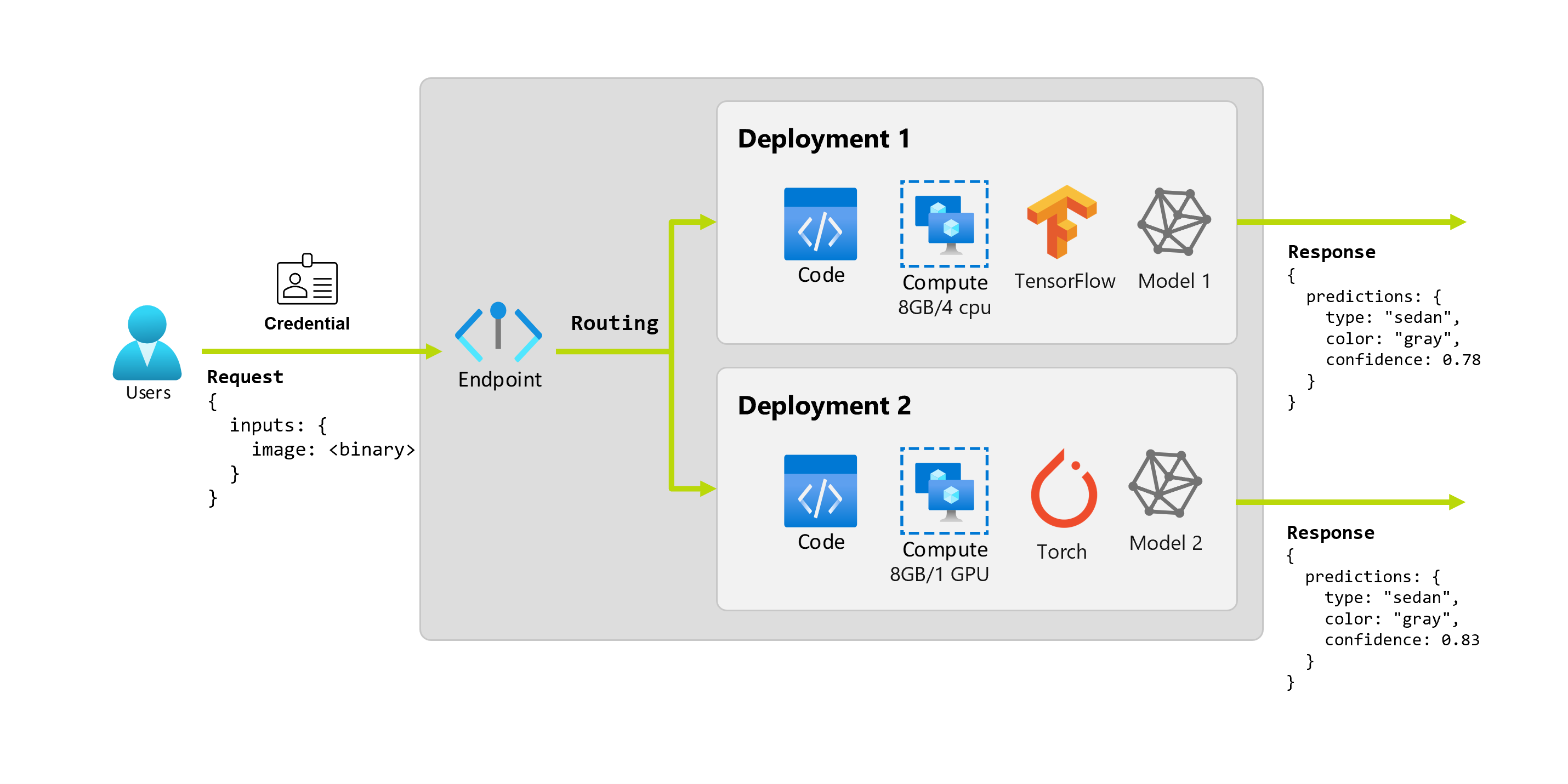
Nach einigen Monaten ermittelt die Organisation, dass die Anwendung bei Bildern mit schlechten Beleuchtungsbedingungen schlecht funktioniert. Bob, ein anderer Data-Wissenschaftler, verfügt über Expertise in Datenerweiterungstechniken, mit denen Modelle die Stabilität für diesen Faktor aufbauen können. Bob bevorzugt jedoch die Verwendung von PyTorch, um das Modell zu implementieren und ein neues Modell mit PyTorch zu trainieren. Bob möchte dieses Modell schrittweise in der Produktion testen, bis die Organisation bereit ist, das alte Modell zurückzuziehen. Das neue Modell erbringt auch bessere Leistungen, wenn es auf einer GPU bereitgestellt wird, daher muss die Bereitstellung eine GPU umfassen. In diesem Szenario bilden Bobs Modell und die Ressourcen , z. B. den Code und die Berechnung, die zum Ausführen des Modells erforderlich sind, eine weitere Bereitstellung unter demselben Endpunkt.
Endpunkte: Standardbereitstellung, Online und Batch
Azure Machine Learning unterstützt standardbereitstellungen, online-Endpunkte und batch-Endpunkte.
Standardbereitstellungen und Onlineendpunkte sind für die Echtzeit-Ableitung konzipiert. Wenn Sie den Endpunkt aufrufen, werden die Ergebnisse in der Antwort des Endpunkts zurückgegeben. Standard-Deployments verbrauchen kein Kontingent aus Ihrem Abonnement; stattdessen erfolgt die Abrechnung über die Standardabrechnung.
Batchendpunkte sind für eine langfristige Batch-Ableitung konzipiert. Wenn Sie einen Batchendpunkt aufrufen, generieren Sie einen Batchauftrag, der die eigentliche Arbeit ausführt.
Wann Sie Standardbereitstellungs-, Online- und Batch-Endpunkte verwenden sollten
Standardbereitstellung:
Verwenden Sie Standardbereitstellungen, um große Grundlagenmodelle für Echtzeit-Inferencing von der Stange oder zur Feinabstimmung solcher Modelle zu verwenden. Nicht alle Modelle sind für die Bereitstellung in Standardumgebungen verfügbar. Es wird empfohlen, diesen Bereitstellungsmodus zu verwenden, wenn:
- Ihr Modell ist ein grundlegendes Modell oder eine fein abgestimmte Version eines basisbasierten Modells, das für Standardbereitstellungen verfügbar ist.
- Sie können von einer kontingentlosen Bereitstellung profitieren.
- Sie müssen den Rückschlussstapel, der zum Ausführen des Modells verwendet wird, nicht anpassen.
Onlineendpunkte:
Verwenden Sie Onlineendpunkte , um Modelle für die Echtzeit-Ableitung in synchronen Anforderungen mit geringer Latenz zu operationalisieren. Es wird empfohlen, sie in folgenden Fällen zu verwenden:
- Ihr Modell ist ein grundlegendes Modell oder eine fein abgestimmte Version eines Basismodells, wird aber in der Standardbereitstellung nicht unterstützt.
- Sie haben niedrige Latenzanforderungen.
- Ihr Modell kann die Anforderung in relativ kurzer Zeit beantworten.
- Die Eingaben Ihres Modells passen in die HTTP-Nutzlast der Anforderung.
- Sie müssen die Anzahl der Anforderungen hochskalieren.
Batchendpunkte:
Verwenden Sie Batch-Endpunkte, um Modelle oder Pipelines für langlaufende asynchrone Inferenz zu operationalisieren. Es wird empfohlen, sie in folgenden Fällen zu verwenden:
- Sie verfügen über teure Modelle oder Pipelines, die eine längere Laufzeit erfordern.
- Sie möchten Machine Learning-Pipelines operationalisieren und Komponenten wiederverwenden.
- Sie müssen eine Ableitung über große Datenmengen durchführen, die in mehreren Dateien verteilt werden.
- Sie haben keine Anforderungen an niedrige Latenzzeiten.
- Die Eingaben Ihres Modells werden in einem Speicherkonto oder in einer Azure Machine Learning Datenressource gespeichert.
- Sie können die Parallelisierung nutzen.
Vergleich von Standard-Bereitstellungs-, Online- und Batch-Endpunkten
Alle Standardbereitstellungen, Online-Endpunkte und Batch-Endpunkte basieren auf dem Konzept der Endpunkte, so dass Sie problemlos von einem zum anderen übergehen können. Online- und Batch-Endpunkte können auch mehrere Deployments für denselben Endpunkt verwalten.
Endpunkte
Die folgende Tabelle enthält eine Zusammenfassung der verschiedenen Features, die für Standard-Deployments, Online-Endpunkte und Batch-Endpunkte auf Endpunktebene verfügbar sind.
| Funktion | Standardbereitstellungen | Onlineendpunkte | Batchendpunkte |
|---|---|---|---|
| Stabile Aufruf-URL | Ja | Ja | Ja |
| Unterstützung für mehrere Bereitstellungen | Nein | Ja | Ja |
| Routing der Bereitstellung | Nichts | Datenverkehrsaufteilung | Wechseln zur Standardeinstellung |
| Spiegeln des Datenverkehrs für einen sicheren Rollout | Nein | Ja | Nein |
| Swagger-Unterstützung | Ja | Ja | Nein |
| Authentifizierung | Schlüssel | Schlüssel und Microsoft Entra ID (Vorschau) | Microsoft Entra ID |
| Unterstützung für private Netzwerke (veraltet) | Nein | Ja | Ja |
| Verwaltete Netzwerkisolation | Ja | Ja | Ja (siehe erforderliche zusätzliche Konfiguration) |
| Vom Kunden verwaltete Schlüssel | NA | Ja | Ja |
| Kostenbasis | Pro Endpunkt, pro Minute1 | Nichts | Nichts |
1Ein kleiner Bruchteil wird für die Standardbereitstellung pro Minute berechnet. Im Abschnitt "Bereitstellungen " finden Sie die Gebühren für den Verbrauch, die pro Token in Rechnung gestellt werden.
Bereitstellungen
In der folgenden Tabelle finden Sie eine Zusammenfassung der verschiedenen Funktionen, die für Standardbereitstellungen, Online-Endpunkte und Batch-Endpunkte auf der Bereitstellungsebene zur Verfügung stehen. Diese Konzepte gelten für jede Bereitstellung unter dem Endpunkt (für Online- und Batchendpunkte) und gelten für Standardbereitstellungen (bei denen das Bereitstellungskonzept in den Endpunkt integriert ist).
| Funktion | Standardbereitstellungen | Onlineendpunkte | Batchendpunkte |
|---|---|---|---|
| Bereitstellungstypen | Modelle | Modelle | Modelle und Pipelinekomponenten |
| MLflow-Modellbereitstellung | Nein, nur bestimmte Modelle im Katalog | Ja | Ja |
| Bereitstellung benutzerdefinierter Modelle | Nein, nur bestimmte Modelle im Katalog | Ja, mit Bewertungsskript | Ja, mit Bewertungsskript |
| Ableitungsserver 2 | Azure KI-Modell-Ableitungs-API | - Azure Machine Learning Inferencing Server -Triton - Benutzerdefiniert (mit BYOC) |
Batch-Ableitung |
| Rechenressource verbraucht | Keine (serverlos) | Instanzen oder granulare Ressourcen | Clusterinstanzen |
| Computetyp | Keine (serverlos) | Verwaltete Rechenressourcen und Kubernetes | Verwaltete Rechenressourcen und Kubernetes |
| Compute mit niedriger Priorität | NA | Nein | Ja |
| Rechenressourcen auf Null skalieren | Eingebaut | Nein | Ja |
| Compute mit automatischer Skalierung3 | Eingebaut | Ja, basierend auf der Ressourcenverwendung | Ja, basierend auf der Auftragsanzahl |
| Überkapazitätsmanagement | Drosselung | Drosselung | Queuing |
| Kostenbasis4 | Pro Token-Einheit | Pro Bereitstellung: Recheninstanzen, die ausgeführt werden | Pro Auftrag: Berechnungsinstanzen, die im Auftrag verbraucht werden (begrenzt auf die maximale Anzahl von Instanzen des Clusters) |
| Lokale Tests von Bereitstellungen | Nein | Ja | Nein |
2Inference-Server bezieht sich auf die Diensttechnologie, die Anforderungen akzeptiert, verarbeitet und Antworten erstellt. Der Ableitungsserver bestimmt auch das Format der Eingabe und der erwarteten Ausgaben.
3Die automatische Skalierung ist die Möglichkeit, die zugeordneten Ressourcen der Bereitstellung basierend auf ihrer Last dynamisch zu skalieren oder zu verkleineren. Online- und Batchbereitstellungen verwenden unterschiedliche Strategien für die automatische Skalierung. Während Online-Bereitstellungen basierend auf der Ressourcenauslastung (z. B. CPU, Arbeitsspeicher, Abfragen usw.) nach oben oder unten skalieren, skalieren Batch-Endpunkte basierend auf der Anzahl der erstellten Aufträge.
4 Sowohl Online- als auch Batch-Bereitstellungen werden nach den verbrauchten Ressourcen abgerechnet. Bei Onlinebereitstellungen werden Ressourcen zum Zeitpunkt der Bereitstellung bereitgestellt. In Batchbereitstellungen werden Ressourcen nicht zur Bereitstellungszeit verbraucht, sondern zum Zeitpunkt der Ausführung des Auftrags. Daher gibt es keine mit der Batchbereitstellung verbundenen Kosten. Ebenso verbrauchen in die Warteschlange eingereihte Aufträge auch keine Ressourcen.
Entwicklerschnittstellen
Endpunkte sollen Organisationen dabei helfen, Workloads auf Produktionsebene in Azure Machine Learning zu operationalisieren. Endpunkte sind robuste und skalierbare Ressourcen und bieten die besten Funktionen zum Implementieren von MLOps-Workflows.
Sie können Batch- und Onlineendpunkte mit mehreren Entwicklertools erstellen und verwalten:
- Azure CLI und Python SDK
- Azure Resource Manager/REST-API
- Azure Machine Learning Studio Webportal
- Azure Portal (IT/Administrator)
- Unterstützung für CI/CD MLOps-Pipelines mit der Azure CLI Schnittstelle & REST/ARM-Schnittstellen