Bereitstellung von Onlineendpunkten für Rückschlüsse in Echtzeit
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In diesem Artikel erfahren Sie mehr über Onlineendpunkte für Echtzeitrückschlüsse in Azure Machine Learning. Rückschluss ist der Prozess, bei dem neue Eingabedaten auf ein Machine Learning-Modell angewandt werden, um Ausgaben zu generieren. Azure Machine Learning ermöglicht Ihnen die Durchführung von Echtzeitrückschlüssen für Daten mithilfe von Modellen, die auf Onlineendpunkten bereitgestellt werden. Obwohl diese Ausgaben in der Regel als Vorhersagen bezeichnet werden, können Sie Rückschlüsse verwenden, um Ausgaben für andere Aufgaben zum maschinellen Lernen wie Klassifizierung und Clustering zu generieren.
Onlineendpunkte
Onlineendpunkte stellen Modelle auf einem Webserver bereit, der über das HTTP-Protokoll Vorhersagen zurückgeben kann. Onlineendpunkte können Modelle für Echtzeitrückschlüsse in synchronen, latenzarmen Anforderungen operationalisieren und kommen am besten in folgenden Fällen zum Einsatz:
- Sie haben Anforderungen mit geringer Latenz.
- Ihr Modell kann die Anforderung in relativ kurzer Zeit beantworten.
- Die Eingaben Ihres Modells passen zur HTTP-Nutzdatenlast der Anforderung.
- Sie müssen die Anzahl der Anforderungen hochskalieren.
Um einen Endpunkt zu definieren, müssen Sie Folgendes angeben:
- Endpunktname: Dieser Name muss in der Azure-Region eindeutig sein. Weitere Benennungsanforderungen finden Sie unter Azure Machine Learning-Onlineendpunkte und Batchendpunkte.
- Authentifizierungsmodus: Sie können für den Endpunkt zwischen dem schlüsselbasierten Authentifizierungsmodus, dem auf einem Azure Machine Learning-Token basierenden Authentifizierungsmodus oder dem auf einem Microsoft Entra-Token basierenden Authentifizierungsmodus wählen. Weitere Informationen zur Authentifizierung finden Sie unter Authentifizieren von Clients bei einem Onlineendpunkt.
Verwaltete Onlineendpunkte
Verwaltete Onlineendpunkte stellen Ihre Machine Learning-Modelle auf bequeme Weise bereit, sodass sie sofort einsatzbereit sind, und stellen die empfohlene Möglichkeit dar, Azure Machine Learning-Onlineendpunkte zu verwenden. Verwaltete Onlineendpunkte arbeiten mit leistungsstarken CPU- und GPU-Computern in Azure auf skalierbare, vollständig verwaltete Weise.
Damit Sie sich nicht um die Einrichtung und Verwaltung der zugrunde liegenden Infrastruktur kümmern müssen, sorgen diese Endpunkte auch für die Bereitstellung, Skalierung, Sicherung und Überwachung Ihrer Modelle. Informationen zum Definieren verwalteter Onlineendpunkte finden Sie unter Definieren des Endpunkts.
Verwaltete Onlineendpunkte im Vergleich zu Azure Container Instances oder Azure Kubernetes Service (AKS) v1
Verwaltete Onlineendpunkte sind die empfohlene Option für die Verwendung von Onlineendpunkten in Azure Machine Learning. In der folgenden Tabelle werden die wichtigsten Attribute verwalteter Onlineendpunkte mit den Lösungen für Azure Container Instances und Azure Kubernetes Service (AKS) v1 verglichen.
| Attribute | Verwaltete Onlineendpunkte (v2) | Container Instances oder AKS (v1) |
|---|---|---|
| Netzwerksicherheit/-isolation | Einfache Eingangs-/Ausgangssteuerung mit schneller Umschaltung | Virtuelle Netzwerke werden nicht unterstützt oder erfordern komplexe manuelle Konfiguration |
| Verwalteter Dienst | • Vollständig verwaltete Computebereitstellung/-skalierung • Netzwerkkonfiguration zur Verhinderung von Datenexfiltration • Hostbetriebssystemupgrade, kontrollierter Rollout von direkten Updates |
• Skalierung eingeschränkt • Der Benutzer muss die Netzwerkkonfiguration oder das Upgrade verwalten. |
| Endpunkte/Bereitstellung: Konzept | Trennung zwischen Endpunkt und Bereitstellung für komplexe Szenarien wie den sicheren Rollout von Modellen | Kein Endpunktkonzept |
| Diagnose und Überwachung | • Debuggen lokaler Endpunkte mit Docker und Visual Studio Code möglich • Erweiterte Metrik- und Protokollanalyse mit Diagramm/Abfrage zum Vergleich zwischen Bereitstellungen • Kostenaufschlüsselung bis zur Bereitstellungsebene |
Kein einfaches lokales Debuggen |
| Skalierbarkeit | Grenzenlose, elastische und automatische Skalierung | • Container Instances nicht skalierbar • AKS v1 unterstützt nur clusterinterne Skalierung und erfordert Skalierbarkeitskonfiguration. |
| Unternehmensfähigkeit | Private Verbindung, kundenseitig verwaltete Schlüssel, Microsoft Entra ID, Kontingentverwaltung, Abrechnungsintegration, SLA (Service Level Agreement, Vereinbarung zum Servicelevel) | Nicht unterstützt |
| Erweiterte ML-Features | • Modelldatensammlung • Modellüberwachung • Champion-Challenger-Modell, sicherer Rollout, Datenverkehrsspiegelung • Erweiterbar für verantwortungsvolle KI |
Nicht unterstützt |
Verwaltete Onlineendpunkte und Kubernetes-Onlineendpunkte
Wenn Sie lieber Kubernetes verwenden, um Ihre Modelle bereitzustellen und Endpunkte zu verwalten, und wenn Sie sich selbst um die Infrastrukturanforderungen kümmern können, können Sie auch Kubernetes-Onlineendpunkte verwenden. Auf diesen Endpunkten können Sie Modelle bereitstellen und Onlineendpunkte mit CPUs oder GPUs in Ihrem vollständig konfigurierten und verwalteten Kubernetes-Cluster verwenden.
Mit verwalteten Onlineendpunkte können Sie Ihren Bereitstellungsprozess optimieren und von folgenden Vorteilen profitieren, die Kubernetes-Onlineendpunkte nicht bieten:
Automatische Infrastrukturverwaltung
- Stellt die Computeressource bereit und hostet das Modell. Sie geben einfach den VM-Typ und die Skalierungseinstellungen an.
- Aktualisiert und patcht das zugrunde liegende Host-Betriebssystemimage.
- Führt die Knotenwiederherstellung bei einem Systemausfall aus.
Überwachung und Protokolle
- Möglichkeit zum Überwachen der Modellverfügbarkeit, Leistung und SLA über die native Integration in Azure Monitor.
- Einfaches Debuggen von Bereitstellungen, indem Sie Protokolle und die native Integration mit Log Analytics verwenden.
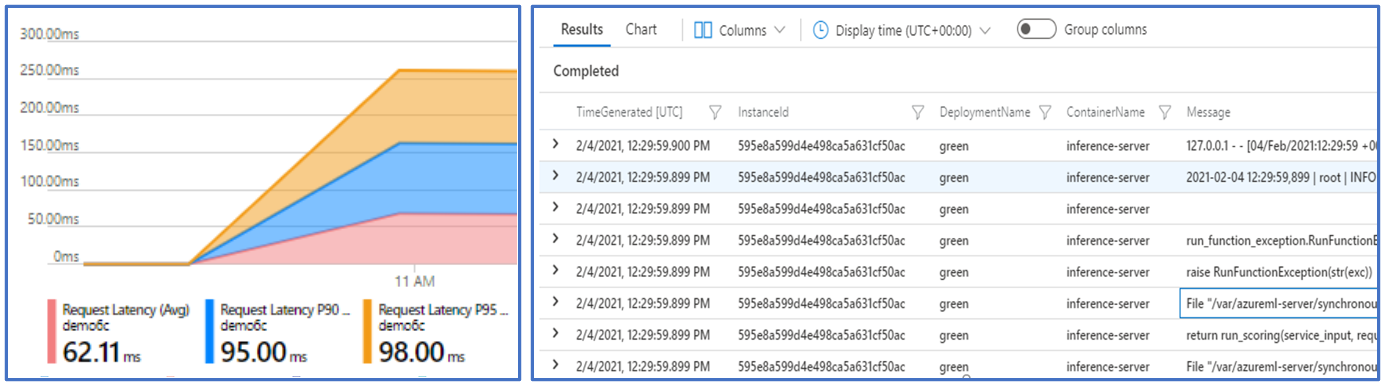
Über die Ansicht „Kostenanalyse“ können Sie Kosten auf Endpunkt- und Bereitstellungsebene überwachen.

Hinweis
Verwaltete Onlineendpunkte basieren auf Azure Machine Learning Compute. Wenn Sie einen verwalteten Onlineendpunkt verwenden, bezahlen Sie die Compute- und Netzwerkgebühren. Es fallen keine zusätzlichen Gebühren an. Weitere Informationen zu Preisen finden Sie unter Azure-Preisrechner.
Wenn Sie ein virtuelles Azure Machine Learning-Netzwerk verwenden, um ausgehenden Datenverkehr vom verwalteten Onlineendpunkt zu schützen, werden Ihnen die vom verwalteten virtuellen Netzwerk verwendeten Ausgangsregeln für Azure Private Link und vollqualifizierte Domänennamen (Fully Qualified Domain Names, FQDN) in Rechnung gestellt. Weitere Informationen finden Sie bei den Preisen für verwaltete virtuelle Netzwerke.


In der folgenden Tabelle werden die wichtigsten Unterschiede zwischen verwalteten Onlineendpunkten und Kubernetes-Onlineendpunkten hervorgehoben.
| Verwaltete Onlineendpunkte | Kubernetes-Onlineendpunkte (AKS v2) | |
|---|---|---|
| Empfohlene Benutzer | Benutzer, die eine Bereitstellung eines verwalteten Modells und eine verbesserte MLOps-Benutzeroberfläche benötigen | Benutzer, die Kubernetes bevorzugen und Infrastrukturanforderungen selbst verwalten können |
| Knotenbereitstellung | Verwaltete Computebereitstellung, -aktualisierung, -entfernung | Benutzerverantwortung |
| Knotenwartung | Verwaltete Updates für Host-Betriebssystemimages und Sicherheitshärtung | Benutzerverantwortung |
| Clusterdimensionierung (Skalierung) | Verwaltete manuelle und Autoskalierung, die die Bereitstellung zusätzlicher Knoten unterstützt | Manuelle und automatische Skalierung, die die Skalierung der Replikatanzahl innerhalb fester Clustergrenzen unterstützt |
| Computetyp | Vom Dienst verwaltet | Kundenseitig verwalteter Kubernetes-Cluster |
| Verwaltete Identität | Unterstützt | Unterstützt |
| Virtuelles Netzwerk | Unterstützt über verwaltete Netzwerkisolation | Benutzerverantwortung |
| Standardmäßige Überwachung und Protokollierung | Azure Monitor- und Log Analytics-Unterstützung, einschließlich Schlüsselmetriken und Protokolltabellen für Endpunkte und Bereitstellungen | Benutzerverantwortung |
| Protokollierung mit Application Insights (Legacy) | Unterstützt | Unterstützt |
| Kostenansicht | Detaillierte Informationen auf Endpunkt-/Bereitstellungsebene | Clusterebene |
| Kosten, die angewendet werden auf | Der Bereitstellung zugewiesene VMs | Dem Cluster zugewiesene VMs |
| Gespiegelter Datenverkehr | Unterstützt | Nicht unterstützt |
| Bereitstellung ohne Code | Unterstützt MLflow- und Triton-Modelle | Unterstützt MLflow- und Triton-Modelle |
Onlinebereitstellungen
Eine Bereitstellung umfasst Ressourcen und Computes, die für das Hosting des Modells erforderlich sind, das den Rückschluss durchführt. Ein einzelner Endpunkt kann mehrere Bereitstellungen mit unterschiedlichen Konfigurationen enthalten. Dieses Setup hilft beim Entkoppeln der Schnittstelle, die vom Endpunkt dargestellt wird, von den Implementierungsdetails der Bereitstellung. Ein Onlineendpunkt verfügt über einen Routingmechanismus, der Anforderungen an bestimmte Bereitstellungen am Endpunkt weiterleiten kann.
Das folgende Diagramm zeigt einen Onlineendpunkt mit zwei Bereitstellungen: blau und grün. Die blaue Bereitstellung verwendet VMs mit einer CPU-SKU und führt Version 1 eines Modells aus. Die grüne Bereitstellung verwendet VMs mit einer GPU-SKU und führt Version 2 des Modells aus. Der Endpunkt ist so konfiguriert, dass 90 % des eingehenden Datenverkehrs an die blaue Bereitstellung und die verbleibenden 10 % an die grüne Bereitstellung geleitet werden.
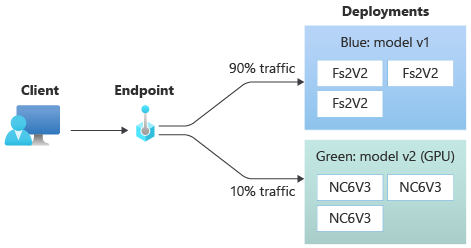
Um ein Modell bereitzustellen, müssen Sie über Folgendes verfügen:
Modelldateien oder Name und Version eines Modells, das bereits in Ihrem Arbeitsbereich registriert ist
Bewertungsskriptcode, der das Modell für eine bestimmte Eingabeanforderung ausführt
Das Bewertungsskript empfängt an einen bereitgestellten Webdienst übermittelte Daten und übergibt sie an das Modell. Anschließend führt das Skript das Modell aus und gibt dessen Antwort an den Client zurück. Das Bewertungsskript ist modellspezifisch und muss die Daten verstehen, die das Modell als Eingabe erwartet und als Ausgabe zurückgibt.
Eine Umgebung zum Ausführen Ihres Modells. Die Umgebung kann ein Docker-Image mit Conda-Abhängigkeiten oder ein Dockerfile sein.
Einstellungen zum Angeben des Instanztyps und der Skalierungskapazität.
Informationen zum Bereitstellen von Onlineendpunkten mithilfe der Azure CLI, des Python SDK, von Azure Machine Learning Studio oder einer ARM-Vorlage finden Sie unter Bereitstellen und Bewerten eines Machine Learning-Modells mithilfe eines Onlineendpunkts.
Wichtige Attribute einer Bereitstellung
In der folgenden Tabelle sind die Schlüsselattribute dieser Bereitstellung beschrieben:
| Attribut | Beschreibung |
|---|---|
| Name | Der Name der Bereitstellung |
| Endpunktname | Der Name des Endpunkts, unter dem die Bereitstellung erstellt werden soll. |
| Modell | Das für die Bereitstellung zu verwendende Modell. Dieser Wert kann entweder ein Verweis auf ein vorhandenes versioniertes Modell im Arbeitsbereich oder eine Inline-Modellspezifikation sein. Weitere Informationen zum Nachverfolgen und Angeben des Pfads zu Ihrem Modell finden Sie unter Angeben des bereitzustellenden Modells für die Verwendung im Onlineendpunkt. |
| Codepfad | Der Pfad zu dem Verzeichnis in der lokalen Entwicklungsumgebung, das den gesamten Python-Quellcode für die Bewertung des Modells enthält. Sie können geschachtelte Verzeichnisse und Pakete verwenden. |
| „Scoring script“ (Bewertungsskript) | Der Relativer Pfad zur Bewertungsdatei im Quellcodeverzeichnis. Dieser Python-Code muss über eine init()- und eine run()-Funktion verfügen. Die Funktion init() wird aufgerufen, nachdem das Modell erstellt oder aktualisiert wurde, etwa zum Zwischenspeichern des Modells im Arbeitsspeicher. Die Funktion run() wird bei jedem Aufruf des Endpunkts aufgerufen, um die tatsächliche Bewertung und Vorhersage auszuführen. |
| Environment | Die Umgebung zum Hosten des Modells und des Codes. Dieser Wert kann entweder ein Verweis auf eine vorhandene versionierte Umgebung im Arbeitsbereich oder eine Inline-Umgebungsspezifikation sein. |
| Instanztyp | Die VM-Größe, die für die Bereitstellung verwendet werden soll. Eine Liste der unterstützten Größen finden Sie unter SKU-Liste für verwaltete Onlineendpunkte. |
| Anzahl von Instanzen | Die Anzahl der Instanzen, die für die Bereitstellung verwendet werden sollen. Richten Sie den Wert nach der zu erwartenden Workload. Legen Sie den Wert mindestens auf 3 fest, um Hochverfügbarkeit zu erzielen. Das System reserviert zusätzliche 20 % für die Durchführung von Upgrades. Weitere Informationen finden Sie unter VM-Kontingentzuweisung für Bereitstellungen. |
Hinweise zu Onlinebereitstellungen
Die Bereitstellung kann jederzeit auf das Modell und das Containerimage verweisen, die in der Umgebung definiert sind, etwa, wenn die Bereitstellungsinstanzen Sicherheitspatches oder andere Wiederherstellungsvorgänge durchlaufen. Wenn Sie ein registriertes Modell oder Containerimage in Azure Container Registry für die Bereitstellung verwenden und das Modell oder das Containerimage später entfernen, können die Bereitstellungen, die sich auf diese Objekte stützen, bei einem Reimaging fehlschlagen. Wenn Sie das Modell oder das Containerimage entfernen, stellen Sie sicher, dass die abhängigen Bereitstellungen mit einem alternativen Modell oder Containerimage neu erstellt oder aktualisiert werden.
Die Containerregistrierung, auf die sich die Umgebung bezieht, kann nur dann privat sein, wenn die Endpunktidentität die Berechtigung hat, über Microsoft Entra-Authentifizierung und rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC) in Azure darauf zuzugreifen. Aus dem gleichen Grund werden andere private Docker-Registrierungen als Container Registry nicht unterstützt.
Microsoft patcht die Basisimages regelmäßig, um bekannte Sicherheitsrisiken zu beheben. Sie müssen Ihren Endpunkt erneut bereitstellen, um das gepatchte Image verwenden zu können. Wenn Sie die Images selbst bereitstellen, liegt die Aktualisierung in Ihrer Verantwortung. Weitere Informationen finden Sie unter Patchen von Images.
VM-Kontingentzuordnung für die Bereitstellung
Für verwaltete Onlineendpunkte reserviert Azure Machine Learning 20 % Ihrer Computeressourcen für die Durchführung von Upgrades auf einigen VM-SKUs. Wenn Sie eine bestimmte Anzahl von Instanzen für diese VM-SKUs in einer Bereitstellung anfordern, müssen Sie über ein Kontingent für ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU verfügen, um zu verhindern, dass Sie einen Fehler erhalten. Wenn Sie in einer Bereitstellung also beispielsweise zehn Instanzen einer VM vom Typ Standard_DS3_v2 (mit vier Kernen) anfordern, muss ein Kontingent für 48 Kerne (12 instances * 4 cores) verfügbar sein. Dieses zusätzliche Kontingent ist für systemseitig initiierte Vorgänge wie Betriebssystem-Upgrades und VM-Wiederherstellungen reserviert und verursacht nur dann Kosten, wenn ein solcher Vorgang ausgeführt wird.
Es gibt bestimmte VM-SKUs, die von der zusätzlichen Kontingentreservierung ausgenommen sind. Informationen zum Anzeigen der vollständigen Liste finden Sie unter SKU-Liste verwalteter Onlineendpunkte. Informationen zum Anzeigen Ihres Verbrauchs und zum Anfordern von Kontingenterhöhungen finden Sie unter Anzeigen Ihres Verbrauchs und Ihrer Kontingente im Azure-Portal. Informationen zum Anzeigen Ihrer Kosten für die Ausführung eines verwalteten Onlineendpunkts finden Sie unter Anzeigen der Kosten für einen verwalteten Azure Machine Learning-Onlineendpunkt.
Pool freigegebener Kontingente
Azure Machine Learning bietet einen Pool freigegebener Kontingente, aus dem Benutzer in verschiedenen Regionen auf ein Kontingent zugreifen können, um Tests für eine begrenzte Zeit durchzuführen (abhängig von der Verfügbarkeit). Wenn Sie das Studio verwenden, um Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- oder Deci-DeciLM-Modelle (aus dem Modellkatalog) auf einem verwalteten Onlineendpunkt bereitzustellen, ermöglicht Azure Machine Learning Ihnen für eine kurze Zeit den Zugriff auf diesen freigegebenen Kontingentpool, um Tests durchzuführen. Weitere Informationen zum freigegebenen Kontingentpool finden Sie unter Freigegebenes Azure Machine Learning-Kontingent.
Um Llama-2-, Phi-, Nemotron-, Mistral-, Dolly- und Deci-DeciLM-Modelle aus dem Modellkatalog über das freigegebene Kontingent bereitzustellen, müssen Sie über ein Enterprise Agreement-Abonnement verfügen. Weitere Informationen zur Verwendung des freigegebenen Kontingents für die Bereitstellung von Onlineendpunkten finden Sie unter Bereitstelle von Grundlagenmodellen mittels Studio.
Weitere Informationen zu Kontingenten und Grenzwerten für Ressourcen in Azure Machine Learning finden Sie unter Verwalten und Erhöhen von Kontingenten und Grenzwerten für Ressourcen mit Azure Machine Learning.
Bereitstellung für Personen mit und ohne Programmiererfahrung
Azure Machine Learning unterstützt die Modellimplementierung für Onlineendpunkte für Personen mit und ohne Programmiererfahrung mit Optionen für die No-Code-Bereitstellung, die Low-Code-Bereitstellung und die BYOC-Bereitstellung (Bring Your Own Container).
- Die No-Code-Bereitstellung bietet sofort einsatzbereite Funktionen für Rückschlüsse für gängige Frameworks wie scikit-learn, TensorFlow, PyTorch und ONNX (Open Neural Network Exchange) über MLflow und Triton.
- Die Low-Code-Bereitstellung ermöglicht es Ihnen, Ihr ML-Modell zusammen mit einem Mindestmaß an Code bereitzustellen.
- Mit der BYOC-Bereitstellung können Sie praktisch jeden beliebigen Container zum Ausführen Ihres Onlineendpunkts verwenden. Sie können alle Features der Azure Machine Learning-Plattform verwenden – z. B. automatische Skalierung, GitOps, Debuggen und sicheres Rollout –, um Ihre MLOps-Pipelines zu verwalten.
Die folgende Tabelle zeigt die wichtigsten Aspekte der verschiedenen Optionen für die Onlinebereitstellung:
| Kein Code | Low-Code-Entwicklung | BYOC | |
|---|---|---|---|
| Zusammenfassung | Bietet sofort einsatzbereite Funktionen für Rückschlüsse für gängige Frameworks wie scikit-learn, TensorFlow, PyTorch und ONNX über MLflow und Triton. Weitere Informationen finden Sie unter Bereitstellen von MLflow-Modellen in Onlineendpunkten. | Verwendet sichere, öffentliche zusammengestellte Images für beliebte Frameworks; alle zwei Wochen erfolgen Updates zum Beheben von Sicherheitsrisiken. Sie stellen das Bewertungsskript und/oder Python-Abhängigkeiten bereit. Weitere Informationen finden Sie unter Azure Machine Learning – zusammengestellte Umgebungen. | Sie stellen Ihren vollständigen Stapel mithilfe der Azure Machine Learning-Unterstützung für benutzerdefinierte Images bereit. Weitere Informationen finden Sie unter Verwenden eines benutzerdefinierten Containers zum Bereitstellen eines Modells auf einen Onlineendpunkt. |
| Benutzerdefiniertes Basisimage | Keine. Kuratierte Umgebungen stellen zur einfachen Bereitstellung das Basisimage zur Verfügung. | Sie können entweder ein kuratiertes Image oder Ihr angepasstes Image verwenden. | Verwenden Sie entweder einen zugänglichen Containerimagespeicherort (z. B. docker.io, Container Registry oder Microsoft-Artefaktregistrierung) oder ein Dockerfile bereit, das Sie mit Container Registry für Ihren Container erstellen/pushen können. |
| Benutzerdefinierte Abhängigkeiten | Keine. Kuratierte Umgebungen bieten Abhängigkeiten für eine einfache Bereitstellung. | Sie stellen die Azure Machine Learning-Umgebung bereit, in der das Modell ausgeführt wird: entweder ein Docker-Image mit Conda-Abhängigkeiten oder ein Dockerfile. | Benutzerdefinierte Abhängigkeiten sind im Containerimage enthalten. |
| Benutzerdefinierter Code | Keine. Zur Vereinfachung der Bereitstellung werden automatisch Bewertungsskripts generiert. | Sie stellen Ihr Bewertungsskript bereit. | Das Bewertungsskript ist im Containerimage enthalten. |
Hinweis
Bei AutoML-Ausführungen werden automatisch ein Bewertungsskript und Abhängigkeiten für Benutzer erstellt. Für die No-Code-Bereitstellung können Sie ein beliebiges AutoML-Modell bereitstellen, ohne weiteren Code zu erstellen. Für die Low-Code-Bereitstellung können Sie automatisch generierte Skripts an Ihre geschäftlichen Anforderungen anpassen. Informationen zum Bereitstellen mit AutoML-Modellen finden Sie unter Bereitstellen eines AutoML-Modells an einem Onlineendpunkt.
Debuggen von Onlineendpunkten
Testen Sie Ihren Endpunkt nach Möglichkeit lokal, um Ihren Code und Ihre Konfiguration zu validieren und zu debuggen, bevor Sie ihn in Azure bereitstellen. Die Azure CLI und das Python SDK unterstützen lokale Endpunkte und Bereitstellungen, während Azure Machine Learning Studio und ARM-Vorlagen dies nicht tun.
Azure Machine Learning bietet die folgenden Möglichkeiten, Onlineendpunkte lokal und mithilfe von Containerprotokollen zu debuggen:
- Lokales Debuggen mit einem HTTP-Rückschlussserver von Azure Machine Learning
- Lokales Debuggen mit lokalem Endpunkt
- Lokales Debuggen mit lokalem Endpunkt und Visual Studio Code
- Debuggen mit Containerprotokollen
Lokales Debuggen mit einem HTTP-Rückschlussserver von Azure Machine Learning
Sie können Ihr Bewertungsskript lokal debuggen, indem Sie den HTTP-Rückschlusserver von Azure Machine Learning verwenden. Dieser HTTP-Server ist ein Python-Paket, das Ihre Bewertungsfunktion als HTTP-Endpunkt verfügbar macht und den Flask-Servercode und die Abhängigkeiten in ein einzelnes Paket packt.
Azure Machine Learning enthält einen HTTP-Server in den vordefinierten Docker-Images für Rückschlüsse, die zum Bereitstellen eines Modells verwendet werden. Mithilfe des Pakets können Sie das Modell lokal für die Produktion bereitstellen und Ihr Einstiegsbewertungsskript auch sehr einfach in einer lokalen Entwicklungsumgebung überprüfen. Wenn ein Problem mit dem Bewertungsskript auftritt, gibt der Server einen Fehler und den Speicherort zurück, an dem der Fehler aufgetreten ist. Sie können Visual Studio Code auch für das Debugging mit dem HTTP-Rückschlussserver von Azure Machine Learning verwenden.
Tipp
Sie können das Python-Paket von Azure Machine Learning für HTTP-Rückschlussserver verwenden, um Ihr Bewertungsskript lokal und ohne Docker-Engine zu debuggen. Das Debuggen mit dem Rückschlussserver hilft beim Debuggen des Bewertungsskripts vor der Bereitstellung auf lokalen Endpunkten, sodass Sie beim Debuggen nicht von der Konfiguration der Bereitstellungscontainer abhängig sind.
Weitere Informationen zum Debuggen mit dem HTTP-Server finden Sie unter Debuggen von Bewertungsskripts mit dem HTTP-Rückschlussserver von Azure Machine Learning.
Lokales Debuggen mit lokalem Endpunkt
Zum lokalen Debuggen benötigen Sie ein Modell, das in einer lokalen Docker-Umgebung bereitgestellt ist. Sie können diese lokale Bereitstellung für Test- und Debugvorgänge vor der Bereitstellung in der Cloud verwenden.
Für die lokale Bereitstellung muss die Docker-Engine installiert sein und ausgeführt werden. Von Azure Machine Learning wird dann ein lokales Docker-Image erstellt, mit dem das Onlineimage imitiert wird. Azure Machine Learning erstellt Bereitstellungen, führt diese lokal für Sie aus und speichert das Image zwischen, um schnelle Iterationen zu ermöglichen.
Tipp
Wenn die Docker-Engine nicht gestartet wird, wenn der Computer gestartet wird, können Sie die Problembehandlung für die Docker-Engine durchführen. Sie können clientseitige Tools wie Docker Desktop verwenden, um zu debuggen, was im Container passiert.
Das lokale Debuggen umfasst typischerweise die folgenden Schritte:
- Überprüfen Sie zunächst, ob die lokale Bereitstellung erfolgreich war.
- Rufen Sie als Nächstes den lokalen Endpunkt für Rückschlüsse auf.
- Überprüfen Sie abschließend die Ausgabeprotokolle für den
invoke-Vorgang.
Lokale Endpunkte haben die folgenden Einschränkungen:
Keine Unterstützung für Datenverkehrsregeln, Authentifizierung oder Testeinstellungen
Unterstützung nur für eine Bereitstellung pro Endpunkt
Unterstützung für lokale Modelldateien und -umgebungen nur mit lokaler Conda-Datei
Wenn Sie registrierte Modelle testen möchten, laden Sie diese zuerst mithilfe der CLI oder des SDK herunter, und verwenden Sie dann
pathin der Bereitstellungsdefinition, um auf den übergeordneten Ordner zu verweisen.Wenn Sie registrierte Umgebungen testen möchten, überprüfen Sie den Kontext der Umgebung in Azure Machine Learning Studio, und bereiten Sie eine lokale Conda-Datei für die Verwendung vor.
Weitere Informationen zum lokalen Debuggen finden Sie unter Lokales Bereitstellen und Debuggen mithilfe eines lokalen Endpunkts.
Lokales Debuggen mit lokalem Endpunkt und Visual Studio Code (Vorschau)
Wichtig
Dieses Feature ist zurzeit als öffentliche Preview verfügbar. Diese Vorschauversion wird ohne Vereinbarung zum Servicelevel bereitgestellt und ist nicht für Produktionsworkloads vorgesehen. Manche Features werden möglicherweise nicht unterstützt oder sind nur eingeschränkt verwendbar.
Weitere Informationen finden Sie unter Zusätzliche Nutzungsbestimmungen für Microsoft Azure-Vorschauen.
Wie beim lokalen Debuggen müssen Sie zunächst die Docker-Engine installieren und ausführen und dann ein Modell in der lokalen Docker-Umgebung bereitstellen. Sobald Sie über eine lokale Bereitstellung verfügen, verwenden die lokalen Endpunkte von Azure Machine Learning Docker- und Visual Studio Code-Entwicklungscontainer (Dev-Container), um eine lokale Debuggingumgebung zu erstellen und zu konfigurieren.
Mit Entwicklungscontainern können Sie Visual Studio Code-Features wie z. B. interaktives Debugging in einem Docker-Container nutzen. Weitere Informationen zum interaktiven Debuggen von Onlineendpunkten in Visual Studio Code finden Sie unter Lokales Debuggen von Onlineendpunkten in Visual Studio Code.
Debuggen mit Containerprotokollen
Sie können keinen direkten Zugriff auf eine VM erhalten, auf der ein Modell bereitgestellt wird, aber Sie können Protokolle aus den folgenden Containern abrufen, die auf der VM ausgeführt werden:
- Das Konsolenprotokoll des Rückschlussservers enthält die Ausgabe von Druck- und Protokollierungsfunktionen aus Ihrem Bewertungsskriptcode score.py.
- Speicherinitialisierungsprotokolle enthalten Informationen dazu, ob das Herunterladen der Code- und Modelldaten in den Container erfolgreich war. Der Container wird ausgeführt, bevor die Ausführung des Containers des Rückschlussservers gestartet wird.
Weitere Informationen zum Debuggen mit Containerprotokollen finden Sie unter Abrufen von Containerprotokollen.
Datenverkehrsrouting und -spiegelung in Onlinebereitstellungen
Ein einzelner Onlineendpunkt kann mehrere Bereitstellungen enthalten. Wenn der Endpunkt Anforderungen für eingehenden Datenverkehr empfängt, kann er prozentuale Anteile dieses Datenverkehrs an jede Bereitstellung weiterleiten – wie in der Strategie für die native Blau-Gründ-Bereitstellung. Der Endpunkt kann auch Datenverkehr von einer Bereitstellung in eine andere spiegeln oder kopieren. Dies wird als Datenverkehrsspiegelung oder Shadowing bezeichnet.
Datenverkehrsrouting für Blau/Grün-Bereitstellung
Eine Blau-Grün-Bereitstellung ist eine Bereitstellungsstrategie, mit der Sie eine neue Grün-Bereitstellung für eine kleine Teilmenge von Benutzern oder Anforderungen einführen können, bevor Sie sie in vollem Umfang einführen. Der Endpunkt kann einen Lastenausgleich implementieren, um jeder Bereitstellung einen bestimmten Prozentsatz des Datenverkehrs zuzuweisen. Dabei summiert sich die Gesamtzuweisung für alle Bereitstellungen auf 100 %.
Tipp
Eine Anforderung kann den konfigurierten Lastausgleich umgehen, indem sie einen HTTP-Header von azureml-model-deployment enthält. Setzen Sie den Wert der Kopfzeile auf den Namen der Einrichtung, an die die Anforderung weitergeleitet werden soll.
Die folgende Abbildung zeigt Einstellungen in Azure Machine Learning Studio für die Zuweisung von Datenverkehr zwischen einer blauen und einer grünen Bereitstellung.
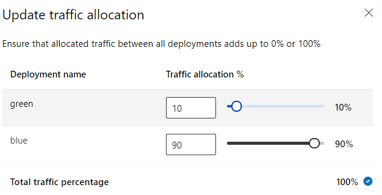
Diese vorausgehende Datenverkehrszuweisung leitet 10 % des Datenverkehrs an die Grün-Bereitstellung und 90 % des Datenverkehrs an die Blau-Bereitstellung weiter, wie in der folgenden Abbildung gezeigt:
Datenverkehrsspiegelung in Onlinebereitstellungen
Der Endpunkt kann auch Datenverkehr von einer Bereitstellung in eine andere spiegeln oder kopieren. Sie können Datenverkehrsspiegelung (auch als Shadow Testing bezeichnet) verwenden, wenn Sie eine neue Bereitstellung mit Produktionsdatenverkehr testen möchten, ohne die Ergebnisse zu beeinträchtigen, die Kunden in vorhandenen Bereitstellungen erhalten.
Sie können beispielsweise eine Blau-Grün-Bereitstellung implementieren, bei der 100 % des Datenverkehrs an die Blau-Bereitstellung weitergeleitet und 10 % in der Grün-Bereitstellung gespiegelt werden. Die Ergebnisse des gespiegelten Datenverkehrs an die Grün-Bereitstellung werden nicht an die Clients zurückgegeben, aber die Metriken und Protokolle werden aufgezeichnet.
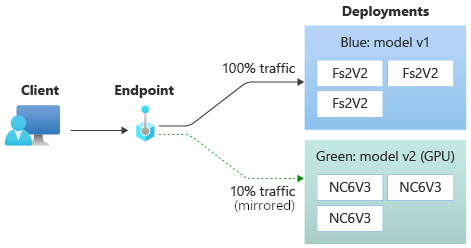
Weitere Informationen zur Verwendung der Datenverkehrsspiegelung finden Sie unter Führen Sie die sichere Bereitstellung neuer Anwendungen für Echtzeitrückschlüsse durch..
Weitere Onlineendpunktfunktionen
In den folgenden Abschnitten werden weitere Funktionen von Azure Machine Learning-Onlineendpunkten beschrieben.
Authentifizierung und Verschlüsselung
- Authentifizierung: Schlüssel und Azure Machine Learning-Token
- Verwaltete Identität: Benutzerseitig und systemseitig zugewiesen
- Standardmäßiges SSL (Secure Socket Layer) für Aufruf von Endpunkten
Automatische Skalierung
Autoscale führt automatisch die richtige Menge an Ressourcen aus, um die Last Ihrer Anwendung zu bewältigen. Verwaltete Endpunkte unterstützen Autoskalierung durch die Integration mit der Funktion für die Autoskalierung in Azure Monitor. Sie können metrikbasierte Skalierung (z. B. eine CPU-Auslastung von mehr als 70 %), zeitplanbasierte Skalierung (z. B. für Hauptgeschäftszeiten) oder beides konfigurieren.

Weitere Informationen finden Sie unter Autoskalierung von Onlineendpunkten in Azure Machine Learning.
Verwaltete Netzwerkisolation
Wenn Sie ein Machine Learning-Modell auf einem verwalteten Onlineendpunkt bereitstellen, können Sie die Kommunikation mit dem Onlineendpunkt durch die Verwendung privater Endpunkte absichern. Sie können Sicherheit für eingehende Bewertungsanforderungen und ausgehende Kommunikationen separat konfigurieren.
Eingehende Kommunikation verwendet den privaten Endpunkt des Azure Machine Learning-Arbeitsbereichs. Ausgehende Kommunikation nutzt hingegen private Endpunkte, die für das verwaltete virtuelle Netzwerk des Arbeitsbereichs erstellt wurden. Weitere Informationen finden Sie unter Netzwerkisolation mit verwalteten Onlineendpunkten.
Überwachen von Onlineendpunkten und Bereitstellungen
Azure Machine Learning-Endpunkte lassen sich in Azure Monitor integrieren. Mit der Azure Monitor-Integration können Sie Metriken in Diagrammen anzeigen, Warnungen konfigurieren, Protokolltabellen abfragen und Application Insights zum Analysieren von Ereignissen aus Benutzercontainern verwenden. Weitere Informationen finden Sie unter Online-Endpunkte überwachen.
Geheimniseinschleusung in Onlinebereitstellungen (Vorschau)
Die Geheimniseinschleusung für eine Onlinebereitstellung besteht aus dem Abrufen von Geheimnissen (z. B. API-Schlüssel) aus Geheimnisspeichern und dem Einschleusen dieser in den Benutzercontainer, der in der Bereitstellung ausgeführt wird. Um einen sicheren Geheimnisverbrauch für den Rückschlussserver bereitzustellen, der Ihr Bewertungsskript oder den Rückschlussstapel in Ihrer BYOC-Bereitstellung ausführt, können Sie Umgebungsvariablen verwenden, um auf Geheimnisse zuzugreifen.
Sie können Geheimnisse manuell mithilfe von verwalteten Identitäten einschleusen oder das Feature zur Geheimniseinschleusung verwenden. Weitere Informationen finden Sie unter Geheimniseinschleusung in Onlineendpunkten (Vorschau).
Zugehöriger Inhalt
- Bereitstellen und Bewerten eines Machine Learning-Modells mithilfe eines Onlineendpunkts
- Batchendpunkte
- Schützen Ihrer verwalteten Onlineendpunkte mit Netzwerkisolation
- Bereitstellen von Modellen mit REST
- Überwachen von Onlineendpunkten
- Anzeigen der Kosten für einen verwalteten Azure Machine Learning-Onlineendpunkt
- Verwalten und Erhöhen der Kontingente und Grenzwerte für Ressourcen mit Azure Machine Learning