Trainieren eines Regressionsmodells mit automatisiertem maschinellem Lernen und Python (SDK v1)
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie mit dem Python SDK für Azure Machine Learning ein Regressionsmodell unter Verwendung des automatisierten maschinellen Lernens von Azure Machine Learning trainieren. Das Regressionsmodell prognostiziert die Fahrgastpreise für Taxis in New York City (NYC). Sie schreiben Code mit dem Python SDK, um einen Arbeitsbereich mit vorbereiteten Daten zu konfigurieren, das Modell lokal mit benutzerdefinierten Parametern zu trainieren und die Ergebnisse zu untersuchen.
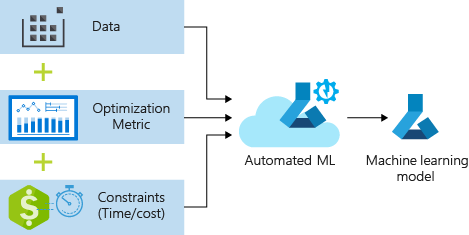
Der Prozess akzeptiert Schulungsdaten und Konfigurationseinstellungen. Er durchläuft automatisch Kombinationen verschiedene Kombinationen von Featurenormalisierungs-/Standardisierungsmethoden, Modellen und Hyperparametereinstellungen, um das bestmögliche Modell zu erhalten. Das folgende Diagramm veranschaulicht den Prozessflow für das Regressionsmodelltraining:
Ein Azure-Abonnement. Sie können ein kostenloses oder kostenpflichtiges Konto für Azure Machine Learning erstellen.
Einen Azure Machine Learning-Arbeitsbereich und eine Compute-Instanz Informationen zum Vorbereiten dieser Ressourcen finden Sie unter Schnellstart Erste Schritte mit Azure Machine Learning.
Rufen Sie die vorbereiteten Beispieldaten für die Übungen des Tutorials ab, indem Sie ein Notebook in Ihren Arbeitsbereich laden:
Wechseln Sie zum Arbeitsbereich im Azure Machine Learning Studio, wählen Sie Notebooks und anschließend die Registerkarte Beispiele aus.
Erweitern Sie in der Liste der Notebooks den Knoten Samples>SDK v1>Tutorials>regression-automl-nyc-taxi-data.
Wählen Sie das Notebook regression-automl-nyc-taxi-data aus.
Damit Sie jede Notebookzelle im Rahmen dieses Tutorials ausführen können, wählen Sie Diese Datei klonen aus.
Alternativer Ansatz: Wenn Sie möchten, können Sie die Übungen des Tutorials auch in einer lokalen Umgebung ausführen. Das Tutorial ist im Azure Machine Learning Notebooks-Repository auf GitHub verfügbar. Wenn Sie sich für diesen Ansatz entscheiden, führen Sie die folgenden Schritte aus, um die erforderlichen Pakete abzurufen:
Führen Sie den Befehl
pip install azureml-opendatasets azureml-widgetsauf Ihrem lokalen Computer aus, um die erforderlichen Pakete abzurufen.
Das Paket „Open Datasets“ enthält eine Klasse für jede Datenquelle (z. B. NycTlcGreen), damit Sie vor dem Herunterladen Datumsparameter einfach filtern können.
Mit dem folgenden Code werden die erforderlichen Pakete importiert:
from azureml.opendatasets import NycTlcGreen
import pandas as pd
from datetime import datetime
from dateutil.relativedelta import relativedelta
Der erste Schritt besteht darin, einen DataFrame für die Taxidaten zu erstellen. Wenn Sie nicht in einer Spark-Umgebung arbeiten, können Sie mit dem Paket „Open Datasets“ bei bestimmten Klassen jeweils nur einen Monat an Daten herunterladen. Dieser Ansatz trägt dazu bei, das MemoryError-Problem zu vermeiden, das bei großen Datasets auftreten kann.
Um die Taxidaten herunterzuladen, rufen Sie iterativ einen Monat nach dem anderen ab. Bevor Sie den nächsten Satz von Daten an den green_taxi_df-DataFrame anfügen, wählen Sie eine Zufallsstichprobe von 2.000 Datensätzen aus jedem Monat, und sehen Sie sich dann die Daten in der Vorschau an. Mit diesem Ansatz lässt sich ein Aufblähen des DataFrames vermeiden.
Mit dem folgenden Code wird der DataFrame erstellt, dann werden die Daten abgerufen und in den DataFrame geladen:
green_taxi_df = pd.DataFrame([])
start = datetime.strptime("1/1/2015","%m/%d/%Y")
end = datetime.strptime("1/31/2015","%m/%d/%Y")
for sample_month in range(12):
temp_df_green = NycTlcGreen(start + relativedelta(months=sample_month), end + relativedelta(months=sample_month)) \
.to_pandas_dataframe()
green_taxi_df = green_taxi_df.append(temp_df_green.sample(2000))
green_taxi_df.head(10)
Die folgende Tabelle zeigt die vielen Spalten mit Werten in den Beispieltaxidaten:
| vendorID | lpepPickupDatetime | lpepDropoffDatetime | passengerCount | tripDistance | puLocationId | doLocationId | pickupLongitude | pickupLatitude | dropoffLongitude | ... | paymentType | fareAmount | extra | mtaTax | improvementSurcharge | tipAmount | tollsAmount | ehailFee | totalAmount | tripType |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2015-01-30 18:38:09 | 2015-01-30 19:01:49 | 1 | 1,88 | Keine | Keine | -73,996155 | 40,690903 | -73,964287 | ... | 1 | 15.0 | 1.0 | 0,5 | 0,3 | 4.00 | 0,0 | Keine | 20,80 | 1.0 |
| 1 | 2015-01-17 23:21:39 | 2015-01-17 23:35:16 | 1 | 2.70 | Keine | Keine | -73,978508 | 40,687984 | -73,955116 | ... | 1 | 11,5 | 0,5 | 0,5 | 0,3 | 2.55 | 0,0 | Keine | 15,35 | 1.0 |
| 2 | 2015-01-16 01:38:40 | 2015-01-16 01:52:55 | 1 | 3.54 | Keine | Keine | -73,957787 | 40,721779 | -73,963005 | ... | 1 | 13,5 | 0,5 | 0,5 | 0,3 | 2.80 | 0,0 | Keine | 17.60 | 1.0 |
| 2 | 2015-01-04 17:09:26 | 2015-01-04 17:16:12 | 1 | 1,00 | Keine | Keine | -73,919914 | 40,826023 | -73,904839 | ... | 2 | 6,5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Keine | 7.30 | 1.0 |
| 1 | 2015-01-14 10:10:57 | 2015-01-14 10:33:30 | 1 | 5.10 | Keine | Keine | -73,943710 | 40,825439 | -73,982964 | ... | 1 | 18.5 | 0,0 | 0,5 | 0,3 | 3.85 | 0,0 | Keine | 23,15 | 1.0 |
| 2 | 2015-01-19 18:10:41 | 2015-01-19 18:32:20 | 1 | 7.41 | Keine | Keine | -73,940918 | 40,839714 | -73,994339 | ... | 1 | 24.0 | 0,0 | 0,5 | 0,3 | 4.80 | 0,0 | Keine | 29,60 | 1.0 |
| 2 | 2015-01-01 15:44:21 | 2015-01-01 15:50:16 | 1 | 1,03 | Keine | Keine | -73,985718 | 40,685646 | -73.996773 | ... | 1 | 6.5 | 0,0 | 0,5 | 0,3 | 1.30 | 0,0 | Keine | 8,60 | 1.0 |
| 2 | 2015-01-12 08:01:21 | 2015-01-12 08:14:52 | 5 | 2.94 | Keine | Keine | -73,939865 | 40,789822 | -73,952957 | ... | 2 | 12,5 | 0,0 | 0,5 | 0,3 | 0,00 | 0,0 | Keine | 13.30 | 1.0 |
| 1 | 2015-01-16 21:54:26 | 2015-01-16 22:12:39 | 1 | 3.00 | Keine | Keine | -73,957939 | 40,721928 | -73,926247 | ... | 1 | 14,0 | 0,5 | 0,5 | 0,3 | 2.00 | 0,0 | Keine | 17,30 | 1.0 |
| 2 | 2015-01-06 06:34:53 | 2015-01-06 06:44:23 | 1 | 2.31 | Keine | Keine | -73,943825 | 40,810257 | -73,943062 | ... | 1 | 10,0 | 0,0 | 0,5 | 0,3 | 2.00 | 0,0 | Keine | 12.80 | 1.0 |
Es ist hilfreich, einige Spalten zu entfernen, die Sie nicht für das Training oder und die Erstellung anderer Features benötigen. Beispielsweise können Sie die Spalte lpepPickupDatetime entfernen, weil das automatisierte ML zeitbasierte Features automatisch verarbeitet.
Mit dem folgenden Code werden 14 Spalten aus den Beispieldaten entfernt:
columns_to_remove = ["lpepDropoffDatetime", "puLocationId", "doLocationId", "extra", "mtaTax",
"improvementSurcharge", "tollsAmount", "ehailFee", "tripType", "rateCodeID",
"storeAndFwdFlag", "paymentType", "fareAmount", "tipAmount"
]
for col in columns_to_remove:
green_taxi_df.pop(col)
green_taxi_df.head(5)
Der nächste Schritt besteht darin, die Daten zu bereinigen.
Mit dem folgenden Code wird die Funktion describe() mit dem neuen DataFrame ausgeführt, um zusammenfassende Statistiken für jedes Feld zu erstellen:
green_taxi_df.describe()
Die folgende Tabelle enthält zusammenfassende Statistiken für die verbleibenden Felder in den Beispieldaten:
| vendorID | passengerCount | tripDistance | pickupLongitude | pickupLatitude | dropoffLongitude | dropoffLatitude | totalAmount | |
|---|---|---|---|---|---|---|---|---|
| count | 24000,00 | 24000,00 | 24000,00 | 24000,00 | 24000,00 | 24000,00 | 24000,00 | 24000,00 |
| mean | 1,777625 | 1,373625 | 2,893981 | -73,827403 | 40,689730 | -73,819670 | 40,684436 | 14,892744 |
| std | 0,415850 | 1,046180 | 3,072343 | 2,821767 | 1,556082 | 2,901199 | 1,599776 | 12,339749 |
| min | 1.00 | 0.00 | 0,00 | -74,357101 | 0,00 | -74,342766 | 0,00 | -120,80 |
| 25 % | 2.00 | 1,00 | 1.05 | -73,959175 | 40,699127 | -73,966476 | 40,699459 | 8.00 |
| 50 % | 2.00 | 1,00 | 1,93 | -73,945049 | 40,746754 | -73,944221 | 40,747536 | 11.30 |
| 75% | 2.00 | 1,00 | 3.70 | -73,917089 | 40,803060 | -73,909061 | 40,791526 | 17.80 |
| max | 2.00 | 8.00 | 154,28 | 0,00 | 41,109089 | 0,00 | 40,982826 | 425,00 |
In der zusammenfassenden Statistik sind mehrere Felder als Ausreißer zu erkennen, d. h. als Werte, die die Modellgenauigkeit verringern. Um dieses Problem zu beheben, filtern Sie die Felder für Breiten-/Längengrad (lat/long), sodass sich die Werte innerhalb der Grenzen von Manhattan befinden. Auf diese Weise werden längere Taxifahrten sowie Fahrten herausgefiltert, die in Bezug auf ihre Beziehung zu anderen Features Ausreißer sind.
Filtern Sie als Nächstes das Feld tripDistance so, dass es größer Null, aber kleiner als 31 Meilen (Semiversus-Abstand zwischen zwei Längen-/Breitengrad-Paaren) ist. Mit dieser Technik werden längere Fahrten mit inkonsistenten Fahrtkosten ausgeschlossen.
Das Feld totalAmount weist schließlich negative Werte für Taxitarife auf, die im Kontext unseres Modells nicht sinnvoll sind. Das Feld passengerCount enthält auch ungültige Daten, bei denen der Minimalwert Null ist.
Mit dem folgende Code werden diese Wertanomalien mithilfe von Abfragefunktionen herausgefiltert. Mit diesem Code werden dann die letzten Spalten, die für das Training nicht erforderlich sind, entfernt:
final_df = green_taxi_df.query("pickupLatitude>=40.53 and pickupLatitude<=40.88")
final_df = final_df.query("pickupLongitude>=-74.09 and pickupLongitude<=-73.72")
final_df = final_df.query("tripDistance>=0.25 and tripDistance<31")
final_df = final_df.query("passengerCount>0 and totalAmount>0")
columns_to_remove_for_training = ["pickupLongitude", "pickupLatitude", "dropoffLongitude", "dropoffLatitude"]
for col in columns_to_remove_for_training:
final_df.pop(col)
Der letzte Schritt in dieser Sequenz besteht darin, die Funktion describe() erneut für die Daten aufzurufen, um sicherzustellen, dass die Bereinigung erwartungsgemäß funktioniert hat. Sie haben jetzt einen vorbereiteten und bereinigten Satz von Taxi-, Feiertags- und Wetterdaten, mit dem Sie das Machine Learning-Modell trainieren können:
final_df.describe()
Erstellen Sie ein Arbeitsbereichsobjekt aus dem vorhandenen Arbeitsbereich. Ein Arbeitsbereich ist eine Klasse, die Informationen zu Ihrem Azure-Abonnement und Ihren Azure-Ressourcen akzeptiert. Außerdem erstellt der Arbeitsbereich eine Cloudressource zur Überwachung und Nachverfolgung Ihrer Modellausführungen.
Der folgende Code ruft die Workspace.from_config() Funktion auf, um die Datei config.json zu lesen und die Authentifizierungsdetails in ein Objekt namens ws zu laden.
from azureml.core.workspace import Workspace
ws = Workspace.from_config()
Das ws-Objekt wird im restlichen Code in diesem Tutorial verwendet.
Teilen Sie die Daten mithilfe der Funktion train_test_split in der Bibliothek scikit-learn in Trainings- und Testsätze auf. Diese Funktion unterteilt die Daten in das x-Dataset (Features) zum Trainieren des Modells und in das y-Dataset (zu prognostizierende Werte) zum Testen.
Der Parameter test_size bestimmt den Prozentsatz der Daten, die zu Testzwecken verwendet werden sollen. Der Parameter random_state legt einen Seed für den Zufallsgenerator fest, damit die Aufteilung zwischen Trainings- und Testdaten deterministisch ist.
Mit dem folgenden Code wird die Funktion train_test_split aufgerufen, um die x- und y-Datasets zu laden:
from sklearn.model_selection import train_test_split
x_train, x_test = train_test_split(final_df, test_size=0.2, random_state=223)
Dieser Schritt dient dazu, Datenpunkte zum Testen des fertigen Modells vorzubereiten, die nicht zum Trainieren des Modells verwendet werden. Diese Punkte werden zur Messung der tatsächlichen Genauigkeit verwendet. Ein gut trainiertes Modell ist in der Lage, aus ungesehenen Daten genaue Vorhersagen zu treffen. Sie verfügen nun über Daten, die für das automatische Trainieren eines Machine Learning-Modells vorbereitet sind.
Führen Sie die folgenden Schritte aus, um ein Modell automatisch zu trainieren:
Definieren Sie Einstellungen für die Experimentausführung. Fügen Sie Ihre Trainingsdaten an die Konfiguration an, und ändern Sie Einstellungen, die den Trainingsprozess steuern.
Übermitteln Sie das Experiment zur Modelloptimierung. Nachdem Sie das Experiment übermittelt haben, durchläuft der Prozess verschiedene Machine Learning-Algorithmen und Hyperparametereinstellungen unter Berücksichtigung der von Ihnen definierten Einschränkungen. Er optimiert eine Genauigkeitsmetrik, um das am besten geeignete Modell auszuwählen.
Definieren Sie die Experimentparameter und Modelleinstellungen für das Training. Die vollständige Liste mit den Einstellungen finden Sie hier. Das Übermitteln des Experiments mit diesen Standardeinstellungen nimmt ungefähr 5-20 Minuten in Anspruch. Um die Bearbeitungszeit zu verringern, reduzieren Sie den Parameter experiment_timeout_hours.
| Eigenschaft | Wert in diesem Tutorial | Beschreibung |
|---|---|---|
iteration_timeout_minutes |
10 | Zeitlimit in Minuten für jede Iteration. Erhöhen Sie diesen Wert für größere Datasets, die mehr Zeit für jede Iteration benötigen. |
experiment_timeout_hours |
0,3 | Maximal zulässige Dauer für alle Iterationen (in Stunden). Danach wird das Experiment beendet. |
enable_early_stopping |
True | Flag zum Aktivieren der vorzeitigen Beendigung, wenn sich der Score auf kurze Sicht nicht verbessert. |
primary_metric |
spearman_correlation | Metrik, die Sie optimieren möchten. Das am besten geeignete Modell wird basierend auf dieser Metrik ausgewählt. |
featurization |
auto | Bei Verwendung des Werts auto kann das Experiment die Eingabedaten vorverarbeiten, beispielsweise fehlende Daten behandeln, Text in numerische Daten umwandeln und Ähnliches tun. |
verbosity |
logging.INFO | Steuert den Protokollierungsgrad. |
n_cross_validations |
5 | Anzahl von Kreuzvalidierungsaufteilungen, die ausgeführt werden sollen, wenn keine Überprüfungsdaten angegeben sind. |
Mit dem folgenden Code wird das Experiment gesendet:
import logging
automl_settings = {
"iteration_timeout_minutes": 10,
"experiment_timeout_hours": 0.3,
"enable_early_stopping": True,
"primary_metric": 'spearman_correlation',
"featurization": 'auto',
"verbosity": logging.INFO,
"n_cross_validations": 5
}
Mit dem folgenden Code können Sie Ihre definierten Trainingseinstellungen als **kwargs-Parameter für ein AutoMLConfig-Objekt verwenden. Außerdem geben Sie Ihre Trainingsdaten und den Modelltyp (in diesem Fall regression) an.
from azureml.train.automl import AutoMLConfig
automl_config = AutoMLConfig(task='regression',
debug_log='automated_ml_errors.log',
training_data=x_train,
label_column_name="totalAmount",
**automl_settings)
Hinweis
Die Schritte zur Vorverarbeitung bei automatisiertem ML (Featurenormalisierung, Behandlung fehlender Daten, Umwandlung von Text in numerische Daten usw.) werden Teil des zugrunde liegenden Modells. Wenn Sie das Modell für Vorhersagen verwenden, werden die während des Trainings angewendeten Vorverarbeitungsschritte automatisch auf Ihre Eingabedaten angewendet.
Erstellen Sie ein Experimentobjekt in Ihrem Arbeitsbereich. Ein Experiment fungiert als Container für die einzelnen Aufträge. Übergeben Sie das definierte Objekt vom Typ automl_config an das Experiment, und legen Sie die Ausgabe auf True fest, um den Fortschritt während des Auftrags anzuzeigen.
Nachdem Sie das Experiment gestartet haben, wird die Anzeige der Ausgabe während der Ausführung des Experiments live aktualisiert. Für die einzelnen Iterationen werden jeweils der Modelltyp, die Ausführungsdauer und die Trainingsgenauigkeit angezeigt. Im Feld BEST wird die beste Trainingsbewertung auf der Grundlage Ihres Metriktyps nachverfolgt:
from azureml.core.experiment import Experiment
experiment = Experiment(ws, "Tutorial-NYCTaxi")
local_run = experiment.submit(automl_config, show_output=True)
So sieht die Ausgabe aus:
Running on local machine
Parent Run ID: AutoML_1766cdf7-56cf-4b28-a340-c4aeee15b12b
Current status: DatasetFeaturization. Beginning to featurize the dataset.
Current status: DatasetEvaluation. Gathering dataset statistics.
Current status: FeaturesGeneration. Generating features for the dataset.
Current status: DatasetFeaturizationCompleted. Completed featurizing the dataset.
Current status: DatasetCrossValidationSplit. Generating individually featurized CV splits.
Current status: ModelSelection. Beginning model selection.
****************************************************************************************************
ITERATION: The iteration being evaluated.
PIPELINE: A summary description of the pipeline being evaluated.
DURATION: Time taken for the current iteration.
METRIC: The result of computing score on the fitted pipeline.
BEST: The best observed score thus far.
****************************************************************************************************
ITERATION PIPELINE DURATION METRIC BEST
0 StandardScalerWrapper RandomForest 0:00:16 0.8746 0.8746
1 MinMaxScaler RandomForest 0:00:15 0.9468 0.9468
2 StandardScalerWrapper ExtremeRandomTrees 0:00:09 0.9303 0.9468
3 StandardScalerWrapper LightGBM 0:00:10 0.9424 0.9468
4 RobustScaler DecisionTree 0:00:09 0.9449 0.9468
5 StandardScalerWrapper LassoLars 0:00:09 0.9440 0.9468
6 StandardScalerWrapper LightGBM 0:00:10 0.9282 0.9468
7 StandardScalerWrapper RandomForest 0:00:12 0.8946 0.9468
8 StandardScalerWrapper LassoLars 0:00:16 0.9439 0.9468
9 MinMaxScaler ExtremeRandomTrees 0:00:35 0.9199 0.9468
10 RobustScaler ExtremeRandomTrees 0:00:19 0.9411 0.9468
11 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9077 0.9468
12 StandardScalerWrapper LassoLars 0:00:15 0.9433 0.9468
13 MinMaxScaler ExtremeRandomTrees 0:00:14 0.9186 0.9468
14 RobustScaler RandomForest 0:00:10 0.8810 0.9468
15 StandardScalerWrapper LassoLars 0:00:55 0.9433 0.9468
16 StandardScalerWrapper ExtremeRandomTrees 0:00:13 0.9026 0.9468
17 StandardScalerWrapper RandomForest 0:00:13 0.9140 0.9468
18 VotingEnsemble 0:00:23 0.9471 0.9471
19 StackEnsemble 0:00:27 0.9463 0.9471
Untersuchen Sie die Ergebnisse des automatischen Trainings mit einem Jupyter-Widget. Mit dem Widget können Sie ein Diagramm und eine Tabelle aller individuellen Auftragsiterationen sowie Metriken zur Trainingsgenauigkeit und Metadaten anzeigen. Darüber hinaus können Sie über das Dropdownmenü nach anderen Genauigkeitsmetriken filtern.
Mit dem folgenden Code wird ein Diagramm zum Untersuchen der Ergebnisse erzeugt:
from azureml.widgets import RunDetails
RunDetails(local_run).show()
Die Ausführungsdetails für das Jupyter-Widget:

Das Plotdiagramm für das Jupyter-Widget:

Mit dem folgenden Code können Sie das beste Modell aus Ihren Iterationen auswählen. Die Funktion get_output gibt die beste Ausführung und das angepasste Modell für den letzten passenden Aufruf zurück. Mithilfe der Überladungen der get_output-Funktion können Sie die beste Ausführung und das am besten angepasste Modell für jede protokollierte Metrik oder eine bestimmte Iteration abrufen.
best_run, fitted_model = local_run.get_output()
print(best_run)
print(fitted_model)
Verwenden Sie das beste Modell, um Vorhersagen für das Testdataset auszuführen und Preise für Taxifahrten vorauszusagen. Die Funktion predict verwendet das beste Modell und prognostiziert die Werte von y (Fahrtkosten) anhand des Datasets x_test.
Der folgende Code gibt die ersten 10 vorhergesagten Kostenwerte aus dem Dataset y_predict aus:
y_test = x_test.pop("totalAmount")
y_predict = fitted_model.predict(x_test)
print(y_predict[:10])
Berechnen Sie den root mean squared error der Ergebnisse. Konvertieren Sie den DataFrame y_test in eine Liste, und vergleichen Sie ihn mit den vorhergesagten Werten. Die Funktion mean_squared_error akzeptiert zwei Wertarrays und berechnet den durchschnittlichen quadratischen Fehler zwischen den Arrays. Die Quadratwurzel des Ergebnisses ergibt einen Fehler in der gleichen Maßeinheit wie die y-Variable (Kosten). Dieser Fehler gibt Aufschluss darüber, wie weit die Vorhersagen des Preises für Taxifahrten ungefähr vom tatsächlichen Preis entfernt sind.
from sklearn.metrics import mean_squared_error
from math import sqrt
y_actual = y_test.values.flatten().tolist()
rmse = sqrt(mean_squared_error(y_actual, y_predict))
rmse
Führen Sie den folgenden Code aus, um den mittleren absoluten Fehler in Prozent (Mean Absolute Percent Error, MAPE) anhand der vollständigen Datasets y_actual und y_predict zu berechnen. Diese Metrik berechnet eine absolute Differenz zwischen jedem vorhergesagten und tatsächlichen Wert und addiert alle Differenzen. Die Summe wird dann als Prozentsatz der gesamten tatsächlichen Werte ausgedrückt.
sum_actuals = sum_errors = 0
for actual_val, predict_val in zip(y_actual, y_predict):
abs_error = actual_val - predict_val
if abs_error < 0:
abs_error = abs_error * -1
sum_errors = sum_errors + abs_error
sum_actuals = sum_actuals + actual_val
mean_abs_percent_error = sum_errors / sum_actuals
print("Model MAPE:")
print(mean_abs_percent_error)
print()
print("Model Accuracy:")
print(1 - mean_abs_percent_error)
So sieht die Ausgabe aus:
Model MAPE:
0.14353867606052823
Model Accuracy:
0.8564613239394718
Anhand der endgültigen Metriken für die Vorhersagegenauigkeit sehen Sie, dass das Modell die Preise von Taxifahrten auf der Grundlage der Features des Datasets ziemlich gut vorhersagen kann (in der Regel mit einer Genauigkeit von +/-4,00 USD und einem Fehler von etwa 15 Prozent).
Der traditionelle Entwicklungsprozess für maschinelles Lernen ist äußerst ressourcenintensiv. Es erfordert ein erhebliches Maß an Fachwissen und Zeit, um die Ergebnisse von Dutzenden von Modellen auszuführen und zu vergleichen. Mit automatisiertem maschinellem Lernen können Sie schnell zahlreiche verschiedene Modelle für Ihr Szenario testen.
Wenn Sie nicht beabsichtigen, andere Tutorials für Azure Machine Learning zu bearbeiten, führen Sie die folgenden Schritte aus, um die nicht mehr benötigten Ressourcen zu entfernen.
Wenn Sie Compute verwendet haben, können Sie den virtuellen Computer beenden, wenn Sie ihn nicht verwenden, und Ihre Kosten reduzieren:
Wechseln Sie zum Arbeitsbereich in Azure Machine Learning Studio, und wählen Sie Compute aus.
Wählen Sie in der Liste die Compute-Instanz aus, die Sie beenden möchten, und wählen Sie dann Beenden aus.
Wenn Sie bereit sind, erneut Compute zu verwenden, können Sie den virtuellen Computer neu starten.
Wenn Sie die in diesem Lernprogramm erstellten Ressourcen nicht weiter verwenden möchten, können Sie sie löschen, um Gebühren zu vermeiden.
Führen Sie die folgenden Schritte aus, um die Ressourcengruppe und alle Ressourcen zu entfernen:
Navigieren Sie im Azure-Portal zu Ressourcengruppen.
Wählen Sie in der Liste die Ressourcengruppe, die Sie in diesem Lernprogramm erstellt haben, und anschließend Ressourcengruppe löschen aus.
Geben Sie an der Eingabeaufforderung zur Bestätigung den Ressourcengruppennamen ein, und wählen Sie Löschen aus.
Wenn Sie die Ressourcengruppe beibehalten und nur einen einzelnen Arbeitsbereich löschen möchten, führen Sie die folgenden Schritte aus:
Wechseln Sie im Azure-Portal zu der Ressourcengruppe, die den Arbeitsbereich enthält, den Sie entfernen möchten.
Wählen Sie den Arbeitsbereich aus, wählen Sie Eigenschaftenund dann Löschen aus.