Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
Azure CLI ML-Erweiterung v2 (aktuell)Python SDK azure-ai-ml v2 (aktuell)
In Azure Machine Learning können Sie einen benutzerdefinierten Container verwenden, um ein Modell auf einem Onlineendpunkt bereitzustellen. Benutzerdefinierte Containerbereitstellungen können andere Webserver als den standardmäßigen Python Flask-Server verwenden, den Azure Machine Learning verwendet.
Wenn Sie eine benutzerdefinierte Bereitstellung verwenden, können Sie:
- Verwenden Sie verschiedene Tools und Technologien wie TensorFlow Serving (TF Serving), TorchServe, Triton Inference Server, das Plumber R-Paket und das Azure Machine Learning Inference Minimal Image.
- Nutzen Sie dennoch die integrierte Überwachung, Skalierung, Warnung und Authentifizierung, die Azure Machine Learning bietet.
In diesem Artikel wird erklärt, wie Sie ein TF Serving-Image verwenden, um ein TensorFlow-Modell bereitzustellen.
Voraussetzungen
Ein Azure Machine Learning-Arbeitsbereich. Anweisungen zum Erstellen eines Arbeitsbereichs finden Sie unter Erstellen des Arbeitsbereichs.
Die Azure CLI und die
mlErweiterung oder das Azure Machine Learning Python SDK v2:Informationen zum Installieren der Azure CLI und der
mlErweiterung finden Sie unter Installieren und Einrichten der CLI (v2).In den Beispielen in diesem Artikel wird davon ausgegangen, dass Sie eine Bash-Shell oder eine kompatible Shell verwenden. Sie können z. B. eine Shell auf einem Linux-System oder Windows-Subsystem für Linux verwenden.
Eine Azure-Ressourcengruppe, die Ihren Arbeitsbereich enthält und auf die Sie oder Ihr Dienstprinzipal als Mitwirkender Zugriff haben. Wenn Sie die Schritte unter "Arbeitsbereich erstellen" verwenden, um Ihren Arbeitsbereich zu konfigurieren, erfüllen Sie diese Anforderung.
Docker-Modul, lokal installiert und ausgeführt. Diese Voraussetzung wird dringend empfohlen. Sie benötigen es, um ein Modell lokal bereitzustellen, und es ist hilfreich für das Debuggen.
Bereitstellungsbeispiele
In der folgenden Tabelle sind Bereitstellungsbeispiele aufgeführt, die benutzerdefinierte Container verwenden und verschiedene Tools und Technologien nutzen.
| Beispiel | Azure CLI-Skript | BESCHREIBUNG |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Stellt mehrere Modelle in einer einzelnen Bereitstellung bereit, indem das Rückschluss-Minimalimage für Azure Machine Learning erweitert wird |
| Minimalmodell/Einzelmodell | deploy-custom-container-minimal-single-model | Stellt ein einzelnes Modell bereit, indem das minimalistische Inferenz-Image von Azure Machine Learning erweitert wird. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Stellt zwei MLFlow-Modelle mit unterschiedlichen Python-Anforderungen für zwei separate Bereitstellungen hinter einem einzelnen Endpunkt bereit. Verwendet das Rückschluss-Minimalimage für Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Stellt drei Regressionsmodelle auf einem Endpunkt bereit. Verwendet das Plumber R-Paket. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Stellt ein Half Plus Two-Modell mithilfe eines benutzerdefinierten TF Serving-Containers bereit. Verwendet den Standardmodellregistrierungsprozess. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Stellt ein Half Plus Two-Modell bereit, indem ein benutzerdefinierter Container für TF Serving verwendet wird, in dem das Modell in das Image integriert ist. |
| Torchserve/Densenet | deploy-custom-container-torchserve-densenet | Stellt ein einzelnes Modell mithilfe eines benutzerdefinierten TorchServe-Containers bereit. |
| triton/single-model | deploy-custom-container-triton-single-model | Stellt ein Triton-Modell mithilfe eines benutzerdefinierten Containers bereit. |
In diesem Artikel erfahren Sie, wie Sie das Tfserving/half-plus-two-Beispiel verwenden.
Warnung
Microsoft-Supportteams können möglicherweise nicht helfen, Probleme zu beheben, die durch ein benutzerdefiniertes Image verursacht werden. Wenn Probleme auftreten, werden Sie möglicherweise aufgefordert, das Standardbild oder eines der Von Microsoft bereitgestellten Bilder zu verwenden, um festzustellen, ob das Problem für Ihr Bild spezifisch ist.
Herunterladen des Quellcodes
Die Schritte in diesem Artikel verwenden Codebeispiele aus dem Azureml-Beispiel-Repository . Führen Sie die folgenden Befehle aus, um das Repository zu klonen:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Initialisieren von Umgebungsvariablen
Um ein TensorFlow-Modell zu verwenden, benötigen Sie mehrere Umgebungsvariablen. Führen Sie die folgenden Befehle aus, um diese Variablen zu definieren:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Herunterladen eines TensorFlow-Modells
Laden Sie ein Modell herunter, und entpacken Sie ein Modell, das einen Eingabewert durch zwei dividiert, und fügt dem Ergebnis zwei hinzu:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Lokales Testen eines TF Serving-Images
Verwenden Sie Docker, um Ihr Image lokal zum Testen auszuführen:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Verfügbarkeits- und Bewertungsanforderungen an das Image senden
Senden Sie eine Liveness-Anforderung, um zu überprüfen, ob der Prozess innerhalb des Containers ausgeführt wird. Sie sollten den Antwortstatuscode 200 OK erhalten.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Senden Sie eine Bewertungsanforderung, um zu überprüfen, ob Sie Vorhersagen zu nicht bezeichneten Daten erhalten können:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Beenden des Images
Wenn Sie den Test lokal abgeschlossen haben, beenden Sie das Bild:
docker stop tfserving-test
Bereitstellen Ihres Onlineendpunkts in Azure
Führen Sie die Schritte in den folgenden Abschnitten aus, um Ihren Onlineendpunkt in Azure bereitzustellen.
Erstellen von YAML-Dateien für Ihren Endpunkt und die Bereitstellung
Sie können Ihre Cloudbereitstellung mithilfe von YAML konfigurieren. Um beispielsweise Ihren Endpunkt zu konfigurieren, können Sie eine YAML-Datei namens tfserving-endpoint.yml erstellen, die die folgenden Zeilen enthält:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
Zum Konfigurieren der Bereitstellung können Sie eine YAML-Datei namens tfserving-deployment.yml erstellen, die die folgenden Zeilen enthält:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
In den folgenden Abschnitten werden wichtige Konzepte zu den PARAMETERn YAML und Python erläutert.
Basisbild
environment Im Abschnitt in YAML oder im Environment Konstruktor in Python geben Sie das Basisimage als Parameter an. In diesem Beispiel wird docker.io/tensorflow/serving:latest als Wert für image verwendet.
Wenn Sie Ihren Container überprüfen, können Sie sehen, dass dieser Server ENTRYPOINT-Befehle verwendet, um ein Einstiegsskript zu starten. Dieses Skript verwendet Umgebungsvariablen wie MODEL_BASE_PATH und MODEL_NAME, und es macht Ports wie 8501 verfügbar. Diese Details beziehen sich alle auf diesen Server, und Sie können diese Informationen verwenden, um zu bestimmen, wie Ihre Bereitstellung definiert wird. Wenn Sie beispielsweise die MODEL_BASE_PATH Variablen und MODEL_NAME Umgebungsvariablen in Ihrer Bereitstellungsdefinition festlegen, verwendet TF Serving diese Werte, um den Server zu initiieren. Ebenso werden Benutzeranfragen bei Festlegung des Ports für jede Route auf 8501 in der Bereitstellungsdefinition ordnungsgemäß an den TF-Serving-Server weitergeleitet.
Dieses Beispiel basiert auf dem TF Serving-Fall. Sie können jedoch jeden Container verwenden, der aktiv bleibt und auf Anforderungen reagiert, die an Routen für Verfügbarkeit, Bereitschaft und Bewertung gesendet werden. Wenn Sie sehen möchten, wie Sie eine Dockerfile-Datei zum Erstellen eines Containers erstellen, können Sie sich auf andere Beispiele beziehen. Einige Server verwenden CMD Anweisungen anstelle von ENTRYPOINT Anweisungen.
Der Parameter „inference_config“
Im environment Abschnitt oder in der Environment Klasse ist inference_config ein Parameter. Gibt den Port und Pfad für drei Arten von Routen an: Verfügbarkeits-, Bereitschafts- und Bewertungsrouten. Der inference_config Parameter ist erforderlich, wenn Sie Ihren eigenen Container mit einem verwalteten Onlineendpunkt ausführen möchten.
Bereitschaftsrouten im Vergleich zu Liveness-Routen
Einige API-Server bieten eine Möglichkeit, den Status des Servers zu überprüfen. Es gibt zwei Arten von Routen, die Sie für die Überprüfung des Status angeben können:
- Liveness-Routen: Um zu überprüfen, ob ein Server läuft, verwenden Sie eine Liveness-Route.
- Bereitschaftsrouten : Um zu überprüfen, ob ein Server für die Arbeit bereit ist, verwenden Sie eine Bereitschaftsroute.
Im Kontext der Ableitung des maschinellen Lernens reagiert ein Server möglicherweise mit einem Statuscode von 200 OK auf eine Livenessanforderung, bevor ein Modell geladen wird. Der Server antwortet möglicherweise mit einem Statuscode von 200 OK auf eine Bereitschaftsanforderung, nachdem es das Modell in den Arbeitsspeicher geladen hat.
Weitere Informationen zu Verfügbarkeits- und Bereitschaftstests finden Sie unter Konfigurieren von Verfügbarkeits-, Bereitschafts- und Starttests.
Der von Ihnen ausgewählte API-Server bestimmt die Verfügbarkeits- und Bereitschaftsrouten. Sie identifizieren diesen Server in einem früheren Schritt, wenn Sie den Container lokal testen. In diesem Artikel verwendet die Beispielbereitstellung denselben Pfad für die Verfügbarkeits- und Bereitschaftsrouten, da TF Serving nur eine Verfügbarkeitsroute definiert. Weitere Möglichkeiten zum Definieren der Routen finden Sie in anderen Beispielen.
Bewertungsrouten
Der verwendete API-Server bietet eine Möglichkeit, die Nutzdaten zu empfangen, um daran zu arbeiten. Im Kontext der Machine Learning-Ableitung empfängt ein Server die Eingabedaten über eine bestimmte Route. Identifizieren Sie diese Route für Ihren API-Server, wenn Sie den Container lokal in einem früheren Schritt testen. Geben Sie diese Route als Bewertungsroute an, wenn Sie die zu erstellende Bereitstellung definieren.
Die erfolgreiche Erstellung der Bereitstellung aktualisiert auch den scoring_uri-Parameter des Endpunkts. Sie können diese Tatsache überprüfen, indem Sie den folgenden Befehl ausführen: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Suchen des eingebundenen Modells
Wenn Sie ein Modell als Onlineendpunkt bereitstellen, bindet Azure Machine Learning Ihr Modell in Ihren Endpunkt ein. Wenn das Modell bereitgestellt wird, können Sie neue Versionen des Modells bereitstellen, ohne ein neues Docker-Image erstellen zu müssen. Standardmäßig befindet sich ein Modell, das mit dem Namen "my-model " und "Version 1 " registriert ist, im folgenden Pfad innerhalb Ihres bereitgestellten Containers: /var/azureml-app/azureml-models/my-model/1.
Betrachten Sie z. B. die folgende Einrichtung:
- Verzeichnisstruktur „/azureml-examples/cli/endpoints/online/custom-container“ auf Ihrem lokalen Computer
- Modellname
half_plus_two
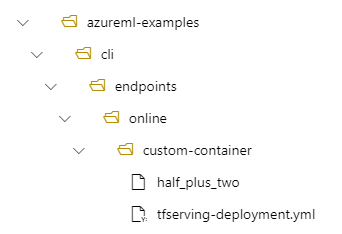
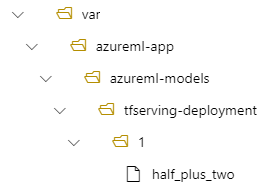
Angenommen, Ihre tfserving-deployment.yml Datei enthält die folgenden Zeilen im model Abschnitt. In diesem Abschnitt bezieht sich der name Wert auf den Namen, den Sie zum Registrieren des Modells in Azure Machine Learning verwenden.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Wenn Sie eine Bereitstellung erstellen, befindet sich Ihr Modell in diesem Fall unter dem folgenden Ordner: /var/azureml-app/azureml-models/tfserving-mounted/1.
Sie können optional Ihren model_mount_path Wert konfigurieren. Durch Anpassen dieser Einstellung können Sie den Pfad ändern, in dem das Modell bereitgestellt wird.
Wichtig
Der model_mount_path Wert muss ein gültiger absoluter Pfad in Linux (dem Betriebssystem des Containerimages) sein.
Wenn Sie den Wert ändern model_mount_path, müssen Sie auch die MODEL_BASE_PATH Umgebungsvariable aktualisieren. Setzen Sie MODEL_BASE_PATH auf denselben Wert wie model_mount_path, um eine fehlgeschlagene Bereitstellung aufgrund eines Fehlers zu vermeiden, dass der Basispfad nicht gefunden wird.
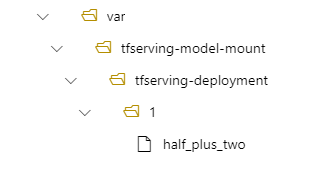
Sie können beispielsweise den model_mount_path Parameter zu Ihrer tfserving-deployment.yml Datei hinzufügen. Sie können den Wert in dieser MODEL_BASE_PATH Datei auch aktualisieren:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
In Ihrer Implementierung befindet sich Ihr Modell dann unter /var/tfserving-model-mount/tfserving-mounted/1. Es befindet sich nicht mehr unter „azureml-app/azureml-models“, sondern unter dem von Ihnen angegebenen Einbindungspfad:
Erstellen Sie Ihren Endpunkt und die Bereitstellung
Nachdem Sie ihre YAML-Datei erstellt haben, verwenden Sie den folgenden Befehl, um Ihren Endpunkt zu erstellen:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Verwenden Sie den folgenden Befehl, um Ihre Bereitstellung zu erstellen. Dieser Schritt kann einige Minuten dauern.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Aufrufen des Endpunkts
Wenn Die Bereitstellung abgeschlossen ist, stellen Sie eine Bewertungsanforderung an den bereitgestellten Endpunkt.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Löschen des Endpunkts
Wenn Sie Ihren Endpunkt nicht mehr benötigen, führen Sie den folgenden Befehl aus, um ihn zu löschen:
az ml online-endpoint delete --name tfserving-endpoint