Erstellen und Untersuchen eines Azure Machine Learning-Datasets mit Bezeichnungen
In diesem Artikel erfahren Sie, wie Sie die Datenbezeichnungen aus einem Azure Machine Learning-Datenbezeichnungsprojekt exportieren und in gängige Formate laden können, z. B. einen Pandas-Datenrahmen zum Untersuchen von Daten.
Was sind Datasets mit Bezeichnungen?
Azure Machine Learning-Datasets mit Bezeichnungen werden als bezeichnete Datasets bezeichnet. Diese spezifischen Datasets sind TabularDatasets mit einer dedizierten Bezeichnungsspalte und werden nur als Ausgabe von Azure Machine Learning-Datenbezeichnungsprojekten erstellt. Erstellen Sie ein Datenbeschriftungsprojekt für Bildbeschriftung oder Textbeschriftung. Machine Learning unterstützt Datenbezeichnungsprojekte für die Bildklassifizierung – mit mehreren Bezeichnungen oder mehreren Klassen – und die Objektidentifikation mit Begrenzungsrahmen.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
- Das Azure Machine Learning SDK für Python, oder greifen Sie auf Azure Machine Learning-Studio zu.
- Ein Machine Learning-Arbeitsbereich. Siehe Erstellen von Arbeitsbereichsressourcen.
- Zugriff auf ein Azure Machine Learning-Datenbezeichnungsprojekt. Wenn Sie kein Bezeichnungsprojekt haben, erstellen Sie zunächst ein Projekt für Bildbeschriftung oder Textbeschriftung.
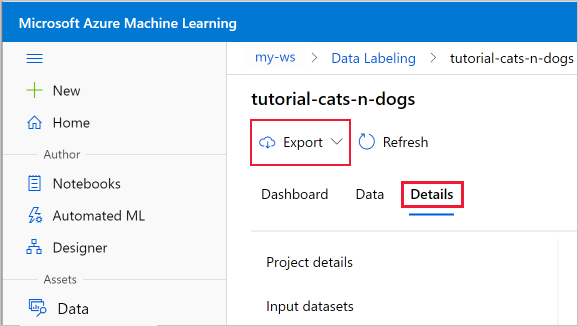
Exportieren von Datenbezeichnungen
Wenn Sie ein Datenbezeichnungsprojekt abschließen, können Sie die Bezeichnungsdaten aus einem Bezeichnungsprojekt exportieren. Auf diese Weise können Sie sowohl den Bezug zu den Daten als auch deren Bezeichnungen erfassen und sie im COCO-Format oder als Azure Machine Learning-Dataset exportieren.
Verwenden Sie die Schaltfläche Exportieren auf der Seite Projektdetails Ihres Beschriftungsprojekts.
COCO
Die COCO-Datei wird im Standardblobspeicher des Azure Machine Learning-Arbeitsbereichs in einem Ordner unter export/coco erstellt.
Hinweis
In Objekterkennungsprojekten werden die exportierten Werte „bbox: [x,y,Breite,Höhe]“ in der COCO-Datei normalisiert. Sie werden auf 1 skaliert. Beispiel: Ein Begrenzungsrahmen an der Position (10, 10) mit einer Breite von 30 Pixeln und einer Höhe von 60 Pixeln wird in einem Bild mit den Maßen 640 × 480 Pixel wie folgt bezeichnet: (0,015625, 0,02083, 0,046875, 0,125). Da die Koordinaten normalisiert werden, wird bei allen Bildern für „Breite“ und „Höhe“ der Wert „0,0“ angezeigt. Die tatsächliche Breite und Höhe können Sie mithilfe einer Python-Bibliothek wie OpenCV oder Pillow(PIL) abrufen.
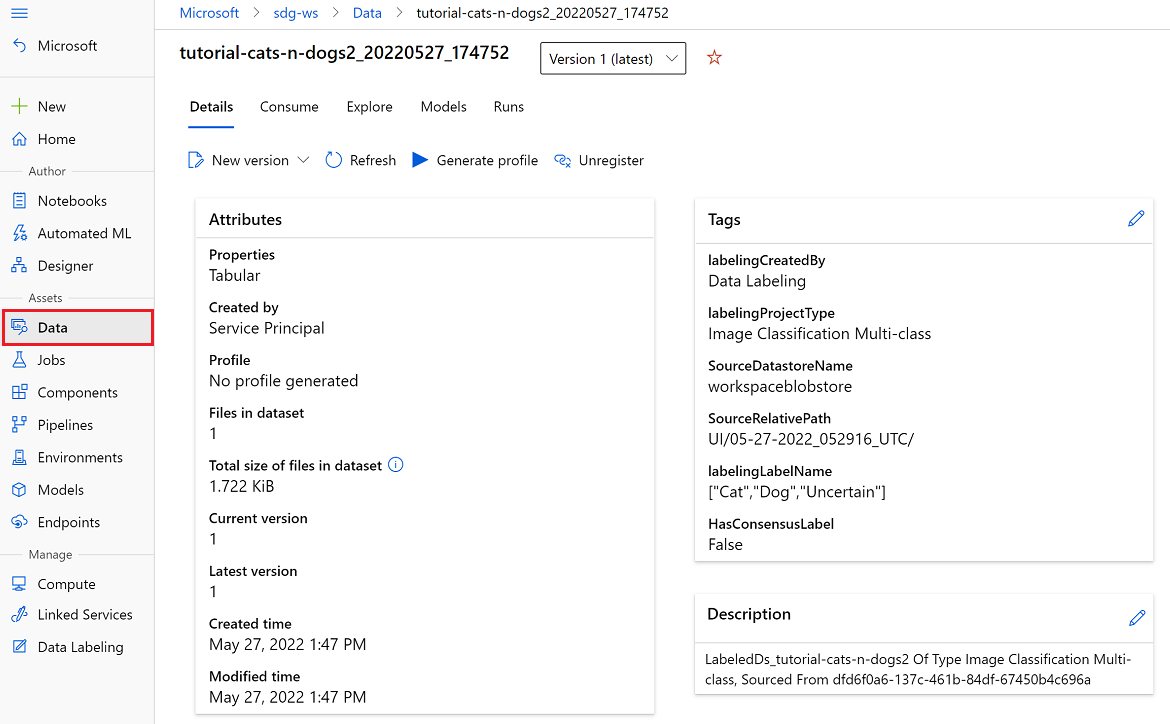
Azure Machine Learning-Dataset
Sie können im Abschnitt Datasets von Ihrem Azure Machine Learning-Studio auf das exportierte Azure Machine Learning-Dataset zugreifen. Die Seite mit Datasetdetails bietet auch Beispielcode für den Zugriff auf Ihre Beschriftungen aus Python.
Tipp
Nachdem Sie Ihre beschrifteten Daten in ein Azure Machine Learning-Dataset exportiert haben, können Sie mithilfe des automatisierten ML Modelle für maschinelles Sehen erstellen, die mit Ihren beschrifteten Daten trainiert werden. Informationen zum Einrichten von automatisiertem ML für das Trainieren von Modellen für maschinelles Sehen mit Python finden Sie hier.
Untersuchen bezeichneter Datasets über den Pandas-Datenrahmen
Laden Sie mit der Methode to_pandas_dataframe() aus der Klasse azureml-dataprep Ihre bezeichneten Datasets in einen Pandas-Datenrahmen, um beliebte Open-Source-Bibliotheken für die Untersuchung von Daten nutzen.
Installieren Sie die Klasse mit dem folgenden Shellbefehl:
pip install azureml-dataprep
Im folgenden Code ist das animal_labels-Dataset die Ausgabe eines zuvor im Arbeitsbereich gespeicherten Bezeichnungsprojekts.
Das exportierte Dataset ist ein TabularDataset.
GILT FÜR:  Python SDK azureml v1
Python SDK azureml v1
import azureml.core
from azureml.core import Dataset, Workspace
# get animal_labels dataset from the workspace
animal_labels = Dataset.get_by_name(workspace, 'animal_labels')
animal_pd = animal_labels.to_pandas_dataframe()
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
#read images from dataset
img = mpimg.imread(animal_pd['image_url'].iloc(0).open())
imgplot = plt.imshow(img)