Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In dieser Schnellstartanleitung erfahren Sie, wie Sie eine GeoCatalog-Ressource von Microsoft Planetary Computer Pro in Azure Batch verwenden, um geospatiale Daten skaliert zu verarbeiten.
Azure Batch ist ein cloudbasierter Auftragsplanungsdienst, mit dem Sie umfangreiche parallele und hochleistungsbasierte Computing-Workloads (HPC) ausführen können. Durch die Kombination von Azure Batch mit Microsoft Planetary Computer Pro können Sie:
- Verarbeiten großer Mengen geospatialer Daten parallel über mehrere Computeknoten hinweg
- Sichere Authentifizierung bei GeoCatalog-APIs mithilfe von verwalteten Identitäten
- Skalierung der Verarbeitungsleistung nach oben oder unten basierend auf Arbeitsauslastungsanforderungen
- Automatisieren von Geospatialdatenpipelinen ohne Verwaltung der Infrastruktur
In dieser Schnellstartanleitung wird veranschaulicht, wie Sie einen Batchpool mit einer vom Benutzer zugewiesenen verwalteten Identität einrichten, Berechtigungen für den Zugriff auf Ihr GeoCatalog konfigurieren und Aufträge ausführen, die die STAC-API abfragen.
Tipp
Eine Übersicht über Anwendungsentwicklungsoptionen mit Microsoft Planetary Computer Pro finden Sie unter Verbinden und Erstellen von Anwendungen mit Ihren Daten.
Voraussetzungen
Bevor Sie beginnen, stellen Sie sicher, dass Sie die folgenden Anforderungen erfüllen, um diese Schnellstartanleitung abzuschließen:
- Ein Azure-Konto mit einem aktiven Abonnement. Verwenden Sie den Link " Konto kostenlos erstellen".
- Eine Microsoft Planetary Computer Pro GeoCatalog-Ressource.
Ein Linux-Computer mit den folgenden installierten Tools:
- Azure CLI
-
perlPaket.
Erstellen eines Batch-Kontos
Erstellen Sie eine Ressourcengruppe:
az group create \
--name spatiobatchdemo \
--location uksouth
Erstellen eines Speicherkontos:
az storage account create \
--resource-group spatiobatchdemo \
--name spatiobatchstorage \
--location uksouth \
--sku Standard_LRS
Weisen Sie dem Storage Blob Data Contributor aktuellen Benutzer das Speicherkonto zu:
az role assignment create \
--role "Storage Blob Data Contributor" \
--assignee $(az account show --query user.name -o tsv) \
--scope $(az storage account show --name spatiobatchstorage --resource-group spatiobatchdemo --query id -o tsv)
Batchkonto erstellen:
az batch account create \
--name spatiobatch \
--storage-account spatiobatchstorage \
--resource-group spatiobatchdemo \
--location uksouth
Von Bedeutung
Stellen Sie sicher, dass Sie über genügend Kontingent verfügen, um einen Pool mit Computerknoten zu erstellen. Wenn Sie nicht über genügend Kontingent verfügen, können Sie eine Erhöhung anfordern, indem Sie die Anweisungen in der Azure Batch-Quoten- und Limits-Dokumentation befolgen.
Melden Sie sich beim neuen Batchkonto an, indem Sie den folgenden Befehl ausführen:
az batch account login \
--name spatiobatch \
--resource-group spatiobatchdemo \
--shared-key-auth
Nachdem Sie Ihr Konto bei Batch authentifiziert haben, verwenden nachfolgende az batch Befehle in dieser Sitzung das von Ihnen erstellte Batchkonto.
Erstellen einer vom Benutzer zugewiesenen verwalteten Identität:
az identity create \
--name spatiobatchidentity \
--resource-group spatiobatchdemo
Erstellen Sie einen Pool mit Computeknoten mithilfe des Azure-Portals:
- Navigieren Sie im Azure-Portal zu Ihrem Batchkonto, und wählen Sie "Pools" aus:

- Wählen Sie +Hinzufügen aus, um einen neuen Pool zu erstellen und "Benutzer zugewiesen" als Identität des Pools auszuwählen: Screenshot of the Azure portal showing the Add Pool page, where users can configure settings for a new pool, including identity, operating system, and VM size.
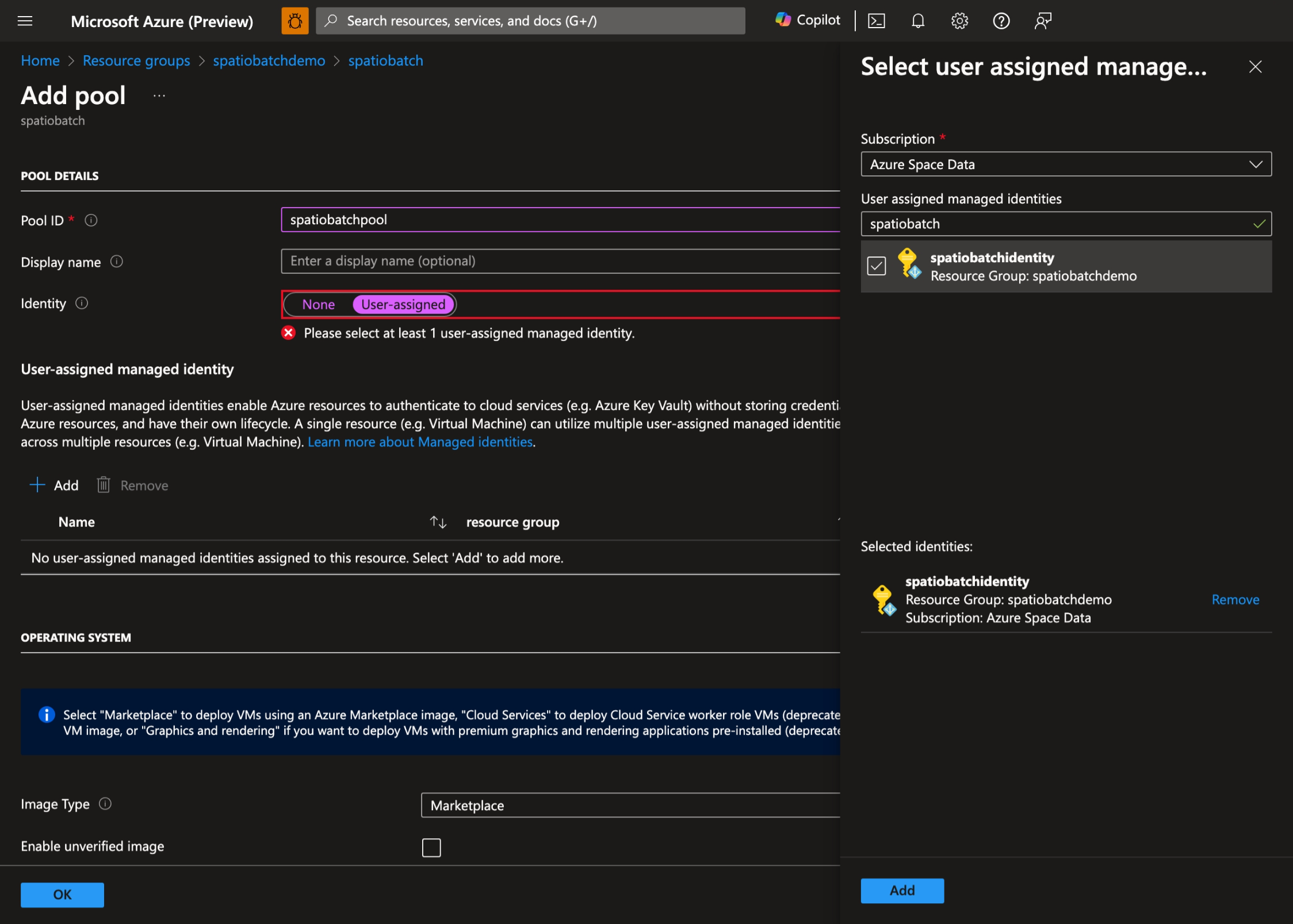
- Wählen Sie die zuvor erstellte vom Benutzer zugewiesene verwaltete Identität aus:
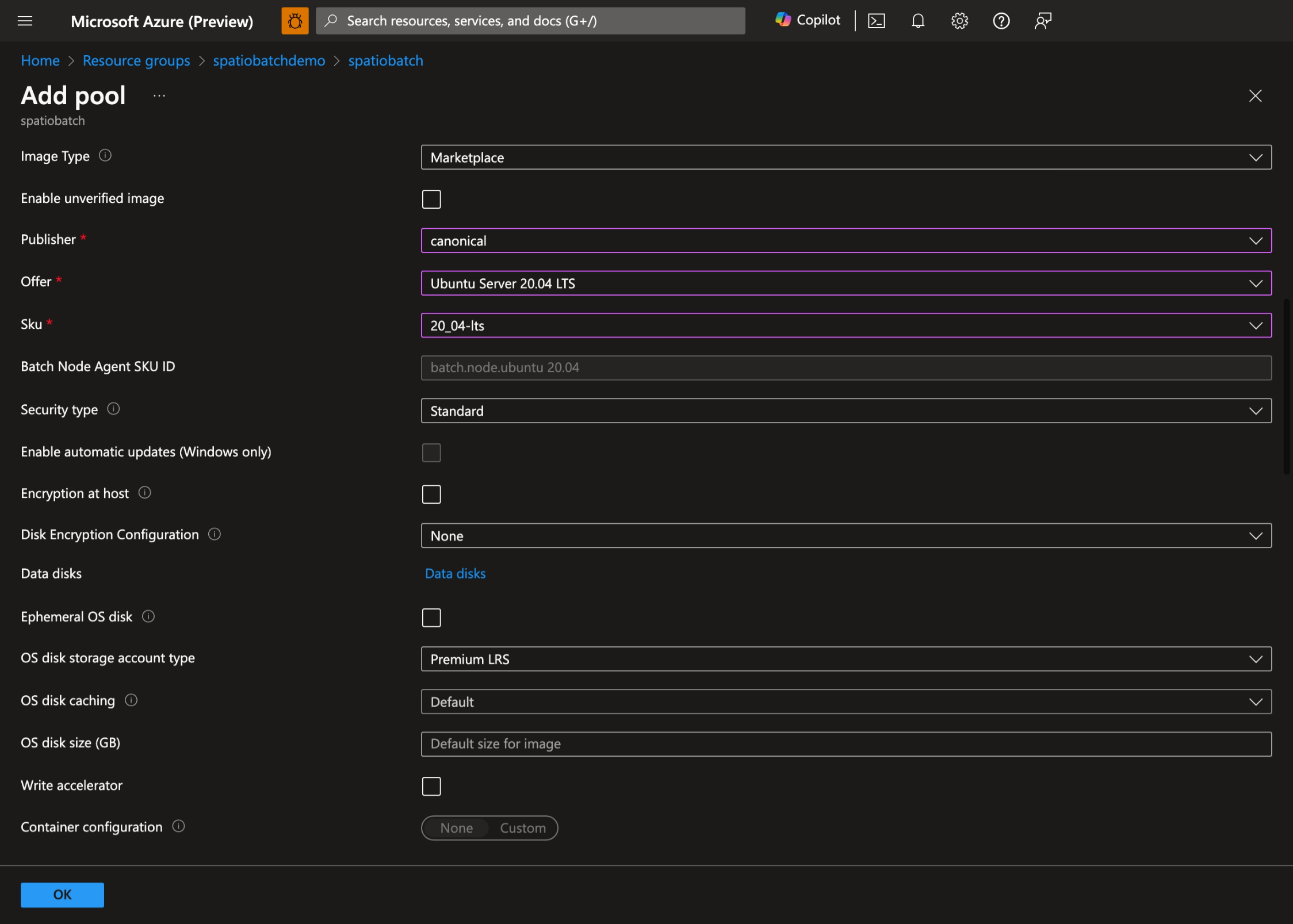
- Wählen Sie Ihr bevorzugtes Betriebssystem und ihre VM-Größe aus. In dieser Demo verwenden wir Ubuntu Server 20.04 LTS:
- Aktivieren Sie Startaufgabe , legen Sie die folgende Befehlszeilefest:
bash -c "apt-get update && apt-get install jq python3-pip -y && curl -sL https://aka.ms/InstallAzureCLIDeb | bash"und legen Sie die Erhöhungsebene auf Automatischer Poolbenutzer, Administrator fest: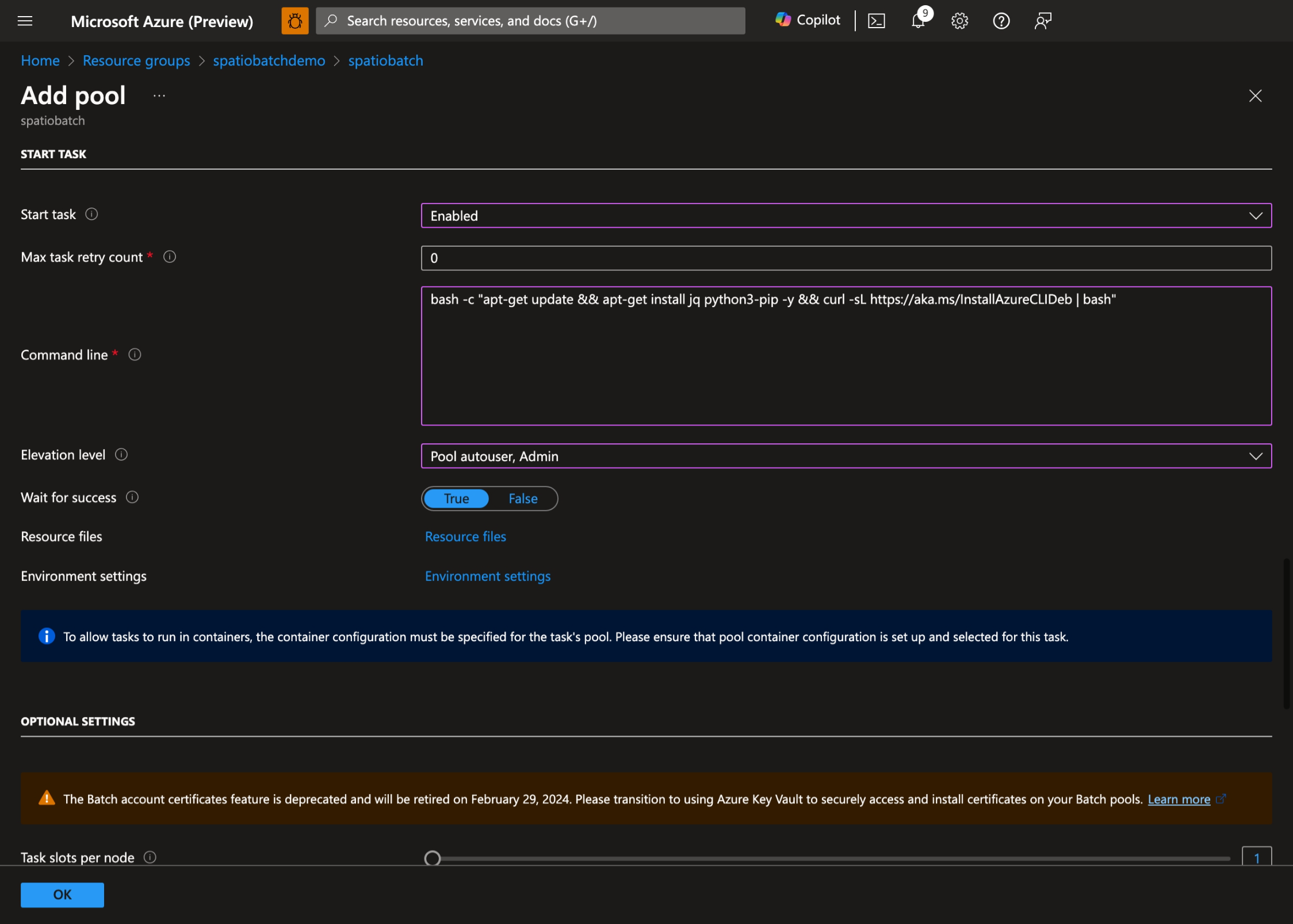
- Wählen Sie "OK" aus, um den Pool zu erstellen.




Zuweisen von Berechtigungen für die verwaltete Identität
Sie müssen den verwalteten Identitätszugriff auf den GeoCatalog bereitstellen. Wechseln Sie zu Ihrem GeoCatalog, wählen Sie unter Access Control (IAM) und dann "Rollenzuweisung hinzufügen" aus:

Wählen Sie die entsprechende Rolle basierend auf Ihren Anforderungen GeoCatalog Administrator oder GeoCatalog Readeraus, und wählen Sie "Weiter" aus:

Wählen Sie die von Ihnen erstellte verwaltete Identität und dann "Überprüfen+ Zuweisen" aus.

Vorbereiten des Batchauftrags
Erstellen Sie einen Container im Speicherkonto:
az storage container create \
--name scripts \
--account-name spatiobatchstorage
Laden Sie das Skript in den Container hoch:
az storage blob upload \
--container-name scripts \
--file src/task.py \
--name task.py \
--account-name spatiobatchstorage
Ausführen der Batch-Aufträge
In dieser Schnellstartanleitung gibt es zwei Beispiele: ein Python-Skript und ein Bash-Skript. Sie können eine der Beiden verwenden, um einen Auftrag zu erstellen.
Python-Skriptauftrag
Führen Sie zum Ausführen des Python-Skriptauftrags die folgenden Befehle aus:
geocatalog_url="<geocatalog url>"
token_expiration=$(date -u -d "30 minutes" "+%Y-%m-%dT%H:%M:%SZ")
python_task_url=$(az storage blob generate-sas --account-name spatiobatchstorage --container-name scripts --name task.py --permissions r --expiry $token_expiration --auth-mode login --as-user --full-uri -o tsv)
cat src/pythonjob.json | perl -pe "s,##PYTHON_TASK_URL##,$python_task_url,g" | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Der Python-Auftrag führt das folgende Python-Skript aus:
import json
from os import environ
import requests
from azure.identity import DefaultAzureCredential
MPCPRO_APP_ID = "https://geocatalog.spatio.azure.com"
credential = DefaultAzureCredential()
access_token = credential.get_token(f"{MPCPRO_APP_ID}/.default")
geocatalog_url = environ["GEOCATALOG_URL"]
response = requests.get(
f"{geocatalog_url}/stac/collections",
headers={"Authorization": "Bearer " + access_token.token},
params={"api-version": "2025-04-30-preview"},
)
print(json.dumps(response.json(), indent=2))
Welche DefaultAzureCredential verwendet, um sich mit der verwalteten Identität zu authentifizieren und die Sammlungen aus dem GeoCatalog abzurufen. Führen Sie den folgenden Befehl aus, um die Ergebnisse des Auftrags abzurufen:
az batch task file download \
--job-id pythonjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Bash-Auftrag
Führen Sie zum Ausführen des Bash-Skriptauftrags die folgenden Befehle aus:
geocatalog_url="<geocatalog url>"
cat src/bashjob.json | perl -pe "s,##GEOCATALOG_URL##,$geocatalog_url,g" | az batch job create --json-file /dev/stdin
Der Bash-Auftrag führt das folgende Bash-Skript aus:
az login --identity --allow-no-subscriptions > /dev/null
token=$(az account get-access-token --resource https://geocatalog.spatio.azure.com --query accessToken --output tsv)
curl --header \"Authorization: Bearer $token\" $GEOCATALOG_URL/stac/collections | jq
Welche az login --identity verwendet, um sich mit der verwalteten Identität zu authentifizieren und die Sammlungen aus dem GeoCatalog abzurufen. Führen Sie den folgenden Befehl aus, um die Ergebnisse des Auftrags abzurufen:
az batch task file download \
--job-id bashjob1 \
--task-id task1 \
--file-path "stdout.txt" \
--destination /dev/stdout
Verwandte Inhalte
- Verbinden und Erstellen von Anwendungen mit Ihren Daten
- Konfigurieren der Anwendungsauthentifizierung für Microsoft Planetary Computer Pro
- Erstellen einer Webanwendung mit Microsoft Planetary Computer Pro
- Verwenden des Microsoft Planetary Computer Pro Explorer
- Verwalten des Zugriffs auf Microsoft Planetary Computer Pro
- Konfigurieren verwalteter Identitäten in Azure Batch-Pools
- Kopieren von Anwendungen und Daten in Poolknoten
- Bereitstellung von Anwendungen auf Computeknoten mit Batch-Anwendungspaketen
- Erstellen und Verwenden von Ressourcendateien