Verfügbarkeit von SAP HANA innerhalb einer Azure-Region
In diesem Artikel werden mehrere Verfügbarkeitsszenarien für SAP HANA innerhalb einer Azure-Region beschrieben. Azure bietet viele Regionen auf der ganzen Welt. Die Liste mit Azure-Regionen finden Sie unter Azure-Regionen. Für die Bereitstellung von SAP HANA auf VMs in einer Azure-Region bietet Microsoft die Bereitstellung einer einzelnen VM mit einer HANA-Instanz. Für eine höhere Verfügbarkeit können Sie zwei VMs mit zwei HANA-Instanzen bereitstellen, indem Sie entweder eine flexible Skalierungsgruppe mit FD=1, Verfügbarkeitszonen oder eine Verfügbarkeitsgruppe verwenden, die die HANA-Systemreplikation für die Verfügbarkeit verwendet.
Azure-Regionen, die Verfügbarkeitszonen bereitstellen, umfassen mehrere Rechenzentren, die jeweils über eine eigene Stromversorgung, Kühlung und Netzwerkinfrastruktur verfügen. Der Zweck, verschiedene Zonen in einer einzelnen Azure-Region anzubieten, besteht darin, die Bereitstellung von Anwendungen in zwei oder drei verfügbaren Verfügbarkeitszonen zu ermöglichen. Durch die Verteilung Ihrer Anwendungsbereitstellung über Zonen hinweg würden alle Energie- oder Netzwerkprobleme, die sich auf eine bestimmte Infrastruktur aus Azure-Verfügbarkeitszonen auswirken, die Funktionalität Ihrer Anwendung innerhalb der Azure-Region nicht vollständig unterbrechen. Es kann zwar zu reduzierter Kapazität kommen, z. B. durch den potenziellen Verlust von VMs in einer Zone, die VMs in den verbleibenden Zonen würden jedoch ohne Unterbrechung weiter funktionieren. Um zwei HANA-Instanzen auf separaten VMs in verschiedenen Zonen einzurichten, haben Sie die Möglichkeit, VMs mithilfe der Bereitstellungsoption mit einer flexiblen Skalierungsgruppe mit FD=1 oder Verfügbarkeitszonen bereitzustellen.
Für eine höhere Verfügbarkeit innerhalb einer Region wird empfohlen, zwei VMs mit zwei HANA-Instanzen mithilfe einer Verfügbarkeitsgruppe bereitzustellen. Eine Azure-Verfügbarkeitsgruppe ist eine Funktion zur logischen Gruppierung, mit der sichergestellt werden kann, dass die in der Verfügbarkeitsgruppe enthaltenen VM-Ressourcen voneinander fehlerisoliert sind, wenn sie in einem Azure-Rechenzentrum bereitgestellt werden. Azure stellt sicher, dass die virtuellen Computer innerhalb einer Verfügbarkeitsgruppe auf mehrere physische Server, Compute-Racks, Speichereinheiten und Netzwerkswitches verteilt werden. Diese Konfiguration wird in einigen Azure-Dokumentationen alternativ als Platzierungen in verschiedene Update- und Fehlerdomänen bezeichnet. Diese Platzierungen erfolgen normalerweise in einem Azure-Rechenzentrum. Falls Probleme an Stromversorgungsquellen und/oder Netzwerken das Rechenzentrum beeinträchtigen, wäre Ihre gesamte Kapazität in einer Azure-Region betroffen.
Bei der Platzierung von Rechenzentren, die Azure-Verfügbarkeitszonen darstellen, wird ein Mittelweg zwischen akzeptablen Netzwerklatenzen zwischen Diensten, die in unterschiedlichen Zonen bereitgestellt werden, und einer Entfernung zwischen den Rechenzentren verfolgt. Damit soll im Idealfall erreicht werden, dass die Stromversorgung, das Netzwerk und die Infrastruktur für alle Verfügbarkeitszonen in dieser Region vor Naturkatastrophen geschützt bleiben. Doch angesichts des gewaltigen Ausmaßes, das sich bei Naturkatastrophen abgezeichnet hat, können Verfügbarkeitszonen nicht immer die von Ihnen gewünschte Verfügbarkeit innerhalb einer Region bieten. Denken Sie daran, als Hurrikan Maria am 20. September 2017 die Insel Puerto Rico durchzog. Der Hurrikan richtete fast einen kompletten Stromausfall auf der etwa 150 km langen Insel an.
Szenario mit einer einzigen VM
In einem Szenario mit einer einzigen VM erstellen Sie eine Azure-VM für die SAP HANA-Instanz. Sie verwenden Azure Storage Premium zum Hosten des Betriebssystemdatenträgers und aller Datenträger. Die SLA von Azure mit einer Betriebszeit von 99,9 % und die SLAs anderer Azure-Komponenten reichen für Sie aus, um Ihren Verfügbarkeits-SLAs für Ihre Kunden gerecht zu werden. In diesem Szenario besteht kein Bedarf dafür, eine Azure-Verfügbarkeitsgruppe für VMs zu nutzen, die die DBMS-Ebene ausführen. In diesem Szenario kommen zwei verschiedene Features zum Einsatz:
- Automatischer Neustart von Azure-VMs (auch als „Azure-Dienstreparatur“ bezeichnet)
- Automatischer Neustart von SAP HANA
Die Funktion „Automatischer Neustart von Azure-VMs“ bzw. „Dienstreparatur“ funktioniert in Azure auf zwei Ebenen:
- Der Azure-Serverhost überprüft die Integrität einer VM, die auf dem Serverhost gehostet wird.
- Der Azure Fabric Controller überwacht die Integrität und Verfügbarkeit des Serverhosts.
Bei jeder VM, die von einem Azure-Serverhost gehostet wird, wird die Integrität der gehosteten VMs durch eine Funktion zur Integritätsprüfung überwacht. Falls eine VM in einen fehlerhaften Zustand wechseln sollte, kann ein VM-Neustart durch den Azure-Host-Agent initiiert werden, der die Integrität der VM überprüft. Der Fabric Controller überwacht die Integrität des Hosts durch Überprüfung zahlreicher verschiedener Parameter, die auf Probleme mit der Hosthardware hinweisen könnten. Zudem überprüft er den Zugriff auf den Host über das Netzwerk. Ein Hinweis auf Probleme mit dem Host kann zu folgenden Ereignissen führen:
- Ein Neustart des Hosts und der VMs, die auf dem Host ausgeführt wurden, wird ausgelöst, wenn der Host einen fehlerhaften Zustand signalisiert.
- Wenn sich der Host nach erfolgreichem Neustart nicht in einem fehlerfreien Zustand befindet, wird eine erneute Bereitstellung der VMs, die sich ursprünglich auf dem nun fehlerhaften Knoten befanden, auf einem fehlerfreien Hostserver eingeleitet. In diesem Fall wird der ursprüngliche Host als fehlerhaft gekennzeichnet. Er wird erst für weitere Bereitstellungen verwendet, wenn er gelöscht oder ersetzt wird.
- Wenn der fehlerhafte Host während des Neustartprozesses Probleme aufweist, wird ein sofortiger Neustart der VMs auf einem fehlerfreien Host ausgelöst.
Durch die von Azure bereitgestellte Host- und VM-Überwachung werden Azure-VMs, bei denen Probleme mit dem Host auftreten, automatisch auf einem fehlerfreien Azure-Host neu gestartet.
Wichtig
Die Azure-Dienstreparatur startet Linux-VMs nicht neu, wenn sich das Gastbetriebssystem in einem Kernel Panic-Status befindet. Die Standardeinstellungen der häufig verwendeten Linux-Versionen starten VMs oder Server nicht automatisch neu, wenn der Linux-Kernel im Panic-Status ist. Stattdessen sorgt die Standardeinstellung dafür, dass das Betriebssystem im Kernel Panic-Status verbleibt, um einen Kernel-Debugger für die Analyse anzufügen. Azure berücksichtigt dieses Verhalten, indem VMs mit dem Gastbetriebssystem in einem solchen Zustand nicht automatisch neu gestartet werden. Es wird davon ausgegangen, dass solche Vorkommnisse äußerst selten sind. Sie können das Standardverhalten außer Kraft setzen, um einen Neustart der VM zu ermöglichen. Aktivieren Sie zum Ändern des Standardverhaltens den Parameter „kernel.panic“ in „/etc/sysctl.conf“. Die Zeit, die Sie für diesen Parameter festlegen, wird in Sekunden angegeben. Es wird allgemein empfohlen, 20 bis 30 Sekunden zu warten, bevor der Neustart mit diesem Parameter ausgelöst wird. Weitere Informationen finden Sie unter sysctl.conf.
Das zweite Feature, auf das Sie in einem solchen Szenario angewiesen sind, betrifft den Vorgang, bei dem der auf einer neu gestarteten VM ausgeführte HANA-Dienst nach dem Neustart der VM automatisch gestartet wird. Sie können das Feature Automatischer Neustart des HANA-Diensts über die Watchdogdienste der verschiedenen HANA-Dienste konfigurieren.
Sie können dieses Szenario mit einer einzelnen VM durch Hinzufügen eines inaktiven Failoverknotens zu einer SAP HANA-Konfiguration optimieren. In der SAP HANA-Dokumentation wird diese Einrichtung als Automatisches Hostfailover bezeichnet. Diese Konfiguration kann bei einer lokalen Bereitstellung sinnvoll sein, bei der die Serverhardware begrenzt ist und Sie für eine Gruppe von Produktionshosts einen einzelnen Serverknoten als Knoten für das automatische Hostfailover reservieren. In Azure, in dem die zugrunde liegende Infrastruktur von Azure einen fehlerfreien Zielserver für einen erfolgreichen Neustart einer VM bereitstellt, ist die Bereitstellung des SAP HANA-Szenarios mit automatischem Hostfailover nicht sinnvoll. Wegen der Azure-Dienstreparatur gibt es keine Referenzarchitektur, in der das automatische Hostfailover von HANA für einen Standbyknoten vorgesehen ist.
Sonderfall von SAP HANA-Konfigurationen mit horizontaler Skalierung in Azure
Weitere Informationen zu Hochverfügbarkeitsarchitekturen basierend auf Standbyknoten oder der HANA-Systemreplikation finden Sie in den folgenden Dokumenten. In Fällen, in denen keine Hochverfügbarkeit mit Standbyknoten oder der HANA-Systemreplikation in den SAP HANA-Skalierungskonfigurationen verwendet wird, können Sie sich auf die Funktionen der Dienstreparatur von Azure-VMs und dem automatischen Neustart der SAP HANA-Instanz verlassen, sobald die VM wieder betriebsbereit ist.
- Red Hat Enterprise Linux
- SUSE Linux Enterprise Server
Verfügbarkeitsszenarien mit zwei verschiedenen VMs
Um die Verfügbarkeit des HANA-Systems innerhalb einer bestimmten Region sicherzustellen, können Sie zwei VMs in den Verfügbarkeitszonen der Region oder innerhalb der Region konfigurieren. Dazu können Sie die VMs mit einer der Bereitstellungsoptionen mit flexibler Skalierungsgruppe, mit Verfügbarkeitszonen oder mit Verfügbarkeitsgruppen konfigurieren. Die grundlegende Einrichtung in Azure würde wie folgt aussehen:
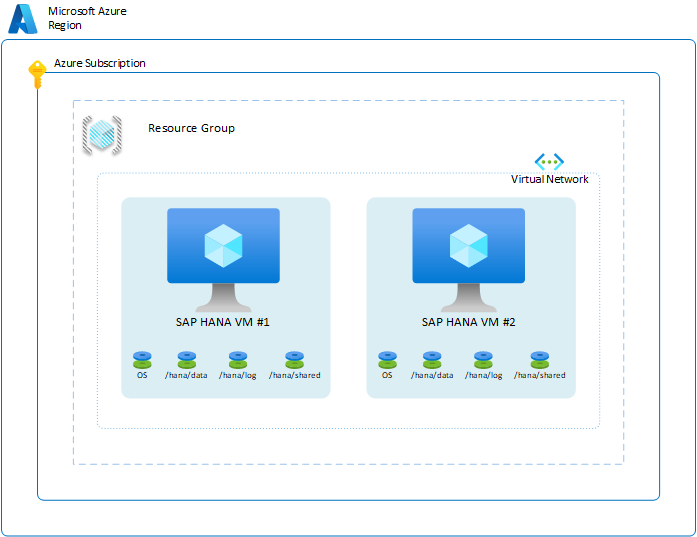
Um die verschiedenen SAP HANA-Verfügbarkeitsszenarien zu veranschaulichen, wurden einige Ebenen in der Abbildung ausgelassen. In der Abbildung werden nur die Ebenen dargestellt, die VMs, Hosts, Verfügbarkeitsgruppen und Azure-Regionen zeigen. Instanzen, Ressourcengruppen und Abonnements virtueller Azure-Netzwerke spielen bei den in diesem Abschnitt beschriebenen Szenarien keine Rolle.
Replizieren von Sicherungen auf einen zweiten virtuellen Computer
Eine der elementarsten Einrichtungen ist die Verwendung von Sicherungen. Dies ist insbesondere dann sinnvoll, wenn Sie Transaktionsprotokollsicherungen von einer VM für eine andere Azure-VM bereitstellen. Sie können den Azure Storage-Typ auswählen. Bei diesem Setup sind Sie für die Skripterstellung der Kopie der geplanten Sicherungen verantwortlich, die auf der ersten VM für die zweite VM durchgeführt werden. Wenn Sie die Instanzen der zweiten VM verwenden müssen, müssen Sie die vollständigen inkrementellen bzw. differenziellen Sicherungen von Transaktionsprotokollen am erforderlichen Zeitpunkt wiederherstellen.
Die Architektur sieht wie folgt aus:
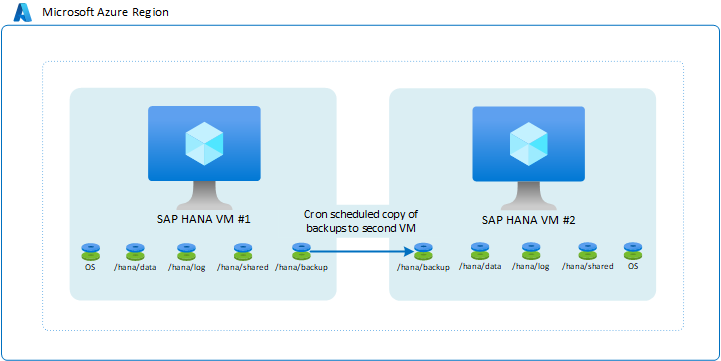
Dieses Setup ist nicht geeignet, um hervorragende Zeiten hinsichtlich der Recovery Point Objective (RPO) und Recovery Time Objective (RTO) zu erzielen. Insbesondere bei den RTO-Zeiten müssen Einbußen in Kauf genommen werden, da die gesamte Datenbank mit den kopierten Sicherungen vollständig wiederhergestellt werden muss. Dieses Setup ist jedoch nützlich, um nach einer unbeabsichtigten Datenlöschung in den Hauptinstanzen Wiederherstellungen durchzuführen. Mit dieser Einrichtung können Sie jederzeit eine Wiederherstellung zu einem bestimmten Zeitpunkt durchführen, die Daten extrahieren und die gelöschten Daten in Ihre Hauptinstanz importieren. Daher kann es sinnvoll sein, eine solche Methode zur Sicherungskopie in Kombination mit anderen Hochverfügbarkeitsfunktionen zu verwenden.
Während des Kopiervorgangs der Sicherungen, können Sie möglicherweise eine kleineren VM als die Haupt-VM verwenden, auf der die SAP HANA-Instanz ausgeführt wird. Denken Sie daran, dass Sie eine kleinere Anzahl von VHDs an kleinere VMs anfügen können. Informationen zu den Grenzwerte für die einzelnen VM-Typen finden Sie unter Größen für virtuelle Linux-Computer in Azure.
SAP HANA-Systemreplikation ohne automatisches Failover
Bei den Szenarien, die in diesem Abschnitt beschrieben werden, wird die SAP HANA-Replikation verwendet. Die SAP-Dokumentation finden Sie unter Systemreplikation. Szenarien ohne automatisches Failover sind für Konfigurationen innerhalb einer Azure-Region unüblich. Bei einer Konfiguration ohne automatisches Failover, bei der jedoch ein Pacemaker-Setup vermieden wird, müssen Sie die Überwachung und das Failover manuell durchführen. Da dies auch mit Aufwand verbunden ist, verlassen sich die meisten Kunden stattdessen auf die Azure-Dienstreparatur. In einigen Grenzfällen kann eine Konfiguration dieser Art bei Ausfallszenarien Abhilfe leisten. In anderen Fällen sollte ein Kunde eventuell eine größere Effizienz realisieren.
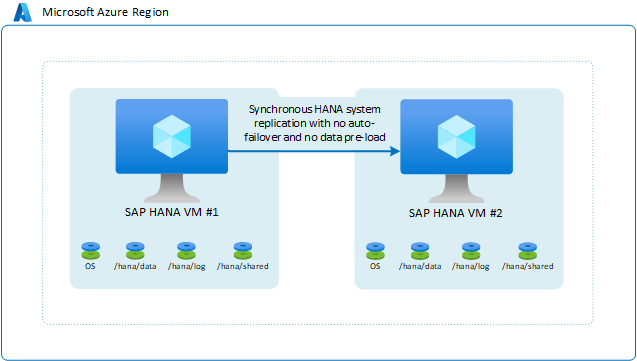
SAP HANA-Systemreplikation ohne automatisches Failover und ohne Laden von Daten im Voraus
In diesem Szenario verwenden Sie die SAP HANA-Systemreplikation zum synchronen Verschieben von Daten, um eine RPO von 0 zu erzielen. Auf der anderen Seite benötigen Sie eine RTO, die lang genug ist, dass ein Failover oder das Laden von Daten im Voraus in den HANA-Instanzcache überflüssig ist. In diesem Fall ist es möglich, Ihre Konfiguration durch die folgenden Aktionen weiter zu optimieren:
- Führen Sie eine andere SAP HANA-Instanz auf der zweiten VM aus. Die SAP HANA-Instanz auf der zweiten VM belegt den Großteil des VM-Speichers. Bei einem Failover auf die zweite VM müssen Sie die aktive SAP HANA-Instanz herunterfahren, die die Daten vollständig in der zweiten VM geladen hat, damit die replizierten Daten in den Cache der Ziel-HANA-Instanz auf der zweiten VM geladen werden können.
- Verwenden Sie eine kleinere VM als zweite VM. Wenn ein Failover auftritt, müssen Sie vor dem manuellen Failover einen zusätzlichen Schritt durchführen. Bei diesem Schritt ändern Sie die Größe der VM in die der Quell-VM.
Das Szenario sieht folgendermaßen aus:
Hinweis
Selbst wenn Sie Daten im Replikationsziel für das HANA-System nicht im Voraus laden, benötigen Sie mindestens 64 GB Arbeitsspeicher. Sie benötigen zusätzlich zu den 64 GB auch genügend Arbeitsspeicher, um die Rowstore-Daten im Arbeitsspeicher der Zielinstanz beizubehalten.
SAP HANA-Systemreplikation ohne automatisches Failover und mit Laden von Daten im Voraus
In diesem Szenario werden Daten, die auf der zweiten VM in der HANA-Instanz repliziert wurden, im Voraus geladen. Hierdurch fallen die beiden Vorteile weg, dass Daten nicht im Voraus geladen werden müssen. In diesem Fall können Sie kein weiteres SAP HANA-System auf der zweiten VM ausführen. Zudem kann auch keine kleinere VM-Größe verwendet werden. Kunden implementieren dieses Szenario daher nur selten.
SAP HANA-Systemreplikation mit automatischem Failover
In der standardmäßigen und am häufigsten verwendeten Verfügbarkeitskonfiguration innerhalb einer Azure-Region wird bei zwei Azure-VMs, auf denen Linux mit Hochverfügbarkeitspaketen ausgeführt wird, ein Failovercluster definiert. Der Linux-Cluster mit Hochverfügbarkeit basiert auf dem Pacemaker-Framework unter SLES oder RHEL mit einemfencing device SLES oder RHEL als Beispiel.
Aus SAP HANA-Sicht wird der verwendete Replikationsmodus synchronisiert, und ein automatisches Failover wird konfiguriert. Auf der zweiten VM agiert die SAP HANA-Instanz als Hot Standby-Knoten. Der Standby-Knoten empfängt einen synchronen Datenstrom von Änderungsdatensätzen aus der primären SAP HANA-Instanz. Da Transaktionen von der Anwendung auf dem primären HANA-Knoten committed werden, wartet dieser mit der Bestätigung des Commits in der Anwendung, bis der sekundäre SAP HANA-Knoten den Commitdatensatz bestätigt hat. SAP HANA bietet zwei verschiedene Modi für die synchrone Replikation. Einzelheiten und eine Beschreibung zu den Unterschieden zwischen diesen beiden Modi für die synchrone Replikation finden Sie im Artikel Replication modes for SAP HANA System Replication (Replikationsmodi für die SAP HANA-Systemreplikation).
Die allgemeine Konfiguration sieht wie folgt aus:
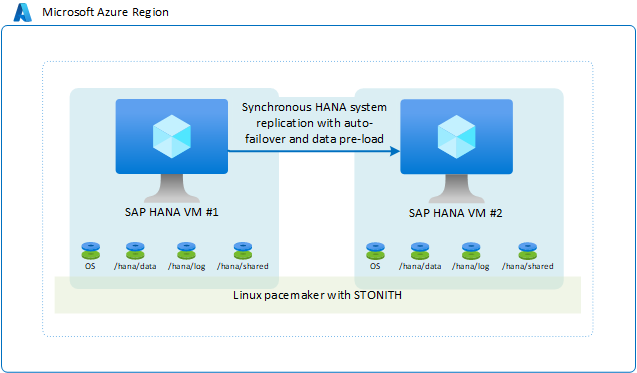
Diese Lösung könnte für Sie geeignet sein, da Sie hierüber ein RPO von 0 und kurze RTO-Zeiten erzielen. Konfigurieren Sie die SAP HANA-Clientkonnektivität so, dass die SAP HANA-Clients zum Herstellen einer Verbindung mit der HANA-Systemreplikationskonfiguration die virtuelle IP-Adresse verwenden. Durch eine solche Konfiguration entfällt die Notwendigkeit, die Anwendung bei einem Failover auf den sekundären Knoten erneut zu konfigurieren. Bei diesem Szenario müssen die Azure-VM-SKUs für die primären und sekundären VMs identisch sein.
Nächste Schritte
Eine ausführliche Anleitung zum Einrichten dieser Konfigurationen in Azure finden Sie in folgenden Artikeln:
- Hochverfügbarkeit von SAP HANA auf virtuellen Azure-Computern (VMs)
- Your SAP on Azure – Part 4 – High Availability for SAP HANA using System Replication (SAP in Azure – Teil 4: Hochverfügbarkeit für SAP HANA durch Systemreplikation)
Weitere Informationen zur SAP HANA-Verfügbarkeit in Azure-Regionen finden Sie im folgenden Artikel:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für