Schnellstart: Erstellen eines Skillsets im Azure-Portal
In diesem Schnellstart erfahren Sie, wie ein Skillset in Azure KI-Suche optische Zeichenerkennung (Optical Character Recognition, OCR), Bildanalyse, Spracherkennung, Textübersetzung und Entitätserkennung hinzufügt, um im Text durchsuchbare Inhalte in einem Suchindex zu erstellen.
Sie können den Datenimport-Assistenten im Azure-Portal ausführen, um Skills anzuwenden, die Textinhalte während der Indizierung erstellen und transformieren. Die Eingaben sind Ihre Rohdaten, in der Regel Blobs in Azure Storage. Die Ausgabe ist ein durchsuchbarer Index mit KI-generiertem Bildtext, Beschriftungen und Entitäten. Mit dem Such-Explorer können generierte Inhalte im Portal abgefragt werden.
Zur Vorbereitung erstellen Sie einige Ressourcen und laden Beispieldateien hoch, bevor Sie den Assistenten ausführen.
Voraussetzungen
Bevor Sie beginnen können, müssen die folgenden Voraussetzungen erfüllt werden:
Ein Azure-Konto mit einem aktiven Abonnement. Sie können kostenlos ein Konto erstellen.
Azure AI Search. Erstellen Sie einen Dienst, oder suchen Sie nach einem vorhandenen Dienst. Für diesen Schnellstart können Sie einen kostenlosen Dienst verwenden.
Azure Storage-Konto mit Blob Storage.
Hinweis
Diese Schnellstartanleitung verwendet Azure KI Services für die KI-Transformationen. Da die Workload so klein ist, wird Azure KI Services im Hintergrund für die kostenlose Verarbeitung von bis zu 20 Transaktionen genutzt. Sie können diese Übung abschließen, ohne eine Azure KI-Ressource für mehrere Dienste erstellen zu müssen.
Einrichten Ihrer Daten
In den folgenden Schritten richten Sie einen Blobcontainer in Azure Storage ein, um heterogene Inhaltsdateien zu speichern.
Laden Sie die Beispieldaten herunter, die aus einem kleinen Satz Dateien verschiedener Typen bestehen.
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an.
Erstellen Sie ein Azure Storage-Konto, oder suchen Sie nach einem vorhandenen Konto.
Es muss sich in der gleichen Region wie Azure AI Search befinden, um Bandbreitengebühren zu vermeiden.
Wählen Sie „StorageV2 (universell V2)“ aus.
Öffnen Sie im Azure-Portal Ihre Azure Storage-Seite, und erstellen Sie einen Container. Sie können die Standardzugriffsebene verwenden.
Wählen Sie im Container Hochladen aus, um die Beispieldateien hochzuladen. Beachten Sie, dass Ihnen ein breites Spektrum an Inhaltstypen zur Verfügung steht – einschließlich Bildern und Anwendungsdateien, die in ihren nativen Formaten für die Volltextsuche nicht geeignet sind.
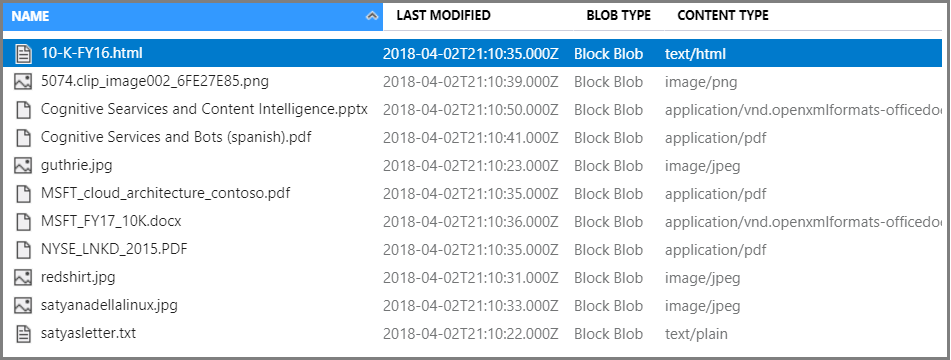
Jetzt können Sie zum Datenimport-Assistenten wechseln.
Ausführen des Datenimport-Assistenten
Melden Sie sich mit Ihrem Azure-Konto beim Azure-Portal an.
Suchen Sie Ihren Suchdienst und wählen Sie auf der Übersichtsseite auf der Befehlsleiste Daten importierenaus, um in vier Schritten durchsuchbare Inhalte zu erstellen.

Schritt 1: Erstellen einer Datenquelle
Wählen Sie unter Mit Ihren Daten verbinden die Option Azure Blob Storage aus.
Wählen Sie eine vorhandene Verbindung mit dem Speicherkonto und wählen Sie den von Ihnen erstellten Container aus. Geben Sie der Datenquelle einen Namen, und verwenden Sie für alles andere die Standardwerte.
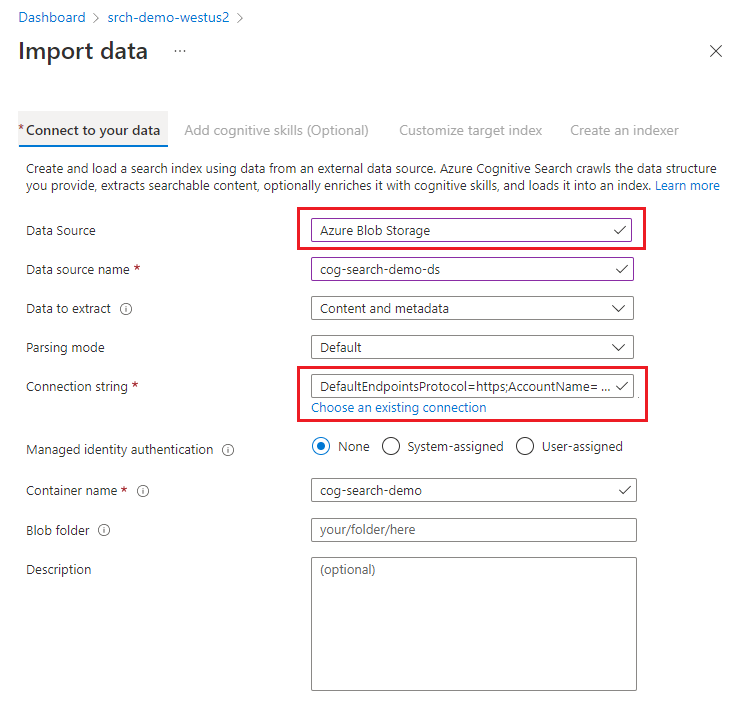
Wechseln Sie zur nächsten Seite.
Wenn Sie „Fehler beim Erkennen des Indexschemas aus der Datenquelle“ angezeigt bekommen, kann der Indexer, der den Assistenten mit Energie versorgt, keine Verbindung mit Ihrer Datenquelle herstellen. Höchstwahrscheinlich verfügt die Datenquelle über Sicherheitsschutzvorrichtungen. Probieren Sie die folgenden Lösungen aus, und führen Sie den Assistenten dann erneut aus.
| Sicherheitsfeature | Lösung |
|---|---|
| Die Ressource erfordert Azure-Rollen, oder die zugehörigen Zugriffsschlüssel sind deaktiviert | Herstellen einer Verbindung als vertrauenswürdiger Dienst oder Herstellen einer Verbindung mithilfe einer verwalteten Identität |
| Die Ressource befindet sich hinter einer IP-Firewall | Erstellen einer Eingangsregel für die Suche und das Azure-Portal |
| Die Ressource erfordert eine Verbindung mit einem privaten Endpunkt | Herstellen einer Verbindung über einen privaten Endpunkt |
Schritt 2: Hinzufügen von kognitiven Qualifikationen
Konfigurieren Sie als nächstes die KI-Anreicherung, um OCR, Bildanalyse und Verarbeitung in natürlicher Sprache aufzurufen.
In diesem Schnellstart verwenden wir die Azure KI Services-Ressource vom Typ Free. Die Beispieldaten bestehen aus 14 Dateien, so dass die kostenlose Zuteilung von 20 Transaktionen auf Azure KI Services für diesen Schnellstart ausreicht.
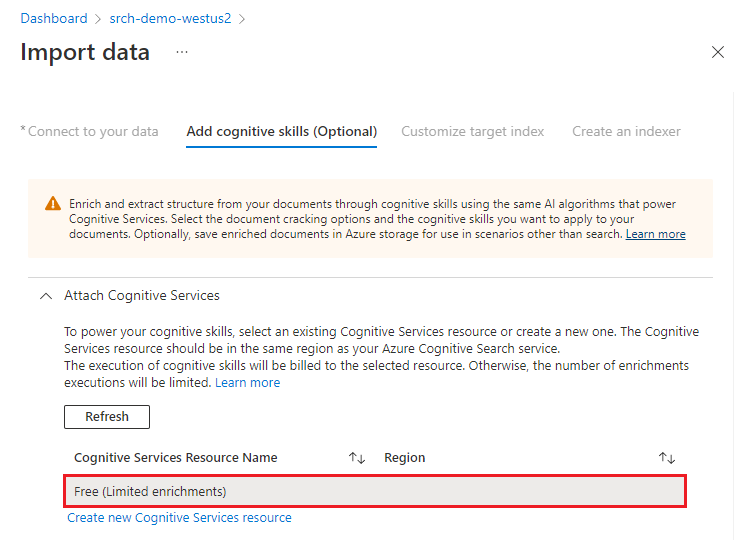
Erweitern Sie Anreicherungen hinzufügen, und wählen Sie sechs Auswahlmöglichkeiten aus.
Aktivieren Sie OCR, um der Assistentenseite Bildanalysequalifikationen hinzuzufügen.
Wählen Sie die Entitätserkennung (Personen, Organisationen, Orte) und Bildanalysequalifikationen (Tags, Beschriftungen) aus.
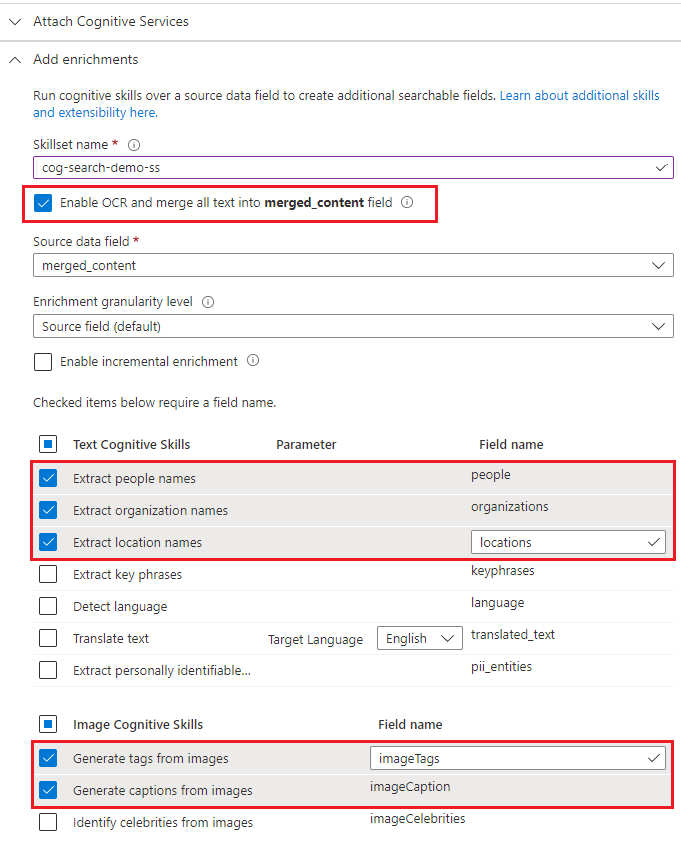
Wechseln Sie zur nächsten Seite.
Schritt 3: Konfigurieren des Index
Ein Index enthält Ihre durchsuchbaren Inhalte, und der Datenimport-Assistent kann in der Regel die Datenquelle untersuchen und das Schema erstellen. Überprüfen Sie in diesem Schritt das generierte Schema, und überarbeiten Sie ggf. die Einstellungen.
Für diesen Schnellstart legt der Assistent sinnvolle Standardwerte fest:
Die Standardfelder basieren auf den Metadateneigenschaften vorhandener Blobs und den neuen Feldern für die Anreicherungsausgabe (z. B.
people,organizations,locations). Datentypen werden aus Metadaten und Datenstichproben abgeleitet.Der Standarddokumentschlüssel ist metadata_storage_path (da dieses Feld eindeutige Werte enthält).
Standardattribute sind Abrufbar und Durchsuchbar. Durchsuchbar ermöglicht die Volltextsuche in einem Feld. Abrufbar bedeutet, dass Feldwerte in Ergebnissen zurückgegeben werden können. Der Assistent geht davon aus, dass diese Felder abrufbar und durchsuchbar sein sollen, da Sie sie über eine Qualifikationsgruppe erstellt haben. Wählen Sie filterbar aus, wenn Sie Felder in einem Filterausdruck verwenden möchten.
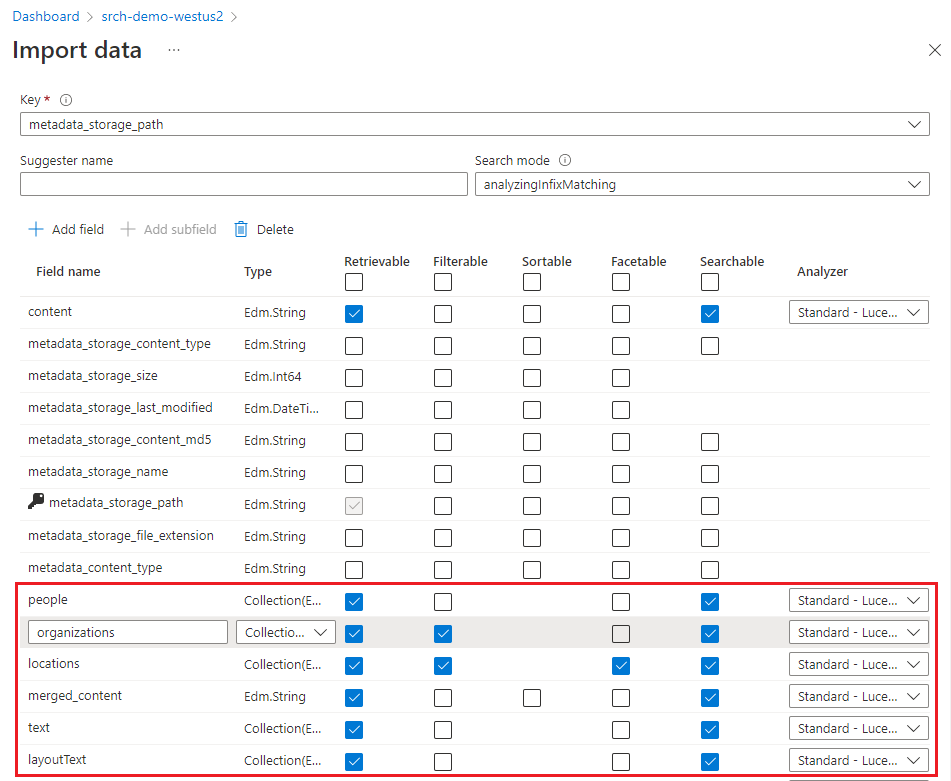
Die Markierung eines Felds als abrufbar bedeutet nicht, dass das Feld in den Suchergebnissen vorhanden sein muss. Sie können die Komposition der Suchergebnisse steuern, indem Sie den Abfrageparameter select verwenden, um anzugeben, welche Felder enthalten sein sollen.
Wechseln Sie zur nächsten Seite.
Schritt 4: Konfigurieren des Indexers
Der Indexer steuert den Indizierungsprozess. Er gibt den Datenquellennamen, einen Zielindex und die Häufigkeit der Ausführung an. Der Datenimport-Assistent erstellt mehrere Objekte, und eines davon ist immer ein Indexer, den Sie zurücksetzen und wiederholt ausführen können.
Übernehmen Sie auf der Seite Indexer den Standardnamen, und wählen Sie Einmal aus.
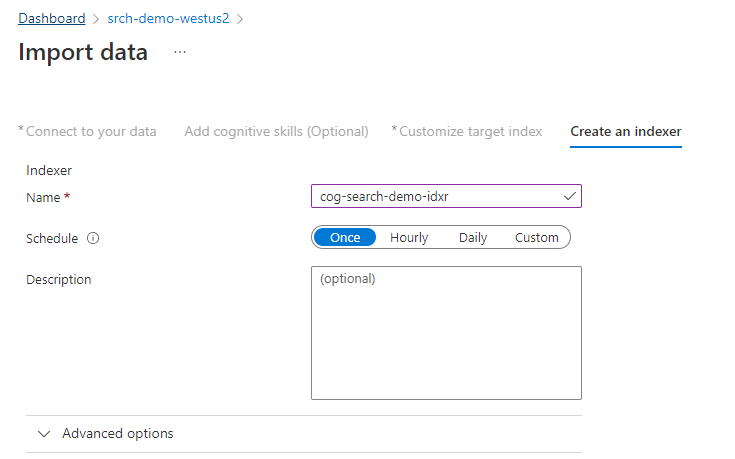
Wählen Sie Senden aus, um den Indexer zu erstellen und gleichzeitig auszuführen.
Überwachen des Status
Wählen Sie Indexer im linken Navigationsbereich aus, um den Status zu überwachen, und wählen Sie dann den Indexer aus. Die fähigkeitsbasierte Indizierung dauert länger als die textbasierte Indizierung, insbesondere OCR und Bildanalyse.
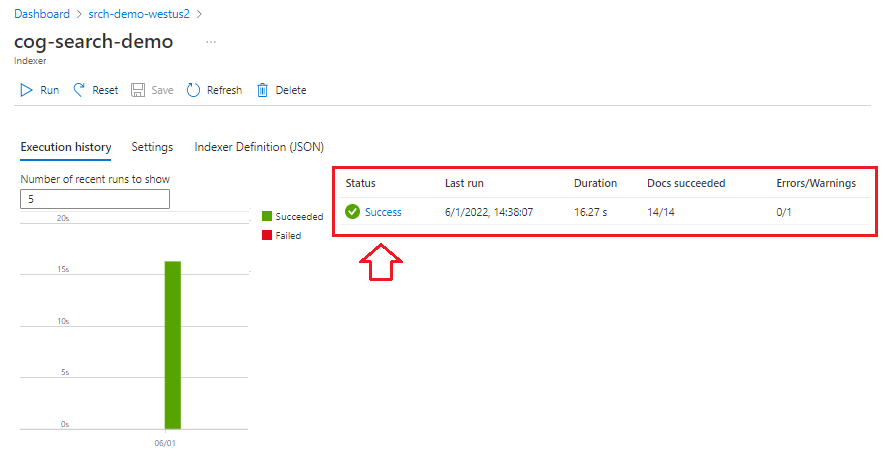
Um Details zum Ausführungsstatus anzuzeigen, wählen Sie erfolgreich (oder fehlgeschlagen) aus, um Ausführungsdetails anzuzeigen.
Diese Demo enthält einige Warnungen: "Could not execute skill because one or more skill input was invalid." Diese Warnung weist Sie darauf hin, dass eine PNG-Datei in der Datenquelle keine Texteingabe für die Entitätserkennung bereitstellt. Die Warnung erfolgt, weil der Upstream-OCR-Skill keinen Text im Bild erkannt hat und deshalb keine Texteingabe für den Downstream-Skill „Entitätserkennung“ bereitstellen konnte.
Warnungen kommen bei der Ausführung von Skillsets häufig vor. Während Sie sich damit vertraut machen, wie Skills Ihre Daten durchlaufen, werden Sie möglicherweise Muster erkennen und lernen, welche Warnungen Sie getrost ignorieren können.
Abfragen im Suchexplorer
Nachdem ein Index erstellt wurde, verwenden Sie den Such-Explorer, um Ergebnisse zurückzugeben.
Wählen Sie auf der linken Seite Indizes und dann den Index aus. Der Such-Explorer befindet sich auf der ersten Registerkarte.
Geben Sie eine Suchzeichenfolge ein, um den Index abzufragen, z.B.
satya nadella. Die Suchleiste akzeptiert Schlüsselwörter, in Anführungszeichen eingeschlossene Ausdrücke und Operatoren ("Satya Nadella" +"Bill Gates" +"Steve Ballmer").
Die Ergebnisse werden als ausführliches JSON zurückgegeben, was vor allem bei großen Dokumenten schwer zu lesen sein kann. Einige Tipps für die Suche in diesem Tool umfassen die folgenden Techniken:
Wechseln Sie zur JSON-Ansicht, um Parameter anzugeben, die die Formergebnisse erzielen.
Fügen Sie
selecthinzu, um die Felder in Ergebnissen einzuschränken.Fügen Sie
counthinzu, um die Anzahl der Übereinstimmungen anzuzeigen.Suchen Sie mit STRG+F im JSON-Code nach bestimmten Eigenschaften oder Begriffen.
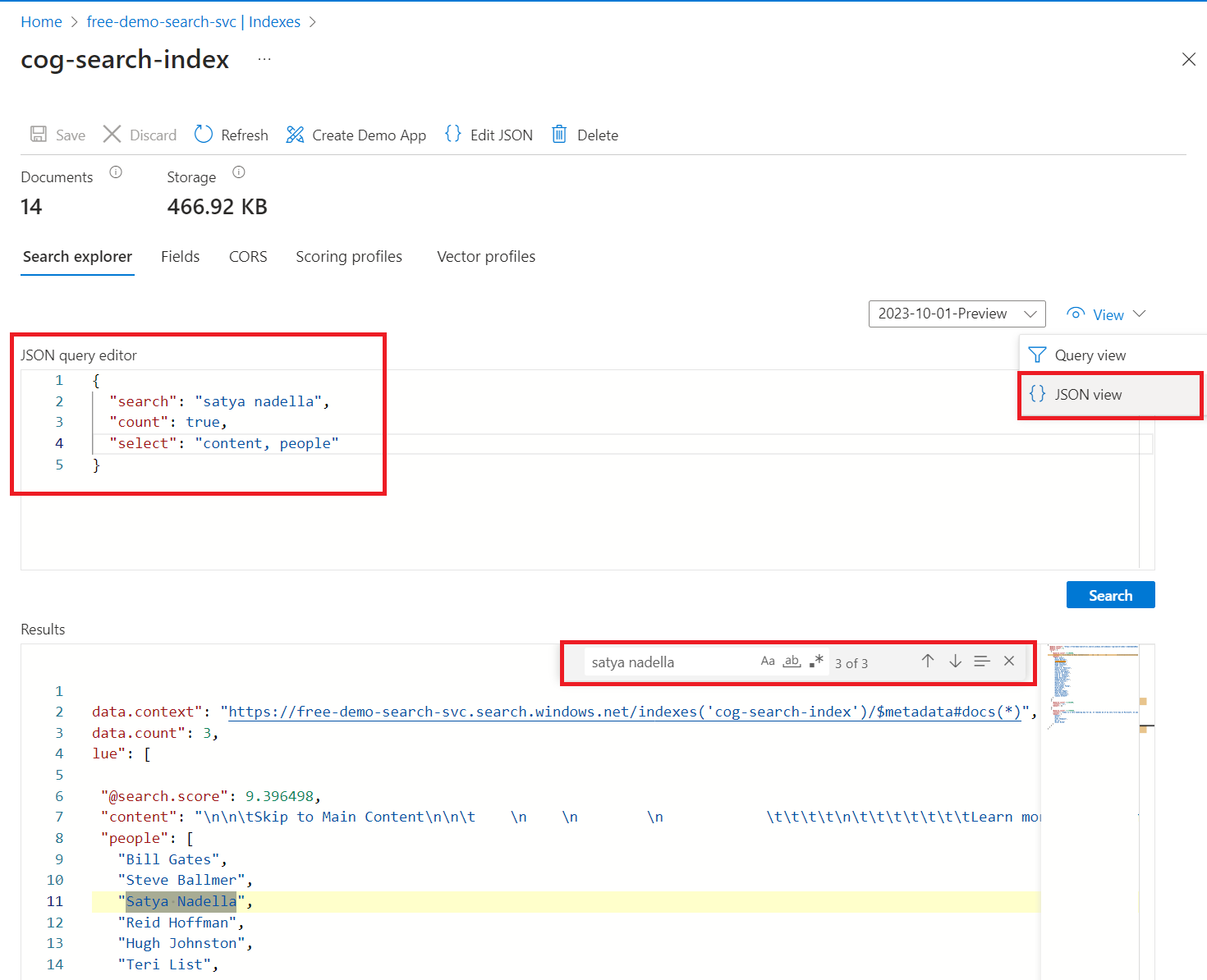
Hier sind einige JSON-Dateien, die Sie in die Ansicht einfügen können:
{
"search": "\"Satya Nadella\" +\"Bill Gates\" +\"Steve Ballmer\"",
"count": true,
"select": "content, people"
}
Tipp
Bei Abfragezeichenfolgen wird die Groß-/Kleinschreibung beachtet. Wenn Sie also eine Meldung „Unbekanntes Feld“ erhalten, überprüfen Sie Felder oder Indexdefinition (JSON) , um Name und Schreibweise zu überprüfen.
Wesentliche Punkte
Sie haben nun Ihr erstes Skillset erstellt und die grundlegenden Schritte der kompetenzbasierten Indizierung gelernt.
Einige wichtige Konzepte, die wir hoffen Ihnen mitgegeben zu haben, sind die Abhängigkeiten. Ein Skillset ist an einen Indexer gebunden, und Indexer sind Azure- und quellenspezifisch. In dieser Schnellstartanleitung wird Azure Blob Storage verwendet. Es können aber auch andere Azure-Datenquellen verwendet werden. Weitere Informationen finden Sie unter Indexer in Azure AI Search.
Ein weiteres wichtiges Konzept ist, dass Skills mit Inhaltstypen arbeiten und bei der Arbeit mit heterogenen Inhalten einige Eingaben übersprungen werden. Außerdem können große Dateien oder Felder die Indexergrenzwerte ihrer Dienstebene überschreiten. Es ist normal, dass Warnungen angezeigt werden, wenn diese Ereignisse auftreten.
Die Ausgabe wird an einen Suchindex geleitet, und es gibt eine Zuordnung zwischen Name-Wert-Paaren, die während der Indizierung erstellt wurden, und einzelnen Feldern in Ihrem Index. Intern richtet der Assistent eine Anreicherungsstruktur ein und definiert ein Skillset, das die Reihenfolge der Vorgänge und den allgemeinen Fluss festlegt. Diese Schritte sind im Assistenten ausgeblendet, werden aber wichtig, wenn Sie selbst mit der Erstellung von Code beginnen.
Außerdem haben Sie gelernt, dass Sie Inhalte durch Abfragen des Index überprüfen können. Was Azure AI Search bereitstellt, ist ein durchsuchbarer Index, den Sie entweder mit der einfachen oder mit der vollständig erweiterten Abfragesyntax abfragen können. Ein Index, der angereicherte Felder enthält, ist wie jeder andere. Wenn Sie standardmäßige oder benutzerdefinierte Analysetools, Bewertungsprofile, Synonyme, Facettennavigation, die geografische Suche oder andere Azure AI Search-Features einbeziehen möchten, stehen Ihnen alle Wege offen.
Bereinigen von Ressourcen
Wenn Sie in Ihrem eigenen Abonnement arbeiten, sollten Sie sich am Ende eines Projekts überlegen, ob Sie die erstellten Ressourcen noch benötigen. Ressourcen, die weiterhin ausgeführt werden, können Sie Geld kosten. Sie können entweder einzelne Ressourcen oder aber die Ressourcengruppe löschen, um den gesamten Ressourcensatz zu entfernen.
Ressourcen können im Portal über den Link Alle Ressourcen oder Ressourcengruppen im linken Navigationsbereich gesucht und verwaltet werden.
Denken Sie bei Verwendung eines kostenlosen Diensts an die Beschränkung auf maximal drei Indizes, Indexer und Datenquellen. Sie können einzelne Elemente über das Portal löschen, um unter dem Limit zu bleiben.
Nächste Schritte
Skillsets können über das Portal, per .NET SDK oder per REST-API erstellt werden. Um Ihr Wissen weiter zu erweitern, probieren Sie die REST-API mit einem REST-Client und weiteren Beispieldaten aus.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für