Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Sie können Ihre Daten, Workloads und Anwendungen von Azure Data Lake Storage Gen1 zu Azure Data Lake Storage Gen2 migrieren. In diesem Artikel wird der empfohlene Migrationsansatz erläutert. Außerdem werden die verschiedenen Migrationsmuster und ihre Anwendungsfälle behandelt. Zur besseren Lesbarkeit wird in diesem Artikel mit dem Begriff Gen1 auf Azure Data Lake Storage Gen1 verwiesen und mit dem Begriff Gen2 auf Azure Data Lake Storage Gen2.
Hinweis
Azure Data Lake Storage Gen1 wurde außer Betrieb genommen. Sehen Sie sich hier die Ankündigung zur Einstellung an. Auf Data Lake Storage Gen1-Ressourcen kann nicht mehr zugegriffen werden.
Azure Data Lake Storage Gen2 setzt auf Azure Blob Storage auf und bietet eine Reihe von Funktionen für Big Data-Analysen. Data Lake Storage Gen2 verbindet Features von Azure Data Lake Storage Gen1 wie Dateisystemsemantik, Sicherheit auf Verzeichnis- und Dateiebene und Skalierbarkeit mit den kostengünstigen, mehrstufigen Speicherlösungen sowie Hochverfügbarkeits- und Notfallwiederherstellungsfunktionen von Azure Blob Storage.
Hinweis
Da Gen1 und Gen2 verschiedene Dienste sind, gibt es keine direkte Upgrade-Erfahrung. Informationen zur Vereinfachung der Migration zu Gen2 über das Azure-Portal finden Sie unter Migrieren von Azure Data Lake Storage von Gen1 zu Gen2 über das Azure-Portal.
Empfohlene Vorgehensweise
Für die Migration von Gen1 zu Gen2 wird der folgende Ansatz empfohlen.
Schritt 1: Bewerten der Bereitschaft
Schritt 2: Vorbereiten der Migration
Schritt 3: Migrieren von Daten und Anwendungsworkloads
Schritt 4: Umstellung von Gen1 auf Gen2
Schritt 1: Bewerten der Bereitschaft
Erfahren Sie mehr über das Data Lake Storage Gen2-Angebot und seine Vorteile, Kosten und allgemeine Architektur.
Vergleichen Sie die Funktionen von Gen1 mit denen von Gen2.
Überprüfen Sie die Liste der bekannten Probleme, um etwaige Lücken in der Funktionalität zu bewerten.
Gen2 unterstützt Blob Storage-Features wie Diagnoseprotokollierung, Zugriffsebenen und Richtlinien für die Blob Storage-Lebenszyklusverwaltung. Wenn Sie eines dieser Features verwenden möchten, erkundigen Sie sich über die aktuelle Unterstützung.
Erkundigen Sie sich über den aktuellen Status der Unterstützung im Azure-Ökosystem, um sicherzustellen, dass Gen2 die Dienste unterstützt, von denen Ihre Lösungen abhängig sind.
Schritt 2: Vorbereiten der Migration
Identifizieren Sie die Datasets, die Sie migrieren möchten.
Nutzen Sie diese Gelegenheit, um Datasets zu bereinigen, die Sie nicht mehr verwenden. Wenn Sie nicht alle Daten gleichzeitig migrieren möchten, nutzen Sie die Zeit, um logische Datengruppen zu finden, die Sie in Phasen migrieren können.
Führen Sie eine Alterungsanalyse (oder ähnliches) für Ihr Gen1-Konto aus, um zu identifizieren, welche Dateien oder Ordner für längere Zeit im Bestand bleiben oder vielleicht veraltet werden.
Ermitteln Sie, welche Auswirkungen eine Migration auf Ihr Unternehmen hat.
Bedenken Sie beispielsweise, ob Sie sich Ausfallzeiten während der Migration leisten können. Diese Überlegungen können Ihnen helfen, ein geeignetes Migrationsmuster zu ermitteln und die am besten geeigneten Tools auszuwählen.
Erstellen Sie einen Migrationsplan.
Wir empfehlen diese Migrationsmuster. Sie können eines dieser Muster auswählen, sie miteinander kombinieren oder ein eigenes Muster entwerfen.
Schritt 3: Migrieren von Daten, Workloads und Anwendungen
Migrieren Sie Daten, Workloads und Anwendungen mithilfe Ihres bevorzugten Musters. Wir empfehlen, Szenarien inkrementell zu validieren.
Erstellen Sie ein Speicherkonto, und aktivieren Sie das Feature für hierarchische Namespaces.
Migrieren Sie Ihre Daten.
Konfigurieren Sie Dienste in Ihren Workloads, sodass sie auf Ihren Gen2-Endpunkt verweisen.
Für HDInsight-Cluster können Sie der Datei „%HADOOP_HOME%/conf/core-site.xml“ Konfigurationseinstellungen für das Speicherkonto hinzufügen. Wenn Sie planen, externe Hive-Tabellen von Gen1 nach Gen2 zu migrieren, stellen Sie sicher, dass Sie auch der Datei „%HIVE_CONF_DIR%/hive-site.xml“ Speicherkontoeinstellungen hinzufügen.
Sie können die Einstellung jeder Datei mit Apache Ambari ändern. Speicherkontoeinstellungen finden Sie unter Hadoop Azure-Support: ABFS – Azure Data Lake Storage Gen2. In diesem Beispiel wird die Einstellung
fs.azure.account.keyverwendet, um die Autorisierung des freigegebenen Schlüssels zu aktivieren:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Links zu Artikeln, die Ihnen bei der Konfiguration von HDInsight, Azure Databricks und anderen Azure-Diensten für die Nutzung von Gen2 helfen, finden Sie unter Azure-Dienste, die Azure Data Lake Storage Gen2 unterstützen.
Aktualisieren Sie Anwendungen für die Verwendung von Gen2-APIs. Sehen Sie sich diese Leitfäden an:
Aktualisieren Sie Skripts für die Verwendung der PowerShell-Cmdlets und Azure CLI-Befehle für Data Lake Storage Gen2.
Suchen Sie nach URI-Verweisen, die die Zeichenfolge
adl://in Codedateien oder in Databricks-Notebooks, Apache Hive-HQL-Dateien oder anderen Dateien in Ihren Workloads enthalten. Ersetzen Sie diese Verweise durch den URI im Gen2-Format Ihres neuen Speicherkontos. Beispiel: Der Gen1-URIadl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilekönnte inabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfilegeändert werden.Konfigurieren Sie die Sicherheit Ihres Kontos so, dass Azure-Rollen, Sicherheit auf Datei- und Ordnerebene und Firewalls und virtuelle Netzwerke von Azure Storage enthalten sind.
Schritt 4: Umstellung von Gen1 auf Gen2
Nachdem Sie sicher sind, dass Ihre Anwendungen und Workloads in Gen2 stabil ausgeführt werden, können Sie mit der Verwendung von Gen2 entsprechend Ihren geschäftlichen Szenarien beginnen. Deaktivieren Sie alle verbleibenden Pipelines, die mit Gen1 ausgeführt werden, und stilllegen Sie Ihr Gen1-Konto.
Funktionen von Gen1 im Vergleich zu Gen2
In dieser Tabelle werden die Funktionen von Gen1 mit denen von Gen2 verglichen.
Muster von Gen1 nach Gen2
Wählen Sie ein Migrationsmuster aus, und ändern Sie dieses Muster nach Bedarf.
| Migrationsmuster | Details |
|---|---|
| Lift & Shift | Das einfachste Muster. Ideal, wenn Ihre Datenpipelines Ausfallzeiten verkraften können. |
| Inkrementelles Kopieren | Ähnlich Lift & Shift, aber mit geringeren Ausfallzeiten. Ideal für große Datenmengen, bei denen das Kopieren länger dauert. |
| Zwei Pipelines | Ideal für Pipelines, bei denen keine Ausfallzeiten auftreten dürfen. |
| Bidirektionale Synchronisierung | Vergleichbar mit dem Muster mit zwei Pipelines, aber mit einer feiner abgestuften Herangehensweise, die für kompliziertere Pipelines geeignet ist. |
Diese Muster sollen nun genauer untersucht werden.
Lift-und-Shift-Muster
Dies ist das einfachste Muster.
Beenden Sie alle Schreibvorgänge in Gen1.
Verschieben Sie Daten von Gen1 zu Gen2. Wir empfehlen dazu Azure Data Factory oder das Azure-Portal. Die ACLs werden mit den Daten kopiert.
Leiten Sie Erfassungsvorgänge und Workloads zu Gen2 weiter.
Setzen Sie Gen1 außer Betrieb.
Sehen Sie sich den Beispielcode für das Lift & Shift-Muster im Lift & Shift-Migrationsbeispiel an.
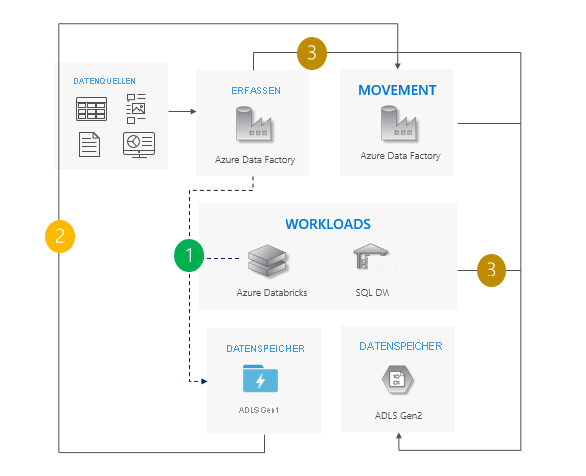
Überlegungen zur Verwendung des Lift & Shift-Musters
Wechseln Sie für alle Workloads gleichzeitig von Gen1 zu Gen2.
Gehen Sie während der Migration und des Umstellungszeitraums von Ausfallzeiten aus.
Ideal für Pipelines, bei denen Ausfallzeiten kein Problem darstellen und alle Apps gleichzeitig aktualisiert werden können.
Tipp
Erwägen Sie die Verwendung des Azure-Portals, um die Ausfallzeit zu verkürzen und die Anzahl der für die Migration erforderlichen Schritte zu verringern.
Inkrementelles Kopiermuster
Beginnen Sie damit, Daten von Gen1 zu Gen2 zu verschieben. Wir empfehlen Azure Data Factory. Die ACLs werden mit den Daten kopiert.
Kopieren Sie schrittweise neue Daten aus Gen1.
Nachdem alle Daten kopiert wurden, beenden Sie alle Schreibvorgänge in Gen1, und leiten Sie Workloads an Gen2 weiter.
Setzen Sie Gen1 außer Betrieb.
Sehen Sie sich den Beispielcode für das Muster mit inkrementellem Kopieren in unserem Beispiel für die Migration mit inkrementellem Kopieren an.
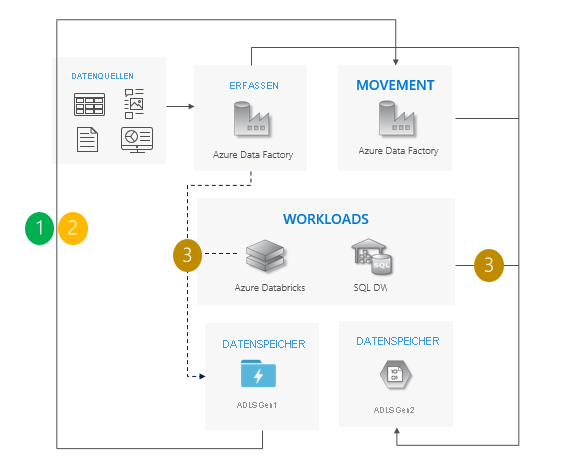
Überlegungen zur Verwendung des Musters mit inkrementellem Kopieren:
Wechseln Sie für alle Workloads gleichzeitig von Gen1 zu Gen2.
Erwarten Sie Ausfallzeiten nur während der Umstellungsphase.
Ideal für Pipelines, bei denen alle Apps gleichzeitig aktualisiert werden, aber für die Datenkopie mehr Zeit erforderlich ist.
Muster mit zwei Pipelines
Verschieben Sie Daten von Gen1 zu Gen2. Wir empfehlen Azure Data Factory. Die ACLs werden mit den Daten kopiert.
Importieren Sie neue Daten sowohl in Gen1 als auch in Gen2.
Leiten Sie Arbeitslasten an Gen2 weiter.
Beenden Sie alle Schreibvorgänge in Gen1, und setzen Sie Gen1 dann außer Betrieb.
Sehen Sie sich den Beispielcode für das Muster mit zwei Pipelines in unserem Beispiel für die Migration mit zwei Pipelines an.
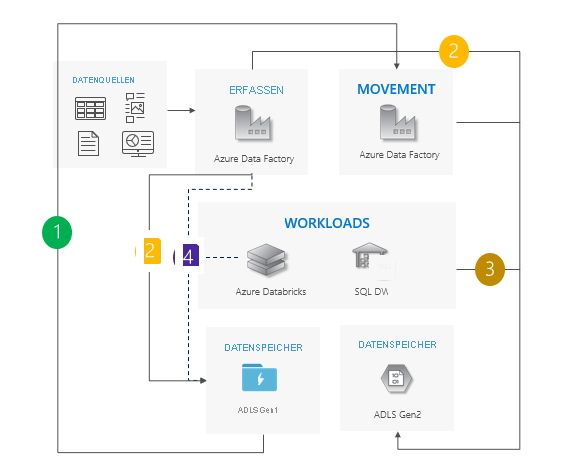
Überlegungen zur Verwendung des Musters mit zwei Pipelines:
Gen1- und Gen2-Pipelines werden parallel ausgeführt.
Unterstützt null Ausfallzeiten.
Ideal für Situationen, in denen bei Ihren Workloads und Anwendungen keine Ausfallzeiten auftreten dürfen und die Erfassung in beiden Speicherkonten erfolgen kann.
Muster mit bidirektionaler Synchronisierung
Richten Sie die bidirektionale Replikation zwischen Gen1 und Gen2 ein. Wir empfehlen WANDisco. Dieses Tool bietet eine Reparaturfunktion für vorhandene Daten.
Wenn alle Verschiebungen abgeschlossen sind, beenden Sie alle Schreibvorgänge in Gen1 und deaktivieren Sie die bidirektionale Replikation.
Setzen Sie Gen1 außer Betrieb.
Sehen Sie sich den Beispielcode für das Muster mit bidirektionaler Synchronisierung im Beispiel für die Migration mit bidirektionaler Synchronisierung an.
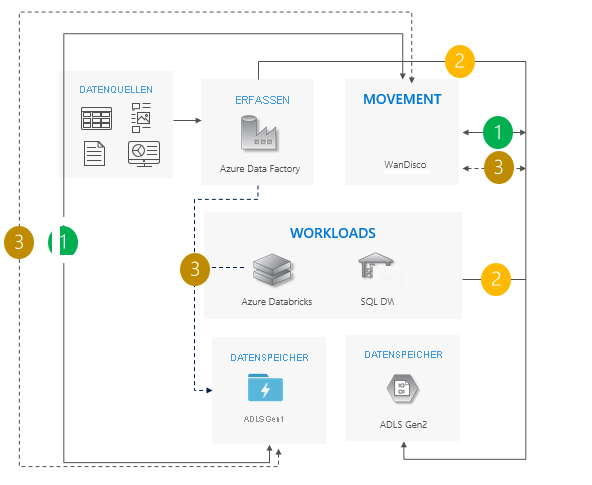
Überlegungen zur Verwendung des Musters mit bidirektionaler Synchronisierung:
Ideal für komplexe Szenarien mit einer großen Anzahl von Pipelines und Abhängigkeiten, in denen ein Verfahren in mehreren Stufen möglicherweise sinnvoller ist.
Der Migrationsaufwand ist hoch, das Muster bietet aber eine gleichzeitige Unterstützung für Gen1 und Gen2.
Nächste Schritte
- Erfahren Sie mehr über die verschiedenen Aspekte der Einrichtung der Sicherheit für ein Speicherkonto. Weitere Informationen finden Sie im Azure Storage-Sicherheitsleitfaden.
- Optimieren Sie die Leistung für Ihren Data Lake Store. Weitere Informationen finden Sie unter Optimieren von Azure Data Lake Storage Gen2 im Hinblick auf Leistung.
- Informieren Sie sich über die bewährten Methoden für die Verwaltung Ihres Data Lake Store. Weitere Informationen finden Sie unter Bewährte Methoden zur Verwendung von Azure Data Lake Storage Gen2.