Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Abschnitt erfahren Sie, wie Sie eine bestehende Lake-Datenbank in Azure Synapse mit dem Database Designer abändern. Der Database Designer erlaubt es Ihnen, auf einfache Art und Weise ohne Veschlüsselung eine Datenbank zu erstellen und bereitzustellen.
Voraussetzungen
- Man benötigt eine Zugangsberechtigung zum Synapse-Administrator oder Synapse-Verteiler auf dem Synapse-Arbeitsbereich, um eine Lake-Datenbank zu erstellen.
- Bei Verwendung der Option Aus Data Lake für die Tabellenerstellung sind Berechtigungen vom Typ „Mitwirkender an Storage-Blobdaten“ für Data Lake erforderlich.
Abändern von Datenbanken
Auf Ihrem Azure-Synapse-Analytics-Arbeitsbereich Home hub wählen Sie links den Tab Datei aus. Der Tab Datei öffnet sich und Sie sehen eine Liste von Datenbanken, die auf Ihrem Arbeitsbereich bereits vorhanden sind.
Zeigen Sie auf den Abschnitt Datenbanken, und wählen Sie neben der Datenbank, die Sie ändern möchten, die Auslassungspunkte (...) aus. Wählen Sie anschließend Öffnen aus.
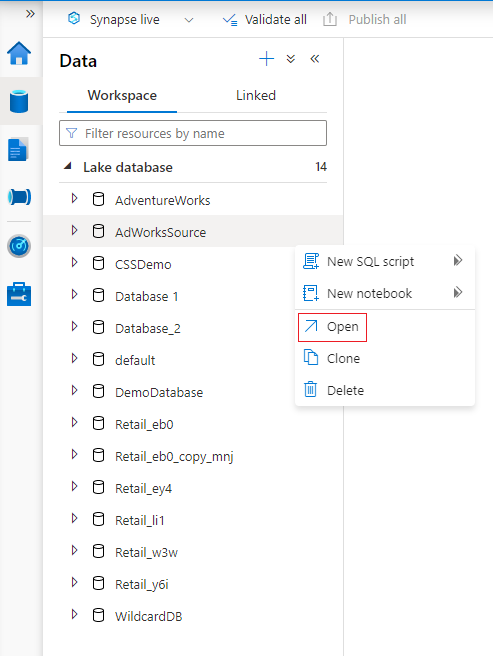
Der Tab Database Designer öffnet sich mit Ihrer ausgewählten Datenbank, die auf die Arbeitsfläche geladen wird.
Der Datenbank-Designer enthält den Bereich Eigenschaften, den Sie öffnen, indem Sie das Symbol Eigenschaften rechts oben auf der Registerkarte auswählt.
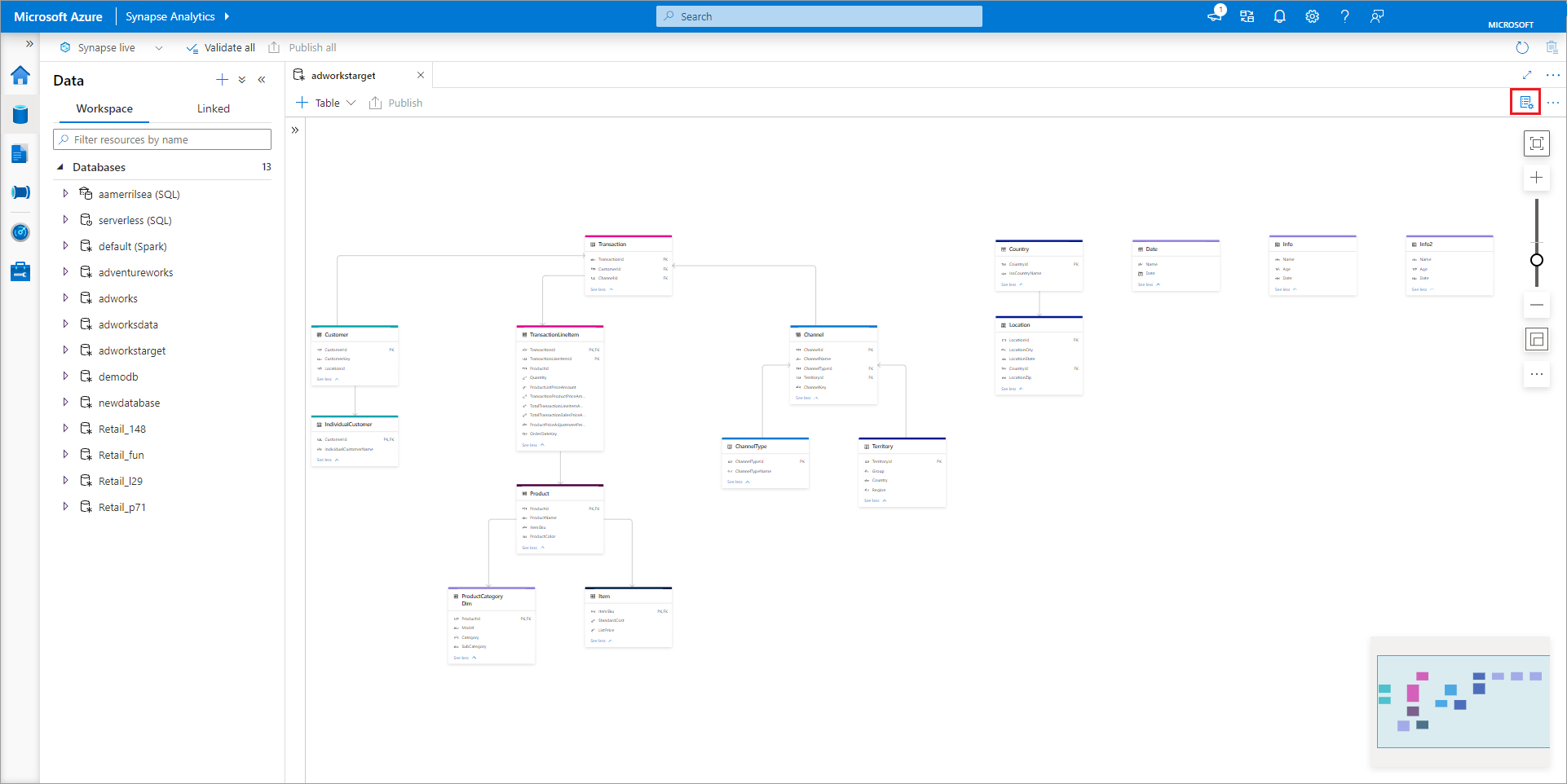
- Name Namen können nicht mehr nach Veröffentlichung der Datenbank bearbeitet werden, also vergewissern Sie sich, dass der von Ihnen gewählte Name richtig ist.
- Beschreibung Es steht Ihnen frei, Ihrer Datenbank eine Beschreibung hinzuzufügen, aber es ermöglicht es den Nutzern, den Bestimmungszweck der Datenbank zu verstehen.
- Der Abschnitt Speichereinstellungen für Datenbanken enthält die voreingestellten Speicherinformationen für Verzeichnisse in der Datenbank. Die Werkseinstellung wird für jedes Verzeichnis in der Datenbank angewandt, außer sie wird von dem Verzeichnis selbst verworfen.
- Der verlinkte Service ist ein voreingestellter verlinkter Service, um Ihre Daten im Azure-Data-Lake-Speicher zu speichern. Der voreingestellte verlinkte Service vom Synapse-Arbeitsbereich wird angezeigt, aber Sie können den verlinkten Service zu jedem anderen ADLS-Speicherkonto abändern, das Sie wollen.
- Eingabeordner zum Festlegen des Standardcontainers und des Ordnerpfads innerhalb des verknüpften Dienstes mithilfe des Dateibrowsers oder durch manuelles Bearbeiten des Pfads mit dem Stiftsymbol
- Datenformat Lake-Datenbanken in Azure Synapse unterstützen Parquet-Dateien und Text mit Trennzeichen als Speicherformate für Dateien.
Um ein Verzeichnis der Datenbank hinzuzufügen, wählen Sie die Schaltfläche + Verzeichnis.
- Benutzerdefiniert fügt dem Canvas-Panel eine neue Tabelle hinzu.
- Über die Vorlage wird der Katalog geöffnet, und Sie können eine Datenbankvorlage auswählen, die beim Hinzufügen einer neuen Tabelle verwendet werden soll. Weitere Informationen finden Sie unter Erstellen einer Lake-Datenbank aus einer Datenbankvorlage.
- Mithilfe von Data Lake können Sie ein Tabellenschema mit daten importieren, die sich bereits in Ihrem Lake befindet.
Wählen Sie Benutzerdefiniert aus. Im Zeichenbereich wird eine neue Tabelle mit dem Namen Table_1.
Sie können dann Verzeichnis_1 anpassen, indem Sie den Verzeichnisnamen, die Beschreibung, die Speichereinstellungen, Spalten und Bezüge einfügen. Unten sehen Sie die angepassten Verzeichnisse innerhalb des Datenbankabschnitts.
Fügen Sie ein neues Verzeichnis von Data Lake hinzu, indem Sie + Verzeichnis und dann Von Data Lake auswählen.
Der Bereich Externe Tabelle aus Data Lake erstellen wird angezeigt. Füllen Sie den Bereich mit den folgenden Details aus, und wählen Sie Weiter aus.
- Geben Sie der externen Tabelle den Namen, den Sie der Tabelle geben möchten, die Sie erstellen.
- Verknüpfter Dienst: Der verknüpfte Dienst, der den Azure Data Lake-Storage, an dem sich Ihre Datendatei befindet.
-
Eingabedatei oder -ordner verwenden den Dateibrowser, um zu einer Datei in Ihrem Lake zu navigieren und diese auszuwählen, mit der Sie eine Tabelle erstellen möchten.
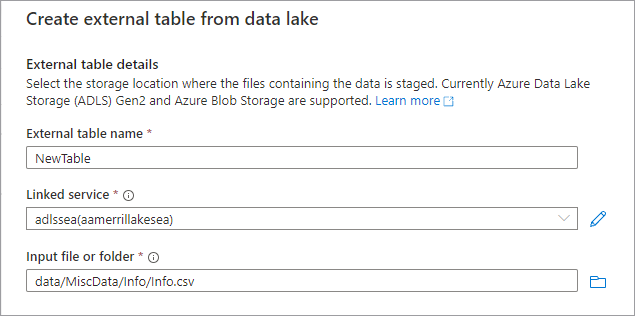
- Auf der nächsten Bildschirmanzeige gibt Ihnen Azure Synapse eine Vorschau von der Datei und erkennt das Schema.
- Sie landen auf den Seiten Neues externes Verzeichnis, wo Sie alle Einstellungen in Bezug auf das Datenformat auf den aktuellen Stand bringen können, und Vorschau Datei, um zu überprüfen, ob Azure Synapse die Datei richtig identifiziert hat.
- Wenn Sie mit den Einstellungen zufrieden sind, wählen Sie Erstellen aus.
- Eine neue Tabelle mit dem von Ihnen ausgewählten Namen wird der Canvas hinzugefügt, und im Abschnitt Speichereinstellungen für Tabellewird die Datei angezeigt, die Sie angegeben haben.
Jetzt ist es Zeit die angepasste Database zu veröffentlichen. Wenn Sie die Git-Integration mit Ihrem Synapse-Arbeitsbereich verwenden, müssen Sie Ihre Änderungen commiten und im Kollaborationszweig zusammenführen. Erfahren Sie mehr über die Quellcodeverwaltung in Azure Synapse. Wenn Sie den Synapse Live-Modus verwenden, können Sie "Veröffentlichen" auswählen.
Ihre Datenbank wird auf Fehler überprüft, bevor Sie veröffentlicht wird. Alle gefundenen Fehler werden auf der Registerkarte "Benachrichtigungen" mit Anweisungen zum Beheben des Fehlers angezeigt.
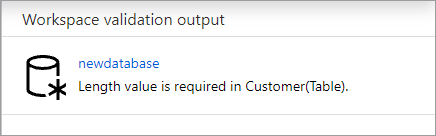
Die Veröffentlichung erstellt Ihr Datenbankschema im Azure Synapse Metastore. Nach der Veröffentlichung sind die Datenbank- und Tabellenobjekte für andere Azure-Dienste sichtbar und ermöglichen den Fluss der Metadaten aus Ihrer Datenbank in Apps wie Power BI oder Microsoft Purview.
Passen Sie Verzeichnisse innerhalb Ihrer Datenbank an.
Der Database Designer erlaubt es Ihnen, jegliche Verzeichnisse in Ihrer Datenbank voll und ganz anzupassen. Wenn Sie ein Verzeichnis auswählen, stehen Ihnen drei Tabs zur Verfügung, wobei ein jedes davon Einstellungen in Bezug auf das Verzeichnisschema oder die Metadata enthält.
Allgemein
Der Allgemein-Tab enthält Informationen, die sich auf das Verzeichnis selbst beziehen.
Name der Name des Verzeichnisses Der Verzeichnisname kann jedem einzigartigen Wert innerhalb der Datenbank angepasst werden. Mehrere Verzeichnisse mit demselben Namen sind nicht zulässig.
Übernommen von (optional) dies wird angezeigt, wenn ein Verzeichnis aus einer anderen Datenbankvorlage erstellt wurde. Es kann nicht bearbeitet werden und zeigt dem Nutzer an, aus welchem Vorlagenverzeichnis es stammt.
Beschreibung ist die Beschreibung des Verzeichnisses. Wenn das Verzeichnis aus einer Datenbankvorlage erstellt wurde, enthält es eine Beschreibung des Konzepts, das diesem Verzeichnis zugrunde liegt. Das Feld kann bearbeitet und so abgeändert werden, dass es mit der Beschreibung übereinstimmt, die auf Ihre Geschäftsanforderungen passen.
Ordner anzeigen zeigt den Namen des Ordners des Geschäftsbereiches an, unter welchem dieses Verzeichnis als Teil der Datenbankvorlage eingeordnet wurde. Benutzerdefinierte Verzeichnisse findet man bei „Andere“.
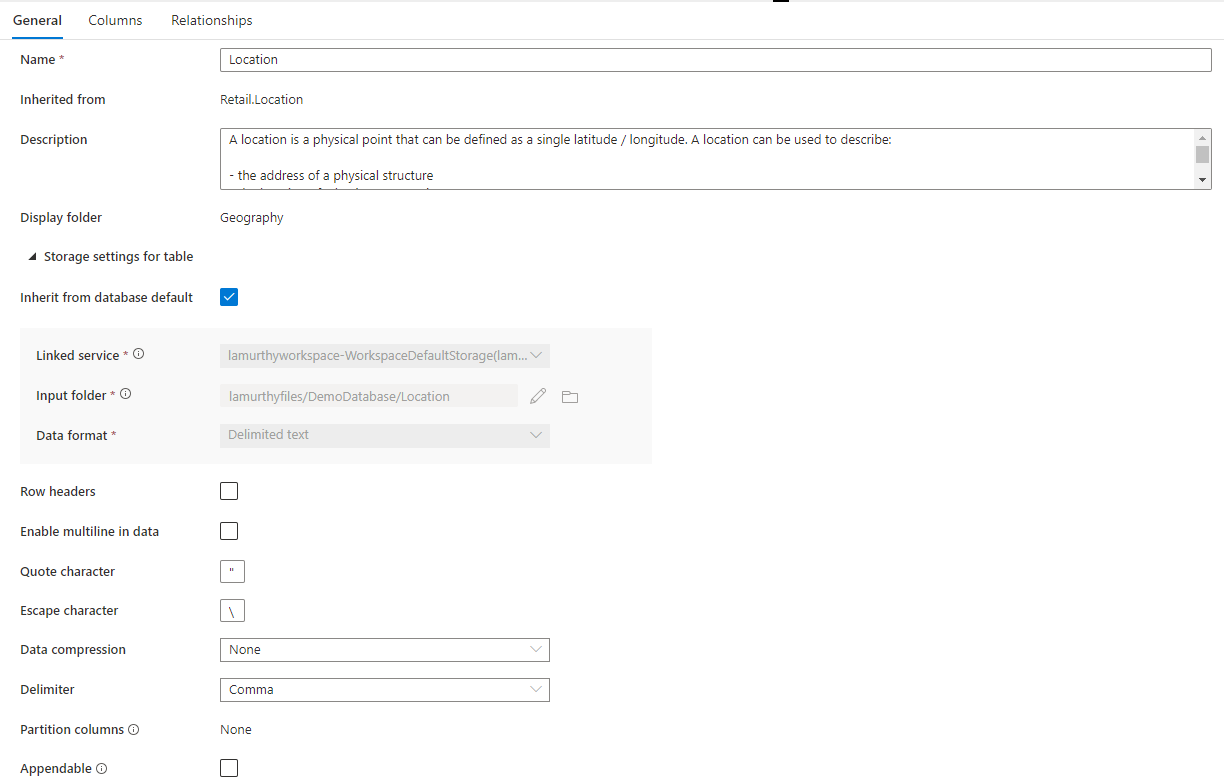
Zusätzlich gibt es einen zusammenklappbaren Abschnitt namens Speichereinstellungen für das Verzeichnis, der Einstellungen für die zugrunde liegenden Speicherinformationen, die vom Verzeichnis verwendet werden, bereitstellt.
Von voreingestellter Datenbank übernehmen ist ein Optionsfeld, das festlegt, ob die unteren Speichereinstellungen von der Einstellung im Datenbank-Tab Eigenschaften übernommen werden oder individuell gemacht werden. Wenn Sie die Speicherwerte anpassen wollen, entfernen Sie das Häkchen aus dem Kontrollkästchen.
- Der verlinkte Service ist ein voreingestellter verlinkter Service, um Ihre Daten im Azure-Data-Lake-Speicher zu speichern. Ändern Sie dies, um ein anderes ADLS-Konto zu wählen.
- Eingabeordner der Ordner in ADLS, wo die Datei, die in dieses Verzeichnis geladen wurde, zu finden ist. Sie können den Ordnerspeicherort durchsuchen oder manuell mithilfe des Stiftsymbols bearbeiten.
- Datenformat das Datenformat der Datei im Eingabeordner Lake-Datenbanken in Azure Synapse unterstützen Parquetdateien und Texte mit Trennzeichen als Speicherformate für Daten. Wenn das Datenformat nicht mit den Daten im Ordner übereinstimmt, werden Abfragen im Verzeichnis nicht gelingen.
Was das Datenformat von Texten mit Trennzeichen angeht, gibt es weitere Einstellungen:
- Kopfzeilen Aktivieren Sie dieses Kontrollkästchen, wenn die Datei Kopfzeilen hat.
- Aktivieren von mehrzeiligen Daten: Aktivieren Sie dieses Kontrollkästchen, wenn die Daten mehrere Zeilen in einer Zeichenfolgenspalte enthalten.
- Anführungszeichen: Geben Sie das benutzerdefinierte Anführungszeichen für eine durch Trennzeichen getrennte Textdatei an.
- Escapezeichen: Geben Sie das benutzerdefinierte Escapezeichen für eine durch Trennzeichen getrennte Textdatei an.
- Datenkomprimierung die Art von Komprimierung, die bei der Datei verwendet wurde.
- Trennzeichen die Trennzeichen, die in der Datei verwendet wurden Unterstützte Werte sind: Komma (,), Tab (\t) und senkrechter Strich (|).
- Partitionsspalten: Hier wird die Liste der Partitionsspalten angezeigt.
- Anfügbar: Aktivieren Sie dieses Kontrollkästchen, wenn Sie Dataverse-Daten über SQL (serverlos) abfragen.
Was Parquet-Datei angeht, gibt es die folgende Einstellung:
- Datenkomprimierung die Art von Komprimierung, die bei der Datei verwendet wurde.
Spalten
Der Spalten-Tab ist da zu finden, wo die Spalten für das Verzeichnis aufgelistet sind und abgeändert werden können. Auf diesem Tab gibt es zwei Listen von Spalten: Standardspalten und Trennspalten.
Standardspalten sind jegliche Spalten, die Daten speichern, ist ein Primärschlüssel und wird sonst nicht zum Trennen von Daten benutzt.
Trennspalten speichern auch Daten, aber sie teilen die zugrunde liegenden Daten auf Ordner auf, basierend auf den Werten, die die Spalte enthält. Jede Spalte hat die folgenden Eigenschaften.
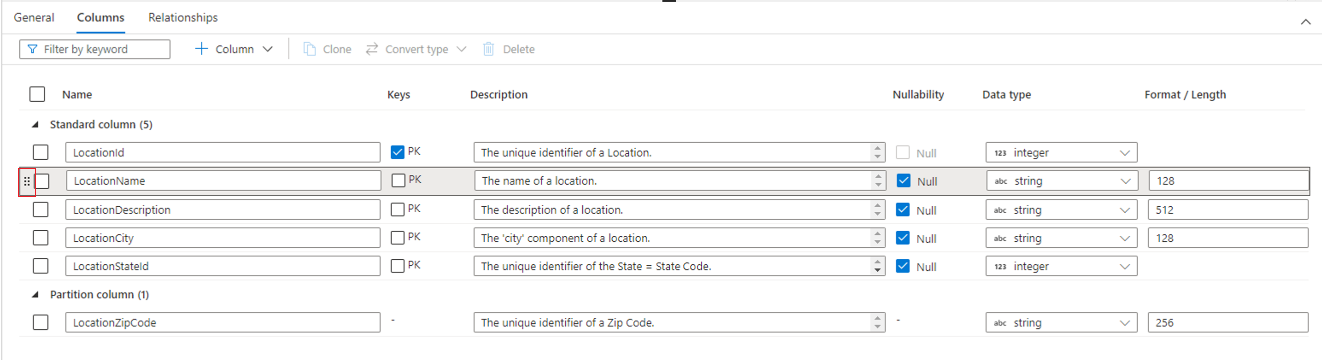
- Name der Name der Spalte. Muss innerhalb des Verzeichnisses einzigartig sein.
- Unter Schlüssel ist angegeben, ob die Spalte ein Primärschlüssel (PS) und/oder ein Fremdschlüssel (FS) für die Tabelle ist. Nicht anwendbar bei Trennspalten.
- Beschreibung eine Beschreibung der Spalte. Wenn die Spalte von einer Datenbankvorlage erstellt wurde, wird die Beschreibung des Konzepts, das dieser Spalte zugrunde liegt, sichtbar sein. Das Feld kann bearbeitet und so abgeändert werden, dass es mit der Beschreibung übereinstimmt, die auf Ihre Geschäftsanforderungen passen.
- Nullbarkeit zeigt an, ob Nullwerte in dieser Spalte zulässig sind. Nicht anwendbar bei Trennspalten.
- Datentyp legt den Datentyp für die Spalte fest, basierend auf der verfügbaren Liste von Spark-Daten-Typen.
- Mit Format / Länge kann man das Format oder die maximale Länge einer Spalte anpassen, je nach Datentyp. Date- und Timestamp-Datentypen weisen Dropdown-Formate auf und andere Datentypen wie String haben ein Feld für eine maximale Länge. Nicht alle Datentypen haben einen Wert, da manche Datentypen eine festgelegte Länge haben. Ganz oben auf dem Spalten-Tab ist eine Befehlsleiste, mit der man mit den Spalten interagieren kann.
- Nach Stichwort filtern filtert die Liste der Spalten nach Elementen, die mit dem angegebenen Stichwort übereinstimmen.
- Mit + Spalte können Sie eine neue Spalte hinzufügen. Es gibt drei mögliche Optionen.
- Neue Spalte erstellt eine neue benutzerdefinierte Standardspalte.
- Aus Vorlage öffnet das Suchfenster und hilft Ihnen, Spalten aus einer Datenbankvorlage zu identifizieren, um sie in Ihr Verzeichnis einzuspeisen. Wenn Ihre Datenbank nicht mit Hilfe einer Datenbankvorlage erstellt wurde, steht diese Option nicht zur Verfügung.
- Trennspalte fügt eine neue benutzerdefinierte Trennspalte hinzu.
- Kopieren dupliziert die ausgewählte Spalte. Kopierte Spalten sind immer vom selben Typ wie die ausgewählte Spalte.
- Spalte konvertieren wird verwendet, um die ausgewählte Sandardspalte in eine Trennspalte und umgekehrt abzuändern. Diese Option wird inaktiviert, wenn Sie mehrere Spalten verschiedener Arten ausgewählt haben oder die ausgewählte Spalte kann nicht konvertiert werden, weil ein PK oder eine Nullbarkeit bei der Spalte verwendet wurde.
- Löschen löscht die ausgewählten Spalten aus dem Verzeichnis. Diese Aktion kann nicht rückgängig gemacht werden.
Sie können die Reihenfolge der Spalten auch per Drag &Drop neu anordnen, indem Sie die doppelten vertikalen Auslassungspunkte verwenden, die links neben dem Spaltennamen angezeigt werden, wenn Sie mit der Maus auf die Spalte zeigen oder klicken, wie in der Abbildung oben dargestellt.
Trennspalten
Trennspalten werden verwendet, um die physischen Daten in Ihrer Datenbank aufzuteilen, basierend auf den in jenen Spalten verwendeten Werten. Trennspalten bieten eine einfache Methode, um Daten auf Datenträgern auf effizientere Einheiten aufzuteilen. Trennspalten in Azure Synapse sind immer am Ende des Verzeichnisschemas. Außerdem werden Sie vom Anfang bis zum Ende verwendet, wenn Trennordner erstellt werden. Zum Beispiel, wenn Ihre Trennspalten Jahr und Monat sind, werden Sie auf eine Struktur in ADLS wie diese stoßen:
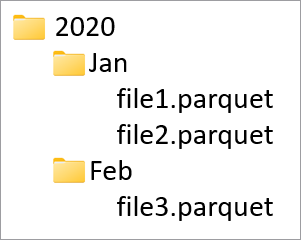
Wo Datei1 und Datei2 alle Reihen beinhalten, wo die Werte von Jahr und Monat jeweils 2020 und Jan waren. Je mehr Trennspalten einem Verzeichnis hinzugefügt werden, desto mehr Dateien werden dieser Anordnung hinzugefügt, was die Gesamtdateigröße einer Trennspalte kleiner macht.
Azure Synapse führt diese Anordnung nicht durch oder erschafft sie, indem es Trennspalten einem Verzeichnis hinzufügt. Daten müssen entweder mit Synapse Pipelines oder mit einem Spark-Notebook in das Verzeichnis geladen werden, damit die Trennstruktur gebildet werden kann.
Beziehungen
Das Tab Beziehungen ermöglicht es Ihnen, Beziehungen zwischen Verzeichnissen in der Datenbank anzugeben. Beziehungen im Database Designer sind informativer Natur und schränken die zugrunde liegenden Daten in keiner Weise ein. Sie werden von anderen Microsoft-Anwendungen gelesen, können verwendet werden, um Transformationen zu beschleunigen oder um Geschäftsnutzern Einblicke darin zu gewähren, wie die Verzeichnisse verknüpft sind. Das Fenster Beziehungen hält folgende Informationen bereit.
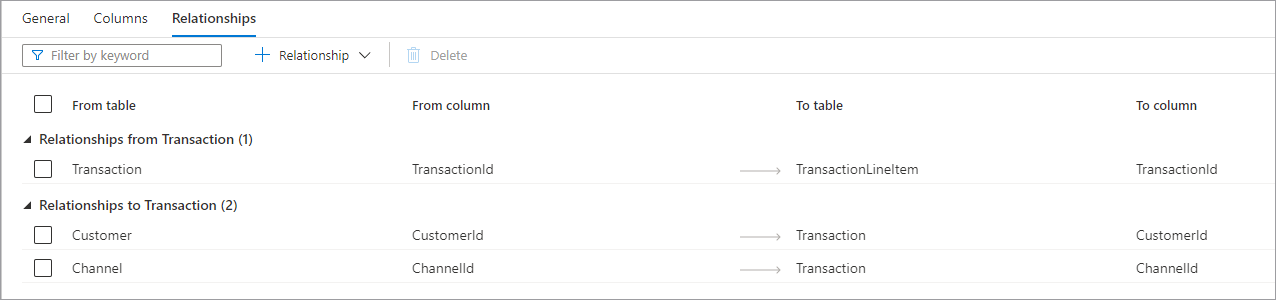
- Beziehungen aus (Verzeichnis) sind dann der Fall, wenn ein oder mehr Verzeichnisse fremde Schlüssel haben, die mit diesem Verzeichnis im Zusammenhang stehen. Dies wird manchmal auch als Elternbeziehung bezeichnet.
- Beziehungen zu (Verzeichnis) sind dann der Fall, wenn ein Verzeichnis, das einen fremden Schlüssel hat, mit einem anderen Verzeichnis im Zusammenhang steht. Dies wird manchmal auch als Kindbeziehung bezeichnet.
- Beide Arten von Beziehung haben die folgenden Eigenschaften.
- Aus Verzeichnis das Elternverzeichnis in der Beziehung oder die „eine“ Seite.
- Aus Spalte die Spalte im Elternverzeichnis, auf der die Beziehung basiert.
- Nach Verzeichnis das Kindverzeichnis in der Beziehung, oder die „vielseitige“ Seite.
- Nach Spalte die Spalte im Kindverzeichnis, auf der die Beziehung basiert. Ganz oben auf dem Beziehungen-Tab, gibt es eine Befehlsleiste, die verwendet werden kann, um zwischen den Beziehungen zu interagieren
- Nach Stichwort filtern filtert die Liste der Spalten nach Elementen, die mit dem angegebenen Stichwort übereinstimmen.
- Mit + Beziehung können Sie eine neue Beziehung hinzufügen. Es stehen zwei Optionen zur Verfügung.
- Aus Verzeichnis erschafft eine neue Beziehung zu einem anderen Verzeichnis, und zwar aus dem Verzeichnis, mit dem Sie gerade arbeiten.
- Nach Verzeichnis erschafft eine neue Beziehung von einem anderen Verzeichnung zu dem Verzeichnis, mit dem Sie gerade arbeiten.
- Aus Vorlage öffnet ein Suchfenster und ermöglicht es Ihnen, aus den Beziehungen in der Datenbankvorlage zu wählen, um sie in Ihre Datenbank einzuspeisen. Wenn Ihre Datenbank nicht mit Hilfe einer Datenbankvorlage erstellt wurde, steht diese Option nicht zur Verfügung.
Nächste Schritte
Erfahren Sie mehr über die Möglichkeiten des Database Designers, indem Sie den Link unten verwenden.