Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel ist Teil eins einer siebenteiligen Reihe, die Anleitungen zur Migration von Oracle zu Azure Synapse Analytics enthält. Der Schwerpunkt dieses Artikels liegt auf bewährten Methoden für Entwurf und Leistung.
Übersicht
Aufgrund der Kosten und Komplexität der Wartung und Aktualisierung von Legacy-lokalen Oracle-Umgebungen möchten viele vorhandene Oracle-Benutzer die Innovationen nutzen, die von modernen Cloud-Umgebungen bereitgestellt werden. Cloudumgebungen vom Typ Infrastructure-as-a-Service (IaaS) und Platform-as-a-Service (PaaS) ermöglichen Ihnen das Delegieren von Aufgaben wie Infrastrukturwartung und Plattformentwicklung an den Cloudanbieter.
Tipp
Mehr als nur eine Datenbank – die Azure-Umgebung beinhaltet eine umfassende Reihe von Funktionen und Tools.
Obwohl Oracle und Azure Synapse Analytics beides SQL-Datenbanken sind, die Massively Parallel Processing (MPP)-Techniken verwenden, um eine hohe Abfrageleistung bei außergewöhnlich großen Datenmengen zu erreichen, gibt es einige grundlegende Unterschiede im Ansatz:
Legacy-Oracle-Systeme werden häufig lokal installiert und verwenden relativ teure Hardware, während Azure Synapse cloudbasiert ist und Azure-Speicher- und Rechenressourcen verwendet.
Das Upgrade einer Oracle-Konfiguration ist eine große Aufgabe, die zusätzliche physische Hardware und möglicherweise langwierige Datenbank-Neukonfiguration oder Dump and Reload erfordert. Da Speicher- und Computeressourcen in der Azure-Umgebung voneinander getrennt sind und über die Funktion der elastischen Skalierung verfügen, können diese Ressourcen unabhängig hoch- oder herunterskaliert werden.
Sie können Azure Synapse nach Bedarf anhalten oder die Größe der Instanz ändern, um die Ressourcennutzung und die Kosten zu reduzieren.
Microsoft Azure ist eine weltweit verfügbare, äußerst sichere und skalierbare Cloudumgebung, die Azure Synapse und ein Ökosystem aus unterstützenden Tools und Möglichkeiten umfasst. Das nächste Diagramm fasst das Azure Synapse-Ökosystem zusammen.
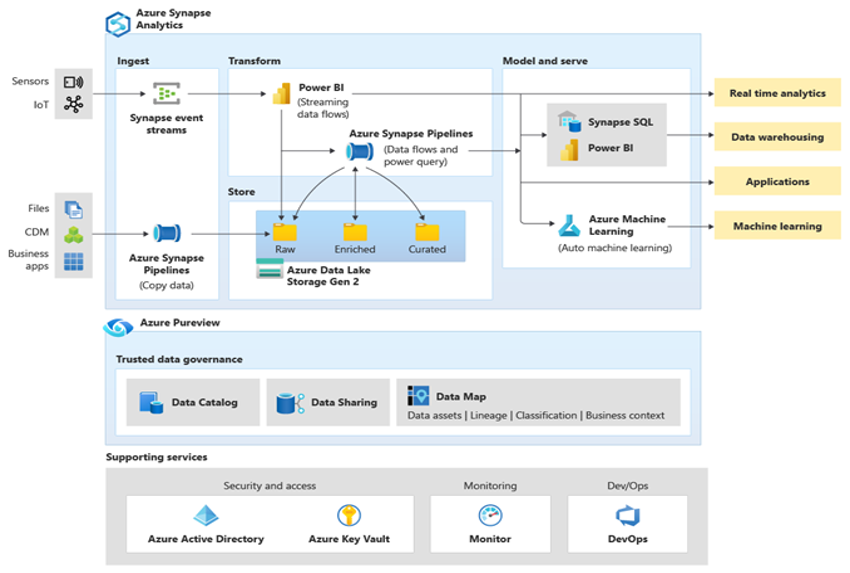
Azure Synapse bietet mithilfe von Techniken wie MPP und automatischem In-Memory-Caching die beste Leistung relationaler Datenbanken. Sie können die Ergebnisse dieser Techniken in unabhängigen Benchmarks wie dem kürzlich vonGigaOm durchgeführten sehen, der Azure Synapse mit anderen beliebten Cloud-Data-Warehouse-Angeboten vergleicht. Kunden, die zur Azure Synapse-Umgebung migrieren, profitieren von vielen Vorteilen, darunter:
Verbesserte Leistung und besseres Preis-Leistungs-Verhältnis
Höhere Flexibilität und schnellere Amortisierung
Schnellere Serverbereitstellung und Anwendungsentwicklung
Elastische Skalierbarkeit – nur für die tatsächliche Nutzung bezahlen
Verbesserte Sicherheit/Konformität
Niedrigere Kosten für Speicherung und Notfallwiederherstellung
Niedrigere Gesamtkosten, bessere Kostensteuerung und optimierte Betriebsausgaben (OPEX).
Migrieren Sie neue oder bereits vorhandene Daten und Anwendungen zur Azure Synapse-Plattform, um bestmöglich von diesen Vorteilen profitieren zu können. In vielen Organisationen umfasst die Migration das Verschieben eines vorhandenen Data Warehouse von einer älteren lokalen Plattform wie Oracle zu Azure Synapse. Auf hoher Ebene umfasst der Migrationsprozess die folgenden Schritte:
Vorbereitung 🡆
Definieren von den Umfang – was migriert werden soll.
Erstellen einer Bestandsaufnahme der Daten und Prozesse für die Migration
Definieren von Datenmodelländerungen (falls erforderlich)
Definieren des Mechanismus zum Extrahieren von Quelldaten
Identifizieren der geeigneten Tools und Features von Azure und Drittanbietern, die verwendet werden sollen
Frühzeitige Schulung von Mitarbeitern für die neue Plattform
Einrichten der Azure-Zielplattform
Migration 🡆
Einfaches Beginnen im kleinen Umfang
Nehmen Sie wann immer möglich eine Automatisierung vor.
Nutzen der integrierten Azure-Tools und -Features zum Verringern des Migrationsaufwands
Migrieren von Metadaten für Tabellen und Sichten
Migrieren von Verlaufsdaten, die beibehalten werden sollen
Migrieren oder Umgestalten von gespeicherten Prozeduren und Geschäftsprozessen
Migrieren oder Umgestalten von ETL/ELT-Prozessen für inkrementelles Laden
Aufgaben nach der Migration
Überwachen und Dokumentieren aller Phasen des Prozesses
Nutzen der gewonnenen Erfahrungen zum Erstellen einer Vorlage für zukünftige Migrationen
Umgestalten des Datenmodells anhand der Leistung und Skalierbarkeit der neuen Plattform (falls erforderlich)
Testen von Anwendungen und Abfragetools
Erstellen von Benchmarks für die Abfrageleistung und Optimieren derselben
Dieser Artikel enthält allgemeine Informationen und Richtlinien zur Leistungsoptimierung beim Migrieren eines Data Warehouse von einer vorhandenen Oracle-Umgebung zu Azure Synapse. Das Ziel der Leistungsoptimierung besteht darin, die gleiche oder bessere Data Warehouse-Leistung in Azure Synapse nach der Migration zu erzielen.
Überlegungen zum Entwurf
Migrationsumfang
Wenn Sie die Migration von einer Oracle-Umgebung vorbereiten, ziehen Sie die folgenden Migrationsoptionen in Betracht.
Auswählen der Workload für die erste Migration
In der Regel haben sich Legacy-Oracle-Umgebungen im Laufe der Zeit dahingehend weiterentwickelt, dass sie mehrere Themenbereiche und gemischte Workloads umfassen. Wenn Sie entscheiden, wo Sie mit einem Migrationsprojekt beginnen möchten, wählen Sie einen Bereich aus, in dem Sie Folgendes tun können:
Belegen der Machbarkeit einer Migration zu Azure Synapse durch schnelles Bereitstellen der Vorteile der neuen Umgebung.
Ermöglichen Sie Ihren internen technischen Mitarbeitern, relevante Erfahrungen mit den Prozessen und Tools zu sammeln, die sie verwenden werden, wenn sie andere Bereiche migrieren.
Erstellen Sie eine Vorlage für weitere Migrationen, die spezifisch für die Oracle-Quellumgebung und die aktuellen Tools und Prozesse ist, die bereits vorhanden sind.
Ein guter Kandidat für eine anfängliche Migration aus einer Oracle-Umgebung unterstützt die vorstehenden Elemente und:
Implementiert eine BI/Analytics-Workload anstelle einer Online-Transaktionsverarbeitung (OLTP)-Workload.
Ein Datenmodell, z. B. ein Stern- oder Schneeflockenschema, das mit minimalen Änderungen migriert werden kann.
Tipp
Erstellen Sie eine Bestandsaufnahme der zu migrierenden Objekte, und dokumentieren Sie den Migrationsprozess.
Das Volumen der migrierten Daten in der ersten Migration sollte groß genug sein, um die Möglichkeiten und Vorteile der Azure Synapse-Umgebung aufzuzeigen, aber nicht zu groß, damit der Nutzen schnell veranschaulicht werden kann. In der Regel liegt die Größe im Bereich von 1 bis 10 TB.
Ein erster Ansatz für ein Migrationsprojekt besteht darin, das Risiko, den Aufwand und die Zeit zu minimieren, damit Sie schnell die Vorteile der Azure-Cloudumgebung erkennen. Die folgenden Ansätze beschränken den Umfang der anfänglichen Migration nur auf die Data Marts und gehen nicht auf breitere Migrationsaspekte wie ETL-Migration und historische Datenmigration ein. Sie können diese Aspekte jedoch in späteren Phasen des Projekts angehen, sobald die migrierte Datamart-Schicht mit Daten und den erforderlichen Build-Prozessen aufgefüllt wurde.
Migration per Lift & Shift im Vergleich zu einem phasenorientierten Ansatz
Unabhängig vom Zweck und Umfang der geplanten Migration gibt es im Allgemeinen zwei Typen von Migration: eine unveränderte Migration per Lift & Shift und einen phasenorientierten Ansatz, der Änderungen einbindet.
Lift & Shift
Bei einer Migration per Lift & Shift wird das vorhandene Datenmodell (z. B. ein Sternschema) unverändert zur neuen Azure Synapse-Plattform migriert. Dieser Ansatz minimiert die Risiken und die Migrationsdauer, indem der Aufwand reduziert wird, der erforderlich ist, um die Vorteile der Umstellung auf die Azure-Cloudumgebung nutzen zu können. Lift-and-Shift-Migration eignet sich gut für diese Szenarien:
- Sie haben eine vorhandene Oracle-Umgebung mit einem einzelnen zu migrierenden Data Mart, oder
- Sie haben eine vorhandene Oracle-Umgebung mit Daten, die sich bereits in einem gut gestalteten Stern- oder Schneeflockenschema befinden, oder
- Sie stehen unter Zeit- und Kostendruck, um auf eine moderne Cloud-Umgebung umzusteigen.
Tipp
Die Migration per Lift & Shift ist ein guter Ausgangspunkt, auch wenn in nachfolgenden Phasen Änderungen am Datenmodell implementiert werden.
Phasenorientierter Ansatz unter Einbindung von Änderungen
Wenn ein Legacy-Data Warehouse über einen längeren Zeitraum weiterentwickelt wurde, müssen Sie es möglicherweise umstrukturieren, um die erforderlichen Leistungsstufen beibehalten zu können. Möglicherweise müssen Sie auch umstrukturieren, um neue Daten wie Internet of Things (IoT)-Streams zu unterstützen. Migrieren Sie im Rahmen des Reengineering-Prozesses zu Azure Synapse, um die Vorteile einer skalierbaren Cloudumgebung zu nutzen. Die Migration kann eine Änderung des zugrunde liegenden Datenmodells umfassen, z. B. einen Wechsel von einem Inmon-Modell zu einem Datentresor.
Microsoft empfiehlt, Ihr vorhandenes Datenmodell unverändert in Azure zu verschieben und die Leistung und Flexibilität der Azure-Umgebung zu nutzen, um die Reengineering-Änderungen anzuwenden. Auf diese Weise können Sie die Funktionen von Azure nutzen, um die Änderungen vorzunehmen, ohne das vorhandene Quellsystem zu beeinträchtigen.
Verwenden Sie Microsoft-Einrichtungen, um eine metadatengesteuerte Migration zu implementieren
Sie können den Migrationsprozess automatisieren und orchestrieren, indem Sie die Funktionen der Azure-Umgebung nutzen. Dieser Ansatz minimiert die Leistungseinbußen in der vorhandenen Oracle-Umgebung, die möglicherweise bereits fast ausgelastet ist.
Der SQL Server-Migrationsassistent (SSMA) für Oracle kann viele Teile des Migrationsprozesses automatisieren, einschließlich in einigen Fällen Funktionen und Verfahrenscode. SSMA unterstützt Azure Synapse als Zielumgebung.

SSMA für Oracle kann Ihnen helfen, ein Oracle-Data Warehouse oder -Data Mart zu Azure Synapse zu migrieren. SSMA wurde entwickelt, um den Prozess der Migration von Tabellen, Sichten und Daten aus einer bestehenden Oracle-Umgebung zu automatisieren.
Azure Data Factory ist ein cloudbasierter Datenintegrationsdienst, der die Erstellung datengesteuerter Workflows in der Cloud unterstützt, die die Datenverschiebung und Datentransformation orchestrieren und automatisieren. Mit Data Factory können Sie datengesteuerte Workflows (Pipelines) erstellen und planen, die Daten aus unterschiedlichen Datenspeichern erfassen. Data Factory kann Daten mithilfe von Computediensten wie Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics und Azure Machine Learning verarbeiten und transformieren.
Data Factory kann verwendet werden, um Daten an der Quelle zum Azure SQL-Ziel zu migrieren. Diese Offline-Datenverschiebung trägt dazu bei, die Ausfallzeit der Migration erheblich zu reduzieren.
Azure Database Migration Services kann Ihnen dabei helfen, eine Migration aus Umgebungen wie Oracle zu planen und durchzuführen.
Wenn Sie beabsichtigen, Azure-Einrichtungen zum Verwalten des Migrationsprozesses zu verwenden, erstellen Sie Metadaten, die alle zu migrierenden Datentabellen und ihren Speicherort auflisten.
Entwurfsunterschiede zwischen Oracle und Azure Synapse
Wie bereits erwähnt, gibt es einige grundlegende Unterschiede im Ansatz zwischen Oracle- und Azure Synapse Analytics-Datenbanken. SSMA für Oracle hilft nicht nur, diese Lücken zu schließen, sondern automatisiert auch die Migration. SSMA eignet sich gut für kleinere Tabellen, ist bei sehr großen Datenmengen jedoch nicht die effizienteste Methode.
Mehrere Datenbanken im Vergleich zu einzelnen Datenbanken und Schemas
Die Oracle-Umgebung enthält oft mehrere separate Datenbanken. Beispielsweise könnte es separate Datenbanken geben für: Datenerfassung- und Staging-Tabellen, Core-Warehouse-Tabellen und Data Marts – manchmal auch als semantische Schicht bezeichnet. Die Verarbeitung in ETL- oder ELT-Pipelines kann datenbankübergreifende Verknüpfungen implementieren und Daten zwischen den separaten Datenbanken verschieben.
Im Gegensatz dazu enthält die Azure Synapse-Umgebung eine einzelne Datenbank und verwendet Schemas, um Tabellen in logisch getrennte Gruppen zu unterteilen. Wir empfehlen, dass Sie eine Reihe von Schemas innerhalb der Azure Synapse-Zieldatenbank verwenden, um die separaten Datenbanken nachzuahmen, die aus der Oracle-Umgebung migriert wurden. Wenn die Oracle-Umgebung bereits Schemas verwendet, müssen Sie möglicherweise eine neue Namenskonvention verwenden, wenn Sie die vorhandenen Oracle-Tabellen und -Ansichten in die neue Umgebung verschieben. Beispielsweise könnten Sie das vorhandene Oracle-Schema und die Tabellennamen mit dem neuen Azure Synapse-Tabellennamen verketten und Schemanamen in der neuen Umgebung verwenden, um die ursprünglichen separaten Datenbanknamen beizubehalten. Obwohl Sie SQL-Ansichten über den zugrunde liegenden Tabellen verwenden können, um die logischen Strukturen beizubehalten, hat dieser Ansatz potenzielle Nachteile:
Ansichten in Azure Synapse sind schreibgeschützt, sodass alle Updates an den Daten in den zugrunde liegenden Basistabellen erfolgen müssen.
Möglicherweise sind bereits eine oder mehrere Ansichtsebenen vorhanden, und das Hinzufügen einer zusätzlichen Ansichtsebene kann die Leistung beeinträchtigen.
Tipp
Kombinieren Sie in Azure Synapse mehrere Datenbanken in einer einzelnen Datenbank, und verwenden Sie Schemanamen, um die Tabellen logisch zu trennen.
Überlegungen zu Tabellen
Wenn Sie Tabellen zwischen verschiedenen Umgebungen migrieren, werden in der Regel nur die Rohdaten und die Metadaten, die sie beschreiben, physisch migriert. Andere Datenbankelemente aus dem Quellsystem, wie z. B. Indizes, werden in der Regel nicht migriert, weil sie in der neuen Umgebung möglicherweise nicht benötigt oder anders implementiert werden.
Leistungsoptimierungen in der Quellumgebung, wie z. B. Indizes, zeigen an, wo Sie Leistungsoptimierungen in der neuen Umgebung hinzufügen könnten. Wenn beispielsweise Abfragen in der Oracle-Quellumgebung häufig Bitmap-Indizes verwenden, legt dies nahe, dass ein nicht gruppierter Index in Azure Synapse erstellt werden sollte. Andere native Techniken zur Leistungsoptimierung wie die Tabellenreplikation sind möglicherweise besser geeignet als die direkte gleichartige Indexerstellung. SSMA für Oracle kann verwendet werden, um Migrationsempfehlungen für die Tabellenverteilung und Indizierung bereitzustellen.
Tipp
Vorhandene Indizes zeigen Kandidaten für die Indizierung im migrierten Warehouse an.
Nicht unterstützte Oracle-Datenbankobjekttypen
Oracle-spezifische Features können oft durch Azure Synapse-Features ersetzt werden. Einige Oracle-Datenbankobjekte werden jedoch nicht direkt in Azure Synapse unterstützt. Die folgende Liste von nicht unterstützten Oracle-Datenbankobjekten beschreibt, wie Sie eine gleichwertige Funktionalität in Azure Synapse erreichen können.
Verschiedene Indizierungsoptionen: In Oracle haben mehrere Indizierungsoptionen, z. B. Bitmap-Indizes, funktionsbasierte Indizes und Domänenindizes, keine direkte Entsprechung in Azure Synapse.
Sie können herausfinden, welche Spalten indiziert sind und welchen Indextyp Sie haben:
Abfragen von Systemkatalogtabellen und -ansichten, wie
ALL_INDEXES,DBA_INDEXES,USER_INDEXES, undDBA_IND_COL. Sie können die integrierten Abfragen in Oracle SQL Developer verwenden, wie im folgenden Screenshot gezeigt.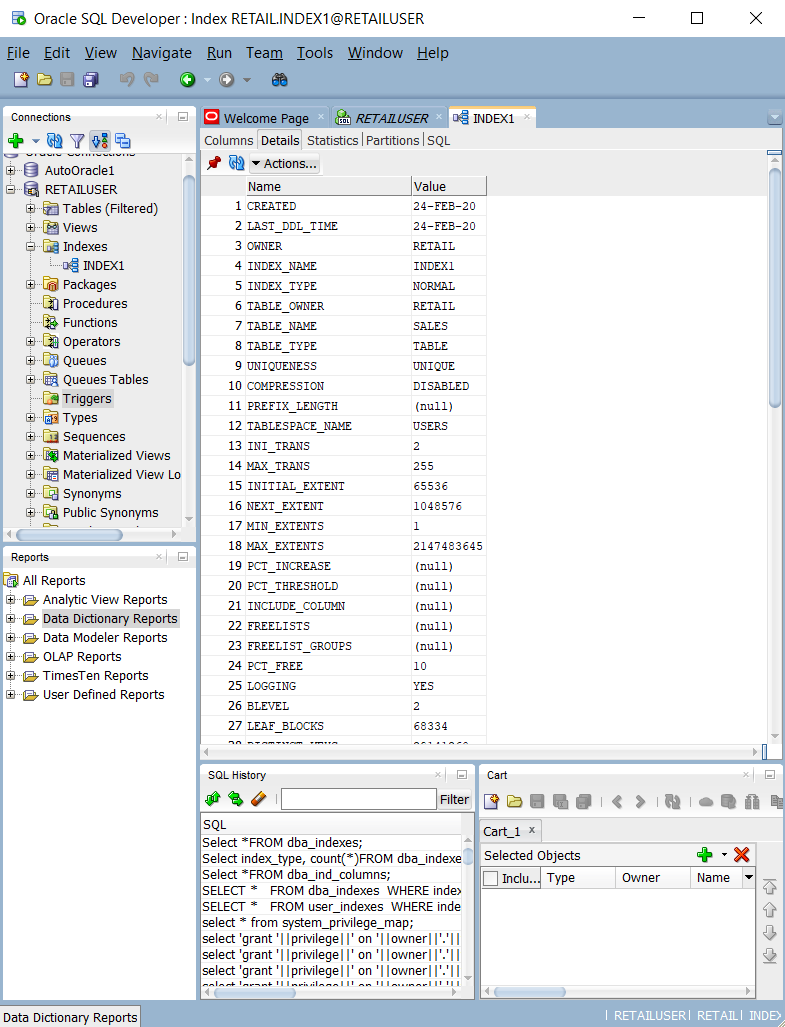
Oder führen Sie die folgende Abfrage aus, um alle Indizes eines bestimmten Typs zu finden:
SELECT * FROM dba_indexes WHERE index_type LIKE 'FUNCTION-BASED%';Abfrage der
dba_index_usage- oderv$object_usage-Ansichten bei aktivierter Überwachung. Sie können diese Ansichten in Oracle SQL Developer abfragen, wie im folgenden Screenshot gezeigt.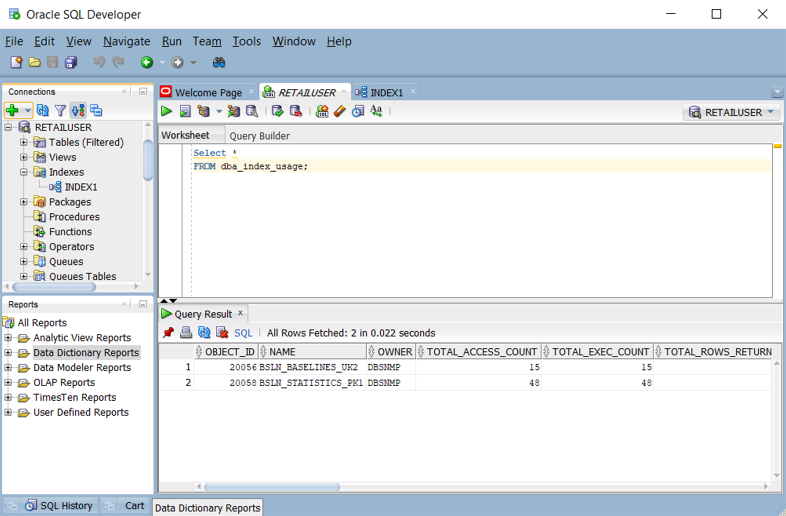
Funktionsbasierte Indizes, bei denen der Index das Ergebnis einer Funktion in den zugrunde liegenden Datenspalten enthält, haben keine direkte Entsprechung in Azure Synapse. Wir empfehlen, dass Sie zuerst die Daten migrieren und dann in Azure Synapse die Oracle-Abfragen ausführen, die funktionsbasierte Indizes verwenden, um die Leistung zu messen. Wenn die Leistung dieser Abfragen in Azure Synapse nicht akzeptabel ist, sollten Sie erwägen, eine Spalte zu erstellen, die den vorberechneten Wert enthält, und diese Spalte dann indizieren.
Wenn Sie die Azure Synapse-Umgebung konfigurieren, ist es sinnvoll, nur verwendete Indizes zu implementieren. Azure Synapse unterstützt derzeit die hier gezeigten Indextypen:
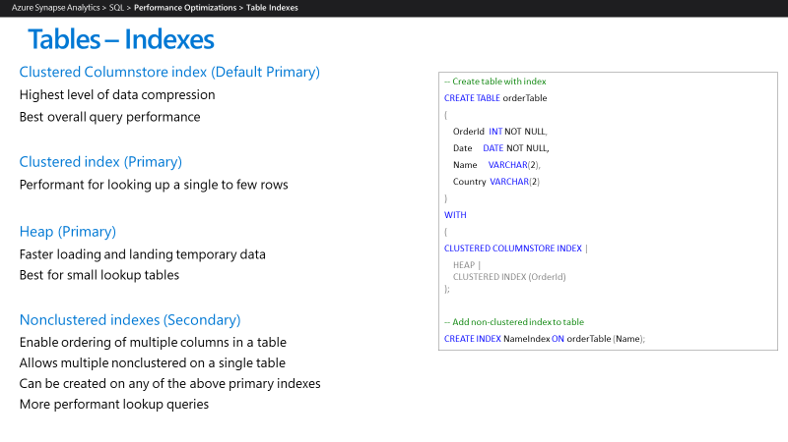
Azure Synapse-Funktionen wie die parallele Abfrageverarbeitung und das In-Memory-Caching von Daten und Ergebnissen machen es wahrscheinlich, dass weniger Indizes für Data Warehouse-Anwendungen erforderlich sind, um Leistungsziele zu erreichen. Wir empfehlen die Verwendung der folgenden Indextypen in Azure Synapse:
Gruppierte Columnstore-Indexes: Wenn für eine Tabelle keine Indexoptionen angegeben sind, erstellt Azure Synapse standardmäßig einen gruppierten Columnstore-Index. Gruppierte Columnstore-Tabellen bieten das höchste Maß an Datenkomprimierung, die beste allgemeine Abfrageleistung und übertreffen im Allgemeinen geclusterte Index- oder Heap-Tabellen. Ein gruppierter Columnstore-Index ist normalerweise die beste Wahl für große Tabellen. Wenn Sie eine Tabelle erstellen, wählen Sie gruppierten Columnstore, wenn Sie sich nicht sicher sind, wie Sie Ihre Tabelle indizieren sollen. Es gibt jedoch einige Szenarien, in denen gruppierte Columnstore-Indizes nicht die beste Option sind:
- Tabellen mit vorsortierten Daten auf einem Sortierschlüssel/auf Sortierschlüsseln können von der Segmententfernung profitieren, die durch sortierte gruppierte Columnstore-Indizes aktiviert wird.
- Tabellen mit den Datentypen varchar(max), nvarchar(max) oder varbinary(max), da ein gruppierter Columnstore-Index diese Datentypen nicht unterstützt. Erwägen Sie stattdessen die Verwendung eines Heaps oder gruppierten Indexes.
- Tabellen mit vorübergehenden Daten, da Columnstore-Tabellen möglicherweise weniger effizient sind als Heap- oder temporäre Tabellen.
- Kleine Tabellen mit weniger als 100 Millionen Zeilen. Erwägen Sie stattdessen die Verwendung von Heap-Tabellen.
Sortierte gruppierte Columnstore-Indizes: Durch die effiziente Segmententfernung bieten sortierte gruppierte Columnstore-Indizes in dedizierten Azure Synapse SQL-Pools eine viel schnellere Leistung, indem große Mengen sortierter Daten übersprungen werden, die nicht mit dem Abfrage-Prädikat übereinstimmen. Das Laden von Daten in eine geordnete CCI-Tabelle kann aufgrund des Datensortiervorgangs länger als das Laden in eine nicht geordnete CCI-Tabelle dauern. Abfragen können jedoch später mit einer geordneten CCI-Tabelle schneller ausgeführt werden. Weitere Informationen zum sortierten gruppierten Columnstore-Index finden Sie unter Leistungsoptimierung mit einem sortierten gruppierten Columnstore-Index.
Gruppierte und nicht gruppierte Indizes: Gruppierte Indizes können gruppierte Columnstore-Indizes übertreffen, wenn eine einzelne Zeile schnell abgerufen werden muss. Für Abfragen, bei denen eine einzelne Zeilensuche oder nur wenige Zeilensuchen mit extremer Geschwindigkeit ausgeführt werden müssen, sollten Sie die Verwendung ein gruppierter Index oder eines nicht gruppierten sekundären Index in Betracht ziehen. Der Nachteil bei der Verwendung eines gruppierten Index besteht darin, dass nur Abfragen mit einem hochselektiven Filter für die gruppierten Index-Spalte davon profitieren. Um die Filterung in anderen Spalten zu verbessern, können Sie den anderen Spalten einen nicht gruppierten Index hinzufügen. Jeder Index, den Sie einer Tabelle hinzufügen, verbraucht jedoch mehr Speicherplatz und erhöht die Verarbeitungszeit zum Laden.
Heap-Tabellen: Wenn Sie Daten vorübergehend auf Azure Synapse landen, stellen Sie möglicherweise fest, dass die Verwendung einer Heaptabelle den Gesamtprozess beschleunigt. Dies liegt daran, dass das Laden von Daten in Heap-Tabellen schneller ist als das Laden von Daten in Indextabellen, und in einigen Fällen können nachfolgende Lesevorgänge aus dem Cache erfolgen. Wenn Sie Daten nur laden, um sie bereitzustellen, bevor Sie weitere Transformationen ausführen, ist es viel schneller, sie in eine Heap-Tabelle zu laden als in eine gruppierte Columnstore-Tabelle. Außerdem ist das Laden von Daten in eine temporäre Tabelle schneller als das Laden einer Tabelle in den permanenten Speicher. Für kleine Nachschlagetabellen mit weniger als 100 Millionen Zeilen sind Heap-Tabellen in der Regel die richtige Wahl. Für gruppierte Columnstore-Tabellen wird die optimale Komprimierung erst erreicht, wenn mehr als 100 Millionen Zeilen enthalten.
Gruppierte Tabellen: Oracle-Tabellen können so organisiert werden, dass Tabellenzeilen, auf die häufig zusammen zugegriffen wird (basierend auf einem gemeinsamen Wert), physisch zusammen gespeichert werden, um die Festplatten-E/A beim Abrufen von Daten zu reduzieren. Oracle bietet auch eine Hash-Cluster-Option für einzelne Tabellen, die einen Hash-Wert auf den Cluster-Schlüssel anwendet und Zeilen mit demselben Hash-Wert physisch zusammen speichert. Um Cluster innerhalb einer Oracle-Datenbank aufzulisten, verwenden Sie die
SELECT * FROM DBA_CLUSTERS;Abfrage. Um festzustellen, ob sich eine Tabelle in einem Cluster befindet, verwenden Sie dieSELECT * FROM TAB;Abfrage, die den Tabellennamen und die Cluster-ID für jede Tabelle anzeigt.In Azure Synapse können Sie ähnliche Ergebnisse erzielen, indem Sie materialisierte und/oder replizierte Tabellen verwenden, da diese Tabellentypen die zur Abfragelaufzeit erforderliche E/A minimieren.
Materialisierte Sichten: Oracle unterstützt materialisierte Sichten und empfiehlt die Verwendung einer oder mehrerer für große Tabellen mit vielen Spalten, bei denen nur wenige Spalten regelmäßig in Abfragen verwendet werden. Materialisierte Ansichten werden vom System automatisch aktualisiert, wenn Daten in der Basistabelle aktualisiert werden.
Im Jahr 2019 gab Microsoft bekannt, dass Azure Synapse materialisierte Ansichten mit der gleichen Funktionalität wie in Oracle unterstützen wird. Materialisierte Ansichten sind jetzt ein Vorschaufeature in Azure Synapse.
In-Datenbank-Trigger: In Oracle kann ein Trigger so konfiguriert werden, dass er automatisch ausgeführt wird, wenn ein auslösendes Ereignis eintritt. Auslösende Ereignisse können folgendes sein:
Eine Data Manipulation Language (DML)-Anweisung, wie z. B.
INSERT,UPDATEoderDELETE, wird für eine Tabelle ausgeführt. Wenn Sie einen Trigger definiert haben, der vor einerINSERTAnweisung in einer Kundentabelle ausgelöst wird, wird der Trigger einmal ausgelöst, bevor eine neue Zeile in die Kundentabelle eingefügt wird.Eine DDL-Anweisung wie
CREATEoderALTERwird ausgeführt. Dieser Trigger wird häufig zu Überwachungszwecken verwendet, um Schemaänderungen aufzuzeichnen.Ein Systemereignis, z. B. das Starten oder Herunterfahren der Oracle-Datenbank.
Ein Benutzerereignis, z. B. Anmelden oder Abmelden.
Sie können eine Liste der in einer Oracle-Datenbank definierten Trigger abrufen, indem Sie die Ansichten
ALL_TRIGGERS,DBA_TRIGGERS, oderUSER_TRIGGERSabfragen. Der folgende Screenshot zeigt eineDBA_TRIGGERSAbfrage in Oracle SQL Developer.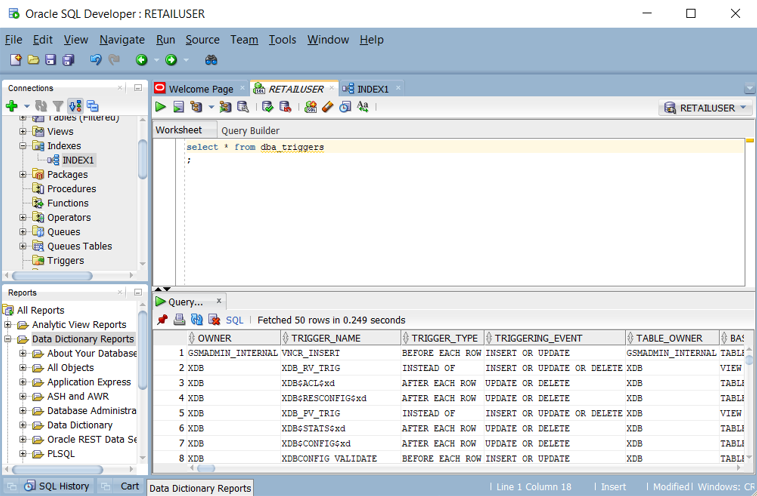
Azure Synapse unterstützt keine Oracle-Datenbankauslöser. Sie können jedoch äquivalente Funktionen mithilfe von Data Factory hinzufügen, obwohl Sie dazu die Prozesse umgestalten müssen, die Trigger verwenden.
Synonyme: Oracle unterstützt die Definition von Synonymen als alternative Namen für mehrere Datenbankobjekttypen. Zu diesen Objekttypen gehören: Tabellen, Ansichten, Sequenzen, Prozeduren, gespeicherte Funktionen, Pakete, materialisierte Ansichten, Schemaobjekte der Java-Klasse, benutzerdefinierte Objekte oder andere Synonyme.
Azure Synapse unterstützt derzeit nicht das Definieren von Synonymen. Wenn sich ein Synonym in Oracle jedoch auf eine Tabelle oder Ansicht bezieht, können Sie in Azure Synapse eine Ansicht definieren, die mit dem alternativen Namen übereinstimmt. Wenn sich ein Synonym in Oracle auf eine Funktion oder gespeicherte Prozedur bezieht, können Sie in Azure Synapse eine andere Funktion oder gespeicherte Prozedur mit einem Namen erstellen, der dem Synonym entspricht, das das Ziel aufruft.
Benutzerdefinierte Typen: Oracle unterstützt benutzerdefinierte Objekte, die eine Reihe einzelner Felder mit jeweils eigener Definition und Standardwerten enthalten können. Auf diese Objekte kann innerhalb einer Tabellendefinition genauso verwiesen werden wie auf integrierte Datentypen wie
NUMBERoderVARCHAR. Sie können eine Liste der in einer Oracle-Datenbank definierten Trigger abrufen, indem Sie die AnsichtenALL_TYPES,DBA_TYPES, oderUSER_TYPESabfragen.Azure Synapse unterstützt derzeit keine benutzerdefinierten Typen. Wenn die Daten, die Sie migrieren müssen, benutzerdefinierte Datentypen enthalten, „vereinfachen“ Sie sie entweder in einer herkömmlichen Tabellendefinition, oder normalisieren Sie sie in einer separaten Tabelle, wenn es sich um Datenarrays handelt.




Oracle-Datentypzuordnung
Die meisten Oracle-Datentypen haben eine direkte Entsprechung in Azure Synapse. Die folgende Tabelle zeigt den empfohlenen Ansatz zum Zuordnen von Oracle-Datentypen zu Azure Synapse.
| Oracle-Datentyp | Azure Synapse-Datentyp |
|---|---|
| BFILE | Wird nicht unterstützt. Zuordnung zu VARBINARY (MAX). |
| BINARY_FLOAT | Wird nicht unterstützt. Zuordnen zu FLOAT. |
| BINARY_DOUBLE | Wird nicht unterstützt. Zuordnen zu DOUBLE. |
| BLOB | Nicht direkt unterstützt. Ersetzen sie durch VARBINARY(MAX). |
| CHAR | CHAR |
| CLOB | Nicht direkt unterstützt. Ersetzen sie durch VARCHAR(MAX). |
| DATE | DATUM in Oracle kann auch Zeitinformationen enthalten. Zuordnung je nach Verwendung zu DATE oder TIMESTAMP. |
| DECIMAL | DECIMAL |
| Double | PRECISION DOUBLE |
| GLEITKOMMAZAHL | GLEITKOMMAZAHL |
| INTEGER | INT |
| INTERVAL YEAR TO MONTH | INTERVAL-Datentypen werden nicht unterstützt. Verwenden Sie Datumsvergleichsfunktionen, z. B. DATEIFF oder DATEADD, für Datumsberechnungen. |
| INTERVAL DAY TO SECOND | INTERVAL-Datentypen werden nicht unterstützt. Verwenden Sie Datumsvergleichsfunktionen, z. B. DATEIFF oder DATEADD, für Datumsberechnungen. |
| LONG | Wird nicht unterstützt. Zuordnung zu VARCHAR(MAX). |
| LONG RAW | Wird nicht unterstützt. Zuordnung zu VARBINARY(MAX). |
| NCHAR | NCHAR |
| NVARCHAR2 | NVARCHAR |
| NUMBER | GLEITKOMMAZAHL |
| NCLOB | Nicht direkt unterstützt. Ersetzen Durch NVARCHAR(MAX). |
| NUMERIC | NUMERIC |
| ORD-Mediendatentypen | Nicht unterstützt |
| RAW | Wird nicht unterstützt. Zuordnung zu VARBINARY. |
| real | REAL |
| ROWID | Wird nicht unterstützt. Ordnen Sie GUID zu, was ähnlich ist. |
| SDO Geospatial-Datentypen | Nicht unterstützt |
| SMALLINT | SMALLINT |
| timestamp | DATETIME2 oder die CURRENT_TIMESTAMP() funktion |
| TIMESTAMP WITH LOCAL TIME ZONE | Wird nicht unterstützt. Zuordnen zu DATETIMEOFFSET. |
| TIMESTAMP WITH TIME ZONE | Nicht unterstützt, da TIME unter Verwendung der Wanduhrzeit ohne Zeitzonenverschiebung gespeichert wird. |
| URIType | Wird nicht unterstützt. Speichern sie in einem VARCHAR. |
| UROWID | Wird nicht unterstützt. Ordnen Sie GUID zu, was ähnlich ist. |
| VARCHAR | VARCHAR |
| VARCHAR2 | VARCHAR |
| XMLType | Wird nicht unterstützt. Speichern von XML-Daten in einem VARCHAR. |
Oracle unterstützt auch die Definition benutzerdefinierter Objekte, die eine Reihe einzelner Felder enthalten können, jedes mit seiner eigenen Definition und seinen eigenen Standardwerten. Diese Objekte können dann innerhalb einer Tabellendefinition genauso referenziert werden wie eingebaute Datentypen wie NUMBER oder VARCHAR. Azure Synapse unterstützt derzeit keine benutzerdefinierten Typen. Wenn die Daten, die Sie migrieren müssen, benutzerdefinierte Datentypen enthalten, „vereinfachen“ Sie sie entweder in einer herkömmlichen Tabellendefinition, oder normalisieren Sie sie in einer separaten Tabelle, wenn es sich um Datenarrays handelt.
Tipp
Bewerten Sie die Anzahl und Art der nicht unterstützten Datentypen während der Migrationsvorbereitungsphase.
Drittanbieter bieten Tools und Dienste zur Automatisierung der Migration an, einschließlich der Zuordnung von Datentypen. Wenn in der Oracle-Umgebung bereits ein ETL-Tool eines Drittanbieters verwendet wird, verwenden Sie dieses Tool, um alle erforderlichen Datentransformationen zu implementieren.
Syntaxunterschiede in SQL DML
SQL DML-Syntaxunterschiede sind zwischen Oracle SQL und Azure Synapse T-SQL vorhanden. Diese Unterschiede werden ausführlich in Minimieren von SQL-Problemen bei Oracle-Migrationen erläutert. In einigen Fällen können Sie die DML-Migration automatisieren, indem Sie Microsoft-Tools wie SSMA für Oracle und Azure Database Migration Services oder Migrationsprodukte und -dienste von Drittanbietern verwenden.
Funktionen, gespeicherte Prozeduren und Sequenzen
Wenn Sie ein Data Warehouse aus einer ausgereiften Umgebung wie Oracle migrieren, müssen Sie wahrscheinlich andere Elemente als einfache Tabellen und Ansichten migrieren. Prüfen Sie, ob Tools innerhalb der Azure-Umgebung die Funktionalität von Funktionen, gespeicherten Prozeduren und Sequenzen ersetzen können, da es in der Regel effizienter ist, integrierte Azure-Tools zu verwenden, als sie für Azure Synapse neu zu codieren.
Erstellen Sie im Rahmen Ihrer Vorbereitungsphase eine Bestandsaufnahme der zu migrierenden Objekte, definieren Sie eine Methode für deren Handhabung, und weisen Sie entsprechende Ressourcen in Ihrem Migrationsplan zu.
Microsoft-Tools wie SSMA für Oracle und Azure Database Migration Services oder Migrationsprodukte und -dienste von Drittanbietern können die Migration von Funktionen, gespeicherten Prozeduren und Sequenzen automatisieren.
In den folgenden Abschnitten wird die Migration von Funktionen, gespeicherten Prozeduren und Sequenzen näher erläutert.
Functions
Wie bei den meisten Datenbankprodukten unterstützt Oracle system- und benutzerdefinierte Funktionen innerhalb einer SQL-Implementierung. Wenn Sie eine Legacy-Datenbankplattform zu Azure Synapse migrieren, können allgemeine Systemfunktionen normalerweise ohne Änderung migriert werden. Einige Systemfunktionen haben möglicherweise eine etwas andere Syntax, aber alle erforderlichen Änderungen können automatisiert werden. Sie können eine Liste von Funktionen innerhalb einer Oracle-Datenbank abrufen, indem Sie die Ansicht mit der ALL_OBJECTS entsprechenden WHERE Klausel abfragen. Sie können Oracle SQL Developer verwenden, um eine Liste von Funktionen zu erhalten, wie im folgenden Screenshot gezeigt.

Für Oracle-Systemfunktionen oder beliebige benutzerdefinierte Funktionen, die in Azure Synapse keine Entsprechung haben, rekodieren Sie diese Funktionen mit einer Zielumgebungssprache. Benutzerdefinierte Funktionen von Oracle sind in PL/SQL, Java oder C codiert. Azure Synapse verwendet die Transact-SQL-Sprache, um benutzerdefinierte Funktionen zu implementieren.
Gespeicherte Prozeduren
Die meisten modernen Datenbankprodukte unterstützen das Speichern von Prozeduren innerhalb der Datenbank. Oracle stellt die PL/SQL-Sprache für diesen Zweck bereit. Eine gespeicherte Prozedur enthält normalerweise sowohl SQL-Anweisungen als auch prozedurale Logik und gibt Daten oder einen Status zurück. Sie können eine Liste von Funktionen innerhalb einer Oracle-Datenbank abrufen, indem Sie die ALL_OBJECTSAnsicht mit der entsprechenden WHERE Klausel abfragen. Sie können Oracle SQL-Entwickler verwenden, um eine Liste der gespeicherten Prozeduren abzurufen, wie im nächsten Screenshot dargestellt.

Azure Synapse unterstützt gespeicherte Prozeduren mit T-SQL, sodass Sie alle migrierten gespeicherten Prozeduren in dieser Sprache neu codieren müssen.
Sequenzen
In Oracle ist eine Sequenz ein benanntes Datenbankobjekt, das mit CREATE SEQUENCE erstellt wird. Eine Sequenz stellt eindeutige numerische Werte über die CURRVAL und NEXTVAL Methoden bereit. Sie können die generierten eindeutigen Nummern als Ersatzschlüsselwerte für Primärschlüssel verwenden.
Azure Synapse implementiert CREATE SEQUENCE nicht, aber Sie können Sequenzen mithilfe von IDENTITY-Spalten oder SQL-Code implementieren, der die nächste Sequenznummer in einer Serie generiert.
Extrahieren von Metadaten und Daten aus einer Oracle-Umgebung
Generierung der Datendefinitionssprache
Der ANSI-SQL-Standard definiert die grundlegende Syntax für Data Definition Language (DDL)-Befehle. Einige DDL-Befehle wie z. B. CREATE TABLE und CREATE VIEW, gelten sowohl für Oracle als auch für Azure Synapse, bieten aber auch implementierungsspezifische Funktionen wie Indizierung, Tabellenverteilung und Partitionierungsoptionen.
Sie können vorhandene Oracle CREATE TABLE und CREATE VIEW-Skripts bearbeiten, um gleichwertige Definitionen in Azure Synapse zu erhalten. Dazu müssen Sie möglicherweise geänderte Datentypen verwenden und Oracle-spezifische Klauseln wie z. B. TABLESPACE entfernen oder ändern.
Innerhalb der Oracle-Umgebung geben Systemkatalogtabellen die aktuelle Tabellen- und Ansichtsdefinition an. Im Gegensatz zur vom Benutzer gepflegten Dokumentation sind Systemkataloginformationen immer vollständig und mit aktuellen Tabellendefinitionen synchronisiert. Sie können mithilfe von Dienstprogrammen wie Oracle SQL Developer auf Systemkataloginformationen zugreifen. Oracle SQL Developer kann DDL-Anweisungen generierenCREATE TABLE, die Sie bearbeiten können, um entsprechende Tabellen in Azure Synapse zu erstellen.
Oder Sie können SSMA für Oracle verwenden, um Tabellen aus einer vorhandenen Oracle-Umgebung zu Azure Synapse zu migrieren. SSMA für Oracle wendet die entsprechenden Datentypzuordnungen und empfohlenen Tabellen- und Verteilungstypen an, wie im folgenden Screenshot gezeigt.

Sie können auch Migrations- und ETL-Tools von Drittanbietern verwenden, die Systemkataloginformationen verarbeiten, um ähnliche Ergebnisse zu erzielen.
Datenextraktion aus Oracle
Sie können Tabellenrohdaten aus Oracle-Tabellen in Flat-Delimited-Dateien wie CSV-Dateien extrahieren, indem Sie standardmäßige Oracle-Dienstprogramme wie Oracle SQL Developer, SQL*Plus und SCLcl verwenden. Anschließend können Sie die flach getrennten Dateien mit gzip komprimieren und die komprimierten Dateien mit AzCopy oder Azure-Datentransporttools wie Azure Data Box in Azure Blob Storage hochladen.
Extrahieren Sie Tabellendaten so effizient wie möglich – insbesondere bei der Migration großer Faktentabellen. Verwenden Sie für Oracle-Tabellen Parallelität, um den Extraktionsdurchsatz zu maximieren. Sie können Parallelität erreichen, indem Sie mehrere Prozesse ausführen, die einzelne Datensegmente einzeln extrahieren, oder indem Sie Tools verwenden, die in der Lage sind, die parallele Extraktion durch Partitionierung zu automatisieren.
Tipp
Verwenden Sie Parallelität für die effizienteste Datenextraktion.
Wenn ausreichend Netzwerkbandbreite verfügbar ist, können Sie Daten aus einem lokalen Oracle-System direkt in Azure Synapse-Tabellen oder Azure Blob Data Storage extrahieren. Verwenden Sie dazu Data Factory-Prozesse, Azure Database Migration Service oder Datenmigrations- oder ETL-Produkte von Drittanbietern.
Extrahierte Datendateien sollten durch Trennzeichen getrennten Text enthalten – und im Format CSV, Optimized Row Columnar (ORC) oder Parquet vorliegen.
Weitere Informationen zur Datenmigration und zur ETL-Migration aus einer Oracle-Umgebung finden Sie unter Datenmigration, ETL und Ladevorgänge für die Oracle-Migration.
Leistungsempfehlungen für Oracle-Migrationsvorgänge
Das Ziel der Leistungsoptimierung ist die gleiche oder bessere Data Warehouse-Leistung nach der Migration zu Azure Synapse.
Ähnlichkeiten in Leistungsoptimierungskonzepten
Viele Leistungsoptimierungskonzepte für Oracle-Datenbanken gelten auch für Azure Synapse-Datenbanken. Beispiel:
Verwenden Sie die Datenverteilung, um zusammenzuführende Daten auf demselben Verarbeitungsknoten zusammenzufassen.
Verwenden Sie den kleinsten Datentyp für eine bestimmte Spalte, um Speicherplatz zu sparen und die Abfrageverarbeitung zu beschleunigen.
Stellen Sie sicher, dass zu verbindende Spalten denselben Datentyp haben, um die Join-Verarbeitung zu optimieren und die Notwendigkeit von Datentransformationen zu reduzieren.
Um dem Optimierer zu helfen, den besten Ausführungsplan zu erstellen, stellen Sie sicher, dass die Statistiken auf dem neuesten Stand sind.
Überwachen Sie die Leistung mithilfe integrierter Datenbankfunktionen, um sicherzustellen, dass Ressourcen effizient genutzt werden.
Tipp
Priorisieren Sie zu Beginn einer Migration die Vertrautheit mit Azure Synapse-Optimierungsoptionen.
Unterschiede in Leistungsoptimierungskonzepten
In diesem Abschnitt werden Unterschiede bei der Implementierung der Leistungsoptimierung auf niedriger Ebene zwischen Oracle und Azure Synapse hervorgehoben.
Datenverteilungsoptionen
Aus Leistungsgründen wurde Azure Synapse mit einer Architektur mit mehreren Knoten entwickelt und verwendet parallele Verarbeitung. Um die Tabellenleistung in Azure Synapse zu optimieren, können Sie mithilfe der DISTRIBUTION-Anweisung eine Datenverteilungsoption in CREATE TABLE-Anweisungen definieren. Sie können beispielsweise eine Hash-verteilte Tabelle angeben, die Tabellenzeilen mithilfe einer deterministischen Hash-Funktion über Compute-Knoten verteilt. Viele Oracle-Implementierungen, insbesondere ältere lokale Systeme, unterstützen diese Funktion nicht.
Im Gegensatz zu Oracle unterstützt Azure Synapse lokale Verknüpfungen zwischen einer kleinen Tabelle und einer großen Tabelle durch die Replikation kleiner Tabellen. Betrachten Sie beispielsweise eine kleine Dimensionstabelle und eine große Faktentabelle in einem Sternschemamodell. Azure Synapse kann die kleinere Dimensionstabelle auf alle Knoten replizieren, um sicherzustellen, dass für jeden Wert eines Joinschlüssels der großen Tabelle eine entsprechende, lokal verfügbare Dimensionszeile vorhanden ist. Der Aufwand der Dimensionstabellenreplikation ist bei einer kleinen Dimensionstabelle relativ gering. Bei großen Dimensionstabellen ist ein Hashverteilungsansatz besser geeignet. Weitere Informationen zu Datenverteilungsoptionen finden Sie unter Anleitung für das Verwenden replizierter Tabellen und Leitfaden zum Entwerfen von verteilten Tabellen.
Tipp
Die Hashverteilung verbessert die Abfrageleistung bei großen Faktentabellen. Roundrobinverteilung ermöglicht die Verbesserung der Ladegeschwindigkeit.
Die Hash-Verteilung kann für eine gleichmäßigere Verteilung der Basistabelle auf mehrere Spalten angewendet werden. Bei der mehrspaltigen Verteilung können Sie bis zu acht Spalten für die Verteilung auswählen. Dies reduziert nicht nur die Datenverzerrung im Laufe der Zeit, sondern verbessert auch die Abfrageleistung.
Hinweis
Die mehrspaltige Verteilung befindet sich derzeit in der Vorschau für Azure Synapse Analytics. Sie können die Multispaltenverteilung mit CREATE MATERIALIZED VIEW, CREATE TABLE und CREATE TABLE AS SELECT verwenden.
Verteilungsratgeber
In Azure Synapse SQL kann die Art und Weise, wie jede Tabelle verteilt wird, angepasst werden. Die Tabellenverteilungsstrategie wirkt sich erheblich auf die Abfrageleistung aus.
Der Verteilerberater ist ein neues Feature in Synapse SQL, das Abfragen analysiert und die besten Verteilungsstrategien für Tabellen empfiehlt, um die Abfrageleistung zu verbessern. Vom Berater zu berücksichtigende Abfragen können von Ihnen bereitgestellt oder aus Ihren in DMV verfügbaren historischen Abfragen entnommen werden.
Einzelheiten und Beispiele zur Verwendung des Verteilungsratgebers finden Sie unter Verteilungsratgeber in Azure Synapse SQL.
Datenindizierung
Azure Synapse unterstützt mehrere benutzerdefinierbare Indizierungsoptionen, die im Vergleich zu systemverwalteten Zonenzuordnungen in Oracle einen anderen Betrieb und eine andere Verwendung haben. Weitere Informationen zu den verschiedenen Indizierungsoptionen in Azure Synapse finden Sie unter Indizes von Tabellen in dedizierten SQL-Pools.
Indexdefinitionen innerhalb einer Oracle-Quellumgebung bieten einen nützlichen Hinweis auf die Datennutzung und die Kandidatenspalten für die Indizierung in der Azure Synapse-Umgebung. In der Regel müssen Sie nicht jeden Index aus einer Legacy-Oracle-Umgebung migrieren, da Azure Synapse sich nicht übermäßig auf Indizes verlässt und die folgenden Features implementiert, um eine hervorragende Leistung zu erzielen:
Parallele Abfrageverarbeitung
In-Memory-Daten- und Ergebnissatz-Caching.
Datenverteilung, z. B. Replikation kleiner Dimensionstabellen, um I/O zu reduzieren.
Datenpartitionierung
Im Data Warehouse eines Unternehmens können Faktentabellen Milliarden von Zeilen enthalten. Die Partitionierung optimiert die Verwaltung und Abfrage dieser Tabellen, indem sie aufgeteilt werden, um die Menge der von Abfragen verarbeiteten Daten zu reduzieren. In Azure Synapse definiert die CREATE TABLE-Anweisung die Partitionierungsspezifikation für eine Tabelle.
Sie können nur ein Feld pro Tabelle für die Partitionierung verwenden. Dieses Feld ist häufig ein Datumsfeld, da viele Abfragen nach Datum oder Datumsbereich gefiltert werden. Es ist möglich, die Partitionierung einer Tabelle nach dem anfänglichen Laden zu ändern, indem Sie die CREATE TABLE AS(CTAS)-Anweisung verwenden, um die Tabelle mit einer neuen Verteilung neu zu erstellen. Eine ausführliche Erläuterung der Partitionierung in Azure Synapse finden Sie unter Partitionieren von Tabellen im dedizierten SQL-Pool.
PolyBase oder COPY INTO zum Laden von Daten
PolyBase unterstützt das effiziente Laden großer Datenmengen in ein Data Warehouse mithilfe paralleler Ladedatenströme. Weitere Informationen finden Sie in der PolyBase-Datenladestrategie.
COPY INTO unterstützt auch die Datenerfassung mit hohem Durchsatz und Folgendes:
- Datenabruf aus allen Dateien innerhalb eines Ordners und Unterordners.
- Datenabruf aus mehreren Speicherorten im selben Speicherkonto. Sie können mehrere Speicherorte angeben, indem Sie durch Trennzeichen getrennte Pfade verwenden.
- Azure Data Lake Storage (ADLS) und Azure Blob Storage.
- Die Dateiformate CSV, PARQUET und ORC.
Tipp
Die empfohlene Methode zum Laden von Daten ist die Verwendung von COPY INTO zusammen mit dem PARQUET-Dateiformat.
Verwalten von Arbeitsauslastungen
Das Ausführen gemischter Workloads kann bei ausgelasteten Systemen zu Ressourcenproblemen führen. Ein erfolgreiches Workload-Management-Schema verwaltet Ressourcen effektiv, stellt eine hocheffiziente Ressourcennutzung sicher und maximiert die Kapitalrendite (ROI). Die Workload-Klassifizierung, die Workload-Priorität und die Workload-Isolation geben mehr Kontrolle darüber, wie die Workload Systemressourcen nutzt.
Der Workload-Management-Leitfaden beschreibt die Techniken zum Analysieren der Workload, Verwalten und Überwachen der Workload-Bedeutung und die Schritte zum Konvertieren einer Ressourcenklasse in eine Workload-Gruppe. Verwenden Sie das Azure-Portal und T-SQL-Abfragen auf DMVs, um die Workload zu überwachen und sicherzustellen, dass die entsprechenden Ressourcen effizient genutzt werden.
Nächste Schritte
Informationen zu ETL und zu Ladevorgängen für die Oracle-Migration finden Sie im nächsten Artikel in dieser Reihe: Datenmigration, ETL und Ladevorgänge für die Oracle-Migrationen.