Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Der intelligente Cache funktioniert nahtlos hinter den Kulissen und übernimmt die Zwischenspeicherung von Daten, um die Ausführung von Spark zu beschleunigen, wenn es aus Ihrem ADLS Gen2-Data Lake liest. Außerdem werden änderungen an den zugrunde liegenden Dateien automatisch erkannt und die Dateien im Cache automatisch aktualisiert, sodass Sie die neuesten Daten erhalten und wenn die Cachegröße ihren Grenzwert erreicht, gibt der Cache automatisch die am wenigsten gelesenen Daten frei, um Platz für neuere Daten zu schaffen. Diese Funktion senkt die Gesamtbetriebskosten, indem die Leistung bei nachfolgenden Lesevorgängen der Dateien, die im verfügbaren Cache für Parquet-Dateien gespeichert sind, um bis zu 65% und für CSV-Dateien um 50% verbessert wird.
Wenn Sie eine Datei oder Tabelle aus Ihrem Data Lake abfragen, ruft das Apache Spark-Modul in Synapse den ADLS Gen2-Remotespeicher auf, um die zugrunde liegenden Dateien zu lesen. Bei jeder Abfrageanforderung zum Lesen der gleichen Daten muss das Spark-Modul einen Aufruf an den ADLS Gen2-Remotespeicher durchführen. Dieser redundante Prozess fügt ihrer gesamten Verarbeitungszeit Latenz hinzu. Spark stellt ein Zwischenspeicherungsfeature bereit, das Sie manuell festlegen und den Cache freigeben müssen, um die Latenz zu minimieren und die Gesamtleistung zu verbessern. Dies kann jedoch dazu führen, dass die Ergebnisse veraltete Daten aufweisen, wenn sich die zugrunde liegenden Daten ändern.
Der intelligente Synapse-Cache vereinfacht diesen Prozess, indem jeder Lesevorgang innerhalb des zugewiesenen Cachespeicherplatzes auf jedem Spark-Knoten automatisch zwischengespeichert wird. Jede Anforderung für eine Datei überprüft, ob die Datei im Cache vorhanden ist, und vergleicht das Tag aus dem Remotespeicher, um festzustellen, ob die Datei veraltet ist. Wenn die Datei nicht vorhanden ist oder die Datei veraltet ist, liest Spark die Datei und speichert sie im Cache. Wenn der Cache voll wird, wird die Datei mit dem ältesten Zeitpunkt des letzten Zugriffs aus dem Cache entfernt, um aktuellere Dateien zuzulassen.
Der Synapse-Cache ist ein einzelner Cache pro Knoten. Wenn Sie einen Knoten mittlerer Größe verwenden und auf einem einzelnen Knoten mittlerer Größe mit zwei kleinen Executoren arbeiten, würden die beiden kleinen Executoren denselben Cache gemeinsam nutzen.
Aktivieren oder Deaktivieren des Caches
Die Cachegröße kann basierend auf dem Prozentsatz der gesamt verfügbaren Datenträgergröße für jeden Apache Spark-Pool angepasst werden. Standardmäßig ist der Cache auf "deaktiviert" festgelegt, aber er ist so einfach wie das Verschieben der Schiebereglerleiste von 0 (deaktiviert) auf den gewünschten Prozentsatz für die Cachegröße, um sie zu aktivieren. Wir reservieren ein Minimum von 20 % des verfügbaren Speicherplatzes für die Umlagerung von Daten. Bei intensiven Arbeitsauslastungen können Sie die Cachegröße minimieren oder den Cache deaktivieren. Es wird empfohlen, mit einer Cachegröße von 50% zu beginnen und bei Bedarf anzupassen. Es ist wichtig zu beachten, dass, wenn Ihr Workload viel Speicherplatz auf der lokalen SSD für die Zwischenspeicherung von Shuffle oder das Caching von RDD erfordert, Sie erwägen sollten, die Cachegröße zu reduzieren, um die Wahrscheinlichkeit eines Fehlers aufgrund unzureichenden Speichers zu verringern. Die tatsächliche Größe des verfügbaren Speichers und der Cachegröße für jeden Knoten hängt von der Knotenfamilie und der Knotengröße ab.
Aktivieren des Caches für neue Spark-Pools
Navigieren Sie beim Erstellen eines neuen Spark-Pools unter der Registerkarte "Zusätzliche Einstellungen ", um den Schieberegler für den intelligenten Cache zu finden, den Sie zur bevorzugten Größe verschieben können, um das Feature zu aktivieren.

Aktivieren/Deaktivieren des Caches für vorhandene Spark-Pools
Navigieren Sie für vorhandene Spark-Pools zu den Skalierungseinstellungen Ihres Apache Spark-Pools, um ihn zu aktivieren, indem Sie den Schieberegler auf einen Wert von mehr als 0 verschieben oder deaktivieren, indem Sie den Schieberegler auf 0 verschieben.
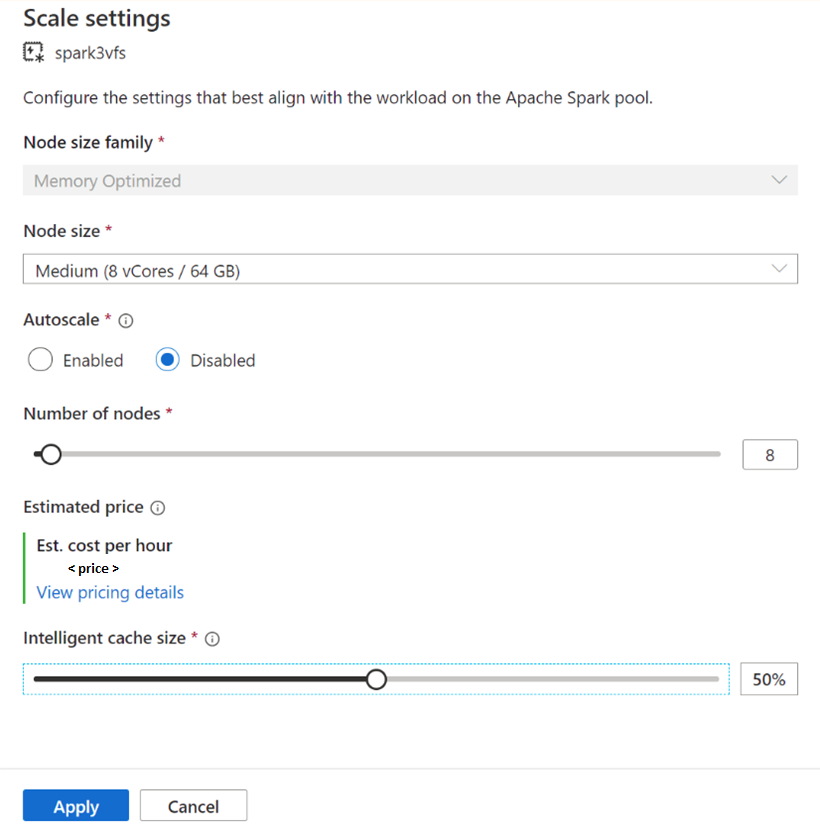
Ändern der Cachegröße für vorhandene Spark-Pools
Um die Größe des intelligenten Caches eines Pools zu ändern, müssen Sie einen Neustart erzwingen, wenn der Pool über aktive Sitzungen verfügt. Wenn der Spark-Pool über eine aktive Sitzung verfügt, wird " Erzwingen neuer Einstellungen" angezeigt. Klicken Sie auf das Kontrollkästchen, und wählen Sie Übernehmen aus, um die Sitzung automatisch neu zu starten.

Aktivieren und Deaktivieren des Caches innerhalb der Sitzung
Deaktivieren Sie den intelligenten Cache in einer Sitzung ganz einfach, indem Sie den folgenden Code in Ihrem Notizbuch ausführen:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
Und aktivieren Sie es durch Ausführen folgender Schritte:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Wann sollte der intelligente Cache und wann nicht verwendet werden?
Dieses Feature wird Ihnen zugute kommen, wenn:
Ihre Workload erfordert das mehrfache Lesen derselben Datei, und die Dateigröße kann in den Cache passen.
Ihre Workload verwendet Deltatabellen, Parquet-Dateiformate und CSV-Dateien.
Sie verwenden Apache Spark 3 oder höher in Azure Synapse.
Die Vorteile dieses Features werden nicht angezeigt, wenn:
Sie lesen eine Datei, die die Cachegröße überschreitet, weil der Anfang der Datei ausgelagert werden könnte und nachfolgende Abfragen die Daten erneut aus dem Remotespeicher abrufen müssen. In diesem Fall werden keine Vorteile des intelligenten Caches angezeigt, und Sie können die Cachegröße und/oder die Knotengröße erhöhen.
Ihre Workload erfordert Umlagerung von Daten in großem Maßstab. Dann wird durch das Deaktivieren des intelligenten Caches verfügbarer Speicherplatz freigegeben, um ein Fehlschlagen Ihres Auftrags aufgrund von unzureichendem Speicherplatz zu verhindern.
Sie verwenden einen Spark 3.3-Pool, sie müssen Ihren Pool auf die neueste Version von Spark aktualisieren.
Erfahren Sie mehr
Weitere Informationen zu Apache Spark finden Sie in den folgenden Artikeln:
Informationen zum Konfigurieren von Spark-Sitzungseinstellungen
- Konfigurieren von Spark-Sitzungseinstellungen
- Festlegen von benutzerdefinierten Spark/Pyspark-Konfigurationen
Nächste Schritte
Ein Apache Spark-Pool bietet Open-Source-Big Data-Computefunktionen, in denen Daten geladen, modelliert, verarbeitet und verteilt werden können, um schnellere Analysedaten zu erhalten. Um mehr darüber zu erfahren, wie Sie ein Setup erstellen, um Ihre Spark-Workloads auszuführen, besuchen Sie die folgenden Tutorials.