Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure Synapse Analytics bietet verschiedene Analysemodule, mit denen Sie Ihre Daten aufnehmen, transformieren, modellieren, analysieren und verteilen können. Ein Apache Spark-Pool bietet Open-Source-Big Data-Computefunktionen. Nachdem Sie einen Apache Spark-Pool in Ihrem Synapse-Arbeitsbereich erstellt haben, können Daten geladen, modelliert, verarbeitet und verteilt werden, um schnellere Analyseerblicke zu erhalten.
In dieser Schnellstartanleitung erfahren Sie, wie Sie mithilfe des Azure-Portals einen Apache Spark-Pool in einem Synapse-Arbeitsbereich erstellen.
Von Bedeutung
Die Abrechnung für Spark-Instanzen erfolgt anteilsmäßig auf Minutenbasis und ist unabhängig von der Verwendung. Fahren Sie daher Ihre Spark-Instanz herunter, wenn Sie sie nicht mehr benötigen, oder legen Sie ein kurzes Timeout fest. Weitere Informationen finden Sie im Abschnitt Bereinigen von Ressourcen in diesem Artikel.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Voraussetzungen
- Sie benötigen ein Azure-Abonnement. Erstellen Sie bei Bedarf ein kostenloses Azure-Konto
- Sie werden den Synapse-Arbeitsbereich verwenden.
Melden Sie sich auf dem Azure-Portal an.
Anmelden beim Azure-Portal
Navigieren zum Synapse-Arbeitsbereich
Navigieren Sie zum Synapse-Arbeitsbereich, 0in dem der Apache Spark-Pool erstellt werden soll, indem Sie den Dienstnamen (oder direkt den Ressourcennamen) in die Suchleiste eingeben.
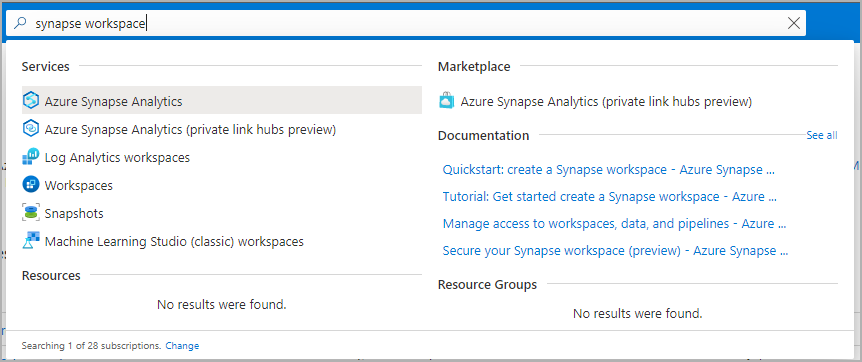
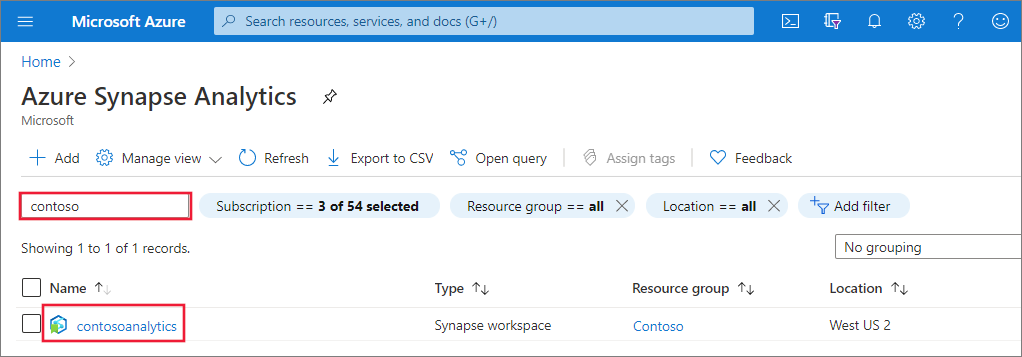
Geben Sie in der Liste der Arbeitsbereiche den Namen (oder einen Teil des Namens) des zu öffnenden Arbeitsbereichs ein. In diesem Beispiel verwenden wir einen Arbeitsbereich namens contosoanalytics.


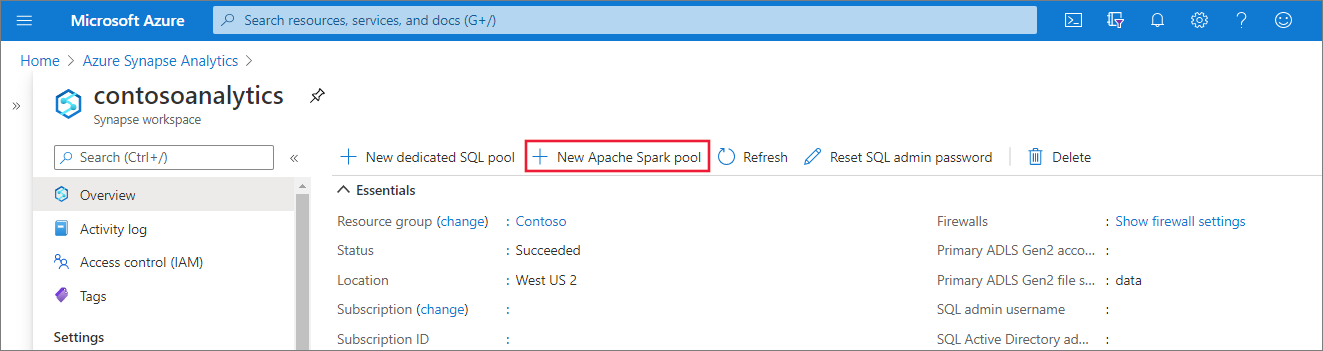
Erstellen eines neuen Apache Spark-Pools
Wählen Sie im Synapse-Arbeitsbereich, in dem Sie den Apache Spark-Pool erstellen möchten, den Neuen Apache Spark-Pool aus.
Geben Sie auf der Registerkarte Grundeinstellungen die folgenden Informationen ein:
Konfiguration Vorgeschlagener Wert Beschreibung Name des Apache Spark-Pools Ein gültiger Poolname, z. B. contososparkDies ist der Name des Apache Spark-Pools. Knotengröße Klein (4 vCPUs/32 GB) Legen Sie diese Einstellung auf die kleinste Größe fest, um die Kosten für diesen Schnellstart zu senken. Automatische Skalierung Arbeitsunfähig Für diese Schnellstartanleitung ist keine automatische Skalierung erforderlich. Anzahl von Knoten 5 Verwenden Sie eine kleine Größe, um die Kosten für diese Schnellstartanleitung zu begrenzen. 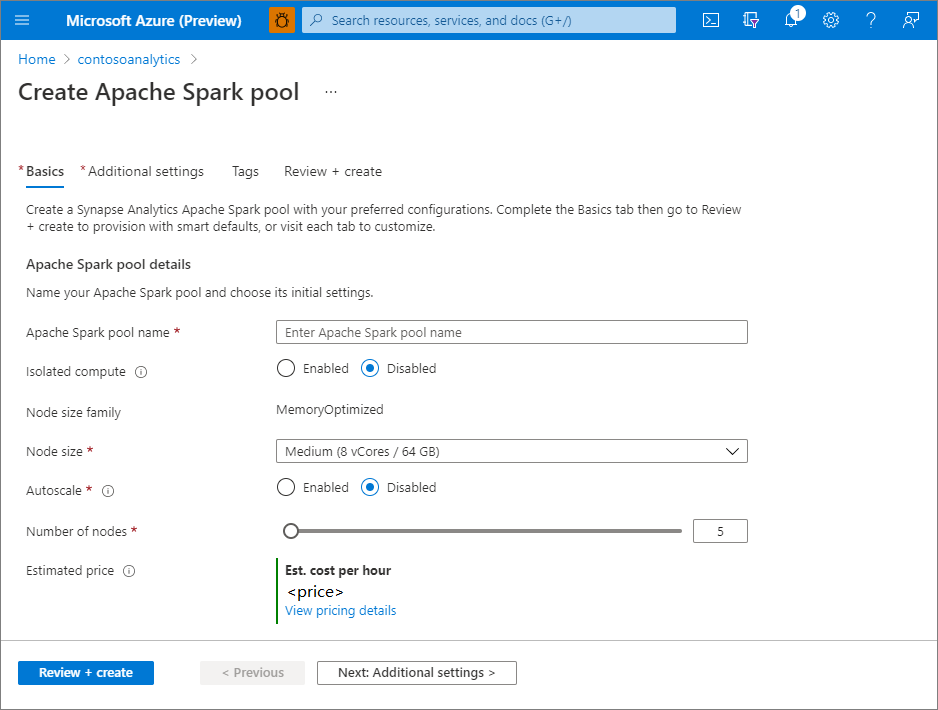
Von Bedeutung
Für die Namen, die Apache Spark-Pools verwendet können, gelten bestimmte Einschränkungen. Namen dürfen nur Buchstaben oder Ziffern enthalten und höchstens 15 Zeichen lang sein, müssen mit einem Buchstaben beginnen, dürfen keine reservierten Wörter enthalten und müssen im Arbeitsbereich eindeutig sein.
Wählen Sie "Weiter" aus: zusätzliche Einstellungen und überprüfen Sie die Standardeinstellungen. Ändern Sie keine Standardeinstellungen.
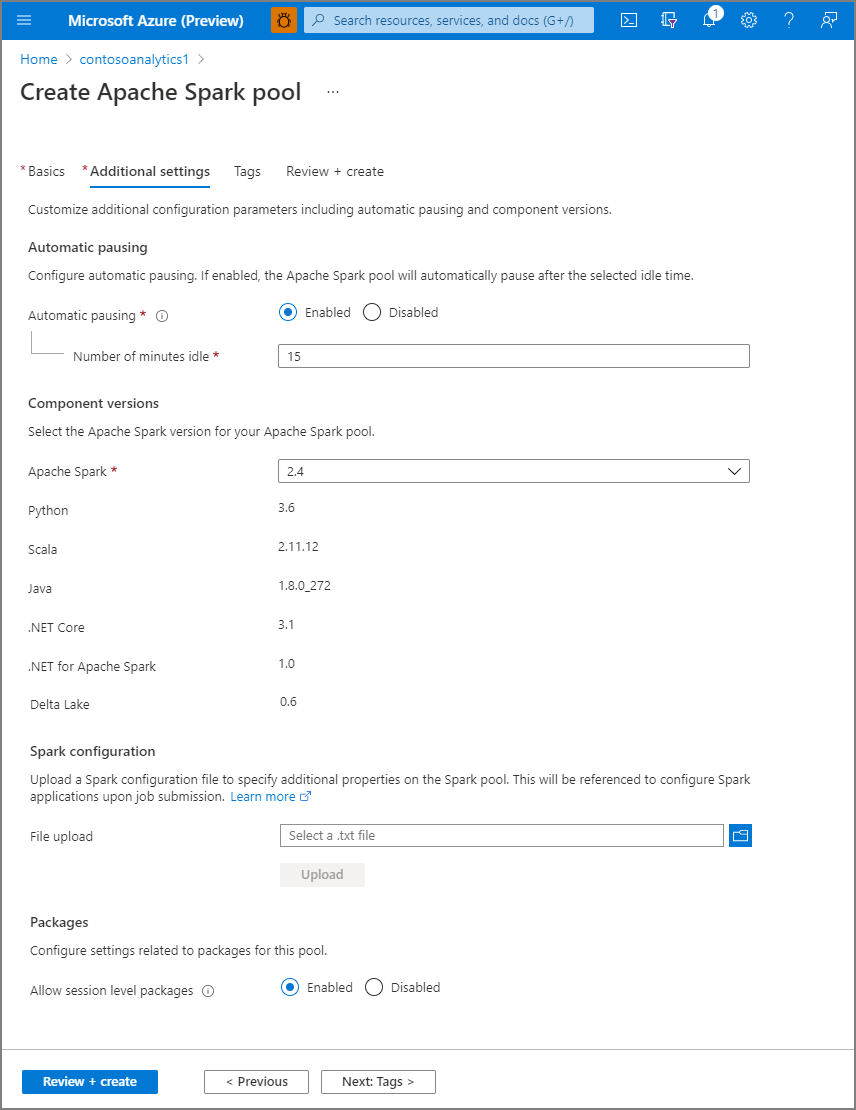
Wählen Sie "Weiter" aus: Tags. Erwägen Sie die Verwendung von Azure-Tags. Beispielsweise das Tag „Owner“ oder „CreatedBy“, um zu identifizieren, wer die Ressource erstellt hat, und das Tag „Environment“, um zu identifizieren, ob sich diese Ressource in Produktion, Entwicklung usw. befindet. Weitere Informationen finden Sie unter Entwickeln Ihrer Benennungs- und Kennzeichnungsstrategie für Azure-Ressourcen.
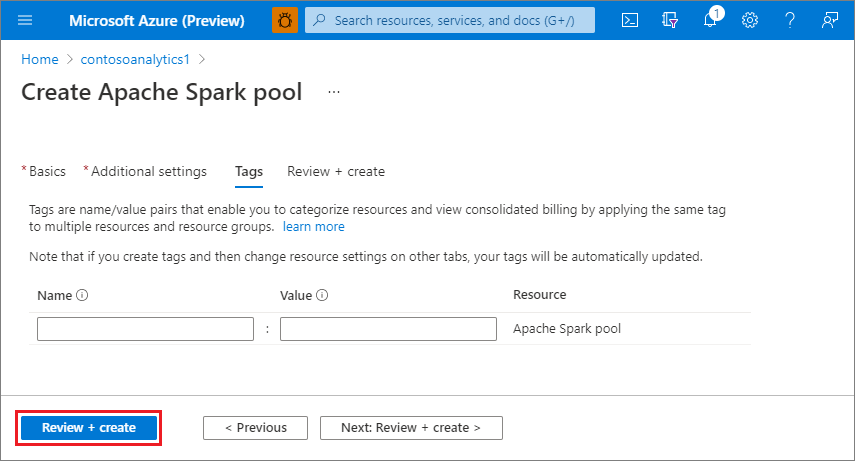
Klicken Sie auf Überprüfen + erstellen.
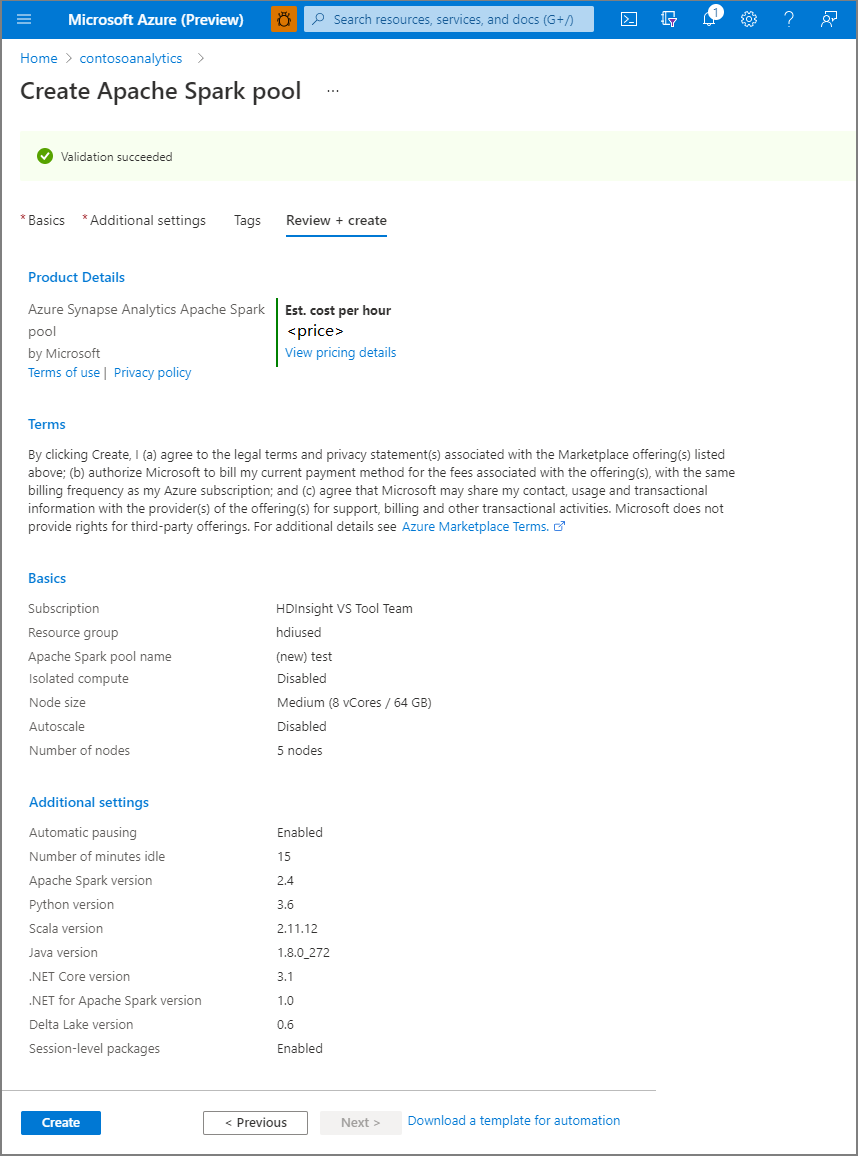
Stellen Sie sicher, dass die Details basierend auf den zuvor eingegebenen Details korrekt aussehen, und wählen Sie "Erstellen" aus.
An diesem Punkt beginnt der Ressourcenbereitstellungsfluss und zeigt an, wann er abgeschlossen ist.
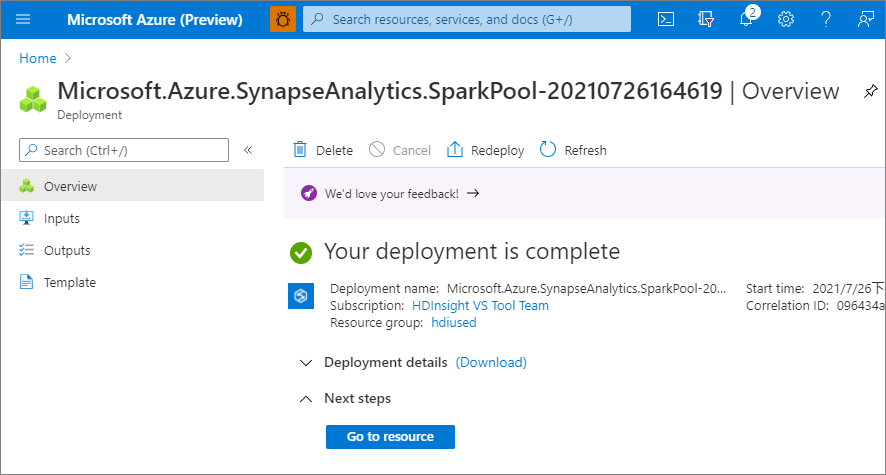
Nach Abschluss der Bereitstellung wird beim Navigieren zum Arbeitsbereich ein neuer Eintrag für den neu erstellten Apache Spark-Pool angezeigt.
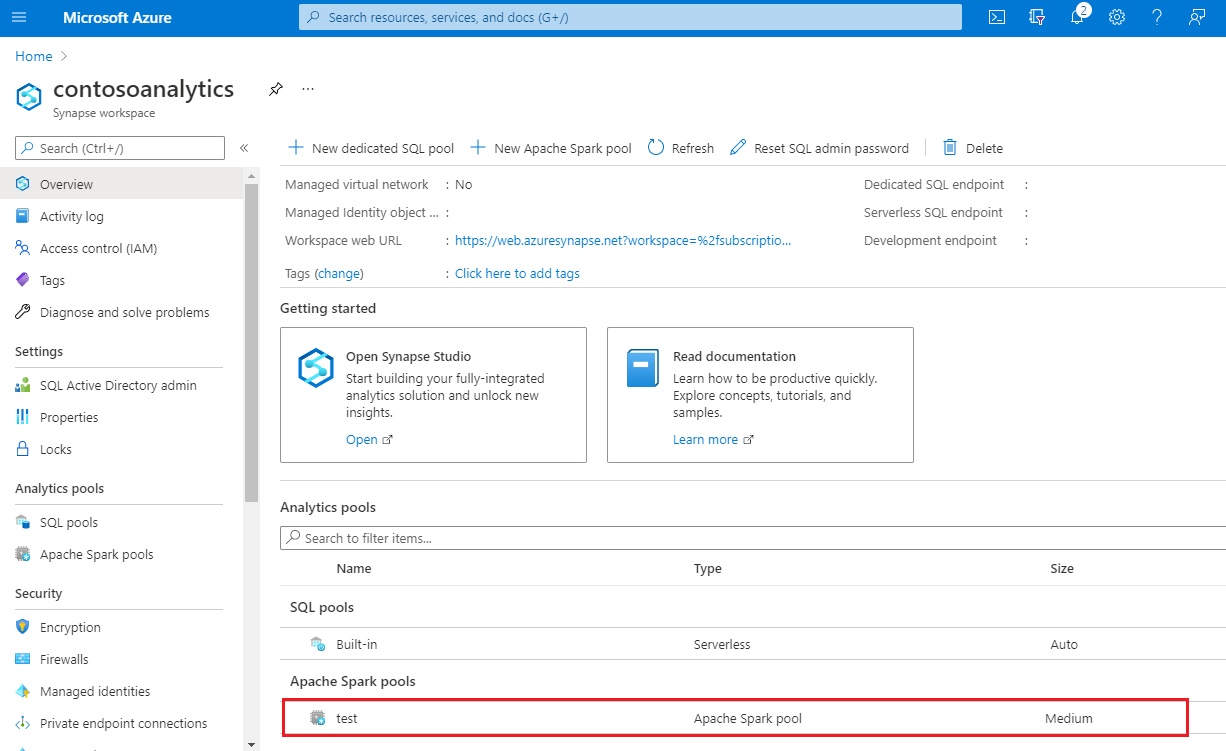
An diesem Punkt werden keine Ressourcen ausgeführt, keine Gebühren für Spark, Sie haben Metadaten zu den Spark-Instanzen erstellt, die Sie erstellen möchten.







Bereinigen von Ressourcen
Die folgenden Schritte löschen den Apache Spark-Pool aus dem Arbeitsbereich.
Warnung
Durch das Löschen eines Apache Spark-Pools wird das Analysemodul aus dem Arbeitsbereich entfernt. Es ist nicht mehr möglich, eine Verbindung mit dem Pool herzustellen, und alle Abfragen, Pipelines und Notizbücher, die diesen Apache Spark-Pool verwenden, funktionieren nicht mehr.
Wenn Sie den Apache Spark-Pool löschen wollen, führen Sie die folgenden Schritte aus:
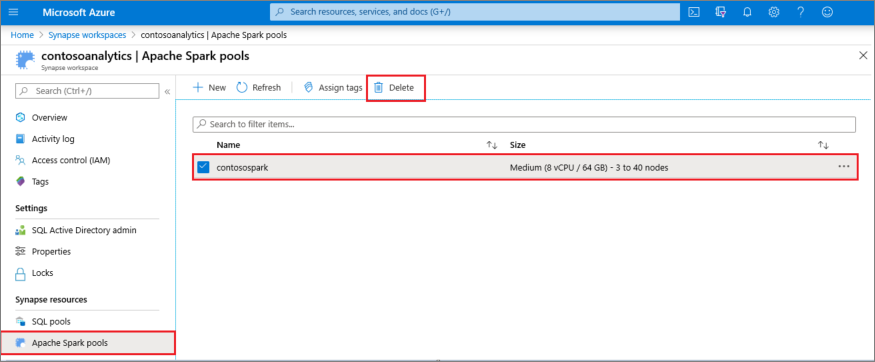
- Navigieren Sie im Arbeitsbereich zum Bereich Apache Spark Pools.
- Wählen Sie den Apache Spark-Pool aus, der gelöscht werden soll (in diesem Fall contosospark).
- Klicken Sie auf Löschen.
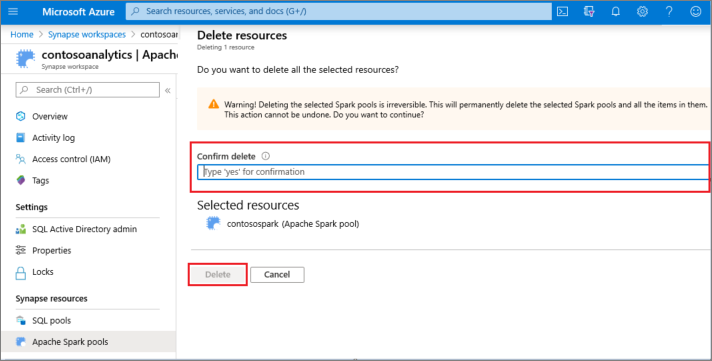
- Bestätigen Sie den Löschvorgang, und wählen Sie die Schaltfläche "Löschen " aus.
- Wenn der Vorgang erfolgreich abgeschlossen wurde, wird der Apache Spark-Pool nicht mehr in den Arbeitsbereichsressourcen aufgeführt.
