Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tipp
Dieser Inhalt ist ein Auszug aus dem eBook, Architecting Cloud Native .NET Applications for Azure, verfügbar auf .NET Docs oder als kostenlose herunterladbare PDF, die offline gelesen werden kann.

Die erste Verteidigungslinie ist anwendungsresilienz.
Sie könnten zwar viel Zeit in das Schreiben Ihres eigenen Resilienzframeworks investieren, aber solche Produkte sind bereits vorhanden.
Polly ist eine umfassende .NET-Resilienz- und vorübergehende Fehlerbehandlungsbibliothek, mit der Entwickler Resilienzrichtlinien fließend und threadsicher ausdrücken können. Polly zielt auf Anwendungen ab, die mit .NET Framework oder .NET 7 erstellt wurden. In der folgenden Tabelle werden die als policies bezeichneten Resilienzfeatures beschrieben, die in der Polly-Bibliothek verfügbar sind. Sie können einzeln angewendet oder gruppiert werden.
| Politik | Erfahrung |
|---|---|
| Erneut versuchen | Konfiguriert Wiederholungsvorgänge für bestimmte Vorgänge. |
| Trennschalter | Blockiert angeforderte Vorgänge für einen vordefinierten Zeitraum, wenn Fehler einen konfigurierten Schwellenwert überschreiten |
| Auszeit | Legt den Grenzwert für die Dauer fest, für die ein Anrufer auf eine Antwort warten kann. |
| Schott | Schränkt Aktionen auf den Ressourcenpool mit fester Größe ein, um zu verhindern, dass fehlerhafte Aufrufe eine Ressource überschwemmen. |
| Zwischenspeicher | Speichert Antworten automatisch. |
| Ausweichplan | Definiert das strukturierte Verhalten bei einem Fehler. |
Beachten Sie, wie in der vorherigen Abbildung die Resilienzrichtlinien auf Anforderungsnachrichten angewendet werden, unabhängig davon, ob sie von einem externen Client oder Back-End-Dienst stammen. Ziel ist es, die Anforderung für einen Dienst zu entschädigen, der möglicherweise momentan nicht verfügbar ist. Diese kurzlebigen Unterbrechungen manifestieren sich in der Regel mit den HTTP-Statuscodes, die in der folgenden Tabelle dargestellt sind.
| HTTP-Statuscode | Ursache |
|---|---|
| 404 | Nicht gefunden |
| 408 | Anforderungszeitlimit |
| 429 | Zu viele Anforderungen (wahrscheinlich erfolgt eine Drosselung) |
| 502 | Ungültiger Gateway |
| 503 | Dienst nicht verfügbar |
| 504 | Gatewaytimeout |
Frage: Würden Sie einen HTTP-Statuscode von 403 wiederholen – Verboten? Nein. Hier funktioniert das System ordnungsgemäß, informiert jedoch den Anrufer, dass er nicht zum Ausführen des angeforderten Vorgangs autorisiert ist. Es muss darauf geachtet werden, nur die Vorgänge zu wiederholen, die durch Fehler verursacht werden.
Wie in Kapitel 1 empfohlen, sollten Microsoft-Entwickler, die cloudeigene Anwendungen erstellen, auf die .NET-Plattform abzielen. Version 2.1 führte die HTTPClientFactory-Bibliothek zum Erstellen von HTTP-Clientinstanzen für die Interaktion mit URL-basierten Ressourcen ein. Die Factoryklasse ersetzt die ursprüngliche HTTPClient-Klasse und unterstützt viele erweiterte Features, von denen eine enge Integration in die Polly-Resilienzbibliothek ist. Damit können Sie problemlos Resilienzrichtlinien in der Anwendungsstartklasse definieren, um Teilfehler und Konnektivitätsprobleme zu behandeln.
Als Nächstes gehen wir auf die Retry- und Circuit Breaker-Muster ein.
Wiederholungsmuster
Aufrufe von Diensten und Cloudressourcen können in einer verteilten Cloud-nativen Umgebung aufgrund vorübergehender (kurzlebiger) Fehler fehlschlagen, die sich in der Regel nach kurzer Zeit selbst korrigieren. Die Implementierung einer Wiederholungsstrategie hilft einem cloudeigenen Dienst, diese Szenarien zu mindern.
Das Wiederholungsmuster ermöglicht es einem Dienst, einen fehlgeschlagenen Anforderungsvorgang mit einer exponentiell steigenden Wartezeit (konfigurierbar) zu wiederholen. Abbildung 6-2 zeigt einen Wiederholungsversuch in Aktion.
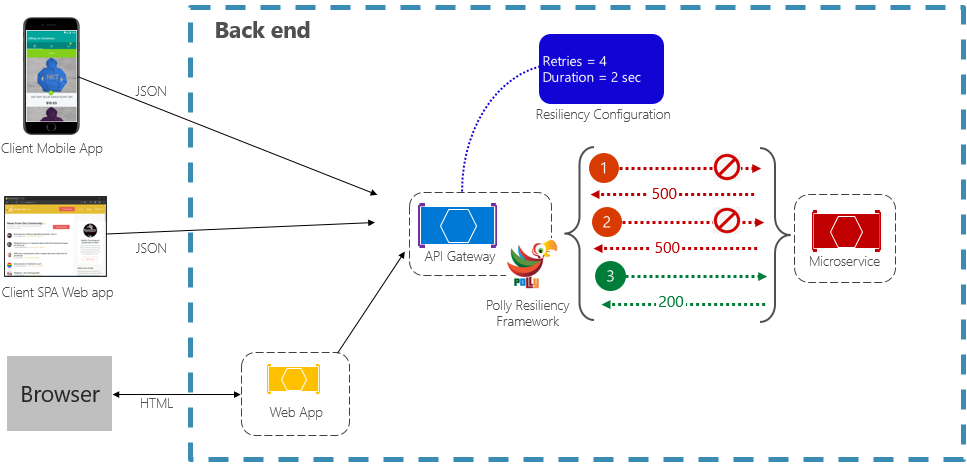
Abbildung 6-2. Retry-Muster in Aktion
In der obigen Abbildung wurde ein Wiederholungsmuster für einen Anforderungsvorgang implementiert. Er ist so konfiguriert, dass bis zu vier Wiederholungsversuche zugelassen werden, bevor ein Fehler auftritt. Das Backoffintervall (Wartezeit) beginnt bei zwei Sekunden und verdoppelt sich exponentiell für jeden weiteren Versuch.
- Der erste Aufruf schlägt fehl und gibt einen HTTP-Statuscode von 500 zurück. Die Anwendung wartet zwei Sekunden lang und ruft den Aufruf erneut ab.
- Der zweite Aufruf schlägt ebenfalls fehl und gibt einen HTTP-Statuscode von 500 zurück. Die Anwendung verdoppelt nun das Backoff-Intervall auf vier Sekunden und wiederholt den Aufruf.
- Schließlich ist der dritte Aufruf erfolgreich.
- In diesem Szenario können bis zu vier Wiederholungsversuche bei gleichzeitiger Verdopplung der Backoffdauer durchgeführt werden, bevor der Aufruf als fehlgeschlagen eingestuft wird.
- Wenn auch der 4. Wiederholungsversuch erfolglos bleibt, wird eine Fallbackrichtlinie aufgerufen, um das Problem ordnungsgemäß zu lösen.
Es ist wichtig, vor einem erneuten Aufruf den Backoffzeitraum zu erhöhen, damit der Dienst Zeit zur Selbstkorrektur erhält. Es ist eine bewährte Methode, einen exponentiell steigenden Backoff (Verdoppelung des Zeitraums für jeden Wiederholungstermin) zu implementieren, um eine angemessene Korrekturzeit zu ermöglichen.
Muster „Trennschalter“
Während das Wiederholungsmuster helfen kann, eine in einem teilweisen Fehler gefangene Anforderung zu retten, gibt es Situationen, in denen Fehler durch unerwartete Ereignisse verursacht werden können, die längere Zeit in Anspruch nehmen, um gelöst zu werden. Zu unterscheiden sind unterschiedliche Schweregrade, die von einem Teilverlust der Konnektivität bis hin zum vollständigen Ausfall des Diensts reichen können. In diesen Situationen ist es sinnlos, dass eine Anwendung einen Vorgang wiederholen kann, der unwahrscheinlich ist, dass er erfolgreich ist.
Um dies noch schlimmer zu machen, kann das Ausführen kontinuierlicher Wiederholungsvorgänge für einen nicht reaktionsfähigen Dienst Sie in ein selbst auferlegtes Denial-of-Service-Szenario verschieben, in dem Sie Ihren Dienst mit kontinuierlichen Aufrufen erschöpfender Ressourcen wie Arbeitsspeicher, Threads und Datenbankverbindungen überfluten, was zu Fehlern in nicht verwandten Teilen des Systems führt, die dieselben Ressourcen verwenden.
In diesen Situationen wäre es vorzuziehen, dass der Vorgang sofort fehlschlägt und nur versucht, den Dienst aufzurufen, wenn er wahrscheinlich erfolgreich ist.
Das Schaltkreisbrechermuster kann verhindern, dass eine Anwendung wiederholt versucht, einen Vorgang auszuführen, der wahrscheinlich fehlschlägt. Nach einer vordefinierten Anzahl fehlgeschlagener Aufrufe blockiert sie den gesamten Datenverkehr an den Dienst. In regelmäßigen Abständen kann ein Testanruf ermitteln, ob der Fehler behoben wurde. Abbildung 6-3 zeigt das Schaltkreistrennmuster in Aktion.
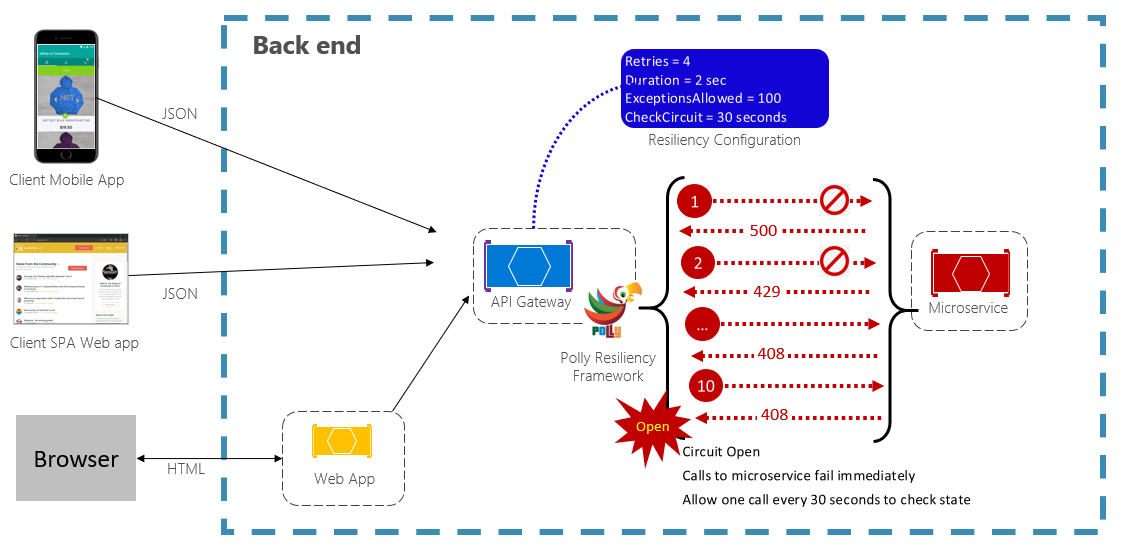
Abbildung 6-3. Schaltkreisbrechermuster in Aktion
In der obigen Abbildung wurde dem ursprünglichen Wiederholungsmuster ein Circuit Breaker-Muster hinzugefügt. Beachten Sie, dass nach 100 fehlgeschlagenen Aufrufen das Circuit Breaker-Muster greift und keine weiteren Aufrufe des Diensts mehr zugelassen werden. Der Wert für CheckCircuit, der auf 30 Sekunden festgelegt ist, gibt an, wie oft die Bibliothek eine Anfrage zur Weiterleitung an den Dienst zulässt. Wenn dieser Aufruf erfolgreich ist, wird der Schaltkreis geschlossen, und der Dienst steht wieder für den Datenverkehr zur Verfügung.
Beachten Sie, dass das Circuit Breaker-Muster einen anderen Zweck verfolgt als das Retry-Muster. Das Wiederholungsmuster ermöglicht es einer Anwendung, einen Vorgang erneut zu versuchen, in der Erwartung, dass er erfolgreich ist. Das Schaltkreisbrechermuster verhindert, dass eine Anwendung einen Vorgang ausführt, der wahrscheinlich fehlschlägt. In der Regel kombiniert eine Anwendung diese beiden Muster mithilfe des Wiederholungsmusters, um einen Vorgang über einen Schaltkreisschalter aufzurufen.
Testen der Resilienz
Tests für Resilienz können nicht immer auf die gleiche Weise durchgeführt werden, wie Sie Anwendungsfunktionen testen (durch Ausführen von Komponententests, Integrationstests usw.). Stattdessen müssen Sie testen, wie sich die End-to-End-Workload unter Fehlerbedingungen verhält, die nur zeitweise auftreten. Beispiel: Fehler provozieren durch das Abstürzen von Prozessen, abgelaufene Zertifikate, abhängige Dienste nicht verfügbar machen, usw. Frameworks wie chaos-monkey können für solche Chaostests verwendet werden.
Die Anwendungsresilienz ist ein Muss für die Behandlung problematischer angeforderter Vorgänge. Aber es ist nur die Hälfte der Geschichte. Als Nächstes behandeln wir Resilienzfeatures, die in der Azure-Cloud verfügbar sind.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.