Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie die Nachfrage nach einem Fahrradverleihdienst mithilfe einer univariaten Zeitreihenanalyse zu Daten prognostizieren, die in einer SQL Server-Datenbank mit ML.NET gespeichert sind.
In diesem Tutorial erfahren Sie, wie:
- Verstehen des Problems
- Laden von Daten aus einer Datenbank
- Erstellen eines Prognosemodells
- Auswerten des Prognosemodells
- Speichern eines Prognosemodells
- Verwenden eines Prognosemodells
Voraussetzungen
- Visual Studio 2022 oder höher mit installierter .NET Desktop Development-Workload .
Übersicht über das Zeitreihenprognosebeispiel
Dieses Beispiel ist eine C#-Konsolenanwendung , die die Nachfrage nach Fahrrädern mithilfe eines univariaten Zeitreihenanalysealgorithmus als Singular Spectrum Analysis prognostiziert. Der Code für dieses Beispiel finden Sie im Repository "dotnet/machinelearning-samples " auf GitHub.
Verstehen des Problems
Um einen effizienten Betrieb auszuführen, spielt die Bestandsverwaltung eine wichtige Rolle. Zu viel von einem Produkt vorrätig zu haben, bedeutet, dass nicht verkaufte Produkte, die in den Regalen sitzen, keinen Umsatz generieren. Zu wenig Produkt zu haben führt zu verlorenen Verkäufen und Kunden, die von Wettbewerbern kaufen. Aus diesem Grund stellt sich häufig die Frage, wie viel Lagerbestand optimal vorrätig gehalten werden sollte. Zeitreihenanalysen helfen dabei, diese Fragen zu beantworten, indem sie historische Daten betrachten, Muster identifizieren und diese Informationen verwenden, um in Zukunft Werte zu prognostizieren.
Die In diesem Lernprogramm verwendete Methode zum Analysieren von Daten ist eine univariate Zeitreihenanalyse. Univariate Zeitreihenanalyse betrachtet eine einzelne numerische Beobachtung über einen bestimmten Zeitraum in bestimmten Intervallen wie monatlichen Verkäufen.
Der in diesem Lernprogramm verwendete Algorithmus ist Singular Spectrum Analysis(SSA). SSA funktioniert durch Dekompilieren einer Zeitreihe in eine Reihe von Prinzipalkomponenten. Diese Komponenten können als Teile eines Signals interpretiert werden, die Trends, Lärm, Saisonalität und viele andere Faktoren entsprechen. Anschließend werden diese Komponenten rekonstruiert und verwendet, um in Zukunft Werte zu prognostizieren.
Erstellen einer Konsolenanwendung
Erstellen Sie eine C# -Konsolenanwendung namens "BikeDemandForecasting". Klicken Sie auf die Schaltfläche Weiter .
Wählen Sie .NET 8 als zu verwendende Framework aus. Klicken Sie auf die Schaltfläche " Erstellen ".
Installiere die Version des Microsoft.ML NuGet-Pakets
Hinweis
In diesem Beispiel wird die neueste stabile Version der erwähnten NuGet-Pakete verwendet, sofern nichts anderes angegeben ist.
- Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf Ihr Projekt, und wählen Sie "NuGet-Pakete verwalten" aus.
- Wählen Sie "nuget.org" als Paketquelle aus, wählen Sie die Registerkarte " Durchsuchen " aus, suchen Sie nach Microsoft.ML.
- Aktivieren Sie das Kontrollkästchen "Vorabversionen einschließen ".
- Wählen Sie die Schaltfläche Installieren aus.
- Wählen Sie im Dialogfeld "Vorschauänderungen" die Schaltfläche "OK" und dann im Dialogfeld "Lizenzakzeptanz" die Schaltfläche "Ich stimme zu", wenn Sie den Lizenzbedingungen für die aufgeführten Pakete zustimmen.
- Wiederholen Sie diese Schritte für System.Data.SqlClient und Microsoft.ML.TimeSeries.
Vorbereiten und Verstehen der Daten
- Erstellen Sie ein Verzeichnis namens "Daten".
- Laden Sie die DailyDemand.mdf Datenbankdatei herunter, und speichern Sie sie im Datenverzeichnis .
Hinweis
Die in diesem Lernprogramm verwendeten Daten stammen aus dem UCI Bike Sharing Dataset. Hadi Fanaee-T und João Gama, "Event labeling combining ensemble detectors and background knowledge", Progress in Artificial Intelligence (2013): S. 1-15, Springer Berlin Heidelberg, Web Link.
Das ursprüngliche Dataset enthält mehrere Spalten, die Saisonalität und Wetter entsprechen. Aus Platzgründen und da der in diesem Lernprogramm verwendete Algorithmus nur die Werte aus einer einzelnen numerischen Spalte erfordert, wurde das ursprüngliche Dataset komprimiert, um nur die folgenden Spalten einzuschließen:
- dteday: Das Datum der Beobachtung.
- Jahr: Das codierte Jahr der Beobachtung (0=2011, 1=2012).
- cnt: Die Gesamtzahl der Fahrradverleiher für diesen Tag.
Das ursprüngliche Dataset wird einer Datenbanktabelle mit dem folgenden Schema in einer SQL Server-Datenbank zugeordnet.
CREATE TABLE [Rentals] (
[RentalDate] DATE NOT NULL,
[Year] INT NOT NULL,
[TotalRentals] INT NOT NULL
);
Es folgt ein Beispiel für die Daten:
| Mietdatum | Jahr | TotalRentals |
|---|---|---|
| 1/1/2011 | 0 | 985 |
| 1/2/2011 | 0 | 801 |
| 1/3/2011 | 0 | 1349 |
Erstellen von Eingabe- und Ausgabeklassen
Öffnen Sie Program.cs Datei, und ersetzen Sie die vorhandenen
usingDirektiven durch Folgendes:using Microsoft.ML; using Microsoft.ML.Data; using Microsoft.ML.Transforms.TimeSeries; using System.Data.SqlClient;Klasse erstellen
ModelInput. Fügen Sie unter derProgramKlasse den folgenden Code hinzu.public class ModelInput { public DateTime RentalDate { get; set; } public float Year { get; set; } public float TotalRentals { get; set; } }Die
ModelInputKlasse enthält die folgenden Spalten:- Beobachtungsdatum: Das Datum der Beobachtung.
- Jahr: Das codierte Jahr der Beobachtung (0=2011, 1=2012).
- TotalRentals: Die Gesamtzahl der Fahrradmieten für diesen Tag.
Erstellen Sie
ModelOutputeine Klasse unterhalb der neu erstelltenModelInputKlasse.public class ModelOutput { public float[] ForecastedRentals { get; set; } public float[] LowerBoundRentals { get; set; } public float[] UpperBoundRentals { get; set; } }Die
ModelOutputKlasse enthält die folgenden Spalten:- ForecastedRentals: Die prognostizierten Werte für den prognostizierten Zeitraum.
- LowerBoundRentals: Die prognostizierten Mindestwerte für den prognostizierten Zeitraum.
- UpperBoundRentals: Die prognostizierten Höchstwerte für den prognostizierten Zeitraum.
Definieren von Pfaden und Initialisieren von Variablen
Unter den
using-Direktiven werden Variablen definiert, um den Speicherort Ihrer Daten, die Verbindungszeichenfolge und den Speicherort des trainierten Modells festzulegen.string rootDir = Path.GetFullPath(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "../../../")); string dbFilePath = Path.Combine(rootDir, "Data", "DailyDemand.mdf"); string modelPath = Path.Combine(rootDir, "MLModel.zip"); var connectionString = $"Data Source=(LocalDB)\\MSSQLLocalDB;AttachDbFilename={dbFilePath};Integrated Security=True;Connect Timeout=30;";Initialisieren Sie die Variable
mlContextmit einer neuen Instanz vonMLContext, indem Sie nach dem Definieren der Pfade die folgende Zeile hinzufügen.MLContext mlContext = new MLContext();Die
MLContextKlasse ist ein Ausgangspunkt für alle ML.NET Vorgänge, und die Initialisierung von mlContext erstellt eine neue ML.NET Umgebung, die für die Workflowobjekte der Modellerstellung freigegeben werden kann. Es ist konzeptionell ähnlich wie inDBContextim Entity Framework.
Laden der Daten
Dient
DatabaseLoaderzum Laden von Datensätzen vom TypModelInput.DatabaseLoader loader = mlContext.Data.CreateDatabaseLoader<ModelInput>();Definieren Sie die Abfrage, um die Daten aus der Datenbank zu laden.
string query = "SELECT RentalDate, CAST(Year as REAL) as Year, CAST(TotalRentals as REAL) as TotalRentals FROM Rentals";ML.NET Algorithmen erwarten, dass Daten vom Typ
Singlesind. Daher müssen numerische Werte aus der Datenbank, die nicht vom TypRealsind, in einen einfachen Gleitkommawert konvertiertRealwerden.Die
Year- undTotalRental-Spalten sind beide Ganzzahltypen in der Datenbank. Mit derCASTbuild-in Funktion werden beide aufRealgecastet.Erstellen Sie eine
DatabaseSourceVerbindung mit der Datenbank, und führen Sie die Abfrage aus.DatabaseSource dbSource = new DatabaseSource(SqlClientFactory.Instance, connectionString, query);Laden Sie die Daten in eine
IDataView.IDataView dataView = loader.Load(dbSource);Das Dataset enthält zwei Jahre Daten. Nur Daten aus dem ersten Jahr werden für die Ausbildung verwendet, das zweite Jahr wird durchgeführt, um die tatsächlichen Werte mit der vom Modell erzeugten Prognose zu vergleichen. Filtern Sie die Daten mithilfe der
FilterRowsByColumnTransformation.IDataView firstYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", upperBound: 1); IDataView secondYearData = mlContext.Data.FilterRowsByColumn(dataView, "Year", lowerBound: 1);Für das erste Jahr werden nur die Werte in der
YearSpalte unter 1 ausgewählt, indem derupperBoundParameter auf 1 festgelegt wird. Umgekehrt werden für das zweite Jahr Werte größer oder gleich 1 ausgewählt, indem derlowerBoundParameter auf 1 festgelegt wird.
Definieren der Zeitreihenanalysepipeline
Definieren Sie eine Pipeline, die den SsaForecastingEstimator verwendet, um Werte in einem Zeitreihen-Dataset zu prognostizieren.
var forecastingPipeline = mlContext.Forecasting.ForecastBySsa( outputColumnName: "ForecastedRentals", inputColumnName: "TotalRentals", windowSize: 7, seriesLength: 30, trainSize: 365, horizon: 7, confidenceLevel: 0.95f, confidenceLowerBoundColumn: "LowerBoundRentals", confidenceUpperBoundColumn: "UpperBoundRentals");Im ersten Jahr nimmt
forecastingPipeline365 Datenpunkte und teilt das Zeitreihen-Dataset in 30-Tage-Intervalle (monatlich) auf oder zieht dafür Stichproben, wie imseriesLength-Parameter angegeben. Jede dieser Proben wird wöchentlich oder über einen 7-Tage-Zeitraum hinweg analysiert. Bei der Bestimmung des prognostizierten Werts für die nächsten Periode(n) werden die Werte aus den vorherigen sieben Tagen verwendet, um eine Vorhersage zu erstellen. Das Modell wird so festgelegt, dass sieben Zeiträume in der Zukunft gemäß der Definition durch denhorizonParameter prognostiziert werden. Da eine Prognose eine fundierte Vermutung ist, ist es nicht immer 100% genau. Daher ist es gut, den Wertebereich in den besten und schlimmsten Szenarien zu kennen, wie sie durch die oberen und unteren Grenzen definiert sind. In diesem Fall wird das Konfidenzniveau für die unteren und oberen Grenzen auf 95%festgelegt. Das Konfidenzniveau kann entsprechend erhöht oder verringert werden. Je höher der Wert ist, desto breiter liegt der Bereich zwischen den oberen und unteren Grenzen, um das gewünschte Konfidenzniveau zu erreichen.Verwenden Sie die
FitMethode, um das Modell zu trainieren und die Daten an die zuvor definiertenforecastingPipelineAnzupassen.SsaForecastingTransformer forecaster = forecastingPipeline.Fit(firstYearData);
Auswerten des Modells
Bewerten Sie die Leistung des Modells, indem Sie die Daten des nächsten Jahres prognostizieren und mit den tatsächlichen Werten vergleichen.
Erstellen Sie am Ende der Datei Program.cs eine neue Hilfsmethode mit dem Namen
Evaluate.Evaluate(IDataView testData, ITransformer model, MLContext mlContext) { }Prognostizieren Sie innerhalb der
EvaluateMethode die Daten des zweiten Jahres mithilfe derTransformMethode mit dem trainierten Modell.IDataView predictions = model.Transform(testData);Rufen Sie die tatsächlichen Werte aus den Daten mithilfe der
CreateEnumerableMethode ab.IEnumerable<float> actual = mlContext.Data.CreateEnumerable<ModelInput>(testData, true) .Select(observed => observed.TotalRentals);Rufen Sie die Prognosewerte mithilfe der
CreateEnumerableMethode ab.IEnumerable<float> forecast = mlContext.Data.CreateEnumerable<ModelOutput>(predictions, true) .Select(prediction => prediction.ForecastedRentals[0]);Berechnen Sie die Differenz zwischen den tatsächlichen und den Prognosewerten, die häufig als Fehler bezeichnet werden.
var metrics = actual.Zip(forecast, (actualValue, forecastValue) => actualValue - forecastValue);Messen Sie die Leistung, indem Sie die Werte für die Mittlere Absolute Abweichung und die Wurzel Mittlere Quadratische Abweichung berechnen.
var MAE = metrics.Average(error => Math.Abs(error)); // Mean Absolute Error var RMSE = Math.Sqrt(metrics.Average(error => Math.Pow(error, 2))); // Root Mean Squared ErrorZum Auswerten der Leistung werden die folgenden Metriken verwendet:
- Mittlerer absoluter Fehler: Misst, wie nahe Vorhersagen auf den tatsächlichen Wert liegen. Dieser Wert liegt zwischen 0 und unendlich. Je näher 0, desto besser ist die Qualität des Modells.
- Root Mean Squared Error: Fasst den Fehler im Modell zusammen. Dieser Wert liegt zwischen 0 und unendlich. Je näher 0, desto besser ist die Qualität des Modells.
Geben Sie die Metriken in die Konsole aus.
Console.WriteLine("Evaluation Metrics"); Console.WriteLine("---------------------"); Console.WriteLine($"Mean Absolute Error: {MAE:F3}"); Console.WriteLine($"Root Mean Squared Error: {RMSE:F3}\n");Rufen Sie die
Evaluatefolgende Methode auf, um dieFit()Methode aufzurufen.Evaluate(secondYearData, forecaster, mlContext);
Speichern des Modells
Wenn Sie mit Ihrem Modell zufrieden sind, speichern Sie es für die spätere Verwendung in anderen Anwendungen.
Erstellen Sie unter der
Evaluate()Methode eineTimeSeriesPredictionEngine.TimeSeriesPredictionEngineist eine Komfortmethode, um einzelne Vorhersagen zu erstellen.var forecastEngine = forecaster.CreateTimeSeriesEngine<ModelInput, ModelOutput>(mlContext);Speichern Sie das Modell in einer Datei, die als
MLModel.zipdefiniert und durch die zuvor definierte VariablemodelPathangegeben ist. Verwenden Sie dieCheckpointMethode, um das Modell zu speichern.forecastEngine.CheckPoint(mlContext, modelPath);
Verwenden des Modells zum Prognostizieren der Nachfrage
Erstellen Sie unterhalb der
EvaluateMethode eine neue Hilfsmethode namensForecast.void Forecast(IDataView testData, int horizon, TimeSeriesPredictionEngine<ModelInput, ModelOutput> forecaster, MLContext mlContext) { }Verwenden Sie innerhalb der
ForecastMethode diePredictMethode, um Vermietungen für die nächsten sieben Tage zu prognostizieren.ModelOutput forecast = forecaster.Predict();Richten Sie die ist- und Prognosewerte für sieben Zeiträume aus.
IEnumerable<string> forecastOutput = mlContext.Data.CreateEnumerable<ModelInput>(testData, reuseRowObject: false) .Take(horizon) .Select((ModelInput rental, int index) => { string rentalDate = rental.RentalDate.ToShortDateString(); float actualRentals = rental.TotalRentals; float lowerEstimate = Math.Max(0, forecast.LowerBoundRentals[index]); float estimate = forecast.ForecastedRentals[index]; float upperEstimate = forecast.UpperBoundRentals[index]; return $"Date: {rentalDate}\n" + $"Actual Rentals: {actualRentals}\n" + $"Lower Estimate: {lowerEstimate}\n" + $"Forecast: {estimate}\n" + $"Upper Estimate: {upperEstimate}\n"; });Durchlaufen Sie die Prognoseausgabe, und zeigen Sie sie auf der Konsole an.
Console.WriteLine("Rental Forecast"); Console.WriteLine("---------------------"); foreach (var prediction in forecastOutput) { Console.WriteLine(prediction); }
Ausführen der Anwendung
Unter dem Aufrufen der
Checkpoint()Methode wird dieForecastMethode aufgerufen.Forecast(secondYearData, 7, forecastEngine, mlContext);Führen Sie die Anwendung aus. Eine Ausgabe wie die unten stehende sollte auf der Konsole erscheinen. Aus Platzgründen wurde die Ausgabe kondensiert.
Evaluation Metrics --------------------- Mean Absolute Error: 726.416 Root Mean Squared Error: 987.658 Rental Forecast --------------------- Date: 1/1/2012 Actual Rentals: 2294 Lower Estimate: 1197.842 Forecast: 2334.443 Upper Estimate: 3471.044 Date: 1/2/2012 Actual Rentals: 1951 Lower Estimate: 1148.412 Forecast: 2360.861 Upper Estimate: 3573.309
Die Überprüfung der tatsächlichen und prognostizierten Werte zeigt die folgenden Beziehungen:
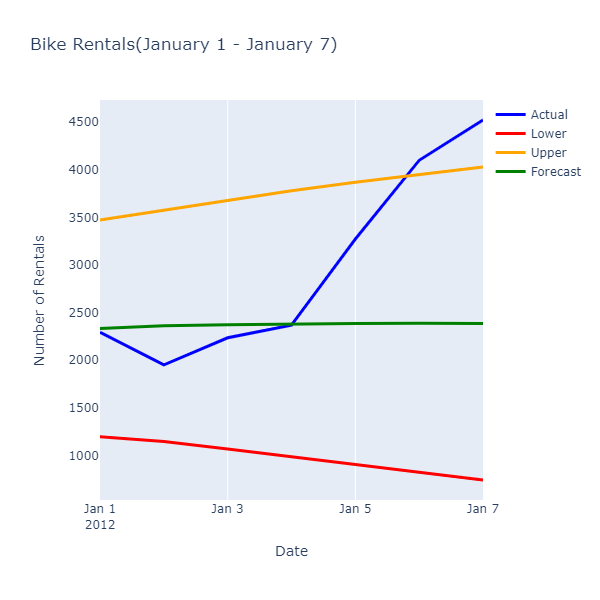
Während die prognostizierten Werte nicht die genaue Anzahl der Vermietungen vorhersagen, stellen sie einen schmaleren Wertebereich bereit, der es einem Vorgang ermöglicht, die Nutzung von Ressourcen zu optimieren.
Glückwunsch! Sie haben nun erfolgreich ein Zeitserien-Machine Learning-Modell entwickelt, um die Nachfrage nach Fahrradverleih zu prognostizieren.
Den Quellcode für dieses Lernprogramm finden Sie im Repository "dotnet/machinelearning-samples" .
Nächste Schritte
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.