Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Dieser Artikel enthält eine Übersicht über Typen, mit denen Daten gelesen werden können, die über mehrere Puffer hinweg ausgeführt werden. Sie werden in erster Linie verwendet, um PipeReader Objekte zu unterstützen.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> ist ein Vertragstyp für synchrone gepufferte Schreiboperationen. Auf niedrigster Ebene gilt Folgendes für die Schnittstelle:
- Ist einfach und nicht schwer zu verwenden.
- Sie bietet Zugriff auf Memory<T>- oder Span<T>-Elemente.
Memory<T>undSpan<T>erlauben Schreibvorgänge, und Sie können ermitteln, wie vieleT-Elemente geschrieben wurden.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
Die oben genannte Methode:
- Fordert einen Puffer von mindestens 5 Bytes von
IBufferWriter<byte>unter Verwendung vonGetSpan(5)an. - Sie schreibt Bytes für die ASCII-Zeichenfolge „Hello“ in das zurückgegebene
Span<byte>-Element. - Aufrufe IBufferWriter<T> , um anzugeben, wie viele Bytes in den Puffer geschrieben wurden.
Diese Schreibmethode verwendet den Memory<T>/Span<T>-Puffer, der vom IBufferWriter<T> bereitgestellt wird. Alternativ kann die Write Erweiterungsmethode verwendet werden, um einen vorhandenen Puffer auf den IBufferWriter<T> zu kopieren.
Write ruft GetSpan/Advance je nach Bedarf auf, daher muss nach dem Schreiben Advance nicht aufgerufen werden:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> ist eine Implementierung von IBufferWriter<T>, deren Speicher ein einzelnes zusammenhängendes Array ist.
Häufige Probleme mit IBufferWriter
-
GetSpanundGetMemorygeben einen Puffer mit mindestens der angeforderten Speichermenge zurück. Gehen Sie nicht von exakten Puffergrößen aus. - Es gibt keine Garantie dafür, dass aufeinander folgende Aufrufe denselben Puffer oder einen Puffer mit derselben Größe zurückgeben.
- Nach dem Aufrufen
Advancemuss ein neuer Puffer angefordert werden, um weitere Daten weiter zu schreiben. Ein zuvor erworbener Puffer kann nicht mehr geschrieben werden, nachdemAdvanceaufgerufen wurde.
ReadOnlySequence<T>
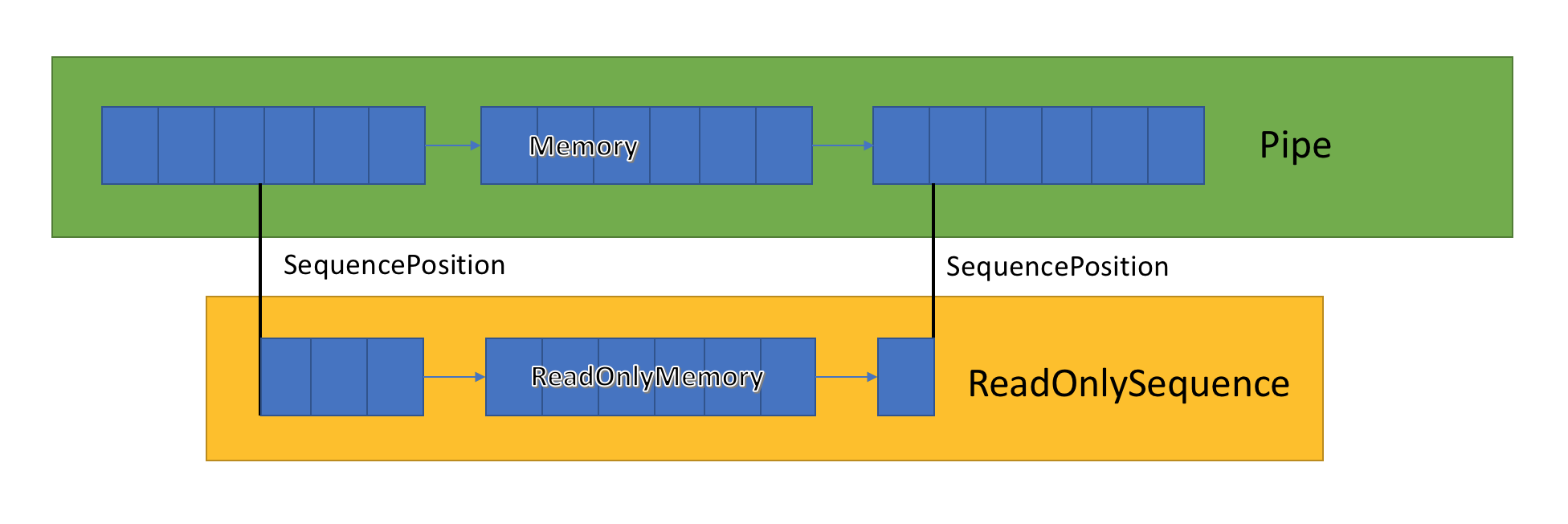
ReadOnlySequence<T> ist eine Struktur, die eine zusammenhängende oder nicht zusammenhängende Sequenz von Tdarstellt. Sie kann aus Folgendem erstellt werden:
- Einen
T[] - Einen
ReadOnlyMemory<T> - Ein Paar verknüpfter Listenknoten ReadOnlySequenceSegment<T> und Index, das die Start- und Endposition der Sequenz darstellt.
Die dritte Darstellung ist die interessanteste, da sie Auswirkungen auf die Leistung bei verschiedenen Vorgängen auf dem ReadOnlySequence<T> hat.
| Repräsentation | Vorgang | Kompliziertheit |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Aufgrund dieser gemischten Darstellung macht ReadOnlySequence<T> Indizes als SequencePosition anstelle einer Ganzzahl verfügbar. Für eine SequencePosition gilt:
- Es handelt sich um einen nicht transparenten Wert, der einen Index für das
ReadOnlySequence<T>-Element darstellt, aus dem der Wert stammt. - Besteht aus zwei Teilen, einer ganzen Zahl und einem Objekt. Was diese beiden Werte darstellen, hängt von der Implementierung von
ReadOnlySequence<T>ab.
Zugreifen auf Daten
ReadOnlySequence<T> macht Daten als aufzählbares Element von ReadOnlyMemory<T> verfügbar. Die Aufzählung jedes der Segmente kann mithilfe eines einfachen foreach-Vorgangs durchgeführt werden:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
Die vorstehende Methode durchsucht jedes Segment nach einem bestimmten Byte. Wenn Sie die SequencePosition jedes Segments nachverfolgen müssen, ist ReadOnlySequence<T>.TryGet besser geeignet. Im nächsten Beispiel wird der vorangehende Code so geändert, dass anstelle einer ganzen Zahl ein SequencePosition Wert zurückgegeben wird. Das Zurückgeben eines SequencePosition Elements hat den Vorteil, dass der Aufrufer eine zweite Überprüfung vermeiden kann, um die Daten an einem bestimmten Index zu erhalten.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
Die Kombination von SequencePosition und TryGet verhält sich wie ein Enumerator. Das Positionsfeld wird am Anfang jeder Iteration geändert, um von jedem Segment innerhalb des ReadOnlySequence<T>Bereichs zu beginnen.
Die vorangehende Methode existiert als Erweiterungsmethode für ReadOnlySequence<T>.
PositionOf kann verwendet werden, um den vorherigen Code zu vereinfachen:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Verarbeiten eines ReadOnlySequence<T>-Elements
Die Verarbeitung einer ReadOnlySequence<T> kann herausfordernd sein, da die Daten möglicherweise über mehrere Segmente einer Sequenz verteilt werden. Um die beste Leistung zu erzielen, teilen Sie Code in zwei Pfade auf:
- Ein schneller Pfad, der sich mit dem Einzelsegmentfall befasst.
- Ein langsamer Pfad, der sich mit den Daten befasst, die über Segmente aufgeteilt werden.
Es gibt einige Ansätze, mit denen Daten in mehrsegmentierten Sequenzen verarbeitet werden können:
- Verwenden Sie den Wert
SequenceReader<T>. - Analysieren Sie Daten segmentweise, und verfolgen Sie die
SequencePositionund den Index innerhalb des analysierten Segments nach. Dadurch werden unnötige Zuordnungen vermieden, aber möglicherweise ineffizient, insbesondere für kleine Puffer. - Kopieren Sie das
ReadOnlySequence<T>Array in ein zusammenhängendes Array, und behandeln Sie es wie ein einzelner Puffer:- Ist die Größe
ReadOnlySequence<T>klein, kann es sinnvoll sein, die Daten mithilfe des Stackalloc-Operators in einen stapelverteilten Puffer zu kopieren. - Kopieren Sie das
ReadOnlySequence<T>Array in ein pooliertes Array mithilfe von ArrayPool<T>.Shared. - Verwenden Sie
ReadOnlySequence<T>.ToArray(). Dies ist im langsamsten Pfad nicht empfehlenswert, da dadurch ein neuesT[]-Element im Heap zugewiesen wird.
- Ist die Größe
Die folgenden Beispiele veranschaulichen einige häufige Fälle für die Verarbeitung ReadOnlySequence<byte>:
Verarbeiten von Binärdaten
Das folgende Beispiel analysiert eine 4 Byte lange Big-Endian-Ganzzahl ab dem Start des ReadOnlySequence<byte>-Elements.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Verarbeiten von Textdaten
Das folgende Beispiel:
- Die erste neue Zeile (
\r\n) inReadOnlySequence<byte>wird gefunden und über den Ausgabeparameter „line“ zurückgegeben. - Kürzt diese Zeile und schließt dabei
\r\nvom Eingabepuffer aus.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Leere Segmente
Es ist zulässig, leere Segmente innerhalb eines ReadOnlySequence<T> zu speichern. Leere Segmente können auftreten, während Segmente explizit aufgezählt werden:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Der vorangehende Code erstellt ein ReadOnlySequence<byte> mit leeren Segmenten und zeigt, wie sich diese leeren Segmente auf die verschiedenen APIs auswirken:
-
ReadOnlySequence<T>.Slicemit einerSequencePosition, die auf ein leeres Segment zeigt, behält dieses Segment bei. -
ReadOnlySequence<T>.Slicemit einem int-Wert überspringt die leeren Segmente. - Beim Aufzählen der
ReadOnlySequence<T>werden die leeren Segmente aufgezählt.
Potenzielle Probleme mit ReadOnlySequence<T> und SequencePosition
Es gibt verschiedene ungewöhnliche Ergebnisse beim Umgang mit ReadOnlySequence<T>/SequencePosition im Vergleich zu einem normalen ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int.
-
SequencePositionist eine Positionsmarkierung für eine bestimmteReadOnlySequence<T>, keine absolute Position. Da sie relativ zu einem bestimmtenReadOnlySequence<T>Ist, hat sie keine Bedeutung, wenn sie außerhalb desReadOnlySequence<T>Ursprungsorts verwendet wird. - In der
SequencePositionkönnen ohne dasReadOnlySequence<T>-Element keine arithmetischen Berechnungen ausgeführt werden. Das bedeutet, dass einfache Vorgänge wieposition++alsposition = ReadOnlySequence<T>.GetPosition(1, position)geschrieben werden. -
GetPosition(long)unterstützt keine negativen Indizes. Das bedeutet, dass es unmöglich ist, das vorletzte Zeichen abzurufen, ohne alle Segmente zu durchlaufen. - Zwei
SequencePositionkönnen nicht verglichen werden, was es schwierig macht:- Wissen Sie, ob eine Position größer oder kleiner als eine andere Position ist.
- Schreiben Sie einige Analysealgorithmen.
-
ReadOnlySequence<T>ist größer als ein Objektverweis und sollte nach Möglichkeit von in oder ref übergeben werden. Durch Übergeben vonReadOnlySequence<T>durchinoderrefwerden weniger Kopien der Struktur erstellt. - Leere Segmente:
- Sie sind innerhalb eines
ReadOnlySequence<T>-Elements gültig. - Kann beim Iterieren mit der
ReadOnlySequence<T>.TryGet-Methode auftreten. - Sie können beim Aufteilen der Sequenz in Slices mithilfe der
ReadOnlySequence<T>.Slice()-Methode mitSequencePosition-Objekten angezeigt werden.
- Sie sind innerhalb eines
SequenceReader<T>
- Ein neuer Typ, der in .NET Core 3.0 eingeführt wurde, um die Verarbeitung eines
ReadOnlySequence<T>zu vereinfachen. - Vereint die Unterschiede zwischen einem einzelnen Segment
ReadOnlySequence<T>und mehreren SegmentenReadOnlySequence<T>. - Stellt Hilfsprogramme zum Lesen von Binär- und Textdaten (
byteundchar) bereit, die gegebenenfalls auf Segmente aufgeteilt sein können oder nicht.
Es gibt integrierte Methoden zum Verarbeiten von binären und getrennten Daten. Im folgenden Abschnitt wird veranschaulicht, wie diese gleichen Methoden mit SequenceReader<T> aussehen.
Zugreifen auf Daten
SequenceReader<T> verfügt über Methoden zum Aufzählen von Daten innerhalb der ReadOnlySequence<T> direkt. Der folgende Code ist ein Beispiel für die gleichzeitige Verarbeitung einer ReadOnlySequence<byte>byte Datei:
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpan macht das Span-Element des aktuellen Segments verfügbar – dies entspricht der manuellen Ausführung des Vorgangs in der Methode.
Verwenden der Position
Der folgende Code ist eine Beispielimplementierung von FindIndexOf unter Verwendung des SequenceReader<T>-Elements:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Verarbeiten von Binärdaten
Das folgende Beispiel analysiert eine 4 Byte lange Big-Endian-Ganzzahl ab dem Start des ReadOnlySequence<byte>-Elements.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Verarbeiten von Textdaten
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Häufige Probleme mit SequenceReader<T>
- Da
SequenceReader<T>es sich um eine veränderbare Struktur handelt, sollte sie immer per Verweis übergeben werden. -
SequenceReader<T>ist eine Referenzstruktur , sodass sie nur in synchronen Methoden verwendet werden kann und nicht in Feldern gespeichert werden kann. Weitere Informationen finden Sie unter Vermeiden von Zuweisungen. -
SequenceReader<T>ist für die Verwendung als Vorwärtslesefunktion optimiert.Rewindist für kleine Sicherungen vorgesehen, die nicht mit anderenRead,PeekundIsNextAPIs behoben werden können.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.