Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article provides an overview of types that help read data that runs across multiple buffers. They're primarily used to support PipeReader objects.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> is a contract for synchronous buffered writing. At the lowest level, the interface:
- Is basic and not difficult to use.
- Allows access to a Memory<T> or Span<T>. The
Memory<T>orSpan<T>can be written to and you can determine how manyTitems were written.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
The preceding method:
- Requests a buffer of at least 5 bytes from the
IBufferWriter<byte>usingGetSpan(5). - Writes bytes for the ASCII string "Hello" to the returned
Span<byte>. - Calls IBufferWriter<T> to indicate how many bytes were written to the buffer.
This method of writing uses the Memory<T>/Span<T> buffer provided by the IBufferWriter<T>. Alternatively, the Write extension method can be used to copy an existing buffer to the IBufferWriter<T>. Write does the work of calling GetSpan/Advance as appropriate, so there's no need to call Advance after writing:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> is an implementation of IBufferWriter<T> whose backing store is a single contiguous array.
IBufferWriter common problems
GetSpanandGetMemoryreturn a buffer with at least the requested amount of memory. Don't assume exact buffer sizes.- There's no guarantee that successive calls will return the same buffer or the same-sized buffer.
- A new buffer must be requested after calling
Advanceto continue writing more data. A previously acquired buffer cannot be written to afterAdvancehas been called.
ReadOnlySequence<T>
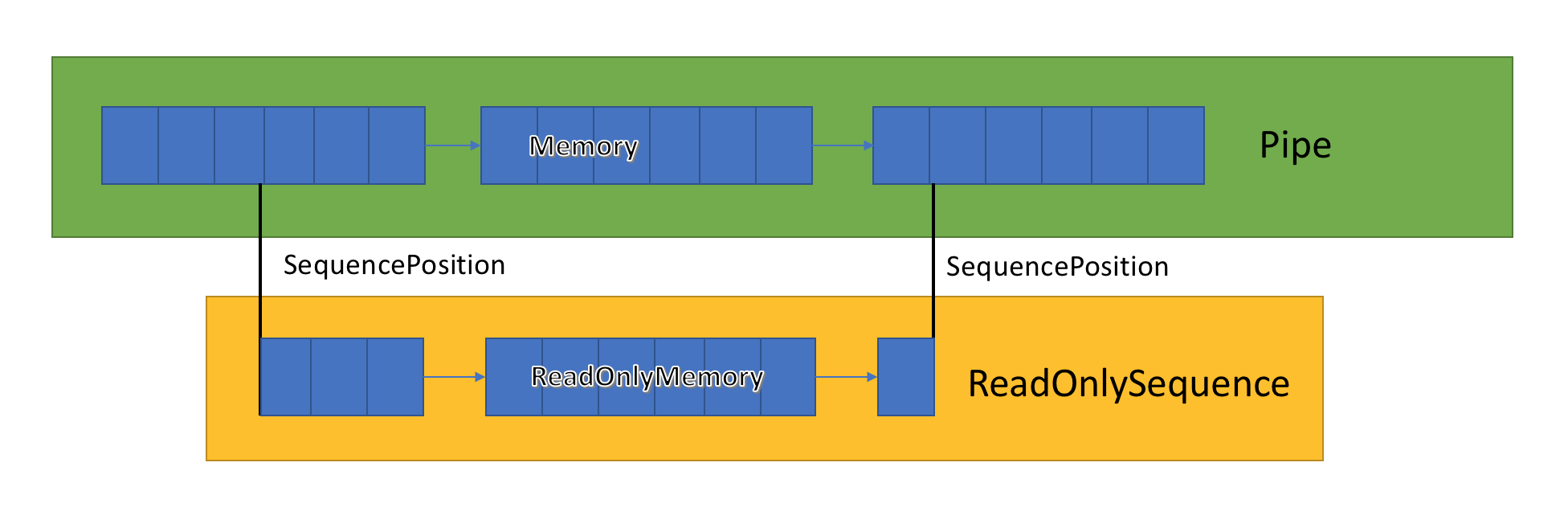
ReadOnlySequence<T> is a struct that can represent a contiguous or noncontiguous sequence of T. It can be constructed from:
- A
T[] - A
ReadOnlyMemory<T> - A pair of linked list node ReadOnlySequenceSegment<T> and index to represent the start and end position of the sequence.
The third representation is the most interesting one as it has performance implications on various operations on the ReadOnlySequence<T>:
| Representation | Operation | Complexity |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
Because of this mixed representation, the ReadOnlySequence<T> exposes indexes as SequencePosition instead of an integer. A SequencePosition:
- Is an opaque value that represents an index into the
ReadOnlySequence<T>where it originated. - Consists of two parts, an integer and an object. What these two values represent are tied to the implementation of
ReadOnlySequence<T>.
Access data
The ReadOnlySequence<T> exposes data as an enumerable of ReadOnlyMemory<T>. Enumerating each of the segments can be done using a basic foreach:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
The preceding method searches each segment for a specific byte. If you need to keep track of each segment's SequencePosition,
ReadOnlySequence<T>.TryGet is more appropriate. The next sample changes the preceding code to return a SequencePosition instead of an integer. Returning a SequencePosition has the benefit of allowing the caller to avoid a second scan to get the data at a specific index.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
The combination of SequencePosition and TryGet acts like an enumerator. The position field is modified at the start of each iteration to be start of each segment within the ReadOnlySequence<T>.
The preceding method exists as an extension method on ReadOnlySequence<T>. PositionOf can be used to simplify the preceding code:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Process a ReadOnlySequence<T>
Processing a ReadOnlySequence<T> can be challenging since data may be split across multiple segments within the sequence. For the best performance, split code into two paths:
- A fast path that deals with the single segment case.
- A slow path that deals with the data split across segments.
There are a few approaches that can be used to process data in multi-segmented sequences:
- Use the
SequenceReader<T>. - Parse data segment by segment, keeping track of the
SequencePositionand index within the segment parsed. This avoids unnecessary allocations but may be inefficient, especially for small buffers. - Copy the
ReadOnlySequence<T>to a contiguous array and treat it like a single buffer:- If the size of the
ReadOnlySequence<T>is small, it may be reasonable to copy the data into a stack-allocated buffer using the stackalloc operator. - Copy the
ReadOnlySequence<T>into a pooled array using ArrayPool<T>.Shared. - Use
ReadOnlySequence<T>.ToArray(). This isn't recommended in hot paths as it allocates a newT[]on the heap.
- If the size of the
The following examples demonstrate some common cases for processing ReadOnlySequence<byte>:
Process binary data
The following example parses a 4-byte big-endian integer length from the start of the ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Process text data
The following example:
- Finds the first newline (
\r\n) in theReadOnlySequence<byte>and returns it via the out 'line' parameter. - Trims that line, excluding the
\r\nfrom the input buffer.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Empty segments
It's valid to store empty segments inside of a ReadOnlySequence<T>. Empty segments may occur while enumerating segments explicitly:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
The preceding code creates a ReadOnlySequence<byte> with empty segments and shows how those empty segments affect the various APIs:
ReadOnlySequence<T>.Slicewith aSequencePositionpointing to an empty segment preserves that segment.ReadOnlySequence<T>.Slicewith an int skips over the empty segments.- Enumerating the
ReadOnlySequence<T>enumerates the empty segments.
Potential problems with ReadOnlySequence<T> and SequencePosition
There are several unusual outcomes when dealing with a ReadOnlySequence<T>/SequencePosition vs. a normal ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int:
SequencePositionis a position marker for a specificReadOnlySequence<T>, not an absolute position. Because it's relative to a specificReadOnlySequence<T>, it doesn't have meaning if used outside of theReadOnlySequence<T>where it originated.- Arithmetic can't be performed on
SequencePositionwithout theReadOnlySequence<T>. That means doing basic things likeposition++is writtenposition = ReadOnlySequence<T>.GetPosition(1, position). GetPosition(long)does not support negative indexes. That means it's impossible to get the second to last character without walking all segments.- Two
SequencePositioncan't be compared, making it difficult to:- Know if one position is greater than or less than another position.
- Write some parsing algorithms.
ReadOnlySequence<T>is bigger than an object reference and should be passed by in or ref where possible. PassingReadOnlySequence<T>byinorrefreduces copies of the struct.- Empty segments:
- Are valid within a
ReadOnlySequence<T>. - Can appear when iterating using the
ReadOnlySequence<T>.TryGetmethod. - Can appear slicing the sequence using the
ReadOnlySequence<T>.Slice()method withSequencePositionobjects.
- Are valid within a
SequenceReader<T>
- Is a new type that was introduced in .NET Core 3.0 to simplify the processing of a
ReadOnlySequence<T>. - Unifies the differences between a single segment
ReadOnlySequence<T>and multi-segmentReadOnlySequence<T>. - Provides helpers for reading binary and text data (
byteandchar) that may or may not be split across segments.
There are built-in methods for dealing with processing both binary and delimited data. The following section demonstrates what those same methods look like with the SequenceReader<T>:
Access data
SequenceReader<T> has methods for enumerating data inside of the ReadOnlySequence<T> directly. The following code is an example of processing a ReadOnlySequence<byte> a byte at a time:
while (reader.TryRead(out byte b))
{
Process(b);
}
The CurrentSpan exposes the current segment's Span, which is similar to what was done in the method manually.
Use position
The following code is an example implementation of FindIndexOf using the SequenceReader<T>:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Process binary data
The following example parses a 4-byte big-endian integer length from the start of the ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Process text data
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
SequenceReader<T> common problems
- Because
SequenceReader<T>is a mutable struct, it should always be passed by reference. SequenceReader<T>is a ref struct so it can only be used in synchronous methods and can't be stored in fields. For more information, see Avoid allocations.SequenceReader<T>is optimized for use as a forward-only reader.Rewindis intended for small backups that can't be addressed utilizing otherRead,Peek, andIsNextAPIs.
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.