Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Lakehouse unterstützt die Erstellung von benutzerdefinierten Schemata. Schemata ermöglichen es Ihnen, Ihre Tabellen zu gruppieren, um Daten besser zu finden, den Zugriff zu kontrollieren und vieles mehr.
Erstellen eines neuen Lakehouse-Schemas
Um die Schemaunterstützung für Ihr Lakehouse zu aktivieren, markieren Sie das Kästchen neben Lakehouse-Schemata (Public Preview), wenn Sie es erstellen.
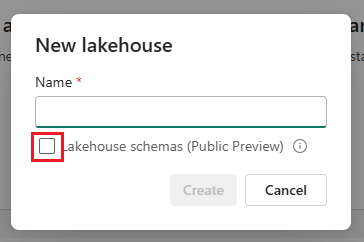
Wichtig
Arbeitsbereichsnamen dürfen aufgrund von Vorschaubeschränkungen nur alphanumerische Zeichen enthalten. Wenn Sonderzeichen in Arbeitsbereichsnamen verwendet werden, funktionieren einige der Lakehouse-Features nicht.
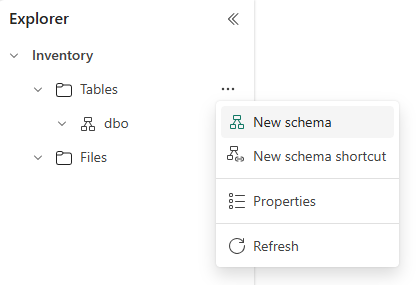
Sobald Sie das Lakehouse erstellt haben, finden Sie unter Tabellen ein Standardschema namens dbo. Dieses Schema ist immer vorhanden und kann nicht geändert oder entfernt werden. Um ein neues Schema zu erstellen, fahren Sie mit dem Mauszeiger über Tabellen, wählen Sie ... und wählen Sie Neues Schema. Geben Sie den Namen Ihres Schemas ein und wählen Sie Erstellen. Sie sehen Ihr Schema unter Tabellen in alphabetischer Reihenfolge.
Speichern von Tabellen in Lakehouse-Schemata
Um eine Tabelle in einem Schema zu speichern, benötigen einen Schemanamen. Andernfalls wird das Standard-dbo-Schema verwendet.
df.write.mode("Overwrite").saveAsTable("contoso.sales")
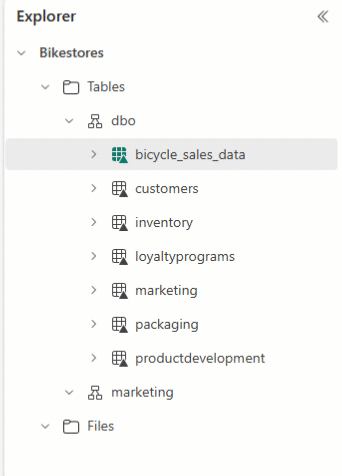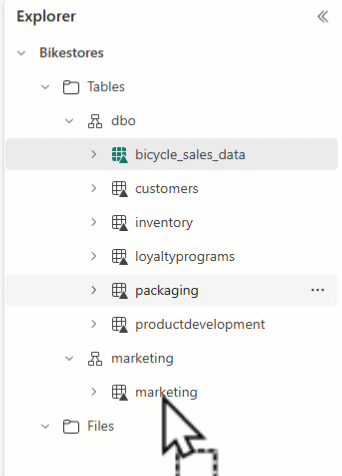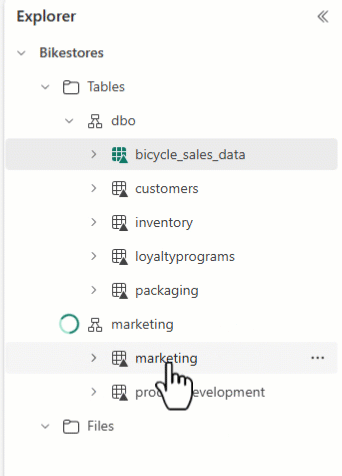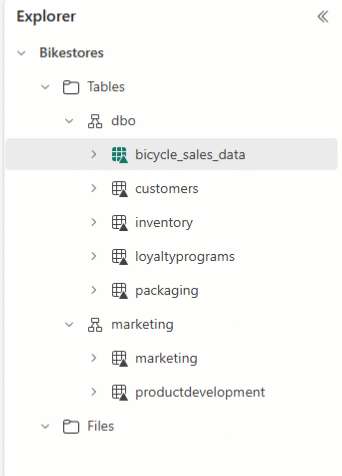
Sie können den Lakehouse Explorer verwenden, um Ihre Tabellen anzuordnen und Tabellennamen per Drag & Drop in verschiedene Schemata zu ziehen.
Achtung
Wenn Sie die Tabelle ändern, müssen Sie auch verwandte Elemente wie Notebook-Code oder Datenflüsse aktualisieren, um sicherzustellen, dass sie mit dem richtigen Schema übereinstimmen.
Verwenden mehrerer Tabellen mit Schemaverknüpfung
Um mehrere Delta-Tabellen aus einem anderen Fabric Lakehouse oder einem externen Speicher zu referenzieren, verwenden Sie eine Schema-Verknüpfung, die alle Tabellen unter dem gewählten Schema oder Ordner anzeigt. Alle Änderungen an den Tabellen im Quellverzeichnis erscheinen auch im Schema. Um eine Schema-Verknüpfung zu erstellen, bewegen Sie den Mauszeiger über Tabellen, wählen Sie ... und wählen Sie Neue Schema-Verknüpfung. Wählen Sie dann ein Schema auf einem anderen Lakehouse oder einen Ordner mit Delta-Tabellen auf Ihrem externen Speicher wie Azure Data Lake Storage (ADLS) Gen2. Dadurch wird ein neues Schema mit den referenzierten Tabellen erstellt.
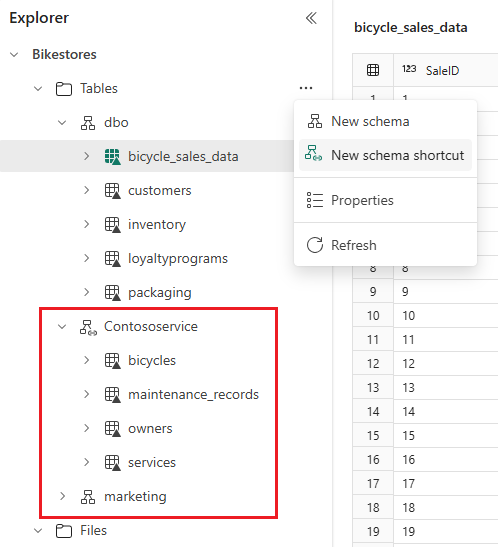
Zugreifen auf Lakehouse-Schemata für Power BI-Berichte
Um Ihr semantisches Modell zu erstellen, wählen Sie einfach die Tabellen aus, die Sie verwenden möchten. Tabellen können in verschiedenen Schemata vorliegen. Wenn Tabellen aus verschiedenen Schemata den gleichen Namen haben, sehen Sie in der Modellansicht Zahlen neben den Tabellennamen.
Lakehouse-Schemata in Notebook
Wenn Sie ein schemafähiges Lakehouse im Notebook-Objekt-Explorer betrachten, werden Tabellen in Schemata angezeigt. Sie können die Tabelle in eine Codezelle ziehen und ablegen und einen Codeausschnitt abrufen, der sich auf das Schema bezieht, in dem sich die Tabelle befindet. Verwenden Sie diesen Namespace, um auf Tabellen in Ihrem Code zu verweisen: „workspace.lakehouse.schema.table“. Wenn Sie eines der Elemente auslassen, verwendet der Executor die Standardeinstellung. Wenn Sie zum Beispiel nur den Tabellennamen angeben, wird das Standardschema (dbo) aus dem Standard-Lakehouse für das Notebook verwendet.
Wichtig
Wenn Sie Schemas in Ihrem Code verwenden möchten, stellen Sie sicher, dass das Standard-Lakehouse für das Notebook schemafähig ist.
Arbeitsbereichübergreifende Spark SQL-Abfragen
Verwenden Sie den Namespace „workspace.lakehouse.schema.table“, um auf Tabellen in Ihrem Code zu verweisen. Auf diese Weise können Sie Tabellen aus verschiedenen Arbeitsbereichen verknüpfen, wenn der Benutzer, der den Code ausführt, über die Berechtigung zum Zugreifen auf die Tabellen verfügt.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Wichtig
Stellen Sie sicher, dass Sie Tabellen nur aus Lakehouses verknüpfen, für die Schemas aktiviert sind. Das Verknüpfen von Tabellen aus Lakehouses, für die keine Schemas aktiviert sind, funktioniert nicht.
Einschränkungen der öffentlichen Vorschauversion
Nachfolgend sind nicht unterstützte Features/Funktionen für die aktuelle Version der Public Preview aufgeführt. Sie werden in den kommenden Versionen vor der allgemeinen Verfügbarkeit aufgelöst.
| Nicht unterstützte Features/Funktionalität | Hinweise |
|---|---|
| Gemeinsames Lakehouse | Die Verwendung des Arbeitsbereichs im Namespace für ein gemeinsames Lakehouses funktioniert nicht, z. B. wokrkspace.sharedlakehouse.schema.table. Benutzende müssen über eine Arbeitsbereichsrolle verfügen, um den Arbeitsbereich im Namaspace zu verwenden. |
| Nicht-Delta, verwaltetes Tabellenschema | Das Abrufen von Schemata für verwaltete, nicht Delta-formatierte Tabellen (z. B. CSV) wird nicht unterstützt. Wenn Sie diese Tabellen im Lakehouse-Explorer erweitern, werden in der UX keine Schemainformationen angezeigt. |
| Externe Spark-Tabellen | Externe Spark-Tabellenvorgänge (z. B. Ermittlung, Abrufen von Schemata usw.) werden nicht unterstützt. Diese Tabellen sind in der UX nicht identifiziert. |
| Öffentliche API | Öffentliche APIs (Tabellen auflisten, Tabelle laden, erweiterte Eigenschaft defaultSchema anzeigen usw.) werden für schemafähige Lakehouses nicht unterstützt. Vorhandene öffentliche APIs, die mit einem schemafähigen Lakehouse aufgerufen werden, führen zu einem Fehler. |
| Aktualisieren von Tabelleneigenschaften | Nicht unterstützt. |
| Arbeitsbereichsname mit Sonderzeichen | Arbeitsbereich mit Sonderzeichen (z. B. Leerzeichen, Schrägstriche) wird nicht unterstützt. Es wird ein Benutzerfehler angezeigt. |
| Spark-Ansichten | Nicht unterstützt. |
| Hive-spezifische Features | Nicht unterstützt. |
| Spark.catalog-API | Nicht unterstützt. Verwenden Sie stattdessen Spark SQL. |
USE <schemaName> |
Funktioniert nicht arbeitsbereichsübergreifend, wird aber innerhalb desselben Arbeitsbereichs unterstützt. |
| Migration | Die Migration von bestehenden nicht-schemabasierten Lakehouses zu schemabasierten Lakehouses wird nicht unterstützt. |
| Dataflow Gen2 | Nicht unterstützt. |