Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für:✅ SQL-Analyseendpunkt und Warehouse in Microsoft Fabric
Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einer Data Lake-Basis.
- Die idealen Anwendungsfälle für Fabric Data Warehouse sind Stern- oder Schneeflakeschemas, kuratierte Corporate Data Marts, geregelte Semantikmodelle für Business Intelligence.
- Fabric Data Warehouse-Daten, wie alle Fabric-Daten, werden in Delta-Tabellen gespeichert, die Parquet-Datendateien mit einem dateibasierten Transaktionsprotokoll sind. Weitere Informationen zum Delta Lake als universelles Speicherformat Fabric finden Sie unter Delta Lake in Microsoft Fabric Übersicht. Basierend auf dem Open Data-Format von Fabric ermöglicht ein Warehouse die Freigabe und Zusammenarbeit zwischen Datentechnikern und Geschäftsbenutzern, ohne die Sicherheit oder Governance zu beeinträchtigen.
- Fabric Data Warehouse wird in erster Linie mit T-SQL entwickelt und teilt eine umfangreiche Grundlage basierend auf dem SQL-Datenbankmodul mit vollständiger Unterstützung für ACID-Transaktionen über mehrere Tabellen, materialisierte Ansichten, Funktionen und gespeicherte Prozeduren.
- Das Massenladen von Fabric Data Warehouse kann über T-SQL- und TDS-Verbindungen oder über Spark erfolgen, wobei Daten massenweise direkt in die Delta-Tabellen geschrieben werden.
- Die einfach zu verwendende SaaS-Erfahrung ist auch eng in Power BI integriert, um einfache Analysen und Berichte zu ermöglichen.
Data Warehouse-Kunden profitieren von:
- Datenbankübergreifende Abfragen können mehrere Datenquellen nutzen, um schnelle Einblicke zu erhalten, ohne dass Daten dupliziert werden.
-
Einfaches Aufnehmen, Laden und Transformieren von Daten über Pipelines, Datenflüsse, datenbankübergreifende Abfrage oder T-SQL-Befehl
COPY INTO. - Autonome Workloadverwaltung mit branchenführenden verteilten Abfrageverarbeitungsmodulen bedeutet keine Drehregler, um optimale Leistung zu erzielen.
- Skalieren Sie nahezu sofort , um geschäftliche Anforderungen zu erfüllen. Storage und Compute sind separat.
- Daten werden automatisch für den externen Zugriff in OneLake-Dateien repliziert.
- Entwickelt für jedes Qualifikationsniveau, vom Bürgerentwickler bis hin zu DBA oder Dateningenieur.
Datenhaltungselemente
Fabric Data Warehouse ist kein herkömmliches Enterprise Data Warehouse, es ist ein Lake Warehouse, das zwei verschiedene Lagerelemente unterstützt: das Fabric Warehouse-Element und das SQL Analytics-Endpunktelement. Beide sind speziell dafür entwickelt, die geschäftlichen Anforderungen der Kunden zu erfüllen, während sie gleichzeitig erstklassige Leistung bieten, die Kosten minimieren und den Verwaltungsaufwand reduzieren.
Fabric Data Warehouse
In einem Microsoft Fabric-Arbeitsbereich wird ein Fabric Warehouse in der Spalte Typ als Warehouse bezeichnet. Wenn Sie die volle Leistungsfähigkeit und Transaktionsfunktionen (DDL- und DML-Abfrageunterstützung) eines Data Warehouse benötigen, ist dies die schnelle und einfache Lösung für Sie.

Das Warehouse kann durch eine der unterstützten Datenerfassungsmethoden aufgefüllt werden (z. B. COPY INTO, Pipelines, Dataflows oder datenbankübergreifende Erfassungsoptionen wie CREATE TABLE AS SELECT (CTAS), INSERT..SELECT und SELECT INTO).
Informationen zu den ersten Schritten mit dem Warehouse finden Sie unter:
SQL-Analyseendpunkt des Lakehouse
In einem Microsoft Fabric-Arbeitsbereich verfügt jedes Lakehouse über einen automatisch generierten "SQL-Analyseendpunkt", der verwendet werden kann, um von der "Lake"-Ansicht des Lakehouse (das Data Engineering und Apache Spark unterstützt) zur "SQL"-Ansicht desselben Lakehouse zu wechseln, um Ansichten, Funktionen, gespeicherte Prozeduren zu erstellen und SQL-Sicherheit anzuwenden.
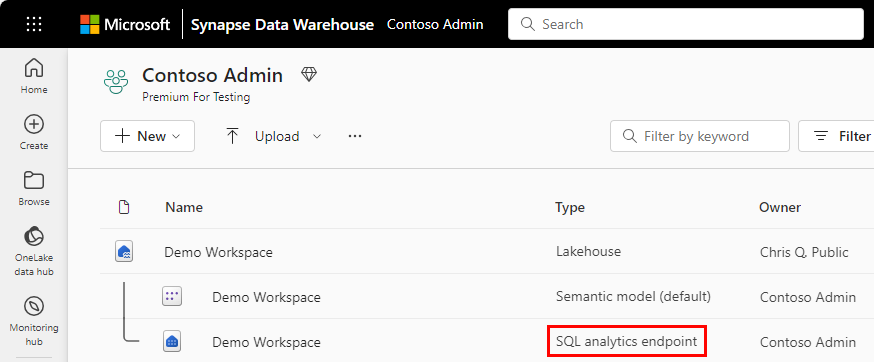
Mit ähnlicher Technologie provisionieren ein Speicher, eine SQL-Datenbank und Fabric OneLake automatisch einen SQL-Analyseendpunkt bei der Erstellung.
Mit dem SQL-Analyseendpunkt können T-SQL-Befehle Datenobjekte definieren und abfragen, die Daten jedoch nicht bearbeiten oder ändern. Sie können die folgenden Aktionen im SQL-Analyseendpunkt ausführen:
- Abfragen der Tabellen, die auf Daten in Ihren Delta Lake-Ordnern im Lake verweisen
- Erstellen Sie Ansichten, Inline-TVFs und Prozeduren, um Ihre Semantik und Geschäftslogik in T-SQL zu kapseln.
- Verwalten von Berechtigungen für die Objekte Weitere Informationen zur Sicherheit im SQL-Analyseendpunkt finden Sie unter OneLake-Sicherheit für SQL-Analyseendpunkte.
Erste Schritte mit dem SQL-Analytics-Endpunkt finden Sie unter:
- Abfragen des SQL-Analyseendpunkts oder -Warehouse in Microsoft Fabric
- Lakehouse SQL Analytics-Endpunkt-Anwendungsfälle
Warehouse oder Lakehouse
Bei der Entscheidung zwischen der Verwendung eines Warehouse oder eines Lakehouse ist es wichtig, die spezifischen Anforderungen und den Kontext Ihrer Datenverwaltungs- und Analyseanforderungen zu berücksichtigen.
Wählen Sie ein Data Warehouse aus, wenn Sie eine Unternehmenslösung mit offenem Standardformat, automatischer Leistung und minimalem Einrichtungsaufwand benötigen. Am besten geeignet für halbstrukturierte und strukturierte Datenformate eignet sich das Data Warehouse sowohl für Anfänger als auch für erfahrene Datenprofis und bietet einfache und intuitive Erfahrungen.
Wählen Sie ein Seehaus aus, wenn Sie ein großes Repository mit hoch unstrukturierten Daten aus heterogenen Quellen benötigen und Spark als primäres Entwicklungstool verwenden möchten. Als "einfaches" Data Warehouse haben Sie immer die Möglichkeit, den SQL-Analyseendpunkt und die T-SQL-Tools zu verwenden, um Berichts- und Datenintelligenzszenarien in Ihrem Lakehouse bereitzustellen.
Sie haben immer die Möglichkeit, zu einem späteren Zeitpunkt das eine oder andere hinzuzufügen, wenn sich Ihre geschäftlichen Anforderungen ändern und unabhängig davon, wo Sie beginnen, sowohl das Warehouse als auch das Lakehouse verwenden dasselbe leistungsstarke SQL-Modul für alle T-SQL-Abfragen.
Ausführlichere Entscheidungsleitfaden finden Sie im Microsoft Fabric-Entscheidungsleitfaden: Wählen Sie zwischen Warehouse und Lakehouse.
Analysieren von Daten im Lakehouse, Warehouse oder Eventhouse
Microsoft Fabric bietet ein einheitliches Daten analysieren mit Menü, das Ihnen eine konsistente Möglichkeit bietet, von Daten zur Datenanalyse zwischen Lakehouse, Warehouse und Eventhouse überzugehen. Anstatt in verschiedenen Menüs für jede Arbeitsauslastung zu navigieren, können Sie Ihre Analyse von einem einzelnen, vorhersagbaren Einstiegspunkt aus starten.
Über ein Lakehouse oder Warehouse können Sie die Aktion Daten analysieren verwenden:
- Analysieren Sie Daten mithilfe des SQL-Analyseendpunkts, wenn OneLake-Verfügbarkeit und -Synchronisierung aktiviert sind.
- Analysieren Sie Daten mithilfe des Eventhouse-Endpunkts direkt aus der Quelldatenerfahrung, ohne zu einer separaten Workload zu navigieren.
- Starten Sie Analyseaktionen von einem einzigen Ort aus, ohne Kontexte zu wechseln oder den Zugriff neu zu konfigurieren.
Diese Integration bietet unabhängig davon, wo sich Ihre Daten befinden, eine konsistente Erfahrung. Die gleichen Analysedaten mit Menü sind in Lakehouse, Warehouse und Eventhouse verfügbar, sodass die Art und Weise, wie Sie Daten analysieren, in allen Workloads gleich aussieht und sich anfühlt. Unabhängig davon, ob Sie explorative Analysen, erweiterte Transformationen oder Experimente durchführen, können Sie schnell von einem vertrauten Ausgangspunkt aus beginnen.
Migration
Verwenden Sie den Fabric-Migrations-Assistenten für Data Warehouse , um von Azure Synapse Analytics, SQL Server und anderen SQL-Datenbankmodulplattformen zu migrieren. Überprüfen Sie die Migrationsplanung und Migrationsmethoden für Azure Synapse Analytics dedizierte SQL-Pools zu Fabric Data Warehouse.
Eine Anleitung zur Migration in Microsoft Fabric erhalten Sie unter den Tools und Links in der Microsoft Fabric-Migrationsübersicht.